PPARG基因taqSNPs遗传模型及单体型与2型糖尿病的相关性∗
2015-11-02多力坤买买提玉素甫祖克拉肉孜宋曼殳赵飞飞伊力哈木乃扎木
多力坤买买提玉素甫,祖克拉肉孜,宋曼殳,赵飞飞,伊力哈木乃扎木
(1.新疆大学 生命科学与技术学院,新疆 乌鲁木齐 830046;2.首都医科大学 公共卫生与家庭医学学院,北京 100069)
近年来,随着人们生活水平的不断提高,2型糖尿玻 T2DM)的发病率有了显著的增加.目前,通过关联研究,己有数百个T2DM的候选基因被报道,其中包括与胰岛B细胞功能缺陷、胰岛素抵抗及肥胖有关的基因,还包括一些与T2DM并发症相关的基因[1−4].国外有研究发现peroxisome proliferators-activated receptor gamma(PPARG)基因及其编码的蛋白质PPARG与2型糖尿病的相关性[5].PPARG是属于转录因子的核激素受体超家族成员,参与糖脂代谢和线粒体能量代谢调节,推测可能与糖尿病的发生有关.这些发现提示PPARG基因与2型糖尿病、代谢综合征及脂类糖类代谢密切相关[5−8].本研究的目的就是应用遗传模型及单体型对照病例的研究方法探讨PPARG基因与2型糖尿病的关系.
1 对象与方法
1.1 研究对象
在新疆阿图什市哈拉峻乡人民医院协助下采集无血缘关系的柯尔克孜族血样117例,同时用统一调查表进行直接问卷调查进行资料收集.采用病例一对照研究,筛选无血缘关系、年龄性别匹配的柯尔克孜族受试者100例,其中50例患者组与50例对照组,对所有的受试者进行了身高、体重、腰围、臀围、血压、空腹血糖、血脂水平包括甘油三酯(TG)、总胆固醇(TC)、高密度脂蛋白胆固醇(HDL)、低密度脂蛋白胆固醇(LDL)的检测.要求所有调查对象均在所在地区居住三代以上,无血缘关系,年龄>40岁,家庭婚姻史为世代族内通婚.自肘静脉采血5ml加EDTA二钾抗凝,充分混匀后分离血浆,放入-20◦C冰箱冷藏室保存待检生化指标和基因组DNA.
本研究所使用的所有研究对象均从阿图什市哈拉峻乡人民医院提供的居民健康档案库资料中筛选,在该医院医护人员协助下采集完成.2型糖尿病新诊断标准遵循世界卫生组织诊断标准[9].对照组均无代谢性疾病背景.对调查对象进行详细询问按项目内容逐项填写,力求调查表完整不缺项:电话、年龄、性别、身高、体重、腰围、臀围、血压、心率、吸烟史、饮酒史、家族史等.上述调查和取样均征得受试者本人同意并签署知情同意书.
1.2 方法
(1)基因组DNA的提取及DNA样品浓度和纯度质检:采用Transgenic Biotech有限公司的EasyPureTMBlood Genomic DNA Kit试剂盒.分离出的DNA用琼脂糖凝胶电泳法检验,并通过紫外分光光度计检测OD260/OD280数值,调整DNA终浓度在30-50 ng/µl之间.
(2)PCR与基因分型分析:根据SNP位点利用Assay Design 3.1软件设计PCR引物和单碱基延伸引物.本项分析是由毅新兴业(北京)科技有限公司(Bioyong Technologies Inc.)利用美国Sequenom公司的Mass ARRAY系统完成,该系统是基于基质辅助激光解析电离飞行时间质谱技术(MALDI-TOF-MS).首先所延伸引物通过质谱预实验进行质检,将引物稀释到质谱反应所需浓度,PCR引物储备液制备终浓度为100 p(u mol/L),单碱基延伸引物储备液终浓度为500 p(u mol/L).Mass ARRAY系统具体步棸如下:5µl的PCR反应体系中含有ddH2O 1.8µl,10×buffer0.5µl,Mg2+0.4µl,dNTP 0.1µl,Hot star 0.2µl,F Primer/R Primer各0.5µl,所有需要分型的基因组DNA样品(20 ng-50 ng)1µl,至终体积5µl.PCR扩增反应条件:95◦C 2min 预变性,95◦C 30s,56◦C 30s,72◦C 60 s,45个循环,最后72◦C 5 min,25◦C∞.PCR扩增后,剩余的dNTP将被去磷酸化消化掉,用总体积2×460µl的SAP酶Mix反应体系包括dddH2O 1.53×460µl,SAP Buffer 0.17×460µl,SAP Enzyme0.3×460µl.该反应在PCR仪中按照下述程序进行SAP酶消化:37◦C40 min,85◦C5 min,最后25◦C∞.SAP酶消化后,单碱基延伸反应在下列反应体系中进行,单碱基延伸反应Mix反应体系含有三蒸水0.619×460µl,10×iplex buffer0.2×460µl,Terminator mix0.2×460µl,引物0.94×460µl,单碱基延伸酶0.041×460µl,至终体积2×460µl.单碱基延伸反应在下列条件下进行:预变性94◦C 30s,然后94◦C 5s,52◦C 5s,80◦C 5s,共40个循环,最后72◦C 3min,25◦C∞.将反应产物的384孔板中加入16µl三蒸水,2000转离心3 min;加入树脂,在反转摇匀仪上做树脂纯化反应35 min,脱盐,反应完成后2000转离心3 min.将脱盐处理后的样品点在样品靶上,自然结晶,并用基质辅助激光解析电离飞行时间质谱进行分析.最终结果由Mass ARRAY-软件系统实时读取,并Mass ARRAY Typer 4.0软件检测质谱峰,并根据质谱峰图判读各样本目标位点基因型.
1.3 主要试剂和仪器
1.3.1 试剂
质谱分析(Complete Genotyping Reagent Kit for Mass ARRAY®Compact 384;USA);提取DNA试剂(EasyPureTMBlood Genomic DNA Kit;Transgenic Biotech).
1.3.2 仪器
基因扩增仪:(ABI Gene Amp®9700 384 Dual;USA);质谱点样仪:(Mass ARRAY Nanodispenser RS1000;USA);质谱分析:(Mass ARRAY Compact System;USA);台式离心机(Pico,德国Hereaus);移液器(0.5-10µ1、10-100µ1、100-1000µ1,德国);微波炉(W700A,亚美公司(日本));凝胶成像仪(Gel Dox XR,美国Bio-Rad);全自动高压灭菌9SM510,日本Yamato);电泳仪(Power Basic,美国Bio-Rad0).
1.4 统计学处理
两组之间均数比较用成组t检验,频率比较的单因素分析采用χ2检验,群体基因型经Hardy-Weinberg平衡检验.每个SNP与T2DM的遗传效应之间的相关性通过非条件Logistic回归分析计算出优势比及95%的可信区间,并对年龄和BMI进行了校正.使用Haploview 4.2分析软件进行LD分析及单体型的频率比较.统计分析均以P<0.01具有统计学意义.
2 结果
2.1 病例-对照组临床资料
采用t检验比较基本临床资料.血压(SBP、DBP)、腰臀比值、血糖、总胆固醇、低密度脂蛋白水平在对照和病例两组间有显著差异(P<0.01),见表1.

表1 两组病例临床资料
2.2 对照-病例组基因分型
根据基质辅助激光解析电离飞行时间质谱(MALDI-TOF-MS)反应产生的数据,应用Typer 4.0软件检测质谱峰,并根据质谱峰图判读各样本目标位点基因型,见图1.

图1 rs1899951 Mass ARRAY等位基因分型示意图
2.3 23个位点Hardy—Winberg平衡吻合度检验
PPARG基因所筛选的23个SNPs 位点借于MAF值进行Hardy—Weinberg遗传平衡定律检验,除了rs9310401,rs9817428,rs17036242位点以外,其他位点均符合,具有群体代表性(P>0.05),见表2.

表2 选择标签SNP基本情况
2.4 单个SNP与2型糖尿病的关联
采用Pearsonχ2检验的连续性校正(correction for continuity)和Fisher精确检验,比较各位点的等位基因,以及不同遗传模型下基因型频率分布在对照组和患者两组中是否具有统计学差异,目的在于确定检测的位点是否与疾病相关.在共显性遗传模型、显性遗传模型和隐性遗传模型下23个SNPs位点与2型糖尿病进行关联分析,年龄和BMI等危险因素在对照组和病例组统计时予以校正.结果显示,23个SNP位点中rs1801282,rs1899951,rs2881654,rs2921190,rs2959272,rs1875796,rs4135275,rs1151999位点在不同遗传模型下基因型频率分布在对照组和患者两组中有统计学差异(P<0.001,P<0.05),其中rs1801282、rs1899951、rs2881654、rs2972162位点基因型在对照和病例组中的分布除了在隐性模型中未见显著的统计学意义之外,在共显性模型和显性模型均存在显著的统计学意义(P<0.001,P<0.05),rs2921190、rs2959272、rs1875796、rs1151999位点基因型在对照和病例组中的分布除了在共显性模型和隐性模型中未见显著的统计学意义之外,在显性模型存在显著的统计学意义(P<0.05).三种遗传模型下各个SNP与2型糖尿病易感性的关系如表3所示.

表3 23个单个SNP位点基因型在不同遗传模型下与T2DM的关联
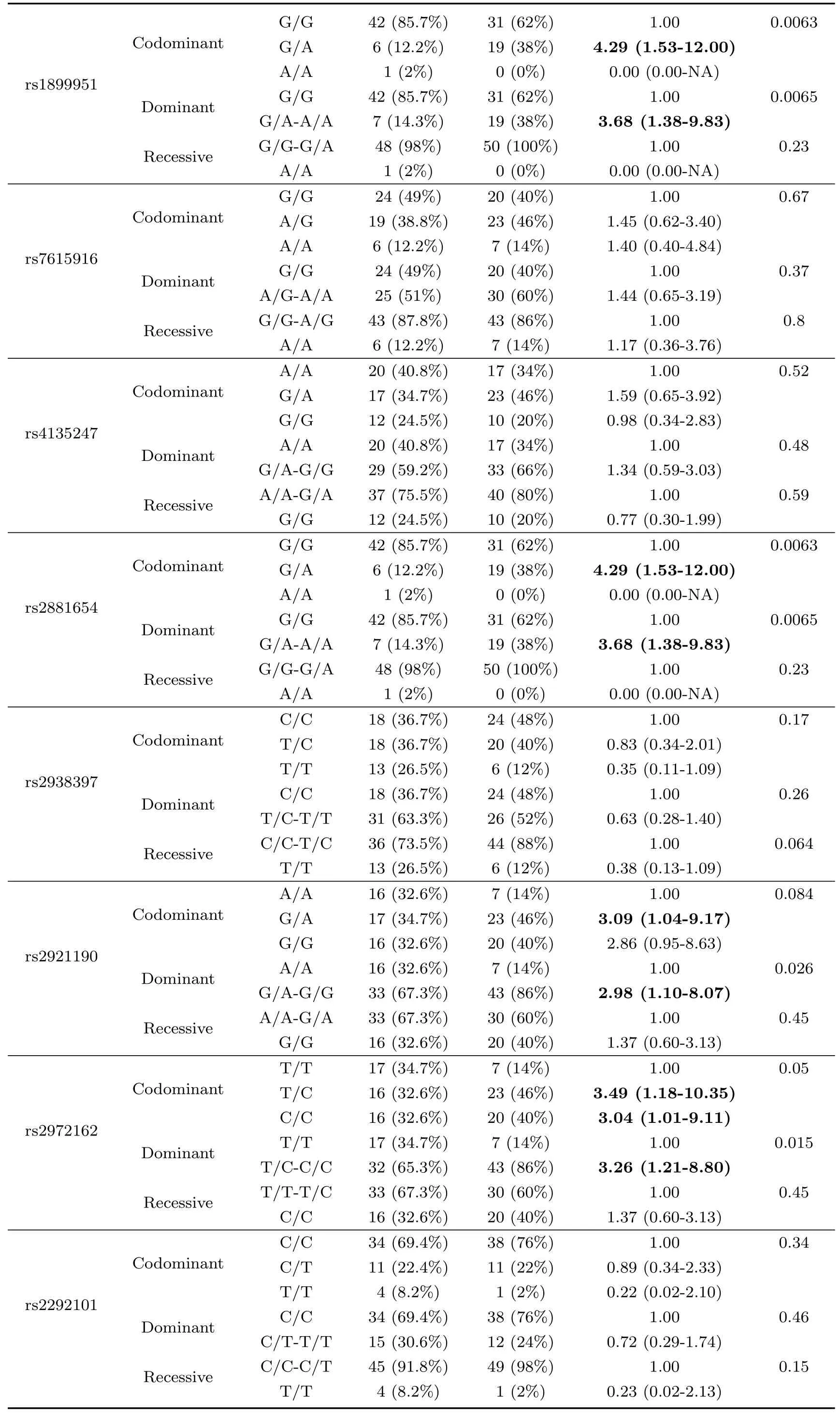
表3续 23个单个SNP位点基因型在不同遗传模型下与T2DM的关联

表3续 23个单个SNP位点基因型在不同遗传模型下与T2DM的关联

表3续 23个单个SNP位点基因型在不同遗传模型下与T2DM的关联
2.5 PPARG基因23个SNPs位点的连锁不平衡分析
所用软件:SPSS 17.0 statistical packages(SPSS,Chicago,IL)PLINK software package(version1.07),SNP Stats web tool.(http://bioinfo.iconcologia.net/SNPstats web)和Haploview software package(version 4.2).连锁不平衡分析(linkage disequilibrium analysis)利用参数D’,r2衡量SNP位点间的连锁不平衡程度,采用D’置信区间法划分单体型区块LD Block.
用Haploview统计软件进行连锁不平衡分析发现rs4684846,rs9817428,rs17036242,rs9310401,rs1801282,rs1899951,rs7615916 7个SNPs处于同一个单体型区块中称为单体型区块Ⅰ(LD BlockⅠ);rs2938397,rs2292101,rs2959273,rs4135275,rs709151,rs1175540 6个SNPs处于另一个单体型区块中称为单体型区块Ⅱ(LD BlockⅡ).当连锁不平衡系数()和关联系数(r2)都为1时,表示SNPs位点间存在强连锁不平衡.柯尔克孜族人群23个位点中13个SNPs位点分别位于两个单体型区块,每个单体型区块内的SNP间的连锁不平衡系数值都为1,且r2基本都大于0.33,表明该多态性位点彼此之间处于强连锁不平衡关系,可用于单体型分析,见图2和图3.
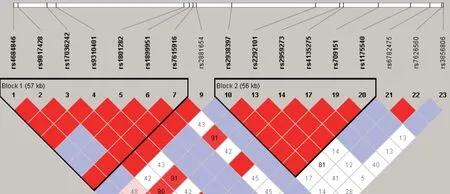
图2 PPARG基因23个SNP的连锁不平衡结构和单体型区块
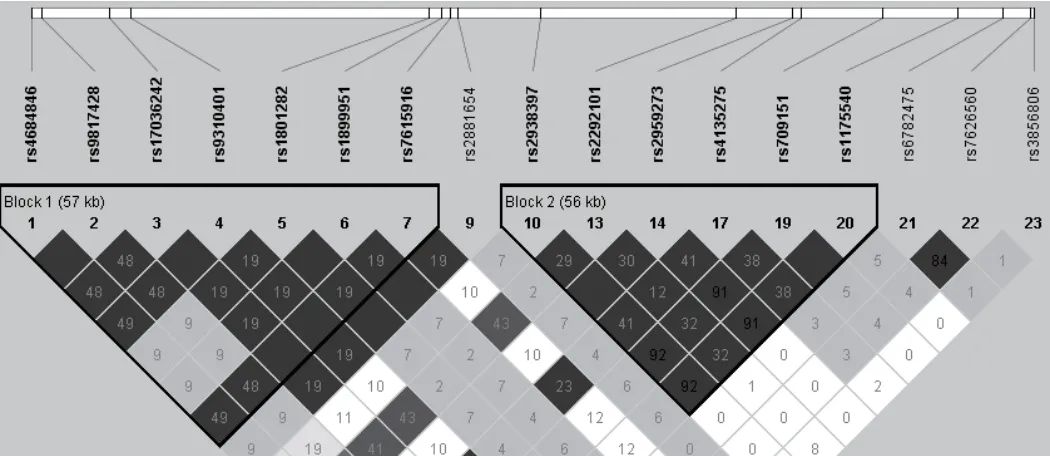
图3 PPARG基因23个SNP的连锁不平衡结构和单体型区块
2.6 单体型病例对照分析
利用Haploview软件分别构建病例组和对照组PPARG基因13个SNPs位点的单体型,以单体型频率>0.01为准,主要有10种单体型,它们分布为两个单体型区块.这种较少的单体型变异也显示PPARG基因内的SNP连锁不平衡较强,重组较少.
PPARG基因第一单体型区块(单体型区块Ⅰ)有7个SNPs(rs4684846,rs9817428,rs17036242,rs9310401,rs1801282,rs1899951,rs7615916)位点组成的4种主要的单体型(frequency>0.01),以ACGTCGG为主,GAACCGA次之,其他单体型为GAGTCGG,GAACGA.4种单体型在对照组和病例组中的分布特征相比较,GAACGAA单体型组间具有统计学差异(χ2=4.935,P=0.0263,P<0.05),结果见表4.

表4 单体型区块Ⅰ4种常见单体型在对照组和患者组的分布特征
PPARG基因第二单体型区块(单体型区块Ⅱ)有6个SNPs(rs2938397,rs2292101,rs2959273,rs4135275,rs709151,rs1175540)位点的组成的6个主要的单体型(frequency>0.01),以CCCGGC为主,CCCAGC次之,其他的单体型为TCTAAA,TTTAAA,TCTAGC和TCTGGA.6种单体型在对照组和病例组中的分布特征比较,发现组间未具有统计学差异(P>0.05),结果见表5.

表5 单体型区块Ⅱ6种常见单体型在对照组和患者组的分布特征
3 讨论
人类基因组计划为疾病的治疗和预防提供了更多的有效工具,带动了诊断与检测产品及方法的研究开发,在遗传疾玻 糖尿病、脂肪肝、代谢综合征等)进行筛选和诊断,并根据结果进行有效治疗并促进预测及预防医学的发展有很大的帮助.目前慢性玻 糖尿病、高血压、心脏病等)的发病频率很高,人们急需了解如何预防此类疾玻 方法之一就是通过基因诊断与检测了解一个人的基因型,并预计他患病的可能性,从而营造适当的外部环境,达到预防的目的,有助于实现个体化医疗与个体化健康[10].随着人类基因组研究的纵深发展,对人类基因组多态性(SNP)及变异的研究十分必要,人类DNA序列变异约90%表现为单个核苷酸的多态性,故SNPs是一种常见的遗传变异类型[11].
目前研究糖尿病相关基因常用的技术是基因组扫描和连锁分析,连锁分析适用于分析基因型与表型有较密切关系,且疾病表型较单一的致病基因.一般认为研究T2DM等多遗传因素及环境因素参与的复杂性疾病时,采用基于群体的基因组SNP“case-control”关联分析,特别是基于连锁不平衡(linkage disequilibrium,LD)的关联分析,比连锁分析更有效[12−13].关联分析是基于群体中无亲缘关系的病例组和表现型正常的对照组在某个遗传标记位点上会出现不同的频率而设计的,通过两者频率的不同,就能推测所研究的遗传标记和某个遗传病易感位点之间是否存在因果关系或连锁不平衡.通过关联研究,己有数百个T2DM的候选基因被报道,其中包括与胰岛B细胞功能缺陷、胰岛素抵抗及肥胖有关的基因,还包括一些与T2DM并发症相关的基因[14].PPARγ变异与胰岛素分泌和胰岛素敏感性胰岛素抵抗是T2DM患者的常见特征,它可以预测糖尿病的发玻 T2DM患者骨骼肌胰岛素抵抗的特征包括胰岛素介导的葡萄糖摄取和利用不充分及脂肪氧化抑制效应减弱,需机体分泌较多的胰岛素方能代偿此种缺陷.复杂疾病关联研究存在的最大问题是可能产生因群体分层(Population Stratification)导致的假阳性错误.而隔离人群人口流动性小、具有相对均一的遗传背景,可避免群体分层问题;此外,利用隔离人群识别侯选基因所需的受试样本量与遗传标记数量相对较少,可为识别相关基因(如致病基因等)的研究提供易于统计分析的群体模型,在解析复杂性状方面具有不容忽视的特殊价值[15].
本研究通过T2DM遗传学研究中使用最广泛的“病例-对照”研究方法寻找柯尔克孜族人群中T2DM的易感基因,为T2DM的早期分子诊断和干预提供初步线索[15].将为新疆地方与民族高发性疾病的预防、早期诊断和治疗等提供重要理论依据.研究结果提示,在对照组和2型DM组间分别在血压(SBP、DBP)、腰臀比值、血糖、总胆固醇、低密度脂蛋白水平有显著差异(P<0.01).单个SNP位点分析采用Pearsonχ2检验的连续性校正和Fisher精确检验方法,不同遗传模型下PPARG基因23个SNP位点中rs1801282,rs1899951,rs2881654,rs2921190,rs2959272,rs1875796,rs4135275,rs1151999位点基因型在对照组和病例间的分布具有统计学差异(P<0.001,P<0.05),其中rs1801282、rs1899951、rs2881654、rs2972162位点基因型在对照和病例组中的分布除了在隐性模型中未见显著的统计学意义之外,在共显性模型和显性模型均存在显著的统计学意义(P<0.001,P<0.05),rs2921190、rs2959272、rs1875796、rs1151999位点基因型在对照和病例组中的分布除了在共显性模型和隐性模型中未见显著的统计学意义之外,在显性模型存在显著的统计学意义(P<0.05).PPARG基因单体型区块Ⅰ7个SNPs(rs4684846,rs9817428,rs17036242,rs9310401,rs1801282,rs1899951,rs7615916)位点组成的4个主要单体型中GAACGAA单体型在对照组和患者组间分布具有统计学差异(P<0.05).单体型区块Ⅱ6个SNPs(rs2938397,rs2292101,rs2959273,rs4135275,rs709151,rs1175540)位点组成的6个主要的单体型组间分布均无统计学差异(P>0.05).最近Ruchat[16],Azab[17]Khadija Tariq[18],Qi PEI[19]等分别以居住在加拿大的阿拉伯人、巴基斯坦人、中国汉族人群为对象进行PPARGrs1801282多态性与T2DM关联,也得出了相同的结论.关于新疆柯尔克孜族与3个国外种族的基因型和等位基因型频率特征比较,结果显示所选的SNPs中rs3856806,rs7615916,rs7626560,rs4135304,rs4135343位点在柯尔克孜族人群与CHB(北京汉族人)人群间基因型和等位基因分布频率均有显著统计学差异(P<0.01).rs2292101,rs2959273,rs3856806,rs4684846,rs6782475,rs7615916,rs7626560,rs9817428,rs4135304,rs4135343位点在柯尔克孜族人群与CEU(欧洲北部和西部犹他州居民)人群间基因型和等位基因分布频率均有显著统计学差异(P<0.01).在SNPs中除了rs17036242,rs7615916,rs9310401,rs9817428,rs2938397,rs2959272位点外,rs1151999,rs1175540,rs1875796,rs1899951,rs2292101,rs2881654,rs2921190,,rs2959273,rs2972162,rs3856806,rs4135247,rs4135275,rs4684846,rs6782475,rs4135343位点在柯尔克孜族人群与YRI(非洲伊巴丹尼日利亚人)人群间基因型和等位基因分布频率均有显著统计学差异(P<0.01)[20].
总之,采用病例-对照关联分析方法,新疆柯尔克孜糖尿病病例组和对照组PPRAG基因23个SNP位点多态性特征比较研究结果显示,共显性模型、显性模型和隐性模型3个遗传模型下PPARG基因的中rs1801282,rs1899951,rs2881654,rs2921190,rs2959272,rs1875796,rs4135275,rs1151999位点变异可能与柯尔克孜族人T2DM相关,GAACGAA单体型可能是柯尔克孜族T2DM的遗传标记.为今后对新疆柯尔克孜族2型DM遗传学机制研究提供理论依据,同时进行的PPRAG基因23个等位基因的遗传数据有利于探讨柯尔克孜族与其他族群的遗传结构提供证据.
