基于Speex的音频压缩算法分析与优化
2015-11-02杨永全宫飞翔
孙 王 杨永全 宫飞翔
基于Speex的音频压缩算法分析与优化
孙 王 杨永全 宫飞翔
随着移动互联网的深入普及,人们越来越习惯通过语音发送消息来代替文字输入。因此,改善音频压缩质量会提高语音的传输效率。本文提出了一种改进了在无线网络环境中speex音频数据压缩的方法,该方法先将原有的码激励线性预测编码技术(CELP)中的感觉加权过滤器进行了简化,再将语音编码中基音搜索的计算复杂度进行简化,并在基于XMPP协议的即时通讯系统中进行实验验证。使得在高压缩比的情况下降低CPU运算复杂度,保证了音频数据传输的低延迟性。
社交网络成为目前互联网上最为流行的沟通方式之一,互联网提供了文字、图片、语音、视频等丰富多样的媒介方式来满足人们日常的交流。伴随着智能手机日益的普及,人们通过手机IM(Instant Message)交流的需求也日益扩大,尤其是语音信息的交流,大大增加了人们的沟通效率。但通常IM协议中没有对语音传输提供很好的支持,它们一般将音频以文件的方式进行传输,没有考虑到无线网络环境中流量的问题和移动设备中系统资源的使用效率。除此之外,各移动平台设备的音频格式也不尽相同,在不同平台上的音频转码会消耗更多系统资源。因此,需要实现一个高压缩比和低资源消耗的音频压缩,以适应无线网络中语音通信的需求。
Speex是一种基于CELP编码技术的开源算法,在网络通话的应用背景下而提出。该算法灵活多变,具有多采样率、多码率、高压缩比等特性,非常适合在无线网络环境中进行语音传输。然而,早期CELP(码激励线性预测)编码技术的运算量比较大。为适应其在移动端上应用,在简单介绍Speex的编码原理后,从感觉加权过滤器和基音搜索中的互相关计算方法进行简化和调整,使其在保持高压缩比和前提下减少CPU占有率,提高编码效率。
算法设计
Speex编码原理
CELP全称为码激励线性预测,是用码本(信号集)作为激励源,根据语音发音的特点,通过激励源中浊音和清音的不同来创建码本:自适应码本和随机码本。自适应码本中的码矢量用来逼近语音的长时周期性(基音)结构。随机码本中的码字用来逼近语音经过短时、长时预测后的残差信号。编码器中的分析滤波器用来计算两个码本的最优码矢,并预测最佳增益矢量后生成残差激励信号。图1为语音分析与合成模型图。
语音分析时,先缓存一帧的语音信号,然后对该信号进行线性预测,确定一组LPA(线性预测)系数,接着利用已确定的LPA系数和分析滤波器A(z)来计算未量化的残差信号。在实际分析中,为提高分析精度,每一帧都会被分成几个子帧来确定基音预测参数,随后用激励码本中的某矢量合成语音,最后计算合成语音与原始语音的最小均方误差作为最佳矢量。
线性预测分析
线性预测是众多编码器的重要成分之一,核心思想是用过去若干个语音值加权线性组合来预测当前时刻语音抽样值。具体采用最小均方预测误差逼近方法来实现,公式如下:

y[n]是x[n]的线性预测值,其误差值为:
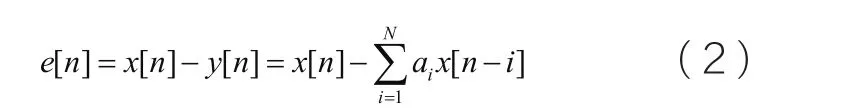
线性预测的目的是为了找到最佳的预测因子ai,使得均方误差值最小:
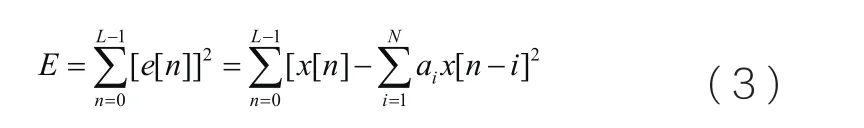
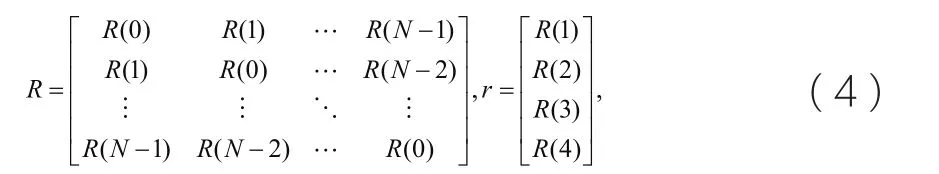
其中R(m)是信号x[ n]的自动调节系数,该值由公式5计算得出:
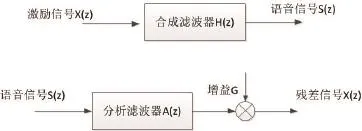
图1 语音分析与合成模型图
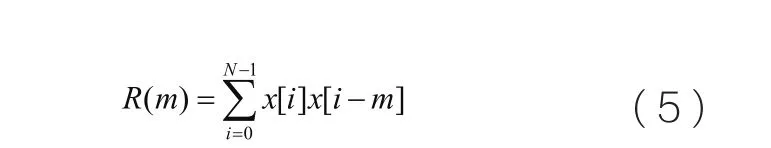
R(m)是通过Levinson-Durbin算法求出,该算法可以证明线性预测综合滤波器1/A(z)总是稳定的。以上公式的计算复杂度比较大,因此在实际应用中使用略大于1的浮点数与R(0)相乘,相当于在信号中添加微小的噪音来降低信号中的共振尖峰。
合成分析
合成分析法通过感知优化闭环中的解码信号来分析的。其目的是使原始语音和合成语音之间的误差最小,而评判误差则是利用信号中的余量信息来确定。余量信息是通过比较合成语音与原始语音所得,根据规定误差范围来动态调整各个计算参数,从而保证两者信号之间的误差最小。
合成分析方式为闭环分析感知优化,闭环分析是指利用系统输出引用编码参数来分析,而不将系统输出引入编码端则称为开环分析。
感觉加权过滤
由于混合编码的合成语音与原始语音在波形上没有一一对应,为了使语音信号的合成更符合人类主观感受,因此在编码中添加感觉加权滤波器,使合成的语音主观上听起来更加平滑。感觉加权滤波器的传输公式为:
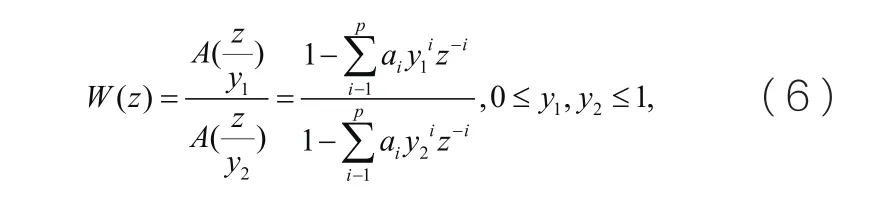
算法优化
语音编码致力于降低传输所需要的信道带宽和编解码所需的系统资源,同时保持输入语音的质量。而为达到这一目的,在CELP编码中应尽可能的降低编码复杂度或以较低的比特率进行编码。本文通过简化滤波器和自适应编码中基音搜索的运算量来减少CPU占有率。
感觉加权滤波器的调整
Speex编码器在语音编码时加入了感觉加权滤波器,而在解码器中加入了感知加强分析。为减少计算复杂度,将其中的感觉加权过滤分析进行简化,以达到提高编码速率。编码语音合成用到感觉加权分析的有自适应码本、随机码本,自适应码本是对元音信号的优化,随机码本是对清音和背景噪音信号的优化。元音信号具有周期性,信号能量强特点,再加上移动端语音输入模式比较固定,加权后信号改变的幅度比较小,因此在这里可以不考虑对其进行感觉加权分析。而清音信号没有固定周期,信号较弱,因此保留该处的感觉加权过滤。
优化前后流程对比如图2所示,其中(a)图为优化前程序流程,(b)图为优化后程序流程,W(z)为感觉加权滤波器。通过语音质量评估,自适应码本搜索在不通过感觉加权过滤器的情况下,合成语音的质量没有明显差别。
简化自适应码本的运算规则
简化的第二个思路为减少自适应码本中语音帧的样点分析值,根据移动客户端语音输入的环境,通过减少样点值计算的复杂度来分析最终合成语音的质量。
在自适应码本的基音周期搜索中,这种传统的运算方法可用公式7表示:
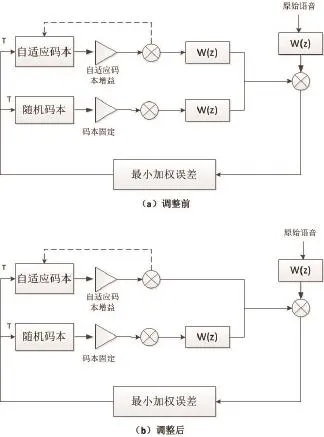
图2 调整前后的编码图
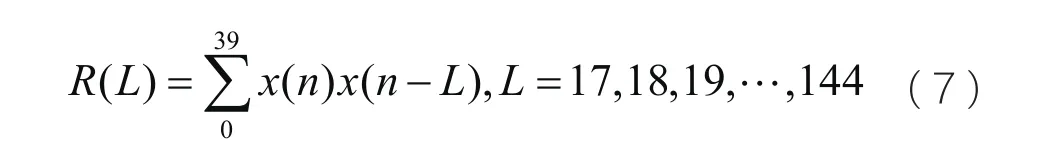
可以看出传统的自适应码本搜索算法中,基音周期的搜索需通过127次频率带宽对比,每次对比还需要分析40个样点,在社交网络的语音传输中,这种运算量过于复杂,尤其是在移动端。为了降低运算复杂度,在原先的算法基础上,采取一种简单的搜索算法。其算法可以用公式8表示:
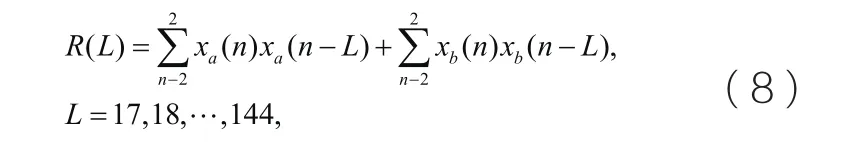
从简化后的公式可以看出,样点数由原来的40减少到现在的10个,当n=0时,xa(0),xb(0)分别表示样点值的最大值和最小值,从最值两边再取两个相邻点来保证运算的预测值相差不大。因为在自适应码本中,语音信号的能量比较大,其频率分布与基音周期值近似相等,在解码时,其近似运算结果所解析的语音质量可以满足大部分移动网络的要求。与公式7相比,其运算量有明显降低。
结果测试
本次测试将从语音质量评估和CPU占有率两方面来判断speex算法优化效果。测试的样本会在三种噪音环境下产生,其中语音质量评估采用ITU的P.862来评分,评分值为MOS(平均主观评分),MOS值的区间为0-5.0,音质越好,评分越高。语音波形图则借助Adobe Audition软件,语音内容为“今天是农历初八”。
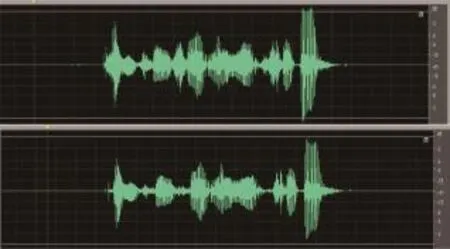
图3 安静环境下波形对比

图4 低噪环境下波形对比
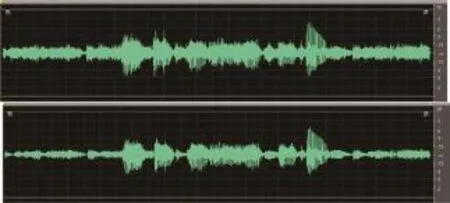
图5 高噪声环境下波形对比
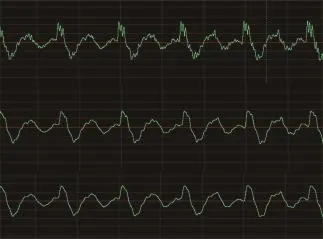
图6 安静环境下波形放大对比
图3至图5分别为安静、低噪和高噪声三种环境下语音波形对比图,第一条波形图为优化前的speex算法波形图,第二条为优化后的波形图。可以看出,两条波形图大体一致,背景环境越安静,波形越一致。噪声越大,对自适应码本中元音发音的干扰更加强烈,即计算所得的偏差度越大。
图6为是将图3中波形信号放大32倍后的波形对比图,图中第一条波形为原始语音波形,随后分别是算法优化前和优化后的波形。从第二、第三条波形中可以看出,speex算法所产生的语音质量较好,音质比较平滑。对比后两条波形图可以观察到未优化的波形更为细腻,而优化后的波形虽不如前者细致,但总体上保持音质与前者一致,音质的实际效果也没有发生明显差别。这主要是算法简化过程中减少帧的采样分析所致,基音搜索从默认的40个减少到10个。
实际上,语音的编码是在编码复杂度和语音质量之间寻找平衡,不同的应用需求会在此两者上寻找不同的平衡点。表1为speex算法优化前后音质与复杂度的对比。从表格中可以看出噪声越大,算法复杂度越高,这是因为speex编码过程中有噪声预处理阶段,该过程会增加编码的复杂度。在安静环境下,MOS值相差0.05,高噪声中MOS值相差0.15,表明MOS的差值也会随着噪声的增加而增大。
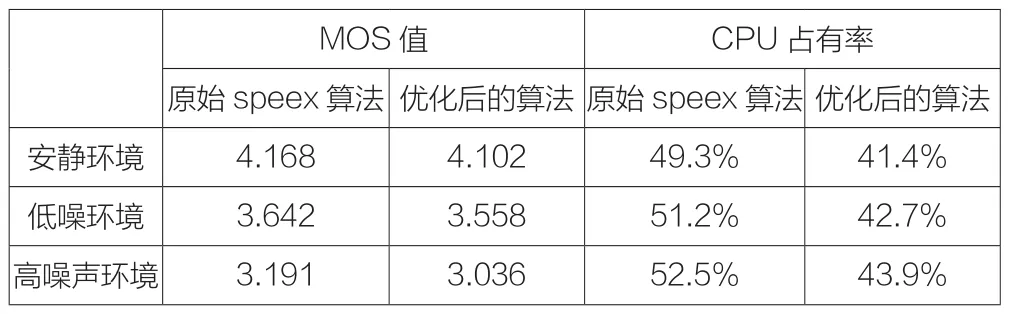
表1 Speex优化前后语音质量和复杂度对比
优化后算法的MOS值与原算法的差幅约为0.1,占总分值的2%。而计算复杂度却有8%的提高。可以看出,优化后的speex算法具有实用性。
总结
在不影响语音质量的前提下,通过对speex压缩算法中感觉加权过滤器和基音搜索过程中采样值分析的简化,来降低编码复杂度,提升了系统的整体性能。
本文优化的speex算法适合低噪环境,但在高噪声环境下语音质量下降幅度比较大。在今后的研究学习中,会将改善speex解码器中感知加强部分来改善噪音的分辨。
10.3969/j.issn.1001-8972.2015.10.017