基于DSP的实时数字音频系统的实现
2015-10-21叶强

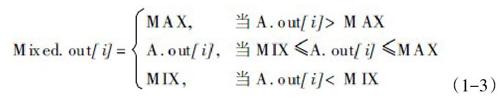
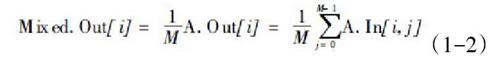
摘要:通过滤波对声音的噪音加以控制、毛刺去除和加以润色,搭配上混响输出给人有专业声乐棚的质感,本文主要研究实时数字音频系统构建的几种不同方法、典型应用和特效开发的流程,最后筛选音频系统混音算法。
关键词:DSP;数字音频;混音
实时音频系统主要是在将模拟信号转换为数字信号后,实现采样、滤波、变换等处理,在一系列流水处理之后再转换为模拟信号输出给扬声器。在信号处理阶段,对人声要经过采集、降噪、均衡、润色、压限和搭配混响等环节。
一、基于DSP的实时音频系统
DSP的实时音频系统是将外部输入的模拟信号通过模数转换为可以处理加工的数字信号,再对数字信号进行编辑、润色、去噪等加工,并通过数模转换芯片中把处理后的信号回归实际环境格式,如图1所示
图1 DSP技术流程图
DSP内置的程序储存器里存放指令与算法,数据存储器里存储过去的抽样数据和滤波器的系数。乘法器用于执行滤波运算中的乘法运算,算术运算单元用于执行滤波运算中的加法运算。滤波器的仿真与优化可以运用MATLAB软件内置的FDATool工具箱,只需在MATLAB主命令行键入FDATool命令即可打开如图2所示,并把所需的滤波器各项参数在滤波器参数配置页面进行输入,就可获得所设计的滤波器幅度响应波形,方便我们观察与分析,在仿真中还可以利用SPTool工具箱分别比较滤波前后的时域信号与频谱。
二、基于宿主软件的实时音频系统
宿主软件的数字音频系统是依托专业音频卡的音频流输入输出接口(Audio Stream Input Output)技术,搭载各种VST插件,将各种数字音频数据通过计算机的CPU与内存处理,在处理数据的时候,各种VST插件按照串联接口排序,逐一对音频数据有效处理,以能够实现多种现场合成效果,在几乎零延时的情况下处理音频数据流,受到广泛音乐制作人与爱好者的青睐。
宿主软件目前广泛使用的有protools,cubase,soner,liveprofessor和Samplitude,都可以组成独立的实时处理系统,主要仿真实际录音棚设备,可以实现多种录音棚合成音效,以及伴奏处理、录音对比和声像包络等。
三、实时音频系统的实现
DSP的实时音频系统的优势是可以通过软件分析波形并根据算法优化,宿主软件的优势是可以通过计算机的cpu与内存的运算模拟专业录音棚的音效。通过模块的设计和组合同时可以兼两者之长,能让实时音频系统具备更为强大的功能,如图2所示
图2 DSP与宿主软件协同工作
本系统的功能与特点如下:
(1)音源的输入可以加入滤波,对音乐的波形与幅度进行必要的调节和控制,达到预期的音乐的鉴赏效果或要求。
(2)ADC输入的音频信号在经过降噪扩展之后,可以根据算法原理为之设置相应的滤波器,在语音信号处理的时候一般在65HZ-80HZ的地方设计一个高通滤波器,用于切除低频的噪音(因为人声不在这个频段),而在高频容易产生尖锐声的地方设计一个低通滤波器,中间则使用钟形滤波器,结果如图3所示,得到一个平缓的输出的波形,同时清除喷声。
图3 多个滤波器的混合波形
如果合成地鼓的音乐还需要加重低音,则在低频不能使用高通滤波器,可以在135HZ的地方做一个窄带宽的加强,针对不同的音色处理要求设计不同的滤波器,实时处理出来和后期制作效果一致。
(3)通过滤波器设计多种混响器,满足各种音色润色的需要,用来合成录音棚制作的音效,在混响器上还设置激发装置,音源有电平信号时即下降沿转换到上升沿时,激发器打开侧链作用,混响器的功能被激发,也就是自动混响的效果。
(4)同样原理,在音源之后增加触发压限的功能,ADC可以触发其侧链,可以实现随麦克风声音增大而音乐降低的效果,也就是主持人所需要的人声突出,同时也让总输出的幅度基本保持均衡。
(5)在上述原理上继续延伸,可以把音乐本身分成左右声道,人声激发消去其中的一路,人不发声时,音乐左右声道都可以处于播放状态,也就是实现智能跟唱。如果压制掉的原唱的声道继续发送到本地扬声器,那么就成为隐含跟唱。
(6)部分特效需要宿主软件处理时,可以通过宿主接口将DSP处理过的音频数据发送至宿主软件,让宿主软件进一步处理各种模仿专业录音棚的特效,再由宿主软件音源输出,实现DSP与宿主软件的完美结合。
四、实时音频系统的多节点混音
混音是将多个音频流或多个音轨通过线性叠加混合为一个音频流,在播放时听感能够与现场趋于一致。要想获得好的混音效果,取决于两个条件:完善的混音方案与优秀的混音算法, 两者缺一不可。
1.混音方案
集中式混音首先将多路音频流各自解码后进行预处理( Preprocessing)。预处理的主要任务是: ①静音检测,可以提前抑制无关用户的噪音,混音过程中自动回避没有发声的无关用户。如果发声用户为一人, 此时混音器只作转发无须解码再编码;②统一语音样本的采样率, 为音频混合提供必要的条件。一般默认8 kHz的采样率,按此标准进行转换。每个音轨增设一个Buffer作为音频流缓冲区,缓冲因为网络延时和处理速率不同的数据,混合后的音频流进行数据溢出检测、音色平滑处理、回音冗余消除等后处理(Post processing)工作就可以重新编码后发送到系统每个终端,如图4所示:
图4 集中式的混音方案
分布式混音有别与集中式混音, 分布式混音具体实施在各个终端分别进行,终端的负担加重,只做数据转发的MCU负担减轻。此方式的优点是MCU负担较轻便于扩展用户数量,终端优越即可完成任务, 因为各终端无需接收到自身的音频流,还规避了混音回声的干擾。MCU的任务只是对音频流进行复制或转发,不需要混音的模式减少传输延时。缺点是每个终端在进行混音, 故每个终端资源开销较大。终端接收的其他用户的多路音频流需要良好的带宽。分布式混音方案如图5所示。从图中可观察出, 在混音器Mixer之前的预处理、缓冲配置和集中式混音相同, 不同的是混音之后的音频经过后处理就可以送到播放缓冲区无须重新编码等待音频播放器播放, 减少了系统的运算开销。
图5 分布式混音方案
2.混音算法
混音运算就是在混音器中对参与混音的各种音频流的线性叠加。如果存在M个输入音频流, 每帧语音流内含N个样本,A. Out[i] 是当前语音帧混音输出的第i个样本, A. In[ i, j ]是当前语音帧的第j个音频流的第i个样本的输入( 其中0≤j≤M-1,0 ≤ i ≤ N) , 则线性叠加表达式如下:
将当前帧的每一个语音样本线性叠加,就得到当前帧的混合样本。为了实现平稳性, 因此帧长不宜过大,通常取帧长为15-35ms。如果取帧长为25ms, 采样率为8000Hz, 则每帧就有200个样本。目前通用量化精度为16bit,取值范围为- 215至215之间, 多个语音流按表达式(1-1)进行线性叠加,可能会溢出而产生噪音。
克服混音溢出难题一般有如下几种方法:
(1)平均值法:针对表达式(1-1) A. Out [ i] 求其平均值作为混合音频流输出,如式(1-2)所示, 该方法能够解决溢出问题, 但会严重降低混音后的音量。参与混音的音频流越多, 音量也就越小, 如果输入的原始音量很小, 经均值计算后则很难听见。当用户数目发生变化时, 混音输出的音量也会随之变化, 因此该方法只能运用于音频流较少的情形。
(2)箝位法: 检测到溢出时,溢出超过临界部分给予切除,未溢出的维持原状。如式(1-3)所示, 该方法虽然较为快速简易,但却造成音频流的损失,引入了波形失真, 同时存在较大杂音的困扰。因此,该方法在音频流较多溢出频繁的情况下,不具备实用价值。
(3)按溢出贡献加权算法:寻求一种权重比将溢出的音频流按预设的权重缩小, 从而克服混音溢出难题。在对音频流混音时可分别对各音频流设置固定权重或自适应权重,比较而言,自适应加权是更为理想的解决途径,但混音计算不宜过于复杂, 否则会导致计算延时加剧, 不适用于实时音频处理。
将人声的音量大小作为权重,混音算法中用音量除以权重,声音大的权重大,除数大减少就多,因此混音后各人的音量互相接近, 消除了小音量被淹没的问题, 又完美克服了溢出难题。假设第j路音频流的第i个样本权重是Wj[i] ,音频流的幅度又可以用其绝对值表示,则表达式为:
当混音后溢出的话, 则修改第j 路的幅度为:
此时混音输出的表达式为:
算法如下: ①按表达式(1-1) 计算混音输出; ②根据混音后是否溢出确定混音输出的表达式,如无溢出则为表达式(1-1),反之转下一步; ③根据表达式(1-4) 确定各路音频流权重, 再由表达式(1-6) 处理溢出问题; ④转表达式(1-1)确定下一个语音样本。如果N 个样本均处理完毕, 则转下一步; ⑤循环上述4个步骤处理下一帧。
五、仿真结果
通过分析上述三种算法的计算复杂度可看出,前两种算法虽然计算复杂度低,容易实现, 但不能保证混音的质量, 也不能对混音溢出做出合理修正,更不能突破四用户的瓶颈限制;第三种按溢出贡献加权算法则相对比较优越。实验结果如下:
實验数据是预先录制音频,两路人声,两路音乐,其中一路人声和一路音乐声音较小,另外两路较大,语音的采样率都是44100Hz,精度为16bit,语音帧长取为20ms,测试时长为80s,测试环境为Windows 7 64位 系统, CPU为双核四线程I3 3220, 4GB 内存。分别对式(1-2), 式(1-3)和式(1-6)三种算法进行实验, 记录三种不同算法进行四路混音语音数据耗时分别为22ms, 32ms和45 ms, 从处理时间可以看出运算开销都不大, 按贡献加权算法只落后十几毫秒。图6至图9是三种算法分别混音后的音频波形, 比较波形图可以看出, 平均值方法得到的波形整体幅度比较小,小的音频信号被淹没, 而且参与混音的音频流数目越多所得波形幅度越小;箝位法混音输出波形虽然似乎保真, 但是仍可以看出在上下边界溢出波形被剪切,参与混音的越多溢出剪切越频繁造成失真越多;按贡献加权混音输出的波形幅度适中, 几乎无溢出, 既平衡了各路的音量, 并完美地控制了溢出。综合以上得出, 按贡献加权算法实用可靠。
图6 平均值混音输出波形
图7 箝位法混音输出波形
图8按贡献加权混音输出波形
本文通过搭建实时系统,对音频合成各种音效进行了分析,可以实现朗诵、录音、对唱、合唱、自动混响与音乐闪避等特效,得到了比较理想的结果。并在此基础上,运用平均值法、箝位法、按贡献加权法对仿真结果进行了分析,而得出按贡献加权法混音输出的效果明显好于传统两种方法输出的结论。与传统的实现方式相比,本文所采用的这种方式可以得到更加线性、平滑的数字波形。
参考文献:
[1]张承云、谢志文、谢渡荪.多媒体计算机的音频实时处理[J].电声技术,2000(1):p19—2l
[2]陆牧基于DSP的数字音效系统研究[D].华中科技大学硕士学位论文,2002
[3]谢铿.基于DSP的数字音频系统[D].广东工业大学硕士学位论文,2002
[4]邓在雄、赵惠清.数据实时采集与处理系统软件开发中若干问题的研究[J].北京化工大学学报(自然科学版),2004(3):32-33
作者简介:
叶强,男,江苏财经职业技术学院教师,工学硕士,计算机应用方向。
