实数编码遗传算法与支持向量机在烟草病害识别中的应用
2015-10-20濮永仙

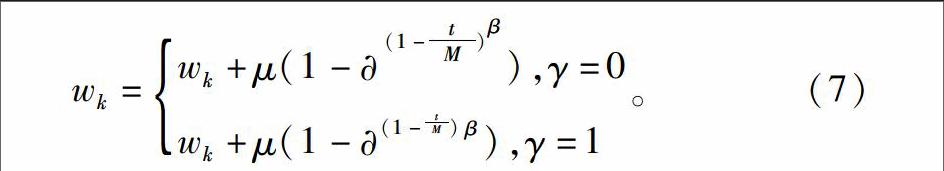
摘要:为实现计算机诊断烟草病害,提出了依据病害图像的特征,运用实数编码遗传算法优化特征和支持向量机识别病害的方法来诊断病害。通过对病害图像增强处理、彩色病斑分割、病斑特征提取,构建了实数编码遗传算法选择有效特征与支持向量机识别病害的模型。该模型通过实数编码遗传算法将权重较高的前n个特征值xi乘以对应权重wi作为支持向量机的输入向量,将分类精度作为遗传算法的适应度,对个体进行了评估,实现了在获得有效特征的同时提高支持向量机的识别精度。试验结果表明,经过训练的模型具有较好的烟草病害识别能力。
关键词:病斑特征;烟草病害;支持向量机;CIE L*a*b*模型;实数编码遗传算法
中图分类号: S126;TP391.41文献标志码: A文章编号:1002-1302(2015)09-0435-04
随着计算机技术的发展和农业信息化的迫切需求,国内外学者尝试利用计算机图像处理技术和模式识别技术对作物病害进行自动定量的识别,已在水稻、小麦、黄瓜、蔬菜[1-5]等的病害识别上取得了一定的成绩。常用的模式识别工具有贝叶斯决策、神经网络、模糊集法等。常用模式识别工具是以无限多样本训练为前提的,但在实际诊断中对于某一类病害,通常不具有大量的病害样本。支持向量机(SVM)[6]是一种新的模式识别方法,它在处理非线性、小样本等问题上具有特定的优势,在生物信息、医学等领域已得到了成功应用。已有学者开始利用支持向量机对葡萄、黄瓜、小麦等的病害进行识别[2-3],取得了一定成绩。因作物种类繁多,同一类作物也会有多种病害发生,且病害特征呈现多样化、复杂化,所以至今还没有一种通用的病害识别方法,需针对不同的作物病害分别进行研究。在烟草生长期内有多种病害发生,每年造成的损失很大[7],病害防治是确保烟草产量和质量的关键技术之一。目前,烟草病害的识别主要通过人为判断,或通过书本、互联网、数据库等提供的烟草病害图片比对诊断,这对于非专业人员,往往会引起人为的误判,从而难以对症下药,造成烟叶质量下降。
本研究提出依据病害图像的病斑特征,构建实数编码遗传算法获取有效特征和支持向量机识别病害的模型以诊断烟草病害。以赤星病、野火病等4种常见又容易混淆的烟草病害图像诊断为例,通过分割彩色病斑、提取病斑特征,将提取的特征输入实数编码遗传算法优化特征和支持向量机识别病害的模型,特征通过模型,获得对应的权重,将前n个权重较高的特征向量值xi乘以对应的权重wi,即xi=wi·xi作为支持向量机的输入向量,支持向量机的分类精度作为遗传算法的适应度对个体进行评估,以在去除冗余特征的同时提高支持向量机的识别精度。试验表明,实数编码遗传算法选择病害特征比采用二进制编码及双编码具有更好的识别率和优势,构建的模型能很好地识别烟草病害,可为病害的科学防治和危害程度评价提供依据。
1材料和方法
1.1病害图像采集与硬件参数
本研究中所采集的图像来源于云南德宏潞西,在田间自然光照下,用Nikon D80数码相机(焦距18~20 mm,最大光圈f/3.5~f/5.6),采集4种烟草病害(野火病、炭疽病、赤星病、蛙眼病)500幅,以“jpg”格式存储在电脑中。
利用Intel(R) Pentium(R)CPU G3220@3.0GHZ处理器,内存4 G,硬盘500 G,在Windows 2007系统环境下用Matlab2009a软件编程实现图像增强、病斑分割、特征提取、特征筛选、病害识别等操作。
1.2研究方法
1.2.1图像预处理和病斑分割(1)图像预处理。为减少计算量和外界带来的干扰,在不损害病斑完整性的前提下,根据病斑所在的位置将图像由原来的3 872×2 592像素统一裁剪为800×600像素。由于图像是在田间自然条件下采集,难免会受采集设备、环境等因素影响,往往使采集到的图像含有噪声,若直接进行图像分割和特征提取,会给识别造成误差。为此本研究首先利用3×3矩形窗口对原图像进行中值滤波[8],以削弱或去除噪声,使病斑轮廓与细节更加清晰,利于后期病斑的分割和处理。
(2)颜色空间选择。在众多颜色模型中,因CIE L*a*b*模型符合人的视觉特征[9],与光线及设备无关,并且处理速度与RGB模型同样快,比CMYK模型快,还是一种均匀的彩色空间,适合于彩色图像的编辑和分析,所以本研究采用了CIE L*a*b*模型。从RGB空间到L*a*b*空间的转化,采用D65白点,其中Xn=0.950 456,Yn=1,Zn=1.088 754。
(3)彩色病斑分割。烟草病害图像由病斑区域和正常区域组成,而病斑区域与正常区域之间有明显的突变,即边缘,所以本研究的病斑分割,采用基于支持向量机与多特征选择的彩色病斑边缘检测方法分割[10]。通过在CIE L*a*b*颜色空间,计算图像亮度和色度通道的方差、均值差、最大梯度,以及位置像素对比度及均值色差作为特征向量,实现支持向量机对病斑边缘的识别,对识别出的病斑边缘,统计近似圆形且半径大于一定值的二值化区域,将区域内的所有像素赋值为“1”,再与原图进行“与”运算,从而获得病害图像的彩色病斑。这样分割既可以减少病害图像处理的信息量,又能描述病斑的形态特征,是进一步识别病害的基础。图1是采用上述方法对赤星病、蛙眼病和野火病图像分割的效果图。
1.2.2病斑区域特征提取(1)颜色特征提取。颜色是区分各种不同病害的重要特征,而颜色模型的选择会影响到病害识别效果。由于病害图像是在自然光照下拍的,为了消除亮度影响,采用颜色矩来描述颜色特征[11],因颜色信息主要集中在低阶,所以本研究在CIE L*a*b*颜色空间,提取L、a、b 3个分量的一阶矩σ和二阶矩σ2,共6个特征向量,其公式如下:
病斑数:E。主要用来计算病害图片上某种病害的病斑个数。endprint
病斑面积与病斑数比值:R=SE。该参数是单个病斑的面积度量,主要用于区分大病斑和小病斑。
1.3基于实数编码遗传算法选取病斑特征与支持向量机识别病害的模型设计
(1)模型介绍。支持向量机(support vector machine,简称SVM)[13-15]是Vapnik等于1995年根据统计学理论中结构风险最小化原则提出的一种模式识别方法。它在解决小样本、非线性及高维模式识别问题中表现出许多特有的优势。由于径向基(RBF)核函数的计算复杂度不随参数的变化而变化,且在全部参数空间满足Mercer条件,是SVM方法中最常用的核函数,因此本研究选择径向基核函数,其数学表达式为:K(x,y)=exp(-γ│x-y│2),其中x为输入特征值,y为特征值x对应的结果,γ为径向基核函数参数(γ>0)。
遗传算法(GA)是美国Holland教授于1975年提出的,是一种全局优化的随机搜索算法,特别适用于处理传统搜索方法难以解决的复杂和非线性问题[16-17]。遗传算法的思想源于生物遗传学和适者生存的自然规律,从一个随机产生的解群体出发,借助选择、交叉、变异等操作,依据适应度函数对个体的评价,使每一代中相对好的解替代前一代相对差的解,最终逼近全局最优解。将GA和SVM结合的目标是在去除冗余特征的同时,提高病害的识别精度。
(2)操作步骤。①编码。遗传特征选择的目标是去除冗余特征,选择最优特征子集,使得分类精度最大化。常用的编码方式是二进制编码,1表示选中,0表示未选中。本研究为了既得到特征子集,又能得到特征对应的权重,采用了实数编码方式。②初始群体。设特征个数为m,则实数编码的初始群体M(0)={Ci},(i=1,2,…,N),其中 Ci=wik,k=1,2,…,m。M(0)中的第1个染色体的每个基因都等于“1”,表示所有特征的权重都相同。其余(N-1)个初始染色体基因随机产生[0,1]之间的实数,表示随机生成(N-1)个特征加权子集。③选择适应度函数。适应度函数是针对需要解决的具体问题而设定的,目的是提高烟草病害的分类精度,所以采用支持向量机的分类精度对个体适应度进行评估。适应度函数 F=accuracy,其中accuracy为SVM分类器的分类精度。④遗传操作。a. 选择操作。将染色体按适应值从大到小顺序排列,适应值最大的染色体直接进入下一代,剩余染色体根据选择概率Ps按轮盘赌选择机制进行选择。b. 交叉操作。实数编码GA中的交叉操作常采用最大-最小-算术交叉方法和双点交叉。双点交叉操作的具体过程是:首先,将所有的父代个体进行两两组合,得到C2N个个体对;然后,就每对组合随机产生1个[0,1]之间的随机数 P,如果 P>Pc(Pc为交叉概率),则确定该组合将进行交叉操作,否则确定该组合将不进行交叉操作;最后,产生2个随机整数 a、d(0 wk=wk+μ(1-(1-tM)β),γ=0 wk+μ(1-(1-tM)β),γ=1。(7) 式中:t为迭代次数,是∈[0,1]间的随机数;M 是最大遗传代数;γ为1或0的随机数;β是突变参数。这种突变方法与遗传代数相关,使得在进化初期,突变的范围相对较大,而随着进化的推进,突变范围逐渐减小,对进化起着微调作用。 ⑤终止条件。终止条件采用最大进化代数或相邻进化代数最优个体适应值相对误差小于 0.001 相结合。分析新个体是否满足终止条件,若不满足返回第③步;若满足则终止。 ⑥染色体解码。迭代结束后,将具有最高适应度的个体作为优选结果,选出n个权重较大的项对应的特征为选中的特征,将这些特征挑选出来得到的特征集合就是选择的最优特征子集。 2结果与分析 2.1试验参数选定 以烟草生长中常见也最容易混淆的野火病、炭疽病、赤星病、蛙眼病4种主要病害为例。选择效果较好的子图300幅,其中以每种病害45幅(共180幅)做分类训练,以每种病害30幅(共120幅)做测试。根据上述方法,提取了颜色、纹理、形态共23个特征。分类器选用SVM的一对一投票策略实现烟草多种病害识别。共训练k(k-1)/2(k为类别数,取4)个二值分类器,在分类时采用了打分策略,分别用训练过程得到的k(k-1)/2个分类器进行测试,每个结果为1分,累计各类别得分,选择得分最高的为测试类别。试验参数为:(1)采用SVM中径向基核函数K(x,y)=exp(-γ│x-y│2)作为核函数,经多次试验其参数C=50、γ=0.125效果较好,输出采用十进制编码输出:0代表正常,1代表野火病,2代表炭疽病,3代表赤星病,4代表蛙眼病,共5个输出。(2)遗传算法的染色体长度m=23,群体大小P=20,交叉概率P01=0.9,变异概率P02=0.05,交叉因子γ=0.6,突变参数β=0.6,最大迭代次数G=400。(3)在Matlab2009a环境编程实现遗传算法(GA)和SVM算法,其中编写的SVM函数有:①MultiSVMtruct=MultiSVMTtrain(TrainData,nSamPerclass,nclass,C,γ),其中TrainData为训练数据,nSamPerclass记录每类的样本数,nclass为类别数;②Class=MultiSVMClassify(TestData,MultiSVMtruct),其中TestData为测试样本集,MultiSVMtruct 为多类SVM的训练结果。
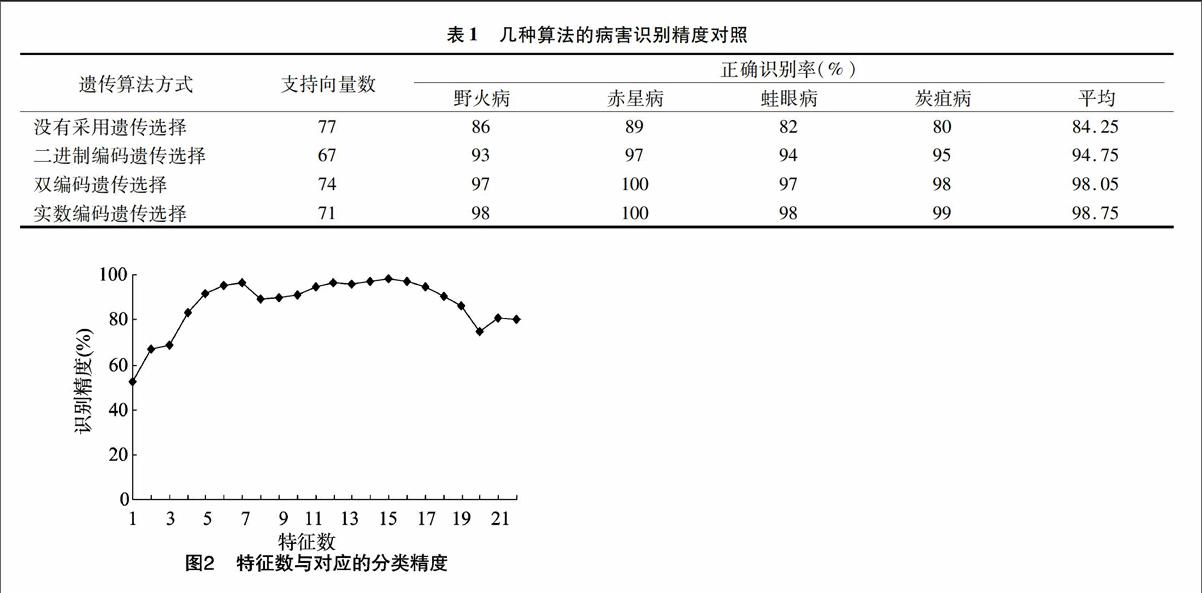
从提取的23个烟草病斑特征中选取对病害识别贡献高的n个特征子集。遗传操作结束后,用n个对应特征向量值乘以特征权重Wi∈[0,1],即Xi=Wi·Xi作为支持向量机的输入向量,其特征数与对应的分类精度如图2 所示。从图2看出,当特征数为15时,分类精度最高,其特征项分别为:颜色A={σL,σa,σb,σa2,σb2},纹理B={ mean f1,sqrt f1,sqrt f2,mean f3,mean f4,mean f5},形态C={S,Ct,St,E,R},对应权重分别为:0.325、0.531、0.774、0.452、0.631、0.168、0.280、0.564、0.198、0.202、0.147、0.471、0.612、0.432、0.271、0.741。
2.2识别结果
表1是几种算法的对照。从表1可得出:本研究算法与没有采用遗传特征选择相比,在特征向量只有原来的92%的情况下,精度却提高了14.5百分点;与采用二进制编码遗传算法优化特征相比,其识别精度高出4百分点;与采用双编码遗传算法[18](同时采用实数编码和二进制编码)优化特征相比,识别精度高出0.70百分点;本研究算法获取的特征数是16,二进制编码遗传算法的为18,双编码遗传算法的为17。表1几种算法的病害识别精度对照
遗传算法方式支持向量数正确识别率(%)野火病赤星病蛙眼病炭疽病平均没有采用遗传选择778689828084.25二进制编码遗传选择679397949594.75双编码遗传选择7497100979898.05实数编码遗传选择7198100989998.75
由上述得出本研究算法在获得有效特征的同时获取了特征的权重,并降低了时间及空间复杂度。
3讨论
以烟草4种常见病害(野火病、赤星病、蛙眼病、炭疽病)病斑图像为研究对象,应用实数编码遗传算法可以去除冗余特征,还能获得对识别病害贡献多少的权重,并用支持向量机对4种病害进行识别,结果表明利用基于支持向量机与多特征选择的彩色病斑边缘检测方法能有效提取出4种病害的病斑。
在病害特征优化和识别精度方面,用同样的样本和模型训练方法,分别用提取的全部特征直接用支持向量机识别,其平均识别精度为84.25%;用二进制遗传算法优化特征和支持向量机识别病害,优化后特征数减为18个,平均识别精度为94.75%;用双编码遗传算法优化特征和支持向量机识别,优化后特征数减为17个,平均识别精度为98.05%;用本研究的方法,实数编码遗传算法优化特征和支持向量机识别病害,优化后的特征数减为15个,平均识别精度为98.75%,从而得出本研究的方法除了能提高识别精度外,还能降低时间和空间复杂度。
本研究的方法可以实现烟草野火病、赤星病、蛙眼病、炭疽病的计算机自动识别,并且可以应用到其他农作物的病害识别中。但是本研究还仅针对烟草4种常见典型病害的叶部危害特征进行研究,这对于实际应用还不够,因为在整个烟草生长期,在不同阶段根、茎、叶等都会染病,且各个部位的病害表征不尽相同;农业与化工污染也可能对烟株造成损害形成类似病斑的斑点,所以还需逐步增加病害和受害种类的研究。此外,支持向量机和遗传算法作为一种有监督的模式识别方法,在特征向量和参数的选择研究上仍然是下一步需加强的工作。参考文献:
[1]管泽鑫,唐健,杨保军,等. 基于图像的水稻病害识别方法研究[J]. 中国水稻科学,2010,24(5):497-502.
[2]李冠林,马占鸿,王海光. 基于支持向量机的小麦条锈病和叶锈病图像识别[J]. 中国农业大学学报,2012,17(2):72-79.
[3]田有文,李天来,李成华,等. 基于支持向量机的葡萄病害图像识别方法[J]. 农业工程学报,2007,23(6):175-180.
[4]蔡清,何东健. 基于图像分析的蔬菜食叶害虫识别技术[J]. 计算机应用,2010,30(7):1870-1872.
[5]李冉,赵天忠,张亚非,等. 基于遗传特征选择和支持向量机的图像标注[J]. 计算机工程与应用,2009,45(6):180-183.
[6]Rough Z. Sets and intelligent data analysis[J]. Information Sciences,2002,147(1/4):1-12.
[7]陈永德,覃春华. 烟草常见病害的田间诊断[J]. 湖南农业科学,2010(18):20-22.
[8]张铮,王艳平,薛桂香. 数字图像处理与机器视觉——Visual C++与Matlab实现[M]. 北京:人民邮电出版社,2010:156-162.
[9]Koschan A M. 彩色数字图像处理[M]. 北京:清华大学出版社,2010:124-162.
[10]濮永仙. 基于支持向量机与多特征选择的农作物彩色病斑边缘检测[J]. 计算机系统应用,2014(9):118-123.
[11]Lindgreen R,Herschberg I. On the validity of the Bell-LaPadula model[J]. Computer & Security,1994,13:317-338.
[12]Haralick R M,Shanmugam K,Dinstein I. Textual features for image classification[J]. IEEE Trans Syst Man Cybernet,1973,3(6):610-621.
[13]Mazzoni D,Garay M J,Davies R,et al. An operational MISR pixel classifier using support vector machines[J]. Remote Sensing of Environment,2007,107(1/2):149-158.
[14]Burges C C. A totorial on support vector machines for pattern recognition[J]. Data Mining and Knowledge Discovery,1998,2(2):121-169.
[15]Steve R G. Support vector machines for classification and regression[R]. Southampton:University of Southampton,1998:1-28.
[16]Oh I S,Lee J S,Moon B R. Hybrid genetic algorithms for featureselection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(11):1424-1437.
[17]Hamdani T M,Alimi A M,Karray F. Distributed genetic algorithm with Bi-coded chromosomes and a new evaluation function for features selection[C]//Evolutionary Computation,2006. CEC 2006. IEEE Congress on,2006:581-588.
[18]濮永仙,余翠兰. 基于双编码遗传算法的支持向量机作物病害图像识别方法[J]. 贵州农业科学,2013,41(7):187-190,194.endprint
