基于数据挖掘的教学评价系统设计与开发
2015-10-19方芳张澎
方芳 张澎

摘要:该文将针对教师教学评价系统开发和使用中存在的主要问题,如数据处理不合理,功能不完善等问题进行分析,提出联机分析处理技术、利用数据仓库技术和数据挖掘技术,对要评测的数据进行采样分析处理。重点讨论以CART算法为中心的决策树生成算法,利用其属性的相关性并对算法进行了相应的改进。测试数据证明:改进后的算法对所生成的规则集的数量和大小有优化作用,有效地缩短处理的时间,使用改进后的算法,对教学评价数据进行知识挖掘,得到决策规则,用以辅助学校相关决策的改进和制定。
关键词:数据挖掘;教学评价;联机分析处理;决策树
中图分类号:G642 文献标识码:A 文章编号:1009-3044(2015)20-0001-03
Design and Development of Teaching Evaluation System that Based on Data Mining
FANG Fang,ZHANG Peng
(Department of Compute Science, Xiangnan University, Chenzhou 423000, China)
Abstract: On account of the low degree of automation and scientific data processing in existing teaching evaluation system, the data warehouse technology, online analytical processing as well as data mining techniques can be used for the evaluation of the data sampling processing. With focusing on the CART (Classification and Regression Trees algorithm) based decision tree generation algorithm, made use of its properties related to overcome shortcomings of it and then improve the algorithm itself. Through tests to demonstrate the improved algorithm can effectively shorten the processing time and reduce the size and number of the generated rule sets. By taking advantage of the improved algorithm, to help data mining on knowledge of teaching and then using generated decision rules to improve school-related decision-making and formulation.
Key words: data mining; teaching evaluation; online analytical processing; decision tree
1 概述
数据仓库和OLAP技术在教学管理系统中的实际应用是在最近才被关注。目前相关的研究主要集中在如何去构建学校的数据仓库,利用OLAP技术对数据进行处理和分析,怎样以学校内部各个数据库中的相关数据为基础,其目的是提高学校的教育能力和水平。
文献[1]主要讨论了粗糙集的基础理论用于教学评价数据处理地方法和决策树分类挖掘,为了让算法再好的应用于所开发的系统中,对ID3数据挖掘算法进行了改进,使其能更好的实现辅助决策功能。文献[2]分析了一种基于用户举的权重推荐模型,以此模型为基础对关联规则算法进行改进从而提出MWFP算法。文献[3] 对各种影响教学水平提高的原因及教学评价的各项指标进行了分析,使用数据挖掘的方法影响和提示教师教学水平因素构建的教学评价决策树模型。文献[4]其OLAP解决方案采用的是ORACLE业务智能系统采用B/S架构方式,能够方便维护和部署。
本文通过OLAP技术可以发现教学评价结果和教师性别、学历、年龄、教龄、职称之间的关系,教师性别与学生异同对评价结果的一些影响,学生考试成绩和评测结果与学生基本信息之间的关系等。通过改进的CART决策树生成算法进行数据挖掘,寻找出教学评价过程中各元素与教学评价结果之间的关系。
2 CART决策树数据挖掘的算法和改进
CART算法是决策树算法的典型代表,采用的策略是先生成二叉决策树,然后进行修剪处理。二叉树的生成采用好的方法可以提高决策树生的效率,在分类准确性的基础上修剪处理又可以减小决策树的规模,进一步提高了可应用的范围和理解性。了进一步简化决策树的结构,在CART的基础上又提出了一种基于属性归约的CART算法。为了方便用户根据自身实际需求调整阈值,有更高的决策准确率,CART算法还考虑了决策属性和测试属性之间的联系,用专业的分类经验作指导,加快了决策树的分类的阈值可调和生成。
通过改进后的CART决策树算法步骤如下:
1)对于训练数据进行预处理应用与选择目标关系密切的数据集体,对“脏数据”进行清理生成符合CART算法处理的数据集。
2)如果待处理数据通过决策树中间节点的属性判别被认为是大于某决策阈值,则此阈值的分支处生成一个叶子节点进行标注。
3)对全部测试数据属性进行分析计算得到决策属性和每一个测试属性之间的相关性。
4)选择相关度比较小的测试属性集test_attribute。
5)假设D为数据样本集合,对其每一个样本数据去除test_attribute。
6)调用CART(D)进行一些处理。
针对改进后的CART算法性能进行分析,其方法是利用UCI实验数据库中的根本依次使用改进后的CART算法和常规CART算法进行处理,分析处理后的结果证明改进算法的有效性。
无关属性对于决策树算法准确率与效率的影响比较大。通过实验证明,在标准的数据集中增加一个无关的二值属性使决策树生成算法的性能显著下降,所有在应用决策算法之前,需要对属性集进行数据缩减处理和减少数据维数,提高算法的效率和准确率。
实验数据基本特征,如表1所示:
表1 实验数据特征描述
[数据库名称\&样本总数\&属性个数\&类别个数\&Balloons\&85\&4\&2\&Mushroom \&8223\&24\&2\&Breast-cancer\&277\&8\&2\&promoters\&157\&58\&2\&]
从执行时间上看,改进后的CART算法优于普通CART算法,改进的CART算法在进行决策树生成之前,对样本数据进行了处理去除与目标相关性不大的属性提高决策树的生成效率。对比常规CART算法和改进后的CART算法,针对每一数据集处理的准确率和时间。在具体对比实验中,对于不同的数据库采用了不同的分类阈值。
表2 实验结果
[数据库名称\& CART算法\&改进后的CART算法\&采用分类阈值\&执行时间\&准确率\&执行时间\&准确率\&Balloons\&70.5%\&0.1\&76.94% \&0.06\&71.1%\&Mushroom\&80%\&0.16\&99.01%\&0.15\&97.25%\&Breast-cancer\&70%\&0.06\&67.12%\&0.04\&70.26%\&promoters\&80%\&0.05\&76.41%\&0.05\&80.18%\&]
在决策树构建过程中,判断和分析某一节点上属于某一类的数据样本值比例,如大于设定的阈值则停止分类,生成最终决策节点,这一处理方法可以提高决策树建立和后修剪过程。与传统CART算法相比较,改进后的CART算法增加了构建决策树之前的数据处理操作,以目标与属性之间的相关性为指导分析,去除样本数据中与决策目标无关或相关性不强的属性,使生成决策树的数据更加简洁提高了生成效率。
3 数据挖掘处理过程
基于CART决策树方法的数据挖掘,主要的目标是研究教学评价过程中,各个不同的指标与最终教学评价结果之间的关系。整个过程需要经过四个阶段:数据预处理,决策树生成,规则生成,准确性评估。
3.1 数据准备和预处理阶段
数据挖掘的基础和对象是数据仓库中的数据。在教学评价系统中,以教学评价结果数据库表为分析对象,研究不同的评价指标与最终评价结果分类之间的关系,因此,在数据准备阶段,主要是从教学评价结果表中提取的评价结果数据,具体如图1所示:
图1 数据挖掘数据源表
3.2 决策树生成的阶段
通过改进后的CART算法从预处理数据中抽取了5112的个样本数据来构建决策树,然后对经过预处理后的数据进行了相应分析,包括了1个结果类项Total和10个影响因素项。各个属性项的取值与相关信息被存储到文件中供CART算法调用。
3.3 模型准确性的评估
常用的分类准确性评估技术的方法主要有两种,分别是保持和确认交叉。本文所研究的“教学评价指标——分类”模型主要是对在线学习进行形成性评估成绩界定的,要满足以下两个要求:
1)对于大小不一样的样本集的成绩评估具有比较好的稳定性;
2)模型(分类规则集合R")在成绩评估上有一定的准确性。
表3 测试数据集的评估结果表
[测试样本
被分类别\&该分类样本数\&原类别为
A的样本数\&原类别为
B的样本数\&原类别为
C的样本数\&原类别为
D的样本数\&分类
正确率\&A\&1895\&1743\&121\&26\&5\&91.98%\&B\&3629\&183\&3240\&171\&35\&89.28%\&C\&3587\&33\&223\&3103\&228\&86.51%\&D\&889\&9\&45\&70\&765\&86.06%\&总计\&10000\&1969\&3628\&3371\&1032\&88.46%\&]
将采用保持方法对模型进行准确性的评估。
通过对教学评价进行的数据分析,本文设定了10个描述教学评价的指标项目,建立数据挖掘的“教学评价指标——分类”模型分析表。
分类结果的准确性测试:表3所示。
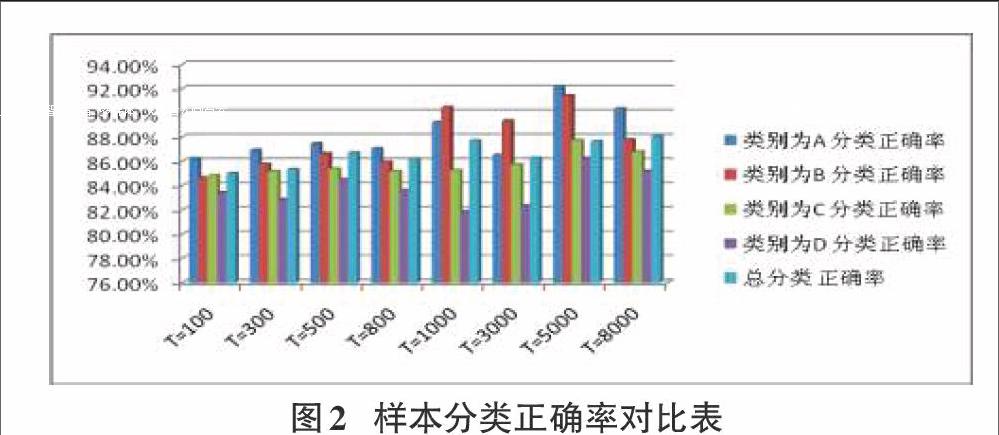
图2为样本分类正确率的对比表。
图2 样本分类正确率对比表
对“教学评价指标——分类”模型分析得出以下结论:
评估结果权重比由大到小的教学指标依次是: TEffect:教学效果;TMethod:教学方法;TContent:教学内容; TAttitude:教学态度;CAura:课堂气氛;TSpeake:教学讲课; HomeWork:作业指导;TWrite:板书情况; TAppear:教师仪表;TStock:备课情况。
根据数据挖掘与分析,得到八条准确率最高的教师教学评价评估标准规则:
1、if TEffect<9, then total=”差”;
2、if TEffect >9 and TEffect <9.5 and TMethod>9 and TMethod<9.5 and TAttitude<9, then total=”中”;
3、if TEffect >9 and TEffect <9.5 and TAttitude<9 and TContent>9 and TContent<9.5, then total=”中”;
4、if TEffect >9 and TEffect <9.5 and TContent>9 and TContent<9.5 and TMethod<9 and TAura>9.5, then total=”中”;
5、if TEffect>9.5,TMethod>9.5, then total=”优”;
6、if TEffect >9 and TEffect <9.5 and TMethod>9 and TMethod<9.5 and TContent>9.5, then total=”优”;
7、if TEffect >9.5 and TMethod>9 and TMethod<9.5 and TAttitude >9.5, then total=”优”;
8、if TEffect >9 and TEffect <9.5 and TMethod>9.5 and TContent>9.5, then total=”优”;
4 规则分析
根据以上数据挖掘得到规则分析如下:
规则一说明,教学的效果是评价教师教学水平的最为重要的标准,由于教学效果是一个综合性的指标,该指标如果不到9分,则教师的教学水平一定为是“差”。
规则二说明,在教学效果达到9分以上时,如果教学方法可以有良好的表现,则教学态度即使不到9分,教学水平可被评定为“中”,说明了教学方法的重要性。
规则三说明,在教学效果达到9分以上时,如果教学内容达到良好,而教学的态度不足9分,教师的水平被认定为“中”,提醒教师要注重平时的教学态度,不能让学生产生逆反心理。
规则四说明,在教学效果达到9分以上时,教学内容达到良好,课堂气氛得分在9.5以上时,即使教学方法小于9分,教学水平可被评价为“中”,教师注意课堂气氛的活跃。
规则五说明,当教学效果和教学的方法都达到9.5分以上时,教师的教学水平可被认定为“优”,要求教师提高教学效果和方法。
规则六说明,在教学效果和教学方法的得分都处于9分到9.5分之间时,如果教师的教学内容突出,则其教学水平可被认定为“优”。
规则七说明,在教学效果达到9.5以上,教学方法处于中等水平时,如果教学态度较好,则可被认定为“优”,说明学生对和蔼可亲的教师较为认可。
规则八说明,如果教学效果处于中等水平,教学方法较好的情况下,如果教学内容比较精彩,则其教学水平的认定为“优”,说明精彩的教学内容更容易吸引学生。
5 结论
根据数据仓库构建的流程和联机分析处理的过程,结合决策树数据挖掘算法,设计并开发了基于数据挖掘的教学评价多维处理系统。改进后的CART算法能有效地缩短处理的时间并减少所生成的规则集的大小和数量。
参考文献:
[1] 韩成勇.基于数据仓库技术的高职院校学评教数据分析决策支持系统的设计与实现[J].科技信息, 2009(26): 215-216.
[2] 胡海员. 数据仓库与数据挖掘技术在招生决策中的应用研究[D].南京: 东南大学, 2006.
[3] 袁华. 基于OLAP技术的高校决策系统研究与设计[D]. 上海:复旦大学, 2010.
[4] 卢晶晶. 基于数据挖掘的教学评价系统.[D]. 南京: 河海大学, 2009.
[5] Yonatan Aumann, Yehuda Lindell, Journal of Intelligent Information Systems, A Statistical Theory for Quantitative Association Rules, 2010,20(3):255-283.
