基于改进SALS算法的大数据挖掘效率优化探究
2015-10-18黄少卿胡立强中国移动通信集团设计院有限公司河北分公司河北石家庄050021
黄少卿,胡立强(中国移动通信集团设计院有限公司 河北分公司,河北 石家庄 050021)
基于改进SALS算法的大数据挖掘效率优化探究
黄少卿,胡立强
(中国移动通信集团设计院有限公司河北分公司,河北石家庄050021)
移动互联网时代,各类移动网络终端的使用在为移动用户带来便利的同时,也为运营商提供了海量的可供挖掘数据来源。运用大数据技术对非结构、半结构、结构化数据进行数据挖掘,可以有效提高挖掘效率,帮助运营商找到潜在商机、提升用户体验、进行精确营销。针对大数据挖掘中存在的效率问题,提出了基于改进SALS算法的Hadoop推测调度,从而减少异构环境下的资源浪费,提高大数据挖掘效率。
大数据挖掘;Hadoop;推测调度;SALS
0 引言
移动互联网时代,随着3G/4G的普及,网络建设速度的加快,以及大规模的数码设备的使用,移动运营商业务和数据规模的扩张呈几何级增长[1]。以某省的基本数据量为例,其语音通话记录每天入库2.5TB,SMS话单记录每天入库800GB以上,MC口信令数据每天20TB,GN口信令数据每天8TB,警告、性能等数据每天约3TB。再计算通过机器设备、服务器、软件自动产生的各类非人机会话数据,以非结构和半结构化形式呈现的数据已经远远超过了传统关系型数据处理的能力范畴。
传统的RDBMS可以处理结构化数据,其缺点是系统孤立、处理数据量小,面对移动互联网时代数据暴增的特点,IT系统的可扩展性、成本控制、数据有效性挖掘均需要通过低成本的通用设备,通过构建“池化资源”并结合“大数据挖掘”能力来推进业务进展。
池化资源指通过运用虚拟化技术,将单个物理机器资源进行分割或者将多台物理机器资源进行整合,充分利用物理机的处理能力,实现物理机的高效分配和利用[2]。大数据挖掘则针对具有4V特点的海量数据进行压缩、去重、整理、交叉分析和对比,并结合关联、聚合等传统数据挖掘技术对非结构化和半结构化的数据进行分析[3]。本文通过对现有大数据挖掘技术的分析比对,就其中涉及的数据查询的可优化部分进行深入讨论。
1 现行的大数据挖掘技术
自大数据概念诞生以来,陆续出现了多种大数据挖掘处理技术,如果以处理的实时性来分类,可以将大数据挖掘处理技术分为两类:实时类处理技术和批处理技术。实时类大数据挖掘处理技术有Storm、S4[4]等,而批处理技术或者称为线下处理技术的典型代表则是MapReduce。对于移动运营商来讲,实时处理能力固然重要,但是通过大批量的线下数据处理找到潜在的商业契机、提升用户体验、实施决策分析、精准营销推荐、运营效能提升、创新商业模式等对于运营商来说更为重要。本文关注大数据批处理中现有技术的性能提升。
1.1MPP架构新型数据库技术
MPP(Massive Parallel Processing)从构成上来讲,是由多个SMP服务器横向扩展组成的分布式服务器集群[5]。但MPP架构并不是一种池化资源的大数据处理架构,集群中的每个节点均可访问本地资源,采用Share Nothing结构,集群节点之间并不存在共享及互访问的问题,而是通过统一的互联模块来调度、平衡节点负载和并行处理过程。其架构如图1所示。
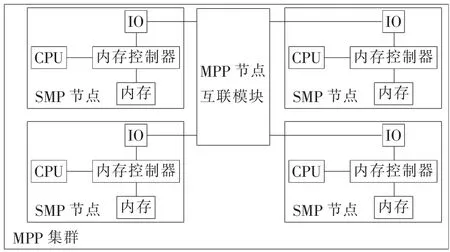
图1 MPP服务器架构图
1.2大数据一体机
大数据一体机是商业公司专门为处理大数据而设计的软硬件一体机,由集成服务器、存储、操作系统、数据库软件、其他数据分析软件等统一封装在机箱内,经过运营商对数据处理流程进行优化,从而形成高性能的大数据处理能力。
1.3Hadoop开源大数据技术
Hadoop技术框架是以MapReduce为核心的一个开源大数据处理框架,其架构如图2所示。其中,最底层的HDFS为分布式文件系统,底层使用廉价x86进行冗余备份;MapReduce分为map、shuffle和 reduce阶段[6],map阶段对处理数据进行分解映射,分开处理,shuffle阶段拽取map阶段数据到reduce端,reduce阶段对处理子集进行归约合并,得到处理结果;HBase不同于传统的关系型数据库,是一种基于列的分布式数据库。
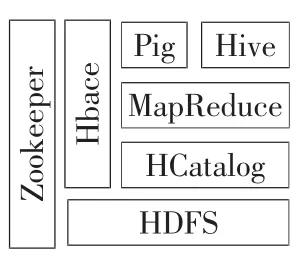
图2 Hadoop服务器架构图
1.4小结
三种大数据挖掘处理技术各有特点,综合比较如下:根据CAP理论,在兼顾分区性、一致性和分区可容忍性的情况下,MPP扩展能力有限,目前最多可以横向扩展至500个节点,并且MPP成本较高,以处理结构性重要数据为主。大数据一体机环境封闭,例如Oracle的ExtData,技术实现细节不清晰,在处理性能上难以做出横向对比,且成本高,这里暂不做讨论。Hadoop以处理非结构化和半结构化数据为主,横向扩展能力达到1 000个节点以上,并且支持厂家和社区庞大,成本低廉,是一项较好的大数据挖掘框架技术。
2 现行的Hadoop推测调度对大数据挖掘的影响
采用Hadoop开源框架进行大数据挖掘,具有较多的便利条件:Hive的使用可以简化数据挖掘程序的编写,只需要掌握普通SQL操作即可进行程序编写;基于HDFS和MapReduce的分布式特点,数据挖掘任务可以在多台机器、不限地域的情况下实施,缩短了挖掘时间,提高了挖掘效率。但是,Hadoop对分布式任务进行推测调度的算法上存在效率问题[7],下面对该调度进行概要分析。
(1)为防止任务因机器故障、程序意外中断引起的任务执行时间过长,Hadoop启用了推测调度,即启用新节点对卡壳任务进行重新执行;
(2)对于每一个运行在节点上的Task,其执行剩余时间=(1-当前进度)/任务平均计算速度,其中任务平均计算速度=当前进度/执行时间;
(3)根据(2)对所有Task执行剩余时间进行排序,选出最大的 Task,若其平均计算速度<其他任务平均速度,则对该任务进行推测,启用新节点执行该节点的任务;
(4)当推测节点任务执行完毕后,强制结束执行同任务节点进程。
上述过程在同构环境且多任务运行的情况下,可以一定程度地避免硬件故障及程序bug对整个MapReduce的影响。但其存在如下可能的推测调度缺陷:(1)由于启动新节点重复执行某任务,会造成同时存在两个以上节点执行同样任务,造成资源浪费;(2)当在异构环境下(硬件机器厂商不同、运行操作系统差异、机器性能差异等),任务节点的资源性能并不等同,以上述标准判断是否需要启动推测调度,会出现较大误差,形成无效的调度,从而使新任务得不到节点来执行任务;(3)Hadoop针对Reduce阶段任务划分为复制、排序、归并,并规定每一阶段占据1/3进度;然而,统计表明,复制阶段最消耗时间和资源,明显存在不合理调度。
针对这些问题,本文在SALS算法基础上进行改进,从而提高Hadoop的推测调度效率,减少重复任务,加快MapReduce的执行。
3 采用改进SALS算法对Hadoop推测调度调优
SALS算法原本用于邻近节点搜索,首先确定节点集合,然后根据权重与节点间举例建立联系图。这里,选取节点集合节点的判定,在第二阶段根据Hadoop的推测调度进行修改。
(1)对所有运行Task节点进行排队,形成TaskQueue,该队列保存Slave节点任务的索引,以节省空间;
(2)根据历史平均速率,对空闲节点进行排队,速率高节点在队列头部,从未运行过节点速率为所有空闲节点平均速率,插入到队列中,形成FreeQueue;
(3)对TaskQueue进行动态排队,每1分钟1次,并对队尾节点进行判定:
(a)运行时间超过其他节点运行时间的1.5倍;
(b)若为非Reduce任务,任务进度与上次更新差别在10%以内;
(c)若为Reduce任务,根据shuffle数据量更新进度,任务进度与上次更新差别在10%以内。
(4)符合(3)-(a)且符合(3)-(b)或(3)-(c)时,对队尾任务启动新节点进行执行,立即结束当前节点并做标记,形成BugQueue以备检查节点状态。
4 实验验证
为检验上述算法的有效性,启用1台机器作为主节点(2GB内存,80GB存储,Ubuntu OS),4台机器作为从属节点(分别为1GB、256MB、256MB、512MB内存,两个Ubuntu OS,两个Red Hat OS)进行试验。先后部署Hadoop环境和改进推测调度的Hadoop环境进行验证,结果如图3所示。
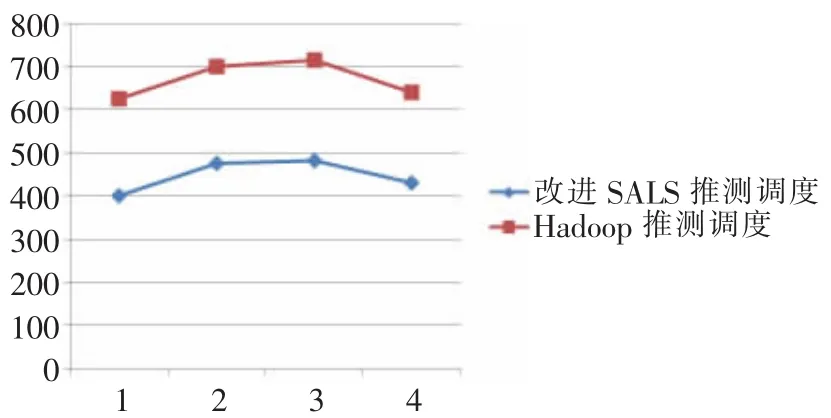
图3 推测算法验证
实验表明,基于改进的SALS推测调度相较于基础Hadoop推测调度能提高40%左右的时间,达到了改进目的。采用该改进的SALS算法后,可以减少重复任务的执行数量并及时释放可能存在问题的节点以备检查。合理更新Reduce任务进度,减少出现活跃任务节点被关闭现象。加强推测调度的准确性,对节点资源进行高效利用,提高了大数据挖掘的效率。
5 结论
移动互联网时代,大数据技术在数据挖掘方面所起的作用越来越重要。针对其中可以优化改进的流程和技术环节还有许多可以深究之处。基于改进的SALS算法优化的推测调度,在流程方面优化了大数据挖掘,提高了Hadoop推测调度的准确性和有效性。除此之外,大数据查询优化、大数据不同架构之间的融合使用等均值得进一步研究。
[1]马建光,姜巍.大数据的概念、特征及其应用[J].国防科技,2013,34(2):10-17.
[2]葛中泽,夏小翔.基于资源池的数据访问模式的探讨[J].科学技术与工程,2012,12(33):9066-9060.
[3]吉根林,赵斌.面向大数据的时空数据挖掘综述[J].南京师大学报,2014,37(1):1-7.
[4]孙朝华.基于Storm的数据分析系统设计与实现[D].北京:北京邮电大学,2014.
[5]辛晃,易兴辉,陈震宇.基于Hadoop+MPP架构的电信运营商网络数据共享平台研究[J].电信科学,2014(4):135-145.
[6]张常淳.基于MapReduce的大数据连接算法的设计与优化[D].合肥:中国科学技术大学,2014.
[7]周扬.Hadoop平台下调度算法和下载机制的优化[D].长沙:中南大学,2012.
Research on optimization of big data mining based on SALS algorism
Huang Shaoqing,Hu Liqiang
(China Mobile Group Design Institute Co.,Ltd.,Shijiazhuang 050021,China)
In the Mobile Internet age,all kinds of network terminals bring convenience to the users and provide huge amount of data.Using Big Data technology to mine all the non-structured,half-structured,and structured data.The mobile operators could find potential business model,improve user′s experience and make accurate sale.Aiming at solving efficiency problem in Hadoop speculation scheduling,this paper proposes an improved SALS algorithm to reduce resource wasting and improve big data mining efficiency.
big data mining;Hadoop;speculation scheduling;SALS
TP311
A
1674-7720(2015)12-0011-03
2015-01-09)
黄少卿(1988-),通信作者,男,硕士,系统分析师,主要研究方向:软件工程、Web数据挖掘、IT支撑系统。E-mail:leo12_leo@163.com。
胡立强(1975-)男,硕士,高级工程师,主要研究方向:移动通信支撑网、IP承载网等。
