基于Nutch框架的农业信息垂直搜索引擎研究与设计
2015-10-13高亮亮等
高亮亮等


摘要:针对当前农业搜索引擎存在的查不全、查不准、死链等问题,在分析中国使用率比较高的农搜、搜农、华农在线和中国农业信息网站等搜索引擎的基础上,提出了基于Nutch框架的农业信息垂直搜索引擎。该搜索引擎对农业词语进行分类,并构建专门的农业词典,提高查询速度。此外,基于Nutch框架的搜索引擎采用了改进的PageRank算法对网页进行排序得到权值最高的网页,呈现出具有价值搜索结果,达到初步的搜索结果的预期目标。
关键词:Nutch框架;农业搜索引擎;农业词典;设计
中图分类号:TP391.3 文献标识码:A 文章编号:0439-8114(2015)18-4603-04
DOI:10.14088/j.cnki.issn0439-8114.2015.18.055
随着农业信息化的发展,农业信息出现了爆炸性增加的局面,搜索引擎成为了必不可少的搜索工具,是人们进行信息收集的必要手段之一。当前农业信息量达到了百TB量级,面对如此多的农业数据,如何快速、有效地获取个性化的农业知识和信息资源就成为了当前农业信息搜索中迫在眉睫的问题[1]。近年来,伴随着农业信息化的推进,各类的农业搜索引擎逐渐发展,虽然能够基本满足当前农业发展的需要,但还需要进一步发展专题农业信息检索。
1 农业搜索现状
目前,农业领域中已存在1万多个各类网站,网页数量超过200多万[2],刘艳华等[3]对谷歌、百度和中国搜农3个搜索引擎在农业领域中进行了分析对比,表明了综合搜索引擎在搜索功能、结果、信息量等方面存在明显的优势,但是在农业内容的专业化、内容时效性方面存在欠缺。
中国也有许多农业类搜索引擎,如农搜、搜农、华农在线、中国农业信息网站等搜索引擎。农搜网采用的是独特的智能页面技术,实现网页信息的结构化索引,将使用者所查询的结果以农业科研单位、农业专家人才、农业实用技术等分类呈现,实现了农业信息的大众化和个性化服务,为急需农业科技信息和市场信息的企业、部门、农户精确获取农业信息提供了有益的工具。搜农网采用的是基于网页主体内容的索引,其优点是加快信息的更新速度,提高信息的查全率和查准率,建立了全新的复杂自适应搜索模型,开发并部署了6 200多个软机器人承担WEB农业信息的采集、清洗、分类、聚类、排序、发布等系列工作,基本实现了WEB信息处理工作的自动化,代替了农业信息服务采、编、发等系列繁重的人工劳动,大大降低了农村网络信息服务成本。华农在线实现了在农业行业的垂直搜索应用,将起到整合现有互联网涉及的各类和各行业主管部门的农业信息资源;实现满足涉农人员的个性化信息需求;提供专业知识问答及其推送功能;组织农业专家答疑,开展学术论坛;建立农业物流、农产品价格、其交易平台及与外国交流的行业平台。
这些农业搜索引擎虽然可以满足用户的一般需求,但是也存在一些问题,查全率和查准率低以及存在死链的现象,使得用户搜索的结果不全面、不准确或网页打不开,难免会使用户受到其他信息的干扰或对搜索引擎的不满。张彧[4]将Nutch搜索引擎应用到农业信息搜索中进行了初步的研究,将Nutch搜索引擎扩展到农业信息搜索中。本研究将Nutch搜索框架应用于农业信息搜索中,建立了基于Nutch搜索框架的农业信息垂直搜索引擎,并将当前农业词语进行分类,建立专业的农业词典,将网页农业信息进行精确分类,可以使用户得到更加准确和实用的查询信息。
2 Nutch搜索引擎
Nutch是Apache的项目之一,是以Java语言作为实现手段及开发工具,作为一个完全开源的搜索引擎包,广泛应用于局域和广域网络的搜索引擎,Nutch搜索引擎的流程(图1)。
3 农业搜索引擎的设计与实现
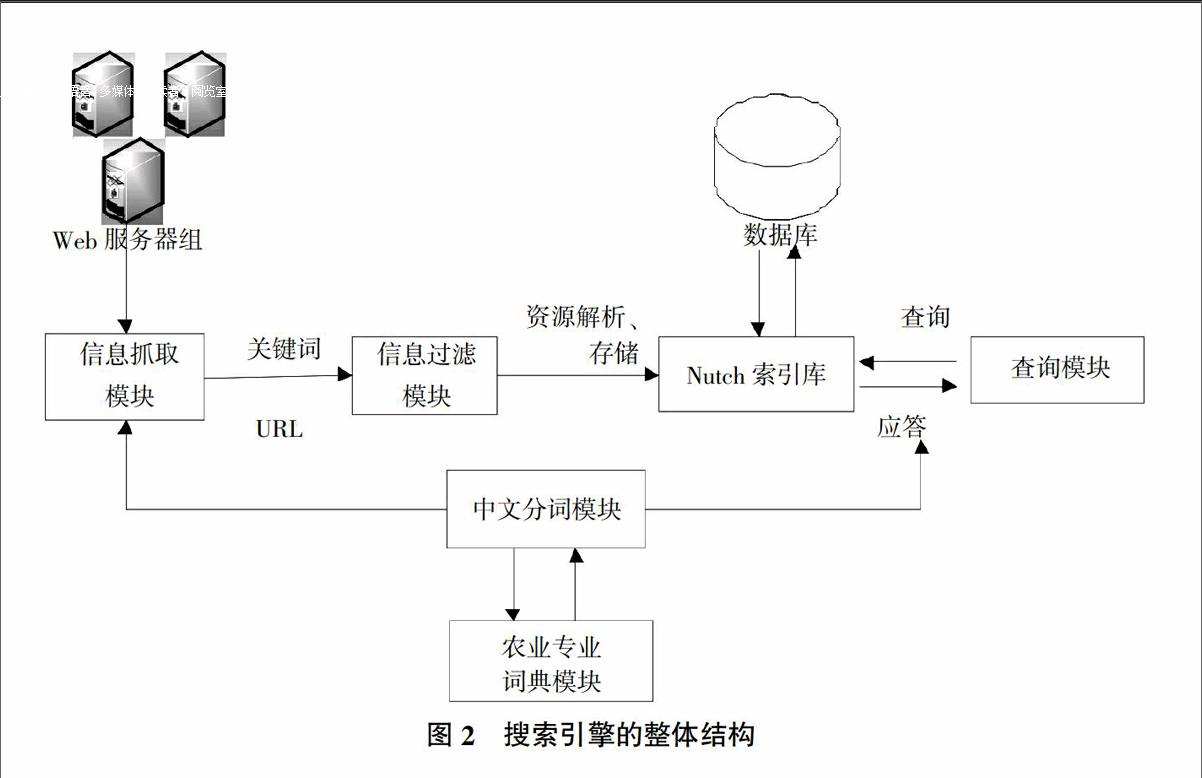
Nutch搜索引擎具有良好的框架结构,为农业搜索引擎的设计带来了便捷,在此结构基础上设计不同的插件,实现引擎的功能。本研究设计的整个搜索引擎分为信息过滤模块、信息抓取模块、中文分词模块、农业专业词典、索引存储模块和查询模块6大主要模块,如图2所示。
3.1 功能结构
根据当前农业发展和农业搜索引擎的现状,本研究提出了基于专业农业词典的搜索引擎,整个搜索引擎包含6个主要模块:信息过滤模块、信息抓取模块、中文分词模块、农业专业词典、索引存储模块和查询模块。其中,信息抓取模块、索引存储模块、查询模块是基于Nutch搜索框架中已存在的模块所实现的。根据农业搜索的专业主题要求设计开发了信息过滤模块、农业专业词典模块以及查询模块中排序算法的改进,能够更好地满足农业专题搜索的要求
3.1.1 农业信息过滤模块 该模块的功能是过滤农业网站中不相关网页和链接,爬虫会分析网站的URL,将URL当中的前后缀去除,提取出关键字。根据专业农业词典进行过滤,将无关URL和网页链接剔除,然后将这些相关的网页内容(网页的title、摘要、正文等)进行提取(网页的title、摘要、正文等),将所有非结构化的网页内容进行结构化,利用与农业专业词典相结合对所提取内容关键词出现频率进行加权处理,进行初步的农业信息过滤。
3.1.2 农业专业词典模块 农业专业词典是分词准确的必备条件,一般词语的词性参照GB/T13715-92《信息处理用现代汉语分词规范》所定义的名词、动词、形容词、代词、数次、量词、副词、介词、连词、助词、语气词、叹词、象声词13类。该农业搜索引擎中将提供农业科学、农业产业、农业产业链和综合搜索4大搜索功能,为此,该系统中将农业词语分为了农业科学、农业产业、农业产业链和其他4大类,农业科学包括传统的农业科学、水产科学、林业科学等(图3)。传统的农业科学包括农业环境科学、作物生产科学、畜牧科学、农业工程科学、农业经济科学等[5]。水产科学包括水产资源学、水产养殖学、捕捞学、水产品加工工艺学、渔业经济学等[6]。林业科学包括林业基础科学、林学、森林环境科学、森林工程科学、林产加工科学、林业经济管理科学等[7]。农业产业包括粮食、经济作物、果树、蔬菜、花卉、生猪、肉牛、家禽、水产、农产品物流等。产业链的产前包含种苗业、农业设施;生产包含种植/养殖/捕捞、农资产品、农业机具、田间管理;加工包含清洗/包装、品级分类、保险处理、食品加工;流通包含仓库物流、批发、零售;消费包含营销推广、餐饮服务。综合搜索是全方面农业信息的搜索,包括农业科学、农业产业、产业链3个类别。
通过专业词典的构建,用户可以在知道自己查询词属性后直接在相关词库中查询;若不知道,可以在综合搜索中查询,这样会使查询时间大大缩短,使得查询结果更加精确。
3.1.3 查询模块 用户通过在搜索界面中输入搜索命令,可以采用模糊查询和多条件查询等,系统会调用中文分词模块,将搜索命令进行分词,分解为关键词,在Nutch索引库中进行索引,找到满足用户的网页,通过评分加权的方式对搜多结果进行排序,呈现给用户,传统的PageRank排序算法[8]:
P(μ)=c■■ (1)
式中,μ是一个网页,P(μ)是网页的PageRank值,F(μ)是页面μ指向的网页集合,B(μ)是指向μ的网页集合,N(μ)=|F(μ)|是μ指向外的链接数,P(v)是网页μ指向网页v的PageRank值,N(v)是v指向外的链接数,c是规范化因子(一般取0.85)。由于该算法不能判别网页中超链接是否与主题的相关性导致PageRank排序算法存在主题漂移的现象,本系统采用的对PageRank算法的改进算法[9]:
PR(p)=(1-d)+d×■■ (2)
其中,PR(p)代表网页P的PageRanK值,PR(Ti)代表网页Ti的PageRank值,d是规范化因子,是在相似度举证S中网页p对Ti的相似度值,S(Ti)=■,B■是网页Ti的链出连接集合。该算法通过验证可以使网页的PageRank值在具有相似主题的网页上传播,极大地减少了无关网页对该值的扩散,影响网页权重的现象。
3.2 整体流程
整个搜索引擎包含3个过程:信息抓取、信息处理、信息检索。
3.2.1 农业信息抓取 主要负责将农业信息从各个农业网站中抓取、整理、入库,这个过程由爬虫、页面分析器、URL更新器、农业信息过滤器组成。爬虫将会在合作的农业网站中利用遍历的形式将农业信息进行抓取有用的网页和连接。页面分析器将会对所抓取的内容进行语法、词法分析,去掉重复URL,将检查过的内容网页内容送到页面分析器中,对页面信息进行过滤,去掉无用的网页和URL。URL更新器主要是更新过滤后的URL方便下一轮的抓取。
3.2.2 农业信息的加工和分类处理 对抓取的网页进行相关性分析,根据本研究中确定的农业词典中分好的农业大类,对抓取网页信息进行匹配,通过不同类别关键词的匹配,将所抓取网页进行分类存取,并按照倒排序的方式建立检索式。主要步骤为:①将网页信息转变为纯文本信息;②通过中文分词,按照农业专业词典进行匹配;③将匹配好的农业信息按照分类进行存储,建立倒排序检索。
3.2.3 农业信息网页资源的检索 农业用户通过发送查询请求,查询模块会调用基于专业农业词典的中文分词模块,将用户输入的请求进行解析,封装成规定的检索式来查询本地Nutch库,返回用户所要求的网页记录。同时在该模块中,会用到改进的PageRank算法,利用返回网页的基础上进行网页加权处理,并作归一化处理,得到最符合关键词前100个进行展示,通过该算法的计算会极大地提高查询结果的查准率和查全率。
4 小结
本研究在Nutch搜索框架的基础上,通过建立农业专业词典,对农业信息进行精确分词和网页信息精确分类,建立Nutch索引库,用户通过查询,系统会对初始搜索结果通过改进后的PageRank算法进行排序,将搜索结果中与关键词最相关的结果进行显示。通过整个系统的构建和插件的设计,将会实现农业领域信息搜索的“专、精、深”的目的,为用户提供更加全面、准确的搜索结果。
参考文献:
[1] 周 鹏.农业搜索引擎系统的关键技术研究[D].北京:首都师范大学,2009.
[2] 周国民,樊景超,周义桃.基于SDD算法的中文农业搜索引擎设计与实现[J].农业图书情报学刊,2008(11):48-50.
[3] 刘艳华,徐 勇.不同搜索引擎在农业领域的应用效果对比[J].农业网络信息,2009(8):25-29.
[4] 张 彧.基于Nutch的农业信息垂直搜索引擎的研究与实现[D].北京:北京邮电大学,2013.
[5] 农学分类.农学[EB/OL].http://baike.baidu.com/view/100209.html.2014-05-10.
[6] 水产科学[EB/OL].http://baike.baidu.com/view/76777.html.2014-05-05.
[7] 林业科学[EB/OL].http://baike.baidu.com/view/76775.html.2013-04-19.
[8] 王德广,周志刚,梁 旭.PageRank算法的分析及其改进[J].计算机工程,2010,36(22):291-292.
[9] 黄德才,戚华春.PageRank算法研究[J].计算机工程,2006, 32(4):145-146.
