基于Apriori算法的科技期刊约稿组稿机制
2015-10-10包震宇
包震宇
(上海师范大学学报期刊杂志社,上海200234)
基于Apriori算法的科技期刊约稿组稿机制
包震宇
(上海师范大学学报期刊杂志社,上海200234)
基于Apriori算法设计了一套用于确定组织承办专家研讨会主题的生成方案,以此为专家学者建立良好学术交流平台,从而增强科技期刊社约稿组稿工作的针对性,提高约稿组稿工作的效率。将该设计方案用于《上海师范大学学报(自然科学版)》2001—2010年文章信息库,提取适合约稿组稿的主题。结果表明:方案较好地反映了10年间学报发表论文的部分学科倾向,为将来承办相关专业化学术研讨会提供了扎实的理论依据,亦为期刊社提供了准确的约稿组稿的工作方向。
约稿组稿;Apriori算法;学术研讨会主题
众所周知,唯有高质量的稿件,才能在充斥着参差不齐的刊物的大环境中,吸引更多的关注[1]。对于科技期刊来说,约稿组稿更需要一定的针对性[2]。在众多约稿形式中,承办高质量的学术研讨会已然成为最佳选择之一。
小型会议的与会人员数量相对较少,研究方向却高度统一[3]。这种极具学术价值的研究成果,而对于一份刊物而言,是一笔非常珍贵的学术财富,也是刊物编辑重点约稿组稿的对象[4]。由此,承办某一特定领域的小型会议可以视为刊物编辑部约稿组稿工作的一条新思路[5]。
要承办小型学术研讨会,首要任务就是寻找研究对象关联度极高的专家群[6]。本文作者在建立一套稿件信息数据库的基础上,基于Apriori算法的基本思想,对数据库中的数据进行对比分析,为确定学术研讨会主题提供可靠的理论依据。
1 Apriori算法基本思想
Argawl等于1993年首先提出了挖掘顾客交易数据库中项集间的关联规则问题,设计了基于频繁集理论的Apriori算法。诸多的研究人员对关联规则的挖掘问题进行了大量的研究,包括对原有算法的优化及算法的应用与推广[7-8]。
Apriori算法使用逐层搜索的迭代方法,即“K-项集”用于搜索“K+1-项集”。首先,找出频繁项集“1-项集”的集合,记为L1。L1用于寻找频繁“2-项集”的集合L2,而L2用于找L3,如此下去,直到不能找到“K-项集”。换而言之,首先产生频繁1-项集L1,然后是频繁2-项集L2,直到有某个r值使得Lr为空,算法停止。
假定存在事务数据表如表1所示,则其频繁项集产生过程如图1所示。
由图 1可知,该事务数据库实例的频繁集为{A,B,C}和{A,B,E},置信度计算结果如表 2所示。
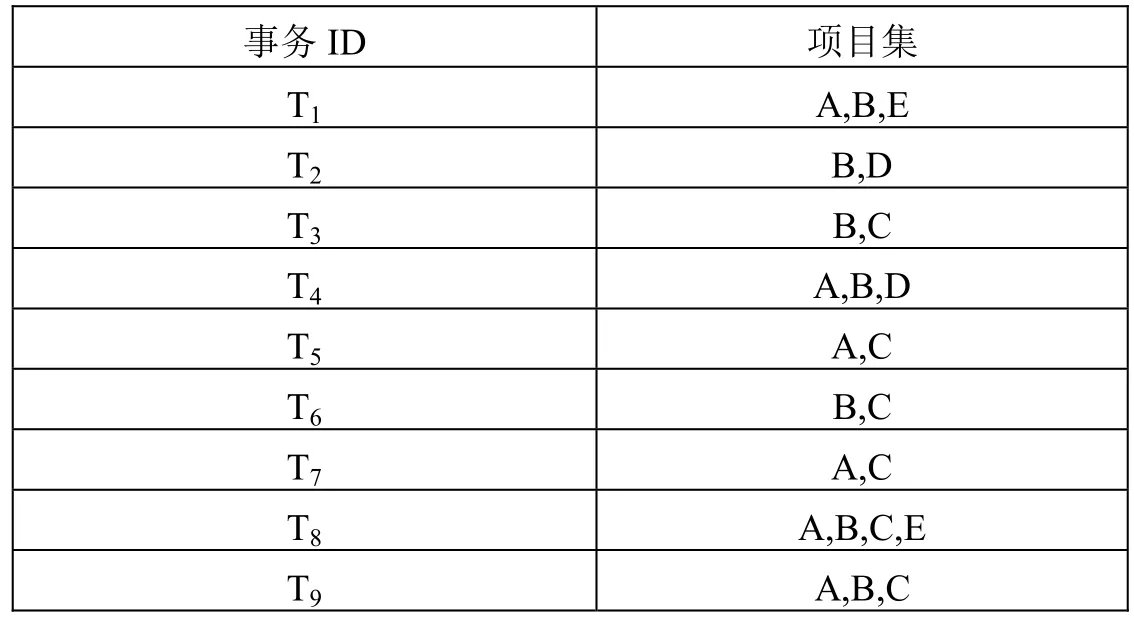
表1 事务数据库实例
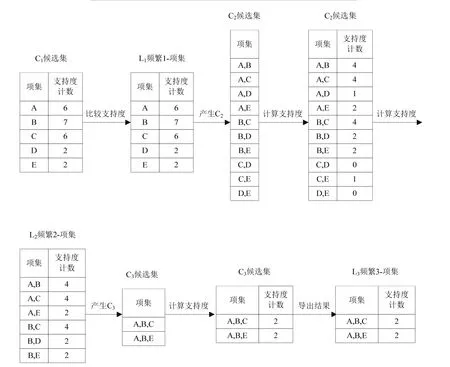
图1 Apriori算法执行示意图
2 Apriori算法在约稿组稿机制中的应用
为突出本研究的实验效果,采用《上海师范大学学报(自然科学版)》2001—2010年的真实出版数据(大约7 000条),实际应用中可选择最近几年的数据,提高实验结果与近期热点的关联性。
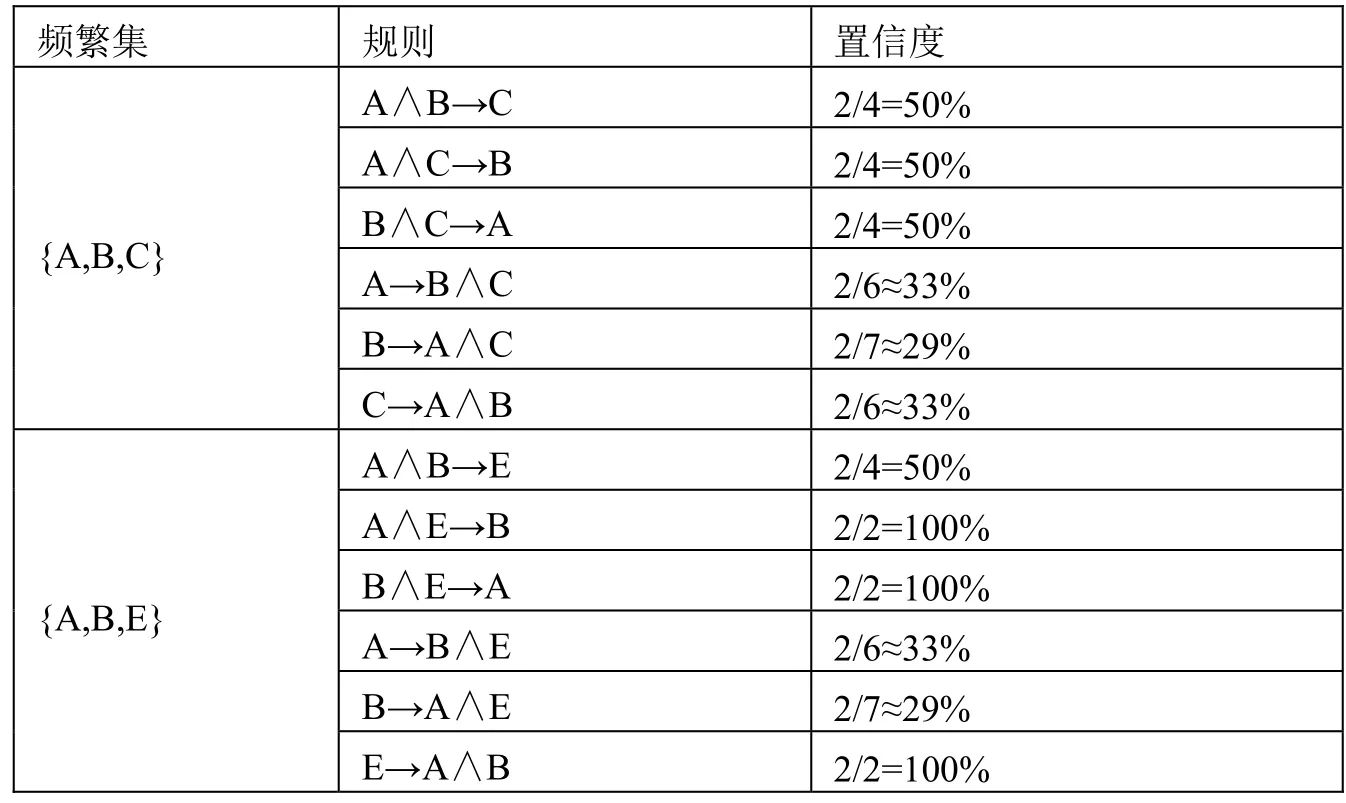
表2 频繁集的置信度计算表
2.1数据预处理
在原有数据库中截取文章表(tb_article)中的作者名(FirstAuthor)与关键字(Keywords)字段,以此作为原始粗糙集,并对该粗糙集进行纵向、横向属性约简。
纵向约简:遍历数据表的作者名字段,若遇到同一作者的2篇文章,则合并2条记录的关键字字段内容,并删除一条记录;
横向约简:在纵向约简后的粗糙集上,遍历关键字字段,删除同一记录中的重复内容。
这里,假设数据表中同名作者为同一人。实际应用中,可在作者名后加一位数字或加上第二作者名,以此区分同名作者的不同身份。
至此,得到了数据预处理后的待操作项集,如图2所示。

图2 数据预处理后的项集
2.2Apriori算法的实际操作
算法的实现步骤如下:
按Apriori算法的基本思想对项集进行遍历分析,计算出所有关键字的出现次数,以此作为 1-项集。其中,出现次数较多的几个词语有:“方程”(60)、“函数”(71)、“数据库”(33)、“向量”(44)、“宇宙”(37)等。这里,可以设置最小支持度为10,删除出现频率较低的词语,计算出频繁的1-项集,从而减少算法执行的时间花费。
将频繁的1-项集排列组合,成为2-项集,并计算其支持度,然后依照最小支持度进行“剪枝”,得出频繁的2-项集:<方程,线性>(42)、<宇宙,理论>(17)、<中国,隐翅虫>(28)等。
重复生成k-项集,并将其约简为频繁的k-项集,直到无法找到k+1-项集。最终得到的频繁项集一共有23条,如<微分,线性,方程,稳定性>(16)、<中国,隐翅虫,新记录,物种>(14)等。
算法设计代码如图3所示。

图3 算法设计样例
2.3对约稿组稿机制的启示
由算法设计实验可知,在2001—2010这10年间,《上海师范大学学报(自然科学版)》发表的论文中,<微分,线性,方程,稳定性>、<中国,隐翅虫,新记录,物种>这两个专题的关键字相对关联度较高,可以结合相关专业举办小规模的学术研讨会,为该领域学术专家提供良好而又专业的学术交流平台,使他们能深入探讨学术相关话题,并趁此机会增大这方面的学术论文约稿组稿力度,应该会有不错的效果。
在此过程中,对于与会专家学者而言,既得到了一个畅所欲言的交流平台,彼此汇报各自的研究进展,并在获取其他学者研究动向的同时,又可拓展思路,为今后的研究工作打下基础;对于主办此次学术会议的期刊社来说,可增强与这些专家们的友谊,设置专栏,组织策划本次会议的专题报道,提升这次学术会议学术价值,也提高了期刊社的知名度与影响力,可谓是一个双赢的结果。
3 结论与展望
现如今,一家科技期刊不能仅依靠传统的发展模式来维持,尤其是在约稿组稿工作上,期刊社编辑要提高自身的约稿组稿积极性,自动与专家联系交流。在专业性组稿方面,更是需要结合创新意识,借助相关软件支持,在原有信息库中挖掘有一定关联度的规则作为约稿组稿的工作方向,使约稿组稿工作变得更有针对性,提高工作效率,达到事半功倍的效果。
本文作者结合数据挖掘中的关联规则算法——Apriori算法,试图将算法融入到约稿组稿的工作中,并对此项研究开展了一系列的理论与实践的论证。实验结果表明,在原有数据库中的信息中,确实存在关联度较高的规则,这为期刊社有针对性地开展约稿组稿工作提供了确凿的依据。
本研究基于Apriori算法,设计了一套简易程序,以2001—2010这10年间《上海师范大学学报(自然科学版)》发表的论文作为基础数据库,实现了算法思想在具体操作中的应用。但限于数据量较少(约7 000条)的影响,只检索到2条学科关联度较高的集合,未来将收集扩大基础数据库,以期挖掘更多潜在关联学科。
另外,Apriori算法需要遍历多次数据表,这将严重影响算法执行的效率,在今后的研究中,作者将试图改进算法的运行机制,压缩时间成本,降低算法的复杂度,以期达到更好的效果。
[1]林松清,佘诗刚.科技学术期刊的组稿及其审理方法[J].编辑学报,2012,24(5):476-478.
[2]卓选鹏,赵大良.莫叹专家赐稿难 转变思路谱新篇[J].中国科技期刊研究,2012,23(1):137-138.
[3]颜巧元,刘义兰,王菊香,等.试论稿件处理中科技期刊编辑对作者的人文关怀[J].中国科技期刊研究,2013,24(4):780-783.
[4]吴学军,赵卫星.科技期刊计划组稿的模式——以《上海电机学院学报》为例[J].编辑学报,2011,23(1):58-60.
[5]曹昭君,陈蔓,卫李静,等.组稿与专题策划的新思维[J].江汉大学学报:自然科学版,2012,40(4):167-168.
[6]刘刚,李朝前,陈晓锋,等.会议与科技期刊约稿[J].江汉大学学报:自然科学版,2012,40(4):172-174.
[7]崔旭,刘小丽.基于粗糙集的改进Apriori算法研究[J].计算机仿真,2013,30(1):329-332,385.
[8]亓文娟,晏杰.数据挖掘中关联规则Apriori算法[J].计算机系统应用,2013,22(4):121-124.
