基于探索性空间数据分析的中国人口生育率空间差异研究
2015-10-09夏磊
摘要:21世纪初我国总和生育率已降到1.5,远低于更替水平,因此研究中国的生育水平对于我国人口健康稳定发展十分重要。本文以港澳台之外的大陆31省为研究区,以2000、2005和2010年的总和生育率为衡量指标,采用探索性空间数据分析(ESDA)方法,通过ARCGIS、Geoda等软件对我国总和生育率的空间演变趋势及分布模式进行探索性空间分析。结果表明:2000、2005和2010年我国的生育水平在空间分布上呈现正的空间自相关,但是这三年的全局空间自相关趋势有所减弱;我国生育水平高值聚集区主要分布于西部省份,并且以西南为高值聚集中心;我国生育水平低值聚集区域主要分布在东北、东部沿海省份,其低值中心是以吉林为代表的东北地区。
关键词:总和生育率;空间自相关;空间模式;区域差异
中图分类号:P208 文献标识码:A 文章编号:
一、引言
Wolfgang lutz等人(2005)提出了“低生育率陷阱”的假设,即生育率一旦下降到一定水平(1.5人)以下,如果生育率一直低于世代更替的平衡水平,会对人口的规模、结构和安全造成严重的不利后果,而且对于后期的人口均衡发展而言,也会带来难以消除的障碍。[1-2]确保不低于世代更替的生育率,是社会可持续发展的保证。2010年全国生育率为1.18110,其中“城市”为0.88210,“镇”为1.15340,“乡村”为1.43755,中国的总和生育率不到世界平均生育水平的一半,并且远低于发达国家的平均水平。[3]82对于我国的人口发展而言,现如今出现的低生育率现象是一种极其危险的警示,因此认真研究中国低生育率现象极为重要,且有利于中国人口的健康发展。
国内学者对中国生育率研究主要集中在三个方面:一是对生育政策的厘清,二是对低生育率的确认,三是对政策调整的探讨。[4]然而传统的中国人口生育率研究注重的是生育水平的差异和生育转变模式,但却无法反映人口生育率在空间关系和数值关系共同作用下的空间模式特征,而探索性空间数据分析(ESDA)可以解决这一问题。探索性空间数据分析已广泛用于区域经济、疾病控制等领域,但是很少应用到人口生育研究方面,因此本研究可以将探索性空间数据分析应用于低生育水平下的全国生育率区域差异研究,分析2000—2010年省级总和生育率的时空差异。同时可以通过对全国省级区域的生育差异特征研究,揭示生育率数据的空间效应。
二、数据来源和分析方法
(一)数据来源
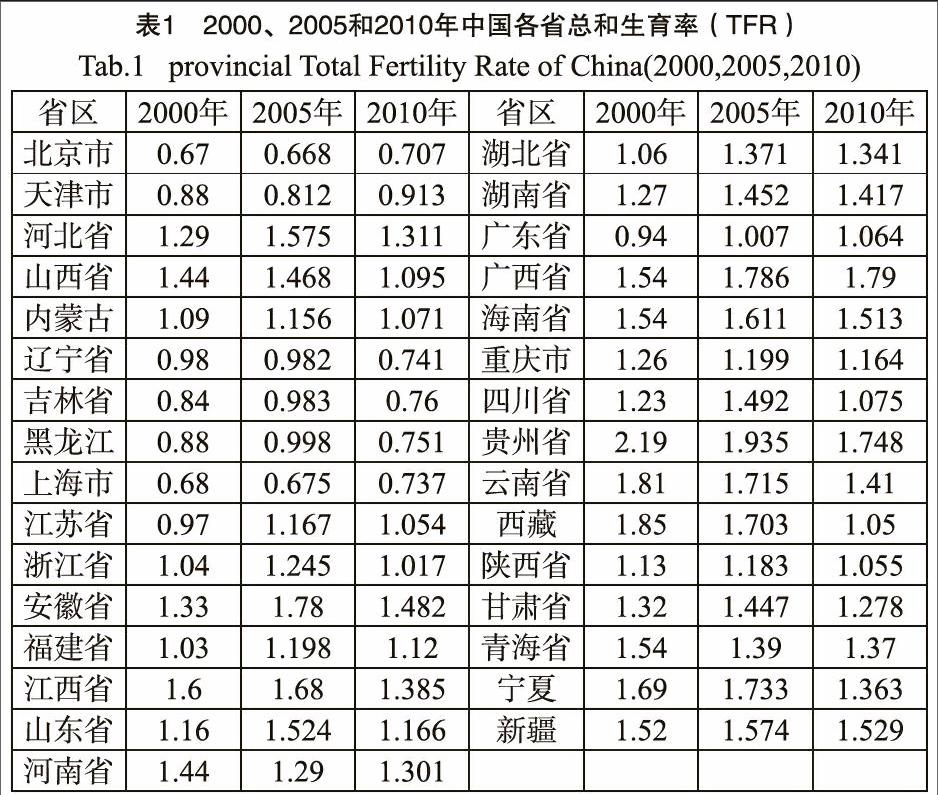
此次研究区域是除香港、澳门和台湾以外的中国31个省市区的数据,以国际学术界认可的总和生育率作为衡量指标,本文数据源自中国国家统计局公布的中国人口统计年鉴(见表1)。[5]
由我国人口统计年鉴得到的2000、2005和2010年中国31省区人口总和生育率数据,需利用Office excel进行处理,导出excel格式的数据表。借助ARCgis平台,在中国地图中提取出除港澳台以外的大陆31个省区作为基础底图,将这三年人口总和生育率数据表同底图关联,导出各省区总和生育率的shapefiles文件,再将其导入GeoDa软件,进行空间数据探测与空间自相关分析。
利用GeoDa的explore工具,对总和生育率数据的宏观情况进行探查。箱形图(Box Plot)是描述变量非空间分析的基本EDA方法之一,它显示分布的中值、第一和第三分位数,同时也显示离群值。通过建立的总和生育率数据箱形图,可得出:
(1)总和生育率最大值分为2.19(贵州)、1.935(贵州)和1.79(广西),最小值分别为0.67(北京)、0.668(北京)和0.707(北京)。
(2)总和生育率的中值分别为1.26(重庆)和1.39(青海)。
(3)总和生育率平均数分别为1.265、1.348和1.186。
(4)总和生育率标准差分别为0.3561、0.335和0.2871。
(二)研究方法
1.空间权重矩阵
空间权重矩阵是建立地理对象之间空间关系不可或缺的一部分,是观测对象之间空间依赖的正式表达。[6]通常用一个二元对称空间权重矩阵W来表示n个区域的邻近关系,其中 为区域i和j的邻近关系,公式如下:
利用Geoda创建空间权重矩阵。对空间权重矩阵有两种定义方式,分别为Rook邻接和Queen邻接。Queen邻接是在Rook上下左右邻接关系的基础上加上了对角线,此次空间权重的定义选用一阶Queen邻接关系。
由于海南省的空间位置特殊性,与其他省区在空间位置上是孤岛,为了更好地表达海南省与周围省份的空间邻接性,本文为使海南省与广东、广西两省为邻接关系,在创建空间权重矩阵过程中人为地调整了空间权重,得到调整后的 空间权重矩阵。
2.全局空间自相关
式中N为空间区域数量, 为i区域观测变量总和生育率的值, 为i和j区域之间的空间权重;[8]I系数取值从-1到1;当I=0时代表空间不相关,取正值时为正相关,取负值为负相关。[9]
3.局部空间自相关
全局空间自相关指标可以探查观测值空间上的整体分布情况,但却难以探查属性值聚集的具体位置及区域相关的程度。因此在1994年,Anselin 提出了局部空间关联指数 LISA(Local Indices of Spatial Association)弥补了Morans I的局限,该指数能揭示空间参考单元与邻近空间单元属性特征值间的相似性,探测空间异质性。[10]
式中, 和 为观测值 与均值的偏差。当 值大于0,表明该区域与周围区域的属性值相似,即为高值或低值聚集;如果I值小于0时,表明该区域与周围区域的属性值不相似,即为高值被低值包围或低值为高值包围。同时本文保持区域i的值固定不变,对于区域i邻近的空间单元的观测值进行随机排列,以此检验局部MoranI的显著性。为得到反映显著性水平的P值,需要在每次排列后重新计算I,并在零假设条件下,比较I值与原始的I值的大小。
4. Moran散点图
Moran散点图轴的中心为平均值,将图分为四个象限,依次对应不同的空间自相关类型,第一、二、三、四象限分别代表该散点对应的地理区域具有高-高聚集模式、低-高异常模式、低-低聚集模式以及高-低异常模式。散点图的回归拟合线的斜率显示了空间数据的空间自相关程度,通过图形的交互,我们能够进一步探查空间数据存在哪些空间自相关影响比较大的局部重要区域。Moran散点图描绘了考察变量与其空间滞后项的关系,表示考察变量局部区域范围内的空间分布特征。[11]
三、研究结果
(一)全局空间自相关指数趋势分析
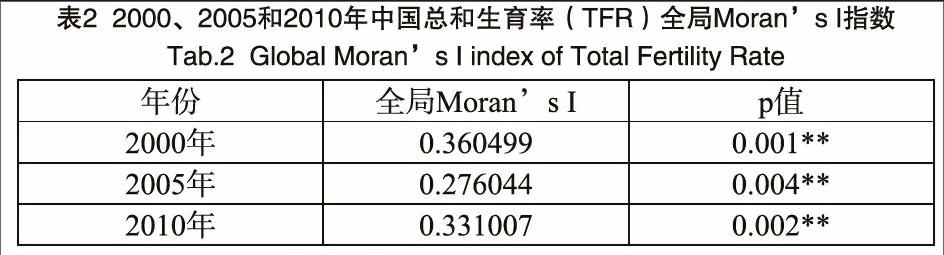
通过地理信息系统软件对中国地图进行处理,提取出除港澳台以外的中国大陆地区,作为创建空间权重的重要基础性文件。之后运用GEODA软件,对这三年数据进行空间分析,得出中国31个省、直辖市、自治区总和生育率的全局自相关指数(见表2)。在创建空间权重矩阵过程中,必须确保表格中的历年总和生育率数据与权重文件中相应的邻接实体能够实现完全匹配。如表2所示,三年的中国总和生育率所对应的全局Morans I值均为正值,且维持在显著水平,说明31个省区总和生育率在地理空间的总体分布并不是随机的,而是存在正向空间自相关,总和生育率值相似的省份趋于空间聚集,即高值省份相互聚集,低值省份相互聚集。
就变化趋势而言, Morans I指数值呈现下降趋势, 2005年下降的尤为明显。这说明这三年,我国生育水平的全局空间自相关趋势减弱,但在2005年生育水平的基础上,2010年某些空间聚集区域有所扩展或在2005年基础上发展了新的空间聚集区域。虽然2000、2005和2010年我国省级总和生育率(TFR)的空间聚集程度呈现波动性,但总的来说,总和生育率在空间分布上仍为正的空间自相关。
(二)Moran散点图
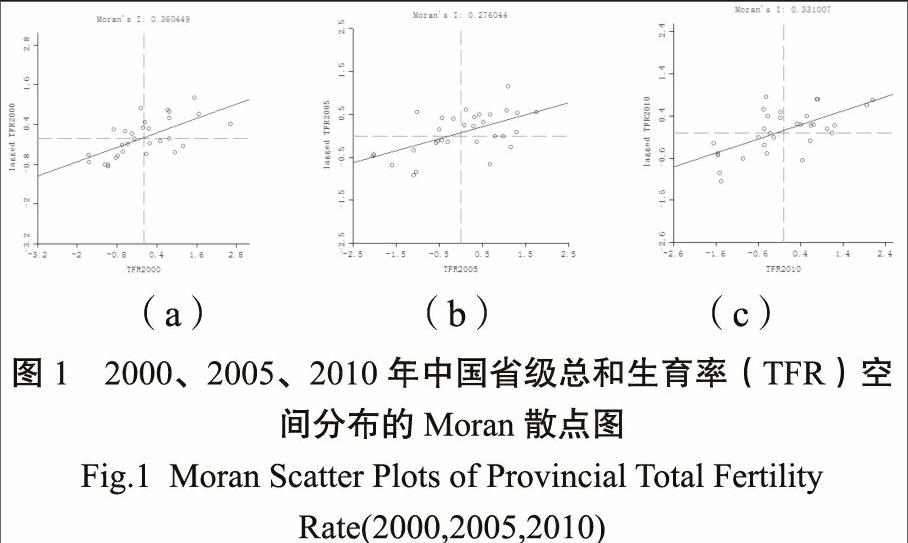
如图1横轴表示总和生育率标准化值,纵轴为相邻区域总和生育率标准化均值。每个象限对应不同的空间自相关类型:高-高和低-低为正相关,低-高和高-低为负相关。
从图1、表3可以看出,大部分省份位于第一、三象限内,表现出正的空间自相关。甘肃、广西、贵州等7个省份三年都属于“高-高”型,在空间分布上为典型的空间聚集分布。2005年“高-高”型阵列中加入安徽、湖北。总体上来说,“高-高”型的省份主要集中于西部省份。“低-低”型变化不大,主要集中于北京、福建等10个东部省份,其中东北三省全部为“低-低”型,这说明这些区域总和生育率较为显著地表现为空间的聚集分布。而“低-低”型省份中明显的变化为2005年山东省落入了“高-高”型行列中。总和生育率低值聚集区域主要集中于东部沿海和东北三省。
同时Moran散点图也有助于发现负局部空间自相关区域,即空间上为离散分布。位于第二象限的“低-高”型区域和第四象限的“高-低”型区域都属于负局部空间自相关。由图1、表3可知,这两类省份数量相比较而言较少。“低-高”型省份以广东、陕西、重庆三省最为显著,“高-低”型区域典型的为海南、河北、宁夏三省。同时2000年属“低-高”型的湖北、四川2005年落入了“高-高”型区域,2000年属“高-低”型的安徽、河南、江西和山西四省2005年进入其他三类区域中。2005年属“低-高”型的河南2010年落入了“高-高”型阵列,2005年属“高—低”型省份的江西、山西分别落入“高-高”型和“低-高”型区域。
2000年以后中国人口生育水平在空间分布上日趋稳定,总体变化幅度不是很大。高生育水平主要集中于西部省份,低生育水平地区分布区域稳定,主要在东北、沿海形成集聚带人口总和生育率呈现这种分布格局,而中部省份的生育水平这三年波动相对大一些。
(三)基于LISA聚集模式图的局部空间自相关分析
使用Geoda中的LISA聚集模式图功能对中国31个省的总和生育率进行分析,分析结果如图2。显示在LISA聚集图中的所谓空间聚集为聚集中心,从图2分析可知:
(1)2000年高—高聚集模式热点中心分别为云南和青海;2005年则只剩云南;2010年高—高聚集模式热点中心在2005年云南的基础上增加了广西与湖南。这表明,2000年我国总和生育率高值聚集区域集中于西南、西北的西部地区,随后两年出现转移:2005年高生育水平省份集中于云南、西藏、贵州等西南省份;2010年高生育水平省份除了西南,还增加了以湖南为热点中心的中部省份,我国高生育水平聚集区域以西南地区为中心,由西北转移到了以湖南为代表的中南地区。
2000年低—低聚集模式冷点中心为吉林;2005年低—低聚集模式冷点中心仍为吉林,2010年冷点中心在吉林的基础上加上了内蒙古。由此可以看出,2000、2005年我国总和生育率低值聚集区域是以吉林为中心的东北地区。2010年总和生育率低值聚集区域扩展到了以内蒙古为中心的北部地区,我国低生育水平区域有所扩展。
总的来说,2000、2005和2010年显著的高—高聚集模式热点中心、低—低聚集模式冷点中心仍为少数地区。
(2)2000年,四川的生育水平相对较低,其邻接的西北、西南地区的生育水平相对较高,四川表现为显著的低—高异常模式。2010年,广东的生育水平相较于邻近的广西、湖南、海南等省份总和生育率值较高,表现为典型的低—高异常模式。
(3)2005和2010年,与河北邻近的华北地区的总和生育率较低,其本身的生育水平较高,因此河北表现为显著的“高—低”型异常模式。
四、讨论
由上述分析,可以得出以下结论:(1)2000、2005和2010年我国的生育水平在空间分布上呈现正的空间自相关,但是这三年其全局空间自相关趋势有所减弱。(2)我国生育水平高值聚集区域主要分布在西部省份,并且以西南为高值聚集中心;我国生育水平低值聚集区域主要分布在我国东北、东部沿海省份,其中心是以吉林代表的东北地区。
2000、2005和2010年我国生育率水平的空间差异仍保持一定的东西差异,与我国社会经济发展水平的空间格局相适应。但局部细节特征仍值得分析,我们在研究空间差异原因时,需对我国总和生育率分布区域做进一步的划分。比如四川省与西北西南显著不同的低生育水平原因,河北省生育水平明显高于邻接的华北地区省份的原因,2010年以湖南为代表的中南地区呈现高值聚集的原因,值得我们进一步研究。
参考文献:
[1]赵维祥.超低生育率现象及其影响研究[D].安徽大学硕士学位论文,2012.
[2]刘忠良.中国崛起与新人口危机[J].决策与信息,2014(4).
[3]郭志刚.中国的低生育水平与被忽略的人口风险[M].北京:社会科学文献出版社,2012.
[4]许静.中国低生育水平与意愿生育水平的差距[J].人口与发展,2010(1).
[5]国家统计局.中国统计年鉴[M].北京:中国统计出版社,2005-2010.
[6]梁洪运,周其龙等.空间权重矩阵对空间自相关影响分析[J].科技资讯,2013(9).
[7]张松林,张昆. 空间自相关局部指标Moran指数和G系数研究[J].大地测量与地球动力学,2007(3).
[8]张旭,朱欣焰等.中国人口生育率的时空演变与空间差异研究[J].武汉大学学报,2012(5).
[9]许莉.基于空间统计与GIS的广西GDP空间自相关分析[J].学术论坛,2012(8).
[10]Luc Anselin.Local indicators aossociation-LISA[J].Geographcial Analysis,1995.
[11]马妍,刘爽.中国省级人口转变的时空演变进程—基于聚类分析的实证研究[J].人口学刊,2011(1).
作者简介:夏磊,男,云南宣威人,主要从事自然地理方面研究。
(责任编辑:李直)
