基于卷积神经网络的图像识别算法设计与实现
2015-09-26王振高茂庭
王振,高茂庭
(上海海事大学信息工程学院,上海 201306)
基于卷积神经网络的图像识别算法设计与实现
王振,高茂庭
(上海海事大学信息工程学院,上海 201306)
0 引言
让计算机能够识别出物体,具有类似人类的视觉一直是人工智能追求的一个目标,经过多年的发展,取得了长足的进步,然而却始不尽如人意。
为了测试图像识别算法的性能和准确率,研究者们建立了一个准确、足够庞大的图像数据库ImageNet,以这个数据库为基础平台,每年举办大规模视觉挑战赛 ImageNet Large Scale Visual Recognition Challenge(以下简称ILSVRC),这是规模最大的图像识别比赛,基本可以代表计算机视觉领域的最高水准,在2012年以前,图像识别的错误率一直居高不下(26%左右)。
在ILSVRC-2012比赛中,使用卷积神经网络的算法[1]取得了非常不错的成绩。从此,卷积神经网络成为这一比赛的主流算法,几乎所有的队伍都或多或少地使用了卷积神经网络,图像识别所能够取得的最好的成绩都是由深度卷积网络相关的算法创造的,这从侧面反映深度卷积网络在计算机视觉方面的良好性能。很快地,在一些相关领域,例如人脸识别、手写字体识别,深度卷积网络也取得了世界领先的成果。可以说,深度卷积网络是现在用于图像识别的最好的算法,这也是本文决定采用深度卷积网络算法的原因。
从算法本身的角度考虑,卷积神经网络在卷积层之间使用了共享的参数,这不仅减少了需要的内存大小,也减少了需要训练的参数数量,提高了算法的性能。同时也几乎不需要对图像进行一些预处理或者特征值提取,这是其他一些机器学习的算法所不具备的优势。
然而,经典的卷积神经网络算法[1]并没有对算法进行深入挖掘,卷积神经层的卷积核较大,而且整体结构的层数略少,算法的优势并没有完全发挥。为了提高经典算法的识别率并改进算法性能,本文引入了一种使用较小卷积核的结构,并进行修改使得这种新的结构可以简单地重复使用,这样既能够保证网络的总体深度,又能够有效地提高算法的识别率。
1 卷积神经网络的基本概念
卷积神经网络是深度学习中的常用算法,最早是受到人体的视觉系统启发提出的[2],后来不断加以修正[3-5],最终形成为一个非常适合用于处理并识别图像的多层神经网络。作为深度学习算法的一个实例,卷积神经网络在一些介绍深度学习算法的论文中也有所提及[6]。
经典的卷积神经网络[1]包括卷积神经层、Rectified Linear Units层 (以下简称为ReLU层)、Pooling层和规范化层,其结构如图1所示。

图1 经典的卷积神经网络结构
为了对经典的卷积神经网络算法进行改进,下面首先对卷积神经网络的这种结构逐层进行介绍,并在一些需要有所改进的地方进行论述。
1.1卷积神经层
卷积是图像识别中常用的算法,是指输出图像中的每个像素都是由输入图像的对应位置的小区域的像素通过加权平均所得,这个区域就叫做卷积核。一般而言,卷积核都是正方形的,所以都是用类似m×m的方式表达,这里的m即为区域的边长。卷积神经层,其实就是对图像的每个点进行卷积运算,卷积核都被作为训练参数。卷积神经层可以看作是对输入图像进行“抽象”的操作,经过几次处理之后,能够提取出图像的“特征值”。
一般而言,卷积神经层中,卷积核越大,对图像“抽象”的效果越好,但需要训练的参数就越多;卷积核越小,越能够精细地处理图像,但需要更多的层数来达到同样的“抽象”效果。只是,较小的卷积核,就意味着更多的ReLU层,也就意味着整个结构更加具有识别力。
经典的结构中,使用了11×11卷积核这样的较大的卷积核,这样的神经层引入了很多的参数,虽然保证了最终的效果,但也降低了算法的性能。因此,在本文引入的结构中,仅使用了3×3和5×5这样的较小的卷积核。
1.2ReLU非线性函数
在经典的结构中,使用的神经网络激活函数是Rectified函数,在卷积神经网络中,这样的神经层一般叫做ReLU。
在文献[15]中,有关于ReLU的详细论证,而在经典的卷积神经网络算法中,也将ReLU与传统的激活函数进行比较,得出的结论是ReLU能够减少训练时间,提高算法性能。深度卷积网络一般都需要大量的数据进行训练,以至于使用传统的激活函数几乎不能够配合卷积神经层完成训练。在这种情况下,ReLU几乎就是最好的选择。
在本文中,如非特指,每个卷积神经层之后都用ReLU处理。
1.3Pooling层
输入图像经过卷积神经层和ReLU处理之后,图像中的每个像素点都包含了周围一小块区域的信息,造成了信息冗余。如果继续使用包含了冗余信息的图像,不仅会降低算法性能,还会破坏算法的平移不变性。
为了提高算法的性能和鲁棒性,这里需要对图像进行二次采样(Subsampling)。在深度卷积网络中,这样的操作又叫做Pooling,即将图像分成一小块一小块的区域,对每个区域计算出一个值,然后将计算出的值依次排列,输出为新的图像。如果划分的区域之间互不重叠,这样的算法被称作Non-overlapping Pooling,否则称为Overlapping Pooling。对每个区域计算输出的方法也分为两种:求平均值(一般叫做Sum Pooling,也可以叫做Avg Pooling)或者取最大值(Max Pooling)。这一神经层比较简单,不需要训练。另外,这一算法有时会忽略输入图像的边缘部分,这对于算法整体而言也是可以接受的。如输入图像为13×13,而Pooling层选取的区域大小为3×3,则最下方和最右方边缘的1个像素则会被忽略。
在经典的网络结构中,使用的是可以重叠的、取最大值的Pooling算法(Overlapping Max-Pooling),原因是可以稍微降低过度拟合。在本文中也使用了相似的算法。
1.4规范化神经层(Normalization Layer)
规范化层是为了让图像更加具有对比性而设计的神经层,这一神经层的效果类似于对图像进行“增加对比度”的操作。显而易见的是,需要一个计算“平均值”的算法,然后按照一定的规则对图像的每个像素进行调整,使得图像的主体部分能够和背景更加具有区分度。目前常用的算法通常是Local Response Normalization[1](以下简称LRN),这一算法可以很有效地提高主题部分与其他部分的区分度。
然而LRN并非必要,对效果的提升并不是很明显,所以在使用深度卷积网络时,一般只有当卷积核较大,即处理得比较“粗糙”的时候,才会使用LRN。
2 网络结构的设计
设计卷积神经网络的结构时,既需要考虑到深度学习算法的一般性,也要针对卷积神经网络进行优化。在实际设计中,还需要兼顾到拓展性。在一般的深度学习算法中。
2.1网络深度很重要
在大多数的深度学习算法里,网络的深度都是很重要的参数[5,8,10],深度卷积网络也不例外。在文献[14]中,VGG甚至专门验证了深度对于结果的影响,他们使用3×3卷积核,然后分别测试了11层、13层、16层和19层的不同网络结构所能够取得的结果。虽然训练的参数有些许的增加(从133M个到144M个),但与正确率提高的幅度相比较,却是微乎其微的。这也是深度卷积网络的一个优势:增加深度并不会引起训练时间的爆炸性增长,而是一个相对缓慢的增长;网络所能够取得的结果却往往能够有明显的改善。
在经典的卷积神经网络中,网络的层数虽然多于普通的神经网络,但由于使用的是卷积核较大的神经层,所以整体的层数略显不足。
2.2引入的结构
在文献[7]中,经典的卷积神经网络使用了11×11的较大的卷积核,虽然,这能够有效地对图像进行“抽象”,但训练的参数较多,限制了整体算法的性能。为了改进算法性能并增加神经网络的深度,在新引入的结构中使用了卷积核较小的卷积层。同时,为了能够方便地调整算法,并兼顾算法的拓展性,引入的结构应当可以直接叠加而不必引入新的神经层。为此,在本文中引入的新的结构如图2所示:

图2 本文中引入的结构
在图2所示的新结构中,每个卷积层之后都包含有一层ReLU。
在该结构的首尾处各有一个1×1卷积核的神经层,可以将其理解为“粘合剂”,即通过使用了1×1卷积核的神经层之后,使得与使用任何卷积核的神经层都可以直接相连。
中间使用了3×3卷积核和5×5卷积核的神经层,既可以有效地提取图像特征值,又保证了这样的结构不会像较大的卷积核一样,引入过多的参数。我们也试过用3层3×3卷积核的神经层,二者效果相差不大,但图2中的结构更易于调整。
2.3网络的总体结构
在最开始的试验阶段,我们曾经试过用4次图2中引入的结构,但训练的时间过长;使用3次图2中的结构,训练时间可以接受,但取得的效果不甚理想,因此,在最后设计的结构中,考虑使用一个7×7卷积核的神经层取代原来的结构,这样既可以保证训练的时间不至于过长,又能够有效地降低错误率。为此,网络的总体结构设计成图3所示的结构。
卷积神经层之后,使用了传统的全连接型的神经网络和Softmax回归,这也是在文献[1]中使用的经典结构。另外,Softmax的输出并不是单一的图像识别分类,而是输出概率最高的几个,如此一来就能够更方便地衡量算法的准确率。
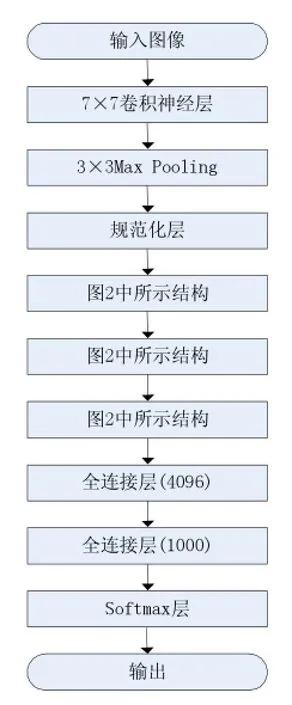
图3 网络的总体结构
相比于经典的卷积神经网络,图3这样的结构更容易调整,只要计算资源允许,就可以在网络中增加图2中引入的结构。同时,这样的结构从卷积神经网络的出发点——提取图像的特征值的角度考虑,抽象能力也更强。
3 实验结果与分析
在实现算法并验证其有效性时,需要首先选定一个足够庞大、精细的图像数据库,之后在这个数据库里甄选有代表意义的图像。同时也需要确定较为精准的算法优劣的判别标准,这样就能够与当前的世界先进水平进行对比。
3.1图像的选取及预处理
深度卷积网络需要大量整理好的图像进行训练,为了有一个通用的图像数据库,ImageNet被设计出来并广泛应用于科研领域。同时ImageNet还会在每年举办的ILSVRC中,选取出进一步整理的图像用来测试算法。
ILSVRC-2014的分类比赛中,共计提供了1000个类别的约120万幅图像用作训练,5万幅图像用作校正,10万幅图像用作测试。虽然,这对于物体识别这一宏伟目标相距甚远,但对于实验,这样的深度卷积网络一般就足够了。实际上,训练全部图像需要有不错的机器设备性能和很长的时间,因此在实际实现中并没有选取全部的图像,而是挑选了其中100个类别的共计99858幅图像训练(针对每个类别挑选1000幅图像,但某些类别不足1000幅)和2000幅图像用作测试。
在使用卷积神经网络处理之前,需要先对图像进行预处理。由于图像的大小直接关系到卷积核的选取,因此不宜太大;如果图像太小,又会引起图像关键细节的丢失。一般选取256×256像素作为图像的标准大小。预处理时,可以将图像的宽或者高之中较小的一个缩放到256像素,之后按比例调节图像大小,然后裁剪出居中的224×224像素的部分作为算法的输入。
3.2判别标准
衡量图像识别算法效果的优劣,一般都是计算错误率。在本文中,由于选取的图像是从ILSVRC中选取,所以为了能够方便地将算法的结果和国际领先水平相比较,也引入了相同的错误率算法。在ILSVRC中,比较不同队伍间的成绩是计算两种错误率:Top-1错误率和Top-5错误率。Top-5错误率是指将算法输出的结果与图像的标签进行比较,如果输出的前5个结果中有任何一个命中 (不考虑顺序),即视为正确。Top-1错误率是指将算法的第一个输出和图像的标签作比较,相同则视作正确。
3.3程序框架
实现深度卷积网络已经有了成熟的框架,本文实验使用的是Caffe[9]。Caffe是一个可读性、简洁性和性能都很优秀的深度学习框架,并且直接集成了卷积神经网络神经层。由于深度卷积网络本身的特性,有时候用GPU加速运算可以大大缩短算法训练时间,Caffe也提供了相应的接口。
使用Caffe实现卷积神经网络时,需要预处理数据,然后根据设计好的网络结构配置相应的文件,即可使用Caffe训练并测试结果。
3.4结果分析
在得出本文算法测试结果后,与ILSVRC一部分具有代表性的算法及其结果[11-12]进行对比,如表1所示。

表1 实验结果与ILSVRC结果对比
在表1中,除最后一行所示算法(ISI),都使用了深度卷积网络。可以看出,卷积神经网络所得到的结果还是相当理想的。其中,排名靠前的算法都使用了卷积核较小的神经层:VGG使用的全是3×3卷积核的神经层,而GoogLeNet设计了一种比本文中的结构更加复杂的模块,并使用了更深的网络结构,所取得的结果也是目前所能够取得的最好的结果。
从错误率的角度来看,对比也是相当明显的。最初将神经网络应用于ImageNet识别的文献[1]中所得到的Top-5错误率是16.4%,远远超过当时没有使用深度卷积网络的算法(26.2%)。随后,经过两年的研究和完善,现在所取得的最好的成果已经可以达到6.67%的错误率。这样的成果是相当振奋人心的,甚至在文献[13]中将这一结果和普通人识别ImageNet的结果相比较,结果是普通人识别的错误率在5%左右,最好的深度卷积网络算法的结果已经比较接近人识别的错误率水平。
4 结语
本文引入的新的卷积神经网络结构能够有效地提高图像识别的准确度,并具备良好的扩展性。对比经典的卷积神经网络,不仅在算法的效果上有所提高,而且训练的参数有所减少,训练所需的时间更短。虽然距离当前世界先进算法的水平尚有些差距,但算法的准确率依旧比传统的图像处理算法高出许多,今后,将继续在这方面进行深入研究。
[1]Alex Krizhevsky,Ilya Sutskever,Geoff Hinton.Imagenet classification with deep con-volutional neural networks[J].Advances in Neural Information Processing Systems 25,2012:1106-1114
[2]DH Hubel,TN Wiesel.Receptive fields,binocular interaction,and functional architecture in the cat's visual cortex[J].Journal of Physiology(London),1962,160:106-154
[3]K.Fukushima,Neocognitron:A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position[J].Biological Cybernetics,1980,36:193-202
[4]Y.Le Cun,L.Bottou,Y.Bengio,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[5]Y.LeCun,B.Boser,J.S.Denker,et al.Backpropagation applied to handwritten zip code recognition[J].Neural Computation,1989,1(4):541-551.
[6]Yoshua Bengio,Learning Deep Architectures for AI[J].Machine Learning,2009,2(1):1-127.
[7]Glorot X,Bordes A,Bengio,Y.Deep sparse rectifier networks[C].Proceedings of the 14th International Conference on Artificial Intelligence and Statistics.JMLR W&CP Volume,2011,15:315-323.
[8]Yoshua Bengio,Aaron Courville,and Pascal Vincent,representation learning:A review and new rerspectives[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2013,Issue No.08-Aug.(2013 vol.35):1798-1828.
[9]JIA Yang-qing,Shelhamer Evan,Donahue Jeff,et al.caffe:convolutional architecture for Fast feature embedding[EB/OL].2014,arXiv preprint arXiv:1408.5093
[10]Know your meme:We need to go deeper[EB/OL][2014-12-01].http://knowyourmeme.com/memes/we-need-to-go-deeper
[11]Christian Szegedy,Wei Liu,Yangqing Jia,et al.Going deeper with convolutions[EB/OL][2014-09-17]arXiv:1409.4842v1[cs.CV]
[12]Olga Russakovsky,Jia Deng,Hao Su,et al.ImageNet Large Scale Visual Recognition Challenge.?[EB/OL],2014,arXiv:1409.0575
[13]Andrej Karpathy.What I learned from competing against a ConvNet on ImageNet[EB/OL][2015-01-24].URL:http://karpathy.github. io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
[14]Karen Simonyan,Andrew Zisserman.Very deep convolutional networks for large-scale image recognition[EB/OL],[2014-11-18]. arXiv:1409.1556v3[cs.CV]
[15]V.Nair,G.E.Hinton.Rectified linear units improve restricted boltzmann machines[C].In Proc.27th International Conference on Machine Learning,2010
Convolutional Neural Networks;Deep Learning;Image Recognition;Machine Learning;Neural Network
Design and Implementation of Image Recognition Algorithm Based on Convolutional Neural Networks
WANG Zhen,GAO Mao-ting
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
国家自然科学基金项目(No.61202022)、上海海事大学科研项目
1007-1423(2015)20-0061-06
10.3969/j.issn.1007-1423.2015.20.014
王振(1990-),男,江苏沛县人,硕士研究生,学生,研究方向为机器学习、深度学习,Email:wangzhen@gra.shmtu.edu.cn
高茂庭(1963-),男,江西九江人,博士,教授,研究方向为智能信息处理、数据库与信息系统
2015-06-19
2015-07-01
卷积神经网络在图像识别领域取得很好的效果,但其网络结构对图像识别的效果和效率有较大的影响,为改善识别性能,通过重复使用较小卷积核,设计并实现一种新的卷积神经网络结构,有效地减少训练参数的数量,并能够提高识别的准确率。与图像识别领域当前具有世界先进水平的ILSVRC挑战赛中取得较好成绩的算法对比实验,验证这种结构的有效性。
卷积神经网络;深度学习;图像识别;机器学习;神经网络
Convolutional neural networks has achieved a great success in image recognition.The structure of the network has a great impact on the performance and accuracy in image recognition.To improve the performance of this algorithm,designs and implements a new architecture of the convolutional neural network by using convolutional layers with small kernel size repeatedly,which will reduce the number of training parameters effectively and increase the recognition accuracy.Compared with the state-of-art results in ILSVRC,experiments demonstrate the effectiveness of the new network architecture.
