H.264 SVC 面向MPEG-2 基本层扩展研究
2015-09-19李晓峰张立军朱新博
李晓峰,张立军,陈 帅,朱新博
(1.山东建筑大学 浪潮数字家庭与云计算研究所,山东 济南250101;2.浪潮集团 数字媒体事业部,山东 济南250101)
可伸缩视频编码(Scalable Video Coding,SVC)是H.264/AVC 标准的一个扩展[1],较好地解决了标准内不同分辨率和不同带宽条件下播放终端的播放问题。H.264 SVC 采用基本层和一个到多个增强层的分层编码方法,基本层编码低质量的视频,增强层在基于基本层预测的基础上编码较高质量视频,这样就实现了在不同播放能力和传输带宽条件下自适应选择不同质量的视频,达到视频顺利播放的目的。H.264 SVC 包括时间可伸缩性、空间可伸缩性和质量可伸缩性等3种分级策略。其中时间可伸缩性是按照不同帧率进行分层,空域可伸缩性是针对不同分辨率的分层编码,而质量可伸缩性主要指的是不同层次图像质量的调整[2]。在视频娱乐应用中需要针对不同分辨率终端提供服务,如手机、计算机和标清与高清机顶盒等,空间可伸缩性是最主要的研究和应用方向。
有线电视的数字化初期采用了MPEG-2 标准对标清视频进行编码,在后来高清化过程中为了节约带宽,采用了H.264/AVC标准编码高清视频[3]。由于早期的机顶盒仅能播放MPEG-2 编码的标清视频,对于已经高清化的节目,还需要进行同时播出MPEG-2 编码的标清码流,以实现对早期机顶盒的兼容支持。但是这使得同一套节目需要高清和标清冗余播出,占用传输带宽大,限制全面高清化的实现。这里的实质问题是对终端分辨率差异性的支持,H.264 空间SVC 就是面向这类问题研制的,但是因为它是定义在标准内的可伸缩编码[4],各层编码都是H.264 的标准,并不能直接应用于有线数字电视领域。
本文为兼容解决有线数字电视中机顶盒播放能力差异并提供带宽利用率,提出了MPEG-2 和H.264 标准间SVC 的研究思路,即在H.264 SVC 的基础上扩展为允许基本层采用MPEG-2 编码标准[5],以实现对早期机顶盒的兼容支持,而增强层继续采用H.264/AVC 编码标准进行高清增强编码,保证压缩效率。为此设计了标准间的空间SVC 编解码框架,通过层间预测消除层间冗余,使编码码流可以适应不同解码能力和显示尺寸的播放终端[6]。
1 系统架构
1.1 H.264 SVC 编解码器架构
H.264 空间SVC 由一个基本层和一到多个增强层组成,每个增强层顺序以其下层的基本层或增强层作为参考层,进行层间预测编码来消除层间的数据冗余。因此各增强层的基本架构都是类似的。H.264 在标准化SVC 扩展时为了便于在已有H.264 编解码器上扩展实现,所采用的编码算法都是H.264 中现有算法。即SVC 定义在H.264 标准之内的,其基本层和增强层都是采用了H.264 编码标准。
首先对H.264 的空间SVC 的编解码框架[7]进行分析(如图1 所示),不失一般性针采用一个基本层和一个增强层。基本层视频图像序列输入是由增强层视频图像序列下采样得到,经过帧内预测、帧间预测、变换量化和熵编码等处理,得到了基本层码流,同时将帧内预测、帧间预测和残差信息传输给增强层,完成基本层向增强层的层间预测。增强层的输入即为原始视频图像序列,和基本层一样,经过增强层的帧内、帧间预测等处理,在此过程中,接收基本层的预测,为增强层的上述处理提供预测信息,提高了编码效率。

图1 H.264 空间SVC 编码器框架
在只对H.264 SVC 的基本层解码时采用标准的H.264解码器。而要解码更高分辨率视频需要对基本层和增强层进行同时解码,解码器结构[8]如图2 所示。其中对基本层进行残差解码,经上采样后作为增强层解码补偿。增强层经过熵解码、反变换反量化的同时,还需要基本层的预测信息,能得到完整的重建图像。因此增强层需要同时得到基本层码流和增强层码流才能顺利解码。
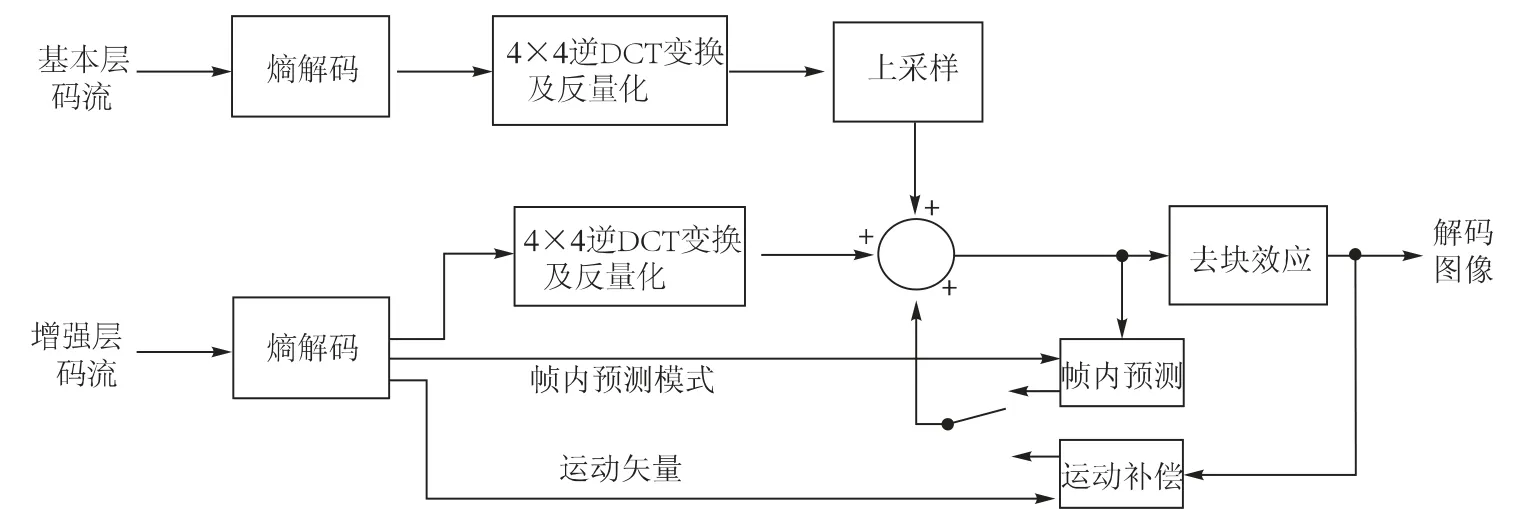
图2 H.264 SVC 解码器框架
1.2 标准间SVC 编解码器架构
从H.264 空间SVC 扩展为标准间SVC,使得各层都采用H.264 编码变为基本层采用MPEG-2 编码和增强层采用H.264编码。为了消除层间冗余,并提供对不同能力终端的支持,标准间SVC 应该继承H.264 空间SVC 的编码和解码架构,继续采用分层编码方式,用层间预测消除数据冗余。但是由于层间编码标准的差异性,标准间空间SVC 的编码器框架和解码器框架分别需要针对性设计。
以H.264 空间SVC 编码框架为基础,标准间SVC 把基本层编码器更换为MPEG-2 编码器,而增强层继续采用了H.264标准,如图3 所示。
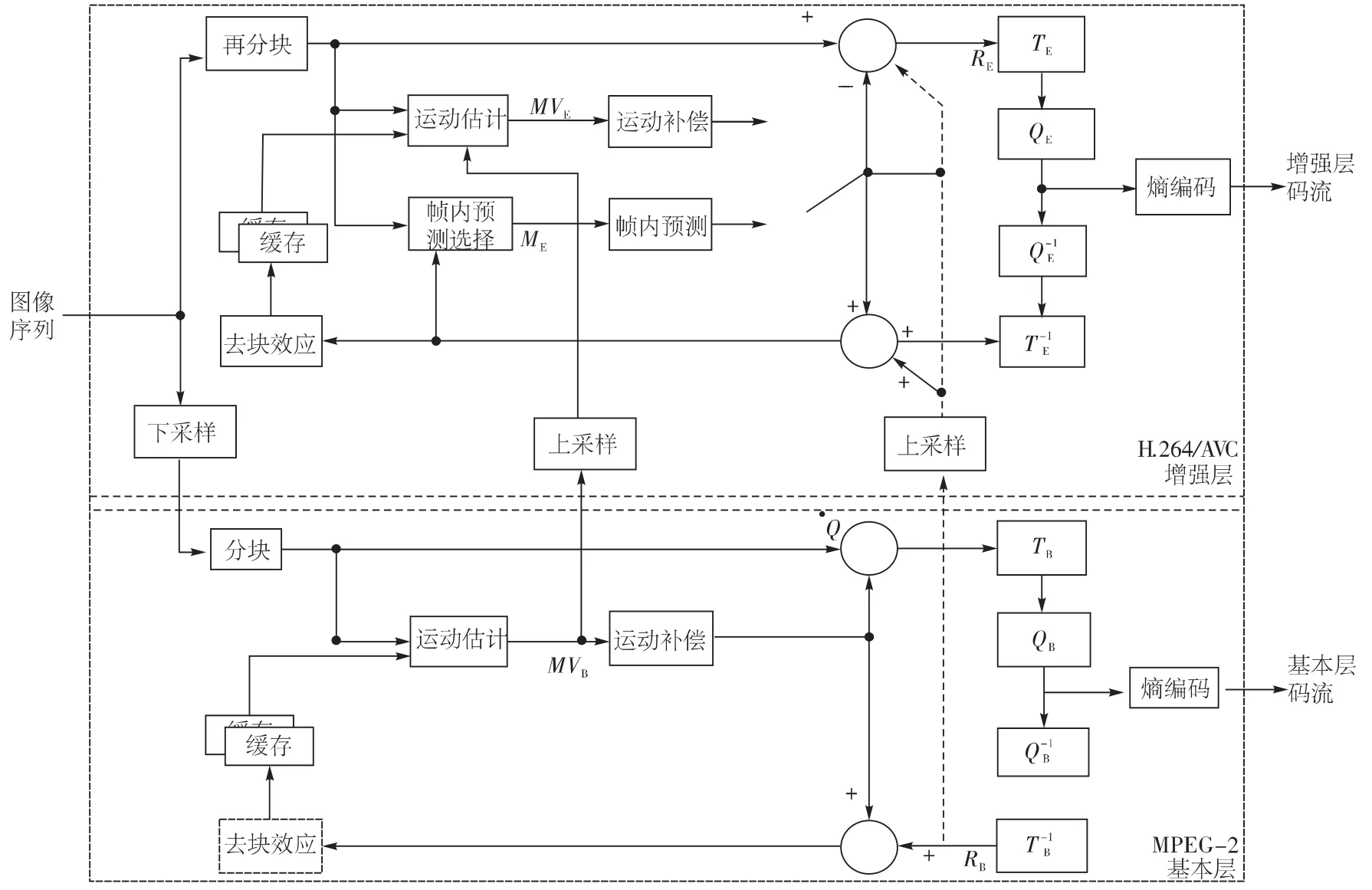
图3 标准间空间SVC 编码器框架
在基本层,输入图像序列为原始图像下采样之后的图像,下采样图像通过分块进行帧间预测,获得的残差矩阵既要直接进行DCT 变换和量化,熵编码之后就得到了基本层码流;也要将残差矩阵直接上采样,向增强层预测,完成层间残差预测。基本层编码并解码完成得到的重建图像,进行上采样,然后传给增强层。
在增强层,输入的原始图像序列,通过再分块,然后进行帧内预测、帧间预测、变换、量化和熵编码等一系列关键步骤,最后得到增强层的码流。由图3 也可以看出,在增强层编码中会有几个部分用到基本层的预测:一是利用图像在不同分辨率下运动一致性,依据MPEG-2 基本层的运动矢量进行层间帧间预测;二是增强层会得到基本层帧间预测之后的残差图像。
由于标准间SVC 编码器结构与H.264 SVC 保持一致,因此所对应的解码器结构也与H.264 空间SVC 解码器保持一致。但是由于基本层编码标注的变化,需要进行相应调整。其中要进行低分辨率解码时,只需要标准MPEG-2 解码器解码基本层码流即可。
要进行高分辨率解码,则需要在基本层预测的基础上增强层解码,如图4 所示。与H.264 SVC 一样,基本层主要为增强层提供残差图像预测。相应地对基本层进行MPEG-2的熵解码和8×8 DCT 逆变换和反量化,经上采样为增强层解码提供预测。增强的解码结构则与H.264 SVC 保持一致。

图4 增强层解码器框架
2 关键问题研究
2.1 层间帧间预测
层间帧间预测,是基本层帧间预测的相关信息,比如宏块的划分方式、运动矢量和参考帧索引值等信息,向增强层预测的一个过程。由于标准间SVC 基本层和增强层图像分辨率的不同,在层间帧内预测的时候其运动相关性一致,但是运动估计的精度不够,这就需要对运动矢量进一步精细化。
在MPEG-2 编码标准中,宏块大小为16×16,每个宏块对应两个运动矢量,分别是垂直方向运动矢量和水平方向运动矢量,如图5a 所示,MVB表示了MPEG-2 宏块的合成运动矢量。在H.264/AVC 编码标准中,宏块的划分种类较多,可以分为16×16,16×8,8×16,8×8 的块,还可以进一步划分为8×4,4×8 和4×4 的块[9],这就会产生多种情况的运动矢量MVE,如图5b 所示,展示了H.264 多种块划分情况下的运动矢量。

图5 MPEG-2 和H.264/AVC 宏块运动矢量示意图
由于层间运动矢量的差异性,基本层向增强层的运动矢量预测时,增强层以基本层所预测的运动矢量为基础,然后进一步进行精细化搜索。采用H.264 编码的增强层具有多种情况的运动矢量,情况较为复杂,因此基本层所预测运动矢量的精度不够,精细化处理过程如图6 所示。其中MVE表示增强层运动矢量,MVB表示基本层运动矢量,由于分辨率的差异,基本层运动矢量预测至增强层后需要做加倍处理,然后在基于此进一步精细化搜索,图中的ΔMVE就是精细化搜索过程中基本层和增强层运动时的变化量。

图6 增强层运动矢量精细化处理示意图
层间帧间预测过程中,运动矢量进一步精细化搜索时,不同的搜索步长会对预测效果和图像质量产生不同的影响,本文以1/4 像素精度作为一个搜索步长,通过实验对不同搜索步长所得到的图像质量进行了统计,如图7 所示,其中图像质量是以图像信噪比(SNR)进行衡量的,从图中可以看到,当搜索步长为8 时,SNR 最大,此时可以得到最佳质量的图像。

图7 不同搜索范围的SNR 变化趋势图
2.2 层间残差预测
层间残差预测,是将基本层的残差数据上采样然后传输给增强层的过程。在SVC 中,基本层是通过预测编码的方式得到了残差数据,也可以叫做残差矩阵,然后将残差矩阵上采样预测至增强层,增强层接收该数据之后直接用此残差矩阵完成后续的DCT 变换和量化等步骤。可是对于标准间SVC,基本层采用的MPEG-2 编码标准,增强采用的是H.264/AVC编码标准,采用MPEG-2 编码的基本层I 帧并没有残差数据,因此无法直接完成层间残差预测。
为了解决基本层I 帧无残差数据的问题,本文提出的解决方案是对I 帧进行增强处理,即直接将基本层I 帧图像进行上采样,然后传输给增强层与增强层I 帧图像做差,得到新的残差图像。由于残差图像具有较强的纹理特性,最后对新的残差图像做进一步帧内预测处理,从而提高了数据的压缩性,大大提高了编码效率。
为了研究其可行性及压缩效果,本文选用了foreman,bus,bridge,football 等6 幅经典标准视频测试序列,针对这六幅CIF 格式的图像分别进行了I 帧的增强处理,并对I 帧残差图像帧内预测后得到的新的残差图像进行了变换量化,然后将此结果与未进行增强处理的残差的变换量化数据进行了对比,如表1 所示,表格对量化后的非零DCT 系数进行了统计并以此为对比依据。从表中可以看到,对I 帧图像进行增强预测处理之后,图像数据的压缩率平均提高79.3%,实验数据表明,层间残差预测采用I 帧增强处理方案可以较好的提高数据压缩率。
2.3 层间帧内预测
层间帧内预测,是基本层的帧内预测模式向增强层预测,为增强层的帧内预测提供参考的过程。本论文所提出的标准间SVC 的基本层,采用MPEG-2 编码,并没有帧内预测处理,基本层没有帧内预测模式可借鉴,因此无法直接完成基本层向增强层的层间帧内预测。
本文提出了基于基本层DCT 系数帧内预测的解决方案,来研究解决层间帧内预测问题。由于DCT 系数具有一定的方向性,能够较好的反映图像的纹理变化,如图8 所示,N0 到N3 表示了不同的能量区域,每个能量区域有不同的纹理变换,比如N0 反了映原图像的竖直纹理,N2 反映了源图像的对角纹理等[10]。
图9 表示了H.264 编码标准中4×4 块的9 种帧内预测模式,共8 个方向和一个DC 模式,不同方向代表了不同的帧内预测模式。通过对基本层DCT 系数的分析,得到图像的纹理方向,从而缩小帧内预测的模式查找和计算,快速找到代价最小的帧内预测模式,实现了标准间SVC 层间帧内预测的快速选择,提高了编码效率。
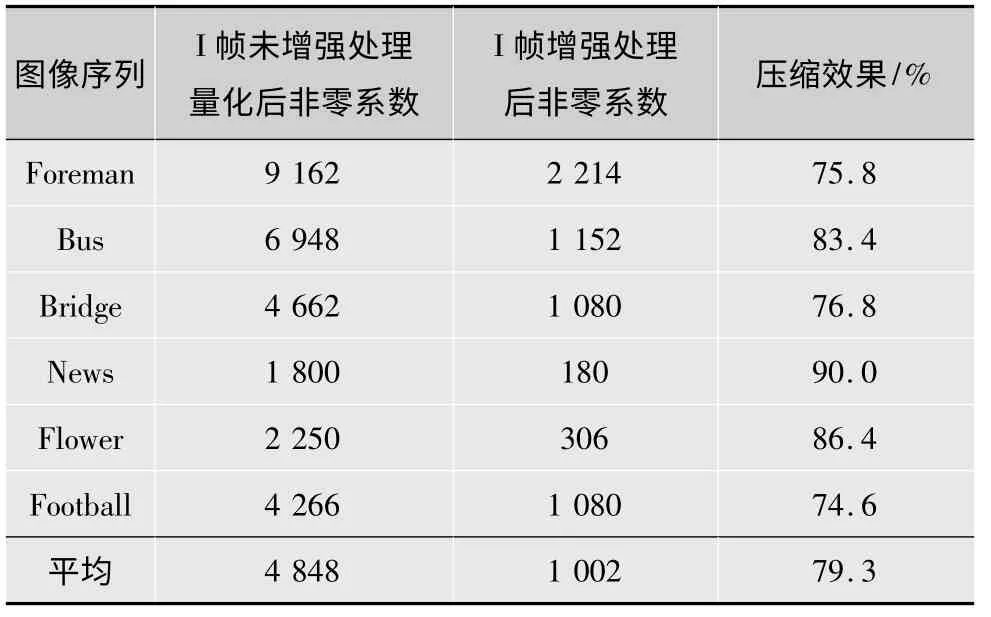
表1 I 帧增强处理结果比较

图8 DCT 域的能量区域分布
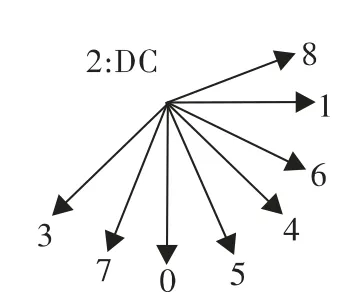
图9 H.264 4×4 块帧内预测模式
本文利用机器学习中BP 神经网络算法[11],通过对基本层DCT 系数和其对应增强层预测模式的大量训练,从而得到训练好的神经网络预测模型[12],用600 个数据分为6 组作为测试集,每个数据都会对应一个包含不同权重大小的9 维输出[13],最后得到了最优预测模式命中率的统计结果,如表2所示。实验数据表明,对每个输出中的权重进行排序,权重的大小可以较好的反映其是否能够命中最佳预测模式,这为通过DCT 系数实现帧内模式的快速预测提供了较好的理论依据。
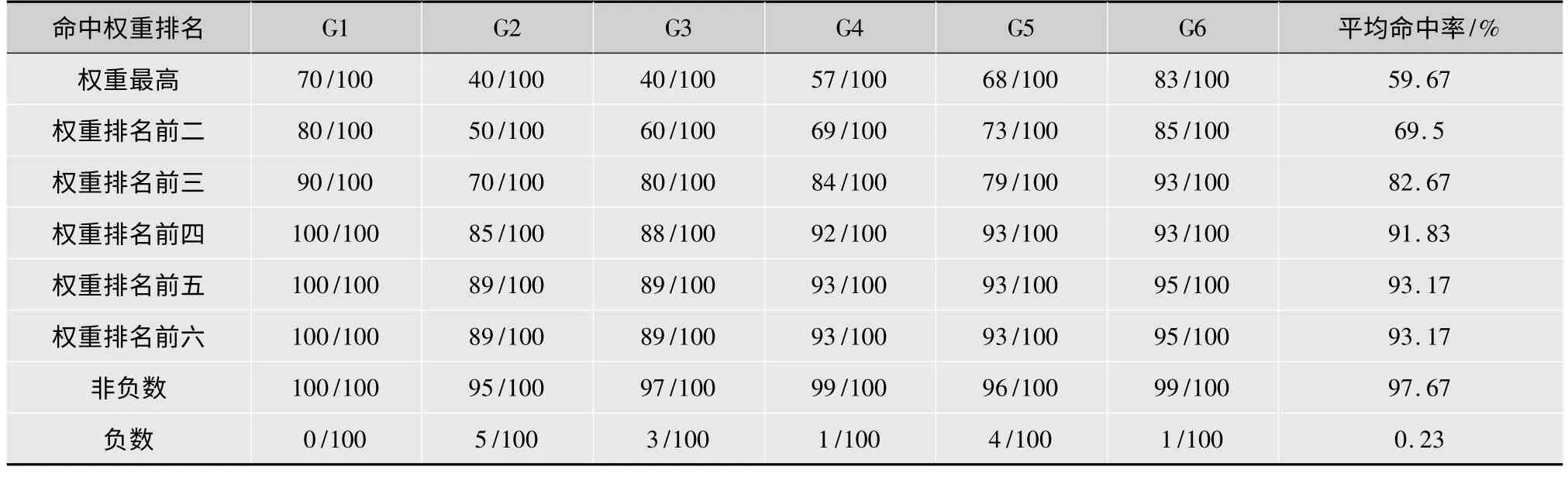
表2 命中最佳预测模式数据统计表
3 小结
随着视频图像高清化的不断发展,家庭数字电视高清化的需求也越来越多,因此越来越多的数字电视推出了高清化频道。现在的高清化频道采用H.264/AVC 编码标准,并且是单独编码单独占一个频道,而其播放内容与标清频道只是分辨率的不同,内容都是一致的,这样就造成了严重的数据冗余和带宽浪费;同时,在播放终端,旧的机顶盒可以解码并播放采用了MPEG-2 编码标清视频标准,而不能正常播放高清视频。本文提出的标准间SVC,可以较好地解决针对不同分辨率视频多次编码的问题,达到一次编码就可以兼容不同版本机顶盒播放的目的。本文给出了标准间空间SVC 详细的异构编码器和解码器架构设计,对关键性问题层间帧间预测、层间帧内预测和层间残差预测分别进行了分析,并根据问题所在提出了相应的解决方案。标准间SVC 的设计,极大地提高了编码的效率及其网络适应性,为数字电视高清化的普及提高了良好的技术支持。
[1]SCHWARZ H,MARPE D,WIEGAND T. Overview of the scalable video coding extension of the H. 264/AVC standard[J].IEEE Trans.Circuits and Systems for Video Technology,2007,17(9):1103-1120.
[2]汪大勇,孙世新.可伸缩视频编码研究现况综述[J].电子测量与仪器学报,2009,23(8):78-84.
[3]王嵩,薛全,张颖,等. H.264 视频编码新标准及性能分析[J].电视技术,2003,27(6):25-27.
[4]WIEGAND T,SULLIVAN G J,BJONTEGAARD G,et al. Overview of the H.264/AVC video coding standard[J].IEEE Trans.Circuits and Systems for Video Technology,2003,13(7):560-576.
[5]SUN Y,XIN J,VETRO A,et al. Efficient MPEG2 to H.264/AVC intra transcoding intransform domain[J].IEEE International Symposium on Circuits and System,2005(5):1234-1237.
[6]PEIXOTO E,IZQUIERDO E.A complexity-scalable transcoder from H.264/AVC to the new HEVC codec[C]//Proc.2012 19th ICIP.[S.l.]:IEEE Press,2012:737-740.
[7]任宏.H_264 扩展标准—可伸缩视频编码(SVC)及其中精细可伸缩编码的研究[D].成都:电子科技大学,2009.
[8]范敏.H.264 可伸缩编码的算法研究及其应用[D].哈尔滨:哈尔滨工业大学,2010.
[9]殷国炯,薛永林.MPEG-2 到H.264 转码的快速模式选择算法[J].电视技术,2010,34(1):26-29.
[10]黄祥林,沈兰荪.基于DCT 压缩域的纹理图像分类[J].电子与信息报,2002,24(2):216-221.
[11]耐格纳威斯基.人工智能:智能系统指南[M].北京:机械工业出版社,2007.
[12]张秀林,王浩全,刘玉,等.基于纹理特征与BP 神经网络的运动车辆识别[J].电视技术,2013,37(13):150-152.
[13]飞思科技产品研发中心.神经网络理论与实现[M].北京:电子工业出版社,2005.
