基于Power Designer的三维工程地质数据仓库模型构建
——以长春市中心区为例
2015-09-09黄静莉
黄静莉
长春工程学院,吉林 长春 130021
基于Power Designer的三维工程地质数据仓库模型构建
——以长春市中心区为例
黄静莉
长春工程学院,吉林 长春 130021
论文以长春市地下空间的岩土体可利用性为研究主题,以勘察工程中提供的钻孔数据及其相关信息为源数据,采用Power Designer16.1设计并实现了长春市中心区的三维工程地质数据仓库的逻辑数据模型和物理数据模型。采用模型驱动架构的方式,利用反向工程技术从Access数据库系统中将现存的数据结构抽取出来形成数据模型,结合研究主题建立了星型数据结构模型,并将生成的SQL脚本文件导入SQL Server2005中进行检查修正后运行正常。
城市地下空间;工程地质钻孔数据;三维工程地质数据仓库;Power Designer
0 引言
地理空间信息的数字化及其应用重点体现在两个方面,一方面是大规模地存储和快速调用海量的地理空间信息数据,一方面是地理空间数据的三维可视化及数据挖掘。因此,国外许多城市诸如纽约、伦敦、大阪等以及国内城市如上海、北京、广州都进行过基于城市地质信息管理和三维可视化的城市三维地质信息系统的研究。
目前现有的工程地质数据主要存储在理正工程地质勘察数据的Access工程备份数据库中,这种传统的工程地质数据库是面向事务设计的,其主要作用是存储工作期间产生的原始数据,绘制地质剖面,并提供简单的查询和分析。但是其数据存储量非常小,且每个工程备份中只能存储一个单一工程的勘察数据,因而不具有对某一宏观主题的决策支持作用。除此之外,不同历史时期、不同行业部门的勘察资料还具有勘察深度不同、试验测试手段不同、土的定名不同、勘察标准不同、坐标系统不同、地层划分不统一等特点。因此,区别于传统的工程地质数据库,三维工程地质数据仓库的构建并不是简单的数据汇总,而是通过对数据源的数据提取、数据集成、数据清洗和数据转换实现对海量工程地质数据的集成管理,其目的是建立面向宏观的城市地质信息管理的决策支持系统。
长春市中心区工程地质数据仓库采用混合架构的方法,在概念模型、逻辑模型和物理模型的架构过程中存在由于用户需要的反复迭代。其特点体现在以下几个方面:①面向长春市中心区地下空间岩土体可利用性的研究主题;②由岩土工程勘察业务驱动;③松耦合、层次化;④采用维度模型的建模工具;⑤具有空间维。
1 研究主题与源数据
论文的研究范围为长春市中心区,其范围为东经125°07′~125°30′;北纬43°44′~44°03′,总面积为380 km2。论文搜集了2006年至今的1 000多个有效的钻孔数据,包含市政工程、道路工程、地铁工程、及工民建工程方面的数据资料。
构建三维工程地质数据仓库的应用需求模式包括[1-4]:浅层地下空间岩土体可利用性评价、中层地下空间岩土体可利用性评价、深层地下空间岩土体可利用性评价、行政区划范围内的地下空间可利用性评价、单项工程实际应用。
构建三维工程地质数据仓库的源数据以表格的方式存储在Access数据库中,包括工程勘察数据、原位测试及土工试验数据,表中的数据由没有实体空间矢量信息的属性数据组成。
源数据经过整理后装载入三维工程地质数据仓库中,被分离成两种数据结构形式,即描述地层空间分布的空间数据和描述岩土体性状的属性数据两大方面。其中,空间数据由工程地质勘察报告中的钻孔数据和长春市地形图数据提供,主要用于反映地形、地层及地下水分布状况;属性数据由工程地质勘察报告中的原位测试机土工实验数据提供,主要用于反映地层岩性、岩土体的物理力学参数。
源数据的清理调整工作包括以下几个方面:
(1)空间数据转换:将描述钻孔点位信息和钻孔工程信息的表格、描述钻孔中地层属性信息和地层层面信息的表格转换为描述地层信息的点实体,构成实体要素表。即将钻孔信息与地层信息联接起来,给每个地层层面高程附上空间坐标信息(X,Y),形成点(X,Y,Z)。
(2)属性数据转换:土工试验数据和原位测试数据都属于属性数据,其中并不包含空间信息。将其读取到属性数据库后,在其中加上地层编号,使之与相应的地层空间数据联接。由于属性数据规格不甚统一,因此在转换过程中应该尽量保持源数据的格式。
(3)地层层面数据调整:按照长春市宏观工程地质分布规律对地层划分情况进行调整。其中,缺失地层按零厚度处理。对于划分较细致的地层或微地貌地层,在不影响宏观分析研究的前提下,应该进行地层合并调整。
(4)地层属性数据调整:对于合并地层,其土工试验、原位测试等试验数据也应调整为经过加权平均后的统计参数,为后期评价计算提供合理可靠的统计数值。
(5)空间插值补齐钻孔数据:对部分缺失钻孔数据的区域,可通过邻近区域的钻孔数据插值,补齐空白区域的地层数据。
(6)对空间数据的粒度粗化处理:在宏观分析背景下,同组工程数据的空间距离较近,造成了数据冗余,会影响数据挖掘分析的速度。因此,有必要对详细数据进行粒度粗化处理,挑选具有空间代表性的数据即可。
2 确定事实与维
为了体现数据的空间性,且减少数据冗余现象,三维工程地质数据仓库以地层空间事实来描述地层的空间和属性分布状态。其度量即为描述地层分布的空间数据,包括空间数据坐标X、Y、Z三个数值,以及描属于哪个地层层面的标识。
在三维工程地质数据仓库中,把数据分为空间数据和属性数据两个部分,其中空间数据存放在事实表中,属性数据分别存放在地层维表、勘探点信息维表、土工试验维表和原位测试维表中。
(1)地层维:主要用于描述地层的属性,包含两个基本层次,分别是勘察野外记录中对地层性质的基本描述以及勘察报告中对地层的特殊属性给出的评价。其中勘察野外记录层次的级别包括地层层号、成因年代、地层岩性、颜色、密实度、湿度、稠度、断面状态及含有物,勘察报告评价的级别包括包括地基承载力特征值、砂土液化、冻胀性、建筑场地类别。
(2)勘探点信息维:主要用于描述勘探工作的基本信息,包含三个基本层次,分别是工程所属的行政区划、工程信息以及工程中的钻孔信息。其中行政区划的级别为工程所属行政区,工程信息的级别包括勘察单位、勘察编号、工程名称、工程日期,钻孔信息的级别勘探点类型、勘探点编号、钻孔深度、地面高程、地下水类型、地下水埋深、地下水标高。
(3)土工试验维:主要用于描述土工试验数据,该维只包含一个层次,其级别分别包括含水率、湿重度、比重、孔隙比、塑限、液限、塑性指数、液性指数、饱和度、压缩系数、压缩模量、天然单轴抗压强度、干燥单轴抗压强度、饱和单轴抗压强度、前期固结压力、压缩指数、回弹指数、有机质含量、粘聚力、内摩擦角。
(4))原位测试维:若按照雪花分层结构设计,原位测试维可以分为7个层次,即十字板、波速、标贯、旁压、静探、动探、载荷。然而为了查询便利,可以按照星型结构直接将十字板表、波速表等原位测试表与事实表相连,成为各自独立的维表。
3 模型设计及实现
采 用 模 型 驱 动 架 构(Model-driven Architecture,MDA)的方式来开发数据仓库。根据Power designer16.1的反向工程功能,从运行系统中将现存的数据结构抽取出来形成数据模型,这样可以加速数据仓库的开发速度,减少数据仓库设计和实现过程中的错误。
首先,安装 ODBC(Open Database Connectivity)中的A ccess驱动,选择系统DSN (Data Source Name),建立ODBC数据源。注意Access2007版本以前的数据库文件为.mdb文件,Access2007为.accdb文件。然后,在Power Designer中通过正向工程生成一个新的物理数据模型,选择数据库(Database)并连接到ODBC数据源。最后在File中选取Reverse Engineer下的Database,将构建三维工程地质数据仓库需要的表(主要包括与原位测试和土工试验相关的表格)选中然后生成PDM,这样就顺利完成了对于理正工程地质数据库的反向工程。该方法的优点是可以保证生成数据的逻辑数据模型与现有的关系数据库一致。然而,其缺点是,中文注释和表外键对应关系在某些情况不能够还原(即只还原了字段,而索引关系没有了)。
使用PowerDesigner建立多维模型可以采用三种方式:第一种是先建立概念模型CDM,然后由CDM生成PDM,其优点是便于检查和调整设计中的错误;第二种是直接建立PDM多维模型,这使得模型在比较简单时其建模速度相对快捷;第三种是由现有数据库的PDM图生成多维模型。论文采用第一种和第三种综合设计的方法,即先设计LDM模型(在Power designer16.1中,没有CDM的设计选择,而是直接选择LDM,然后再生成PDM,其步骤和原理跟第一种方法是一样的)。然后将从Access反向工程导出的表格复制添加到新建的LDM中,这样既保证了在数据抽取和加载时其数据的结构形式与原有数据的一致性,又能够有针对性地建立符合主题需求的数据仓库模型(图1)。
将 Power designer中 的PDM打 开, 在Database中 的Generate Database中 选 择Script Generate,导出生成SQL脚本。将该脚本在SQL Server2005中运行,检查相关错误并修正后,运行正常。
4 数据查询及调用
对工程地质数据仓库的查询调用,主要分为以下两种应用模式:
(1)关键词查询:关键词查询是工程地质数据仓库中的基本查询。比如查询属于某项工程的所有钻孔数据,可以使用查询语句select * from bore_ table where engineering=工程名称。或者从相关的表格中查询属于某项工程的地层属性数据,包括强度参数、水理参数、物理参数、变形参数等。比如查询某项工程中包含的孔隙比参数, 可以使用查询语句select zuobiao_ID, e from soiltest_table where zuobiao_ID in (select zuobiao_ID from bore_ table where engineering=工程名称)。又比如查询属于第三层地层的具有统计意义的孔隙比参数,可以使用查询语句select zuobiao_ID, e from soiltest_ table where zuobiao_ID in (select zuobiao_ID from zuobiao_table where H=3),将该查询结果存储为table1。在对地层属性数据进行空间分析、统计和评价时,需要将属性数据与空间坐标联系起来,可以使用查询语句select zuobiao_table.X, zuobiao_ table.Y, zuobiao_table.Z,table1.zuobiao_ID, table1.e from zuobiao_table inner join table1on zuobiao_table.zuobiao_ID= table1.zuobiao _ID,从而给属性数据附加上空间坐标值(图2)。
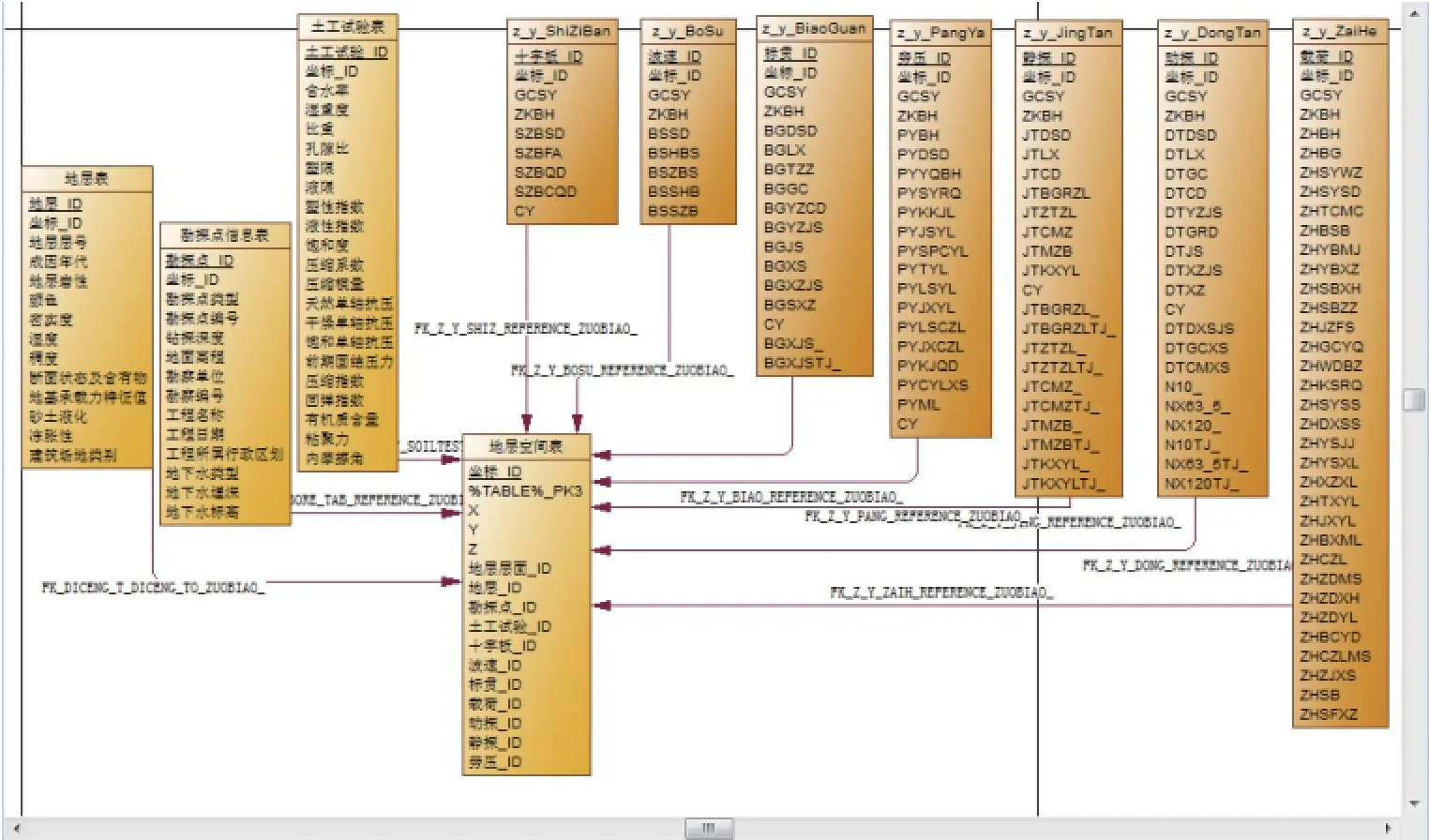
图1 工程地质数据仓库星型结构图(PDM)Fig.1 The star chart of engineering geology data warehouse (PDM)

图2 孔隙比与空间坐标的联合查询Fig.2 Conjunctive query of void ratio and space coordinates

图3 地层层面坐标查询Fig.3 Coordinate query of stratum
(2)内部数据调用:内部数据调用是基于绘图需要而调用的某类特指数据。如在三维可视化工程地质建模时,需要调用研究区范围内钻孔深度大于30 m或钻至基岩深度的钻孔数据。可以从勘探点信息表中select bore_ID from bore_table where bore_ depth >= 30 或者从地层空间事实表中select bore_ ID from zuobiao_table where H_ID= 8。将符合这两个查询条件的钻孔ID抽取出来并合并到table2中,并应用select distinct bore_IDfrom table2来去除重复项目,即为可用数据(图3)。
由于钻孔的地层分层情况不同,在绘制地层层面模型时,还需要按照其地理位置划分成为伊通河以西及以东的数据集。由于伊通河以东的体育馆附近为长春城市坐标原点,因此可以通过selec distinct bore_ID, X, Y, Z fromtable2whereX〉=0来选取东部数据。考虑到在伊通河附近存在有小范围的地层波动,因此在该区域附近的地层是属于哪种地貌单元的需要手动进行分析归类。可以将手动分析调整后的东部数据集存储为table3(图4)。
调取的空间数据需要分别形成地层层面的点文件和井文件。对于点文件来说,每个地层层面的空间坐标信息都应该构成一个单独的点文件,其中包含钻孔_ID和坐标XYZ。比如从表table3和地层空间事实表中继续联合查询属于第一层地层的空间信息数据,可以采用查询语句select bore_ID, X,Y, Z fromzuobiao_tablewhere H_ID=1and bore_ID in (select bore_ID from talbe3)。

图4 东部区域坐标查询Fig.4 Coordinate query of east area
对于井文件来说,其中分别包含钻孔位置信息和钻孔分层信息。如分别从地层空间事实表和勘探点信息表中查询属于某项工程的钻孔_ID,钻孔坐标、孔口高程、钻孔深度等信息,并计算出地层分层厚度,汇总到table4中。然后从table4中查询钻孔位置信息,可以采用查询语句select bore_ID, X,Y, altitude, bore_depth from table4。按照钻孔_ID和地层_ID来排序的钻孔分层信息的查询可以采用语句 select bore_ID, H_ID, thickness from table4 order by bore_ID, H_ID(图5)。
上述空间数据的查询结果可以导出后存储为txt文本,再导入GOCAD中生成三维可视化地质模型。
4 结论
构建三维工程地质数据仓库的目的是为了快速调用存储于不同数据库中、数据格式不统一的海量的城市地质空间数据。在现有工程地质勘察资料的基础上,以城市地下空间岩土体可利用性为研究主题,对源数据进行清洗调整,获得用于构建三维地质地层模型和决策分析的空间数据和属性数据。该模型即能保证数据格式的统一性,又能快速建库,清洗冗余数据,使得数据仓库的数据抽取和存储更为简单。构建的三维工程地质数据仓库模型在SQL Server2005中运行正常。其数据查询和调用结果能够为后期三维地质地层建模和城市地下空间岩土体可利用性评价体系提供有效数据。
[1] 童林旭.地下空间概论(一)[J].地下空间, 2004, 24(1):133
[2] Huang JL.Analysis and Evaluation of the available rock and soil mass in underground space in ChangChun,China.[J].GEOCHIMICA ET COSMOCHIMICA ACTA.2009, 73(13):A558-A558.
[3] Huang JL.Contemporary geo-space use and environment improvement.GEOCHIMICA ET COSMOCHIMICA ACTA.[J].2010, 74(12): A429-A429
[4] 黄静莉,王清.城市地下空间岩土体的可利用性研究[J].煤炭技术.2011,30(10):110-112.
[5] 刘如九,张振山,柴天佑.一种通用的多数据库间数据抽取方法及应用[J].北京交通大学学报,2008,32(4):14-18.
[6] 杨莉国,欧付娜,刘庆海等.数据仓库相关技术研究综述[J].电脑知识与技术.2011,7(10): 2234-2236.
[7] 郭 峰.数据仓库技术在GIS决策支持中的应用[J].华中农业大学学报.2003,22(1):60-64.
[8] 葛 凡,祝玉华.空间数据仓库综述[J].许昌学院学报.2010,29(2): 81-83.
[9] 沙宗尧,空间数据仓库体系结构框架的概念模型[J].地理空间信息.2008,6(1):18-21.
[10] 于焕菊,谢传节,李云岭等.中国华北地区地震空间数据仓库的构建与分析[J].地球信息 科学.2006,8(3):88-93.
Three-dimensional engineering geology data warehouse constructed by Power Designer:In the case of the centre area in Changchun City
HUANG Jing-li
Changchun Institute of Technology, Changchun 130021, China
The Three-dimensional engineering geology data warehouse is constructed by Power Desinger16.1, with the rock and mass availability in urban underground space as the theme, and the borehole data of engineering investigation as the source data.Use the model-driven architecture method, reverse engineer the access data base, extract existed data model, combine research theme to construct the star data structure model.And check the SQL script in SQL Server2005,to ensure normal operation.
urban underground space; engineering geology borehole data; three-dimensional engineering geology data warehouse; Power Designer
P642.4;TP317.4
A
1001—2427(2015)04 - 132 -5
2015-08-05;
2015-12-17
黄静莉(1982—),女,山西运城人,长春工程学院讲师.
