熵值标准下数据信息量的FCM改进
2015-08-27李春忠
徐 健,李春忠
(安徽财经大学 统计与应用数学学院,安徽 蚌埠 233030)
在现代信息技术迅猛发展的背景下,越来越多的领域都采用数据驱动的方式进行研究。应运而生的数据技术从传统的统计分析到数据挖掘,再到现今的云计算和大数据都很好的给生产生活带来更多的价值。但是随之而来的数据量度和尺度都变得纷繁复杂,再加上各行业所取观测指标的不同使得数据在单位、量纲和指标含义等客观情况下呈现很大差异性和不确定性,特别是经济数据指标的数值差距过大,因此给数据技术方法本身的可行性以及所得结果的可靠性带来很大挑战。传统的数据预处理中多采用清理、变换和规约等方法来提高数据质量[1,2],在大多数文献中多采用Min - Max标准化[3,4]、Z -score 标准化[4]、Decimal scaling 小数定标标准化[5]以及Log 和Atan 函数转化[6]来处理数据,并不着重讨论数据达到的质量程度。但是由于标准化方法的一些理论局限性,容易在处理中降低数据的信息量。所以在研究中如何能够判断标准化后数据信息量的改变程度,这对采用的技术方法本身和后续结果分析将起到重要的作用。本文将尝试探讨数据信息量衡量熵标准,并从理论层面和结合皖北沿淮区域经济发展数据做相应的实证分析。
一、构建熵标准下FCM 分类改进模型
(一)信息熵与FCM 准备
1.数据质量的信息熵标准
热力学第二定律表明孤立系统中任何变化都不可能减少熵值,1948年Shannon 定义通信信号中平均信息量为熵[7],从此熵作为衡量信息量的一种方式被广泛应用。信息熵是数据含载信息程度的一种度量方式,当信息熵越大时表明数据越无序,需要理清数据所需信息就越多,也说明数据的信息量越大。离散随机变量的信息熵定义为自信息的平均值
其中Ⅰ(x)为事件的自信息,E p(x)表示对随机变量的概率取平均运算。其具有熵的非负性、对称性、扩展性和可加性等相关性质。
2.模糊C 均值聚类FCM
模糊C 均值聚类[8,9](FCM)是由Bezdek 在1981年提出的一种模糊分类方法,FCM 需要根据类中距和类间距构造分类准则,利用预先给定的分类数C 对所给样本点进行分类。即求解规划问题:
(二)熵标准下FCM 分类改进模型
由于熵值代表了数据的信息量,而通过衡量信息量可以产生评价策略,陈衍泰等在综合评价方法分类的研究中总结了信息熵方法应用在评价领域的情况[10],张树森等将熵与聚类算法结合提出改进的模糊聚类算法EFC[11],韩宇平等将最大熵原理用于评价区域水资源短缺问题[12],刘红琴等将信息熵应用到能源消费的分配衡量中[13],本文考虑将信息熵引入到数据质量的评价中。
再由于区域发展数据在数值上差距过大,如果仅仅统一进行z -score 标准化处理则可能带来信息损失,本文考虑利用FCM 方法将数据进行分类标准化,这样也同时带来数据扁平化特征,而由离散最大熵定理[7]可知,数据出现概率越相同,那么数据的信息熵越大。
因此在分类标准化后的数据信息量比直接标准化的信息量要大。从分类的角度来看,分类后数据标准化数值会产生比整体标准化更多的多样性,从而带来的信息量的增加,而数据信息量的增加也给后续的研究方法提供更好的数据质量。
二、基于区域发展面板数据的实证分析
(一)指标体系构建与数据来源说明
1.区域发展指标体系构建
结合前期工作制定指标体系[14]21,指标的选取原则兼顾经济、生活、环境、社会、特征产业和可持续发展的指标体系,构建一级指标,细化二级指标共选取5个一级指标和69个二级指标如图1 所示,并由此构建整体指标模型和各级别体系。
具体指标表现为:(1)在经济发展与产业结构方面:GDP;城镇固定资产投资额;出口总额;进口总额;农业总产值;工业总产值;建筑业乡村从业人员数;交通运输、仓储及邮政业乡村从业人员数;乡村私营企业从业人员数;农、林、牧、渔业乡村从业人员数;乡村个体从业人员数;工业从业人员年平均人数;城镇房地产开发投资额;(2)民生能力与生活质量:职工工资总额;总户数;农民人均纯收入;城乡居民储蓄存款余额;社会消费品零售总额;城镇居民最低生活保障人数;新型农村合作医疗参合率;建成区绿化覆盖率;城市出租汽车数;公共汽(电)车客运总量(市辖区);人口自然增长率;城市公共汽(电)车客运总量;城市每万人拥有公共交通车辆数;城市人口密度;人口密度;基本养老保险基金支出;基本医疗保险参保人数;人均公园绿地面积;(3)政府管理与社会服务:财政收入;财政支出;财政用于教育的支出;财政支出中卫生经费;等级公路里程;公路货物周转量;公路旅客周转量;公路客运量;铁路客运量;城市道路长度;城市供水总量;城市清扫保洁面积;城市天然气供气量;地质灾害防治投资;城市公园数;街道办事处数量;(4)资源实力与可持续发展:降水量;人均水资源量;土地面积;林业用地面积;水田耕地面积;城市污水排放量;生活垃圾无害化处理率;城市排水管道长度;城市污水处理率;工业废气排放量;工业废水排放量;“三废”综合利用产品产值;(5)教育产业与创新科技:财政用于教育的支出;普通高等学校数;普通高等学校在校学生数;普通高中在校学生数;普通小学在校生数;发明专利申请受理量;发明专利授权量;科技活动人员数;
基于以上初步指标体系充分涵盖从经济发展到人民生活,从政府能力到社会服务,从可持续发展到特色产业的方方面面,兼顾发展的效率、速度、质量、潜力和能力。但是在数据收集中往往遇到很多实际情况需要做修正,对于少部分的数据遗漏采用数据拟合回归和缺省值补充等传统数据预处理方法进行修整[1],对于大部分的数据遗漏则采用指标替换的方式进行变通。
2.面板数据来源说明
本文依托皖北沿淮地区6 市39 县区的区域发展研究,因为在皖北沿淮地区中蚌埠市和淮南市具有相同的地缘特征和相似生活特征,所以对两个地区指标的衡量具有很好的实际意义,故而采用2005年到2012年蚌埠市和淮南市数据,数据来源于中国知网提供的《中国统计年鉴》、《中国城市统计年鉴》和各地区发展统计年鉴等。同时本文数据属于面板数据,可以克服时间序列分析受多重共线性的困扰,能够提供更多信息、变化、自由度和估计效率。
(二)具体实证分析
本文的具体实证分析分为以下三个方面:(1)对于原始数据的处理过程:按照论文前面介绍的科学指标模型和数据采集来源,将两个城市69个属性从2005年到2012年共8年的数据进行矩阵化,得到一个138 行8 列的原始数据矩阵,对于原始数据矩阵中的缺省值采用外插和内插法进行相应的差值拟合得到完整的使用数据。(2)对于使用数据的分析过程:第一步根据本文前期工作[14]22通过对数据进行谱系聚类、HCM 和FCM 三种聚类方法,采用Matlab2012b 进行编程,比较从分2 类到分10 类的由R 方统计量和伪F 统计量得到的半偏相关统计量SPRSQ 数值,发现当分三类时谱系聚类方法和HCM 的SPRSQ 数值达到最高值分别为0.400 1 和0.023 9,而FCM 的SPRSQ 数值在分四类时达到最高值0.027 0,因此在进行分类构建信息熵时,将分三类和分四类的情况均予以考虑。第二步根据论文前面讨论的信息熵构建过程进行分类信息熵构建,首先将利用FCM 对数据分三类和分四类得到的数据集{xij}i=1,…C,j=1…ni(其中C =3 或者4),在每个数据集进行z - score 标准化:然后讨论这些数据在分D 段中出现的概率其中分段数D 的大小要足够体现数据概率分布特征[7,11]取D 分别为10和20 两种情况,计算相关信息熵数值最后通过和没有进行分段改进的原始数据集的未标准化和统一标准化两种情况进行比较得到相关结论。(3)对于数值比较的分析结果:通过比较未标准化、普通的列统一标准化和采用FCM 分三类和四类的类标准化的三种方法在取分段数为10 和20 下的信息熵大小,得到了相关的数值结果表1。
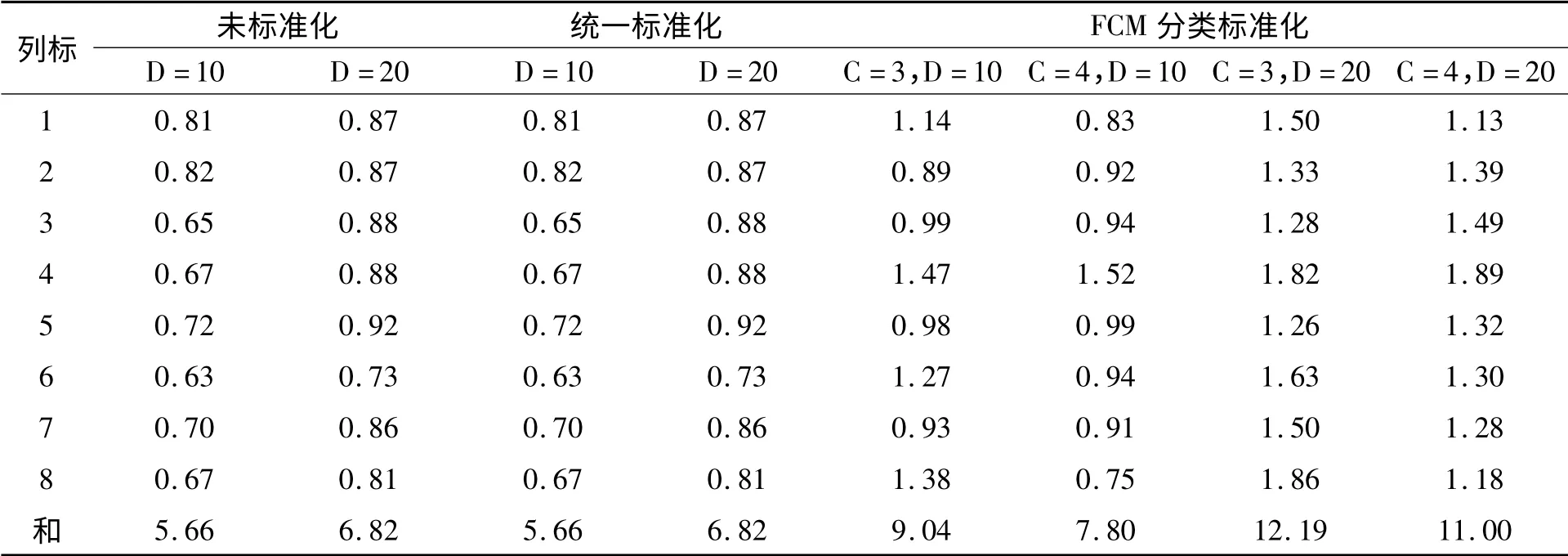
表1 三种标准化的数据信熵衡量表
对表1 中的相关数值做图进行直观的表达,可以得到在分10 段情况下的图2 和分20 段情况下的图3,其中横坐标为从2005年到2012年每一年的数据情况,从图中可以发现不论哪一年的数据数值在分类标准化后的熵值都高于图中最下面的线,即统一标准化的数据熵值。
从以上图表的结果来看,采用FCM 算法对于数据分类标准化后得到的信息熵提升效果是明显的,具体可以概括为以下的一些结论:
1.未标准化和统一标准化的结果数值完全一样,这是因为z-score 标准化过程并不改变数据分布特征,因此他们拥有相同的概率分布,则信息熵也完全一致,故而数据所含信息不变,因此在作图阶段就不体现未标准化的结果图形。
2.分段标准化后所有的数据结果均大于统一标准化的数据值,即信息熵在分段标准化后都有显著提高,这和理论推导的结果一致。故而分段标准化的方法可以有效消除量纲差异,同时还能有效的提高数据信息熵,从而使得数据含有更好的信息量。
3.就分段标准化而言从所有列信息熵的总和数值可以发现,在两种最佳聚类数时信息熵的总和情况分别可以表示为:分10 段3 类时的9.07 高于4 类时的7.8,分20 段3 类时的12.19 高于4 类时的11;同时数据信息熵随着分段的增大数值也在增大,这是信息熵本身性质所决定的,因为分段越多概率分布越接近均匀分布,由离散最大熵定理以及本文理论推导可知数据信息熵在增加。但是如果分段过多,甚至达到数据总量的一定比例,此时再高的信息熵数值也并不能够说明很好的信息量,所以在分段数的选取需要与数据总量相互匹配。
三、结论
根据以上论证发现,从理论角度和实证分析都验证了分类标准化可以有效的提高数据信息量。所以在相应数据分析方法使用之前,对于数据标准化处理阶段可以尝试采用分类标准化的方式,这样既可以消除数据量纲差异,也可以有效的提高数据含载信息,为进一步使用数据挖掘方法得到更好的数据结论提供较好的前期准备。
同时由于在数据集统一标准化中均值唯一,相当于只有一个中心节点。但是在分类标准化后,在不同类中都有相应的均值作为中心节点,所以分类标准化比传统的统一标准化更符合现代互联网思维,那就是去中心化和多节点多分类,以及扁平化结构体系的相关思想。
[1]Jiawei Han.Data Mining Concepts and Techniques,Second Edition[M].BeiJing:China Machine Press,2008:30 -65.
[2]韩京宇. 数据质量研究综述[J]. 计算机科学,2008(2):1 -5.
[3]程惠芳,唐辉亮.开放条件下区域经济转型升级综合能力评价研究——中国31个省市转型升级评价指标体系分析[J].管理世界,2011(8):173 -174.
[4]张钢. 长江三角洲16个城市政府能力的比较研究[J].管理世界,2004(8):18 -27.
[5]安悦.基于微博客的手机供应商排名推荐[J]. 数学的认识与实践,2013(10):23 -29.
[6]汪冬华.我国沪深300 股指期货和现货市场的交叉相关性及其风险[J]. 系统工程理论与实践,2014(3):631 -639.
[7]田宝玉. 信息论基础[M]. 北京:人民邮电出版社,2008:18 -26.
[8]史小松,黄勇杰,刘永革.数据挖掘技术中聚类的几种常用方法比较[J].中国科技信息,2009(20):99 -105.
[9]诸克军,苏顺华,黎金玲. 模糊C 均值中的最优聚类与最佳聚类数[J]. 系统工程理论与实践,2005(3):52 -61.
[10]陈衍泰.综合评价方法分类及研究进展[J].管理科学学报,2004(2):69 -77.
[11]张树森.改进的基于熵的中心聚类算法[J].计算机与现代化,2014(3):53 -56.
[12]韩宇平.基于最大熵原理的区域水资源短缺风险综合评估[J].安徽农业科学,2011(1):397 -399.
[13]刘红琴.基于信息熵的省域内能源消费总量分配研究[J].长江流域资源与环境,2014(4):482 -489.
[14]徐健.基于数据挖掘的区域发展指标分析[J].渤海大学学报:人文社科版,2014(5):21 -35.
