含混性与多值逻辑
2015-08-20陈明益
陈明益
(中山大学哲学系,广东广州510275)
一、含混性引发的逻辑疑难
根据二值原则,我们言说某事物的话语是或者真或者假,因此相对于会话语境我们表达话语的语句就有确定真值。按照弗雷格、罗素和早期维特根斯坦的观点,一种逻辑上完善的语言是二值的,并且这种语言中的每个合式公式都是或真或假,可见二值对于现代逻辑核心的形式系统的所有标准解释是必不可少的。然而,二值原则对于日常语言的许多语句是成问题的。我们看下列三个语句:
(1)明年12月21日中午我将在北京。
(2)飞马有一条白色的后腿。
(3)蒂莫西·威廉姆森(Timothy Williamson)是瘦的[1]185。
语句(1)涉及未来偶然事件,因为它在当下时刻既不能肯定也不能否定,只是可能而非必然,所以它既不真也不假。语句(2)包含空名或虚构名称,即其中的单称词项“飞马”没有指称,所以它也没有确定真值。语句(3)同样没有确定真值,因为它包含的谓词“是瘦的”具有含混性(vagueness)。
通常,我们把“是瘦的”这类谓词称作含混谓词,日常语言中有许多这样的词,如“是秃头”、“是高的”等。含混谓词的主要特征是它应用来描述的事物情形与不能应用来描述的事物情形之间没有精确边界,总会出现边界情形(borderline case)。以“是瘦的”为例。它可以用来描述体重仅为50公斤的成年男性,不能用来描述体重100公斤的成年男性,但它能否用来描述体重75公斤的成年男性则是不确定的。因此,就威廉姆森的身材来说,没有人知道他是否是瘦的,即使将他的体重测量结果与其他人进行比较也无法做出断定。于是,类似体重75公斤的人这样的情形就属于含混谓词“是瘦的”的边界情形。当描述边界情形时,包含含混谓词的语句没有确定真值,我们把这样的语句称作边界语句(borderline sentence)。上述语句(3)就可能是一个边界语句。基于此,排中律的一个实例“或者威廉姆森是瘦的或者威廉姆森不是瘦的”也没有确定真值。因此,日常语言的含混性导致经典逻辑的排中律或二值原则失效。
不仅如此,当我们用经典逻辑的有效规则对包含含混表达式的语句进行推理或论证时,堆垛悖论(sorites paradox)便会产生出来。含混谓词应用的情形没有精确边界,这就意味着它指称的概念的外延没有固定界限,或者说它的外延边界是弹性的。按照莱特(C.Wright)的观点,含混谓词具有容忍性(tolerance),也即它能够容忍谓词外延范围内的细小变化而不会造成大的影响[2]。例如,如果“是瘦的”可以应用于体重50公斤的成人,那么它也可以应用于体重50.1公斤的成人。我们可以用含混谓词“是瘦的”描述这样一个序列的事物:a0,a1,a2,……,an,其中a0表示“体重 50 公斤的成人”,an表示“体重 50+n/10 公斤的成人”。这样的序列我们称作堆垛序列,在这个序列上任意两个相邻事物间的差异非常之小以致无法区分,如果含混谓词可以应用于an,那么它必定也可应用于an+1。此外,含混谓词可以明确地应用于序列的第一个事物,而不能应用于序列的最后一个事物。显然,“a0是瘦的”为真,并且对于任意n(n为自然数),如果“an是瘦的”为真,那么“an+1是瘦的”也为真。经过连续多次运用分离规则(modus ponens),我们可以证明体重100公斤的成人是瘦的(也即n=500)。这个结论明显为假。我们可以换用不同的含混谓词做出同样论证,例如“是秃头”、“是红的”,最后得到的结果分别是“无论有多少头发我总是秃头”、“红色是蓝色”。借用这种堆垛论证,我们几乎可以证明任何明显为假的事情。堆垛论证有许多不同种类的形态,海棣(D.Hyde)曾给出六种不同的论证型式[3]1~17。我们在此主要关注它讨论最多的标准型式,也即条件句型式的堆垛论证。我们熟知的(谷)堆悖论和秃头悖论都可使用这种型式表达。令F表示含混谓词,a0,a1,a2,……,an表示相应的堆垛序列的事物,条件句型式的堆垛论证可以表述如下:

堆垛论证之所以称为悖论,是因为它的前提都看起来为真,推理也是有效的,结论却为假。关于悖论,我们至少可以有三种方式拒斥它:或者证明它的论证不可靠,因为它实际上有某个或某些假的前提;或者证明它的论证形式无效,因为它使用的推理形式无效;或者两者兼有之。确实,一种好的含混性解释理论应当能够提供堆垛悖论的一种好的解决方案。
二、三值逻辑的解决方案
既然经典二值逻辑不能处理含混性问题,作为基于哲学的考量而产生的第一个非经典逻辑,多值逻辑自然被用作一种替代方案。我们这里仅考虑三值逻辑。不过,大多数三值逻辑的产生不是由于含混性问题。例如,皮尔士(C.S.Peirce)既关注过含混性问题又考虑过三值逻辑,但是他没有发表他的三值表,我们也不清楚他对三值逻辑的信念有多坚定,所以皮尔士是否有意将三值逻辑的基本原理应用于含混性问题尚不得而知。卢卡西维茨在1920年代正式提出的第一个三值逻辑系统也是基于自由意志或非决定论问题。俄国数学家鲍契瓦尔(D.Bochvar)在1937年提出两个非常不同的三值逻辑系统,但他的动机是为了解决经典逻辑和集合论中出现的悖论,特别是说谎者悖论。克林(S.C.Kleene)在1938年受到数学基础研究的启发创立了一种强三值逻辑,后又在1952年的《元数学导论》中建立弱三值逻辑,但他的动机主要来自算术。
第一位尝试将多值逻辑用来解释含混性的人是瑞典逻辑学家哈尔登(S.Hallden)。他在1949年的著作《无意义的逻辑》中认为,一个命题是“无意义的”意指它既不真也不假[4]9。因此,边界语句的真值就是无意义,既不真也不假。例如,“1000根头发的人是秃头”是“无意义”命题。哈尔登通过采用一种包含真、假和无意义的三值逻辑来适应“无意义”的语言。为此,他给出一个包含二值真值表的三值表,如果每个支命题是真或者假,那么复合命题拥有与二值表相同的真值;如果任何一个支命题是“无意义”,那么复合命题也是“无意义”(见表1)。除了表1所示真值表外,哈尔登还引入一个新的一元算子+。+p意味着p是“有意义的”。因此,如果p是“无意义”,+p就为假而不是“无意义”。否则,它为真(见表2)。因此,┐+p意味着p是“无意义”。哈尔登将真和无意义都当作指派值,也即非假的保存。他给出的有效性定义是:一个公式是有效的,只要它不为假而不必为真。

(表 1)
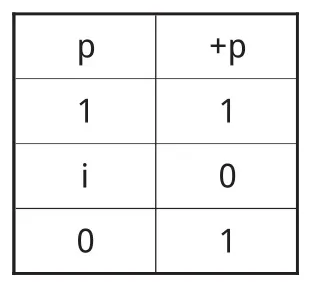
(表 2)
显然,根据哈尔登的三值逻辑,条件句型式的堆垛论证是一个无效论证,因为它使用的推理规则是无效的。也就是说,分离规则在哈尔登的三值逻辑系统内是无效的。我们来检验这个规则的一个应用形式是否有效,也即从(p∨┐p)→+p和p∨┐p到+p的推理。无论我们如何赋值,它的两个前提都不为假,但当p是“无意义”时它的结论为假。因此,分离规则对于涉及算子+的公式无效。我们再看分离规则对不涉及算子+的公式是否有效。当p是“无意义”并且q为假时,前提p→q和p不为假而结论q为假,分离规则仍然无效。由此可知,根据哈尔登的三值逻辑的有效性定义,分离规则缺少有效推理形式的属性:当前提采取指派值,结论也取指派值。但是,按照这个有效性定义,排中律是有效的,因为它虽然不为真但也不为假,而这与排中律在含混语言中失效的观念相矛盾。因此,哈尔登的三值逻辑似乎不是适合含混语言的有效逻辑。
科尔纳(S.Korner)在1966年的著作中用一种不同版本的三值逻辑来处理含混性问题[5]37~40。科尔纳将他的三值逻辑称为“不确切概念的逻辑”。根据科尔纳的观点,不确切性源自事例所定义的概念的边界情形。这样的概念F将对象划分为:正面候选者,也即必定被选择为F的正面实例;反面候选者,也即必定被选择为反面实例;以及中立候选者,也即可能选择为正面或反面实例,这依赖于自由选择。由此,就有一种三值的前选择逻辑和一种二值的后选择逻辑。概念的三种候选者对应三种命题:真、假和中立。真和假被想象为稳定态,中立被想象为临时态。我们可以通过自由选择选取一个中立命题为真或假。科尔纳的三值语义真值表如下(表3):

(表 3)
从科尔纳的三值表,我们看到否定和等值联接词的语义解释与哈尔登的三值表相同。但是两者也有不同:首先,科尔纳取消了哈尔登的一元算子+的真值表;其次,对于合取联接词,当一个合取支为假而另一个合取支是中间值时,根据哈尔登的三值表合取式为中间值而根据科尔纳的三值表合取式为假;再次,对于析取联接词,当一个析取支为真而另一个析取支为中间值时,根据哈尔登的三值表析取式为中间值而根据科尔纳的三值表析取式为真;最后,对于蕴涵联接词,当前件为中间值而后件为真,或者当前件为假而后件为中间值时,根据哈尔登的三值表条件句为中间值而根据科尔纳的三值表条件句为真。
科尔纳似乎没有明确说明将哪个或哪些值作为指派值并给出相应的有效性定义。按照科尔纳的三值表,如果真是唯一的指派值,没有公式将是有效的,因为当一个公式的所有语句变元都是中立的时候这个公式是中立的。不矛盾律、同一律都是无效的,不过分离规则是有效的。如果真和中立都是指派值,那么有效的公式将与经典逻辑的那些有效公式相符,但分离规则例外,因为当p为中立值而q为假时,p→q和p都取指派值而q取非指派值,因而推理无效。但是,在这种有效性定义下排中律仍然成立。因此,将科尔纳的三值逻辑用来处理含混性问题确实是一个困难。
三、模糊逻辑的解决方案
以三值逻辑为代表的有限多值逻辑(其值的数量为n,n为自然数且n≥3)将真值划分出离散的边界与堆垛序列的连续性不相容,因此人们猜想真值可能是连续地变化,由此产生一种“真”以连续的度变化的逻辑,这就是模糊逻辑。卢卡西维茨创立的连续值或无限值逻辑是形式化的模糊逻辑的基础。一些得到最广泛研究的模糊逻辑都是建立在卢卡西维茨的无限值系统基础上。在后来模糊集合的基础上发展出一种形式上相似于连续值逻辑的模糊逻辑,因而连续值逻辑被看作建构模糊逻辑的一种自然和基本方式。模糊逻辑通过一系列规则和多值逻辑联系起来,主要运用了卢卡西维茨的连续值逻辑(continuumvalued logic)[6]。
我们令语句p的真度是[p],它被假定为0和1之间的实数。当p是完全真时,[p]=1;当p是完全假时,[p]=0;当q是至少和p一样真时,[p]≤[q]。卢卡西维茨的连续值逻辑有以下语义学:

(≡)[p≡q]=1+min{[p],[q]}-max{[p],[q]
(∀)[∀xFx]=Glb{[Aa/x]:对于所有的a}(即所有实例的真度的最大下界)
(∃)[∃xFx]=Lub{[Aa/x]:对于所有的a}(即所有实例的真度的最小上界)
在这种模糊语义学中,卢卡西维茨将1(即完全真)作为唯一的指派值,一个公式是有效的只要它在其原子语句的任何真度赋值下皆为完全真。因此,推理形式是有效的只要它的结论在所有前提为完全真的赋值下为完全真,也即有效性被定义为完全真的保存。但是,也有哲学家将有效性定义为真度的保存,即结论的真度不低于最低值的前提的真度。
根据上述模糊语义学,我们可以赋予边界语句一定的真度(0到1之间)。以含混谓词“是秃头”为例,那么就有一个堆垛序列:a0,a1,a2,……,an,其中a0表示“有 0 根头发的人”,an表示“有 n 根头发的人”。显然,“a0是秃头”为真,并且对于任意n(n为自然数),如果“an是秃头”为真,那么“an+1是秃头”也为真。假设n=100000,通过连续运用10万次分离规则,我们可以得到结论“有10万根头发的人是秃头”,这个结论明显为假。问题是,这里使用的分离规则是否有效。这就依赖于我们采用什么样的有效性标准。如果有效性被定义为完全真的保存,那么分离规则是有效的,因为如果p和p→q在度1上为真,那么q也是。在这种意义上,堆垛论证是有效的,但这意味着一个有效论证可以有几乎完全真的前提和完全假的结论。如果有效性被定义为真度的保存,那么分离规则不是有效的,因为如果p和p→q在至少99999/100000的度上为真,那么q可能只在99998/100000的度上为真,这样结论的真度就低于前提的真度。我们换种简单的方式来说明。例如,当[p]=0.7,[q]=0.6,[p→q]的真度就为 1+0.6-0.7=0.9,这样前提 p 的真度为0.7,另一前提p→q的真度为0.9,而结论q的真度为0.6,显然结论q的真度低于最低值的前提p的真度,这违反了有效性标准。因此,如果分离规则不是有效的,那么堆垛论证就是一个无效论证。
然而,按照模糊语义学的分析,堆垛论证不在于它是有效还是无效,它其实是不可靠的,因为它包含假的前提。为什么我们不能识别出这些假的前提,并且还倾向于接受这些假前提呢?在上述有关秃头的堆垛论证中,它的第一个前提Fa0是完全真,而结论Fan是完全假。根据真度理论,随着n从0增加到100000,Fan的真度在不知不觉地减少。但是,为什么我们无法察觉到这种减少呢?我们可以使Fan在1-(n/100000)(0≤n≤100000)的度上为真(这样Fa0是完全真而Fa100000是完全假),于是真度从Fan到Fan+1的下降仅仅是1/100000,这意味着在堆垛论证的每个条件句前提中,前件仅仅由于1/100000的程度比后件更真。根据蕴涵联接词的解释(→),每个条件句前提在99999/100000的度上为真。我们在连续运用分离规则的过程中不断从前提Fan(在(100000-n)/100000的度上为真)和Fan→Fan+1(在99999/100000的度上为真)推出结论Fan+1(在(99999-n)/100000的度上为真)。因此,中间结论的真以1/100000的程度在不断下降。由于论证的每个步骤都是同等地位,所以每个条件句前提都是几乎完全真,不存在一个切割点可以区分从真到假的转变。在堆垛论证的条件句前提中细小的假度导致它的结论中高的虚假度。我们无法察觉这种细小的假度,反过来由于这些条件句前提的真度极高(几乎接近完全真),所以我们又倾向于接受它们。因此,堆垛论证可能既是无效的,也是不可靠的。
四、多值逻辑解释的困境
以三值逻辑和模糊逻辑为代表的多值逻辑已经发展成为解释含混性的一种标准理论,但是由于下述两个方面的困难,它很难成为一种好的含混性解释理论,因而也不能提供一种好的关于堆垛悖论的解决方案。
首先,一个困难是高阶含混性问题。三值逻辑直接遭遇二阶含混性问题。既然人们认为将含混命题划分为真与假是不合理的,同样将含混命题划分为真、假和中间值也是不合理的。如果我们认为经典二值逻辑将真与假之间划分清晰的界线是反直觉的,那么三值逻辑将真与中间值以及中间值与假之间划分清晰界线也是反直觉的。例如,当仅有一粒谷子的时候,语句“这是一个堆”明显为假,但是随着我们每次不断增加一粒谷子,在某个时刻上这个语句就变为真(比如增加到100万粒谷子)。然而,我们不能识别出一个切割点(也即增加到多少粒谷子的时候),在这个点上语句由假变为真。同样,我们也不能识别出两个这样的切割点:一个是从假转变成中间值,另一个是从中间值转变成真。如果两个值不够,那么三个值(甚至更多值)也是不够的,反对二值逻辑的论证同样适用于自身。因此,三值逻辑遭遇的二阶含混性将继续导致高阶含混性:“最初划分为三类(真/假/边界)让位于划分为五类(清晰的真/真和边界之间的边界/清晰的边界/假和边界之间的边界/清晰的假),这又依次让位于划分为九类,等等。这不是一个可接受的递归。分割成新的类是我们还没有充分解释这种潜在现象的征兆”[7]。因此,解决三值逻辑的困境不是用更多值(比如十七值)的逻辑来替代三值逻辑,因为反对三值逻辑的论证同样适用于n(n≥3)值逻辑,而且n的选择是任意的。这也是为什么应用于解释含混性的多值逻辑逐渐趋向于使用无限多值的模糊逻辑。但是,模糊逻辑也有类似问题。模糊逻辑用两个其他的划分来代替真假划分:“在度1上的真与小于1的正度上的真之间的划分,以及在大于0的某个度上的真与在度0上的真之间的划分”[7]。事实上,我们把某个模糊真值赋予给每个对象形成特殊函数,再将日常语言的每个含混谓词与这些特殊函数相联系,并将每个含混语句与特殊的模糊真值相联系,这种做法只会造成人为的清晰性,因而是不合理的。
其次,解释含混性的多值逻辑都暗地假定了真值函项的理念,也即根据真值函项联接词形成的复合句的真值分类依赖于其子句的真值分类。模糊逻辑的度函项就体现了这种真值函项理念。真度理论假定复合句的真度是其成分句的真度的函数,因此在模糊逻辑中联接词同样被真值函项地定义。然而,这种度函项假定存在问题。假设p在与q相同的度上为真,那么p∧q与p∧p也在相同的度上为真。既然p∧p与p在相同的度上为真,那么p∧q也与p在相同的度上为真。我们假设某人渐渐入睡,语句“他是醒着的”和“他是睡着的”都是含混的。按照真度理论,随着前者在真度上下降而后者在真度上上升,在某个点上它们就有相同的真度,也即中间真度。因此,合取式“他是醒着的并且他是睡着的”也有相同的中间真度。然而,根据定义“醒着”和“睡着”是相互排斥的,“他是醒着的并且他是睡着的”根本就不可能为真,我们人不可能处在这个合取式为真的情形与它为假的情形之间的不清楚区域。如果我们用“他不是醒着的”代替“他是睡着的”,那么在某个点上“他是醒着的”为半真(中间真度),所以“他不是醒着的”也为半真,于是“他是醒着的并且他不是醒着的”也将算作半真。一个明显的矛盾式怎么可能在任何度上为真而不是假呢?因此度函项对于合取式是失效的,同理可知,度函项对于析取和条件句都失效。真值函项对于最基本的逻辑算子的语义学很重要,但它可能不是根据度来描述。因此,通过用真度取代真值从而将真值条件语义学适用于含混语言,这种做法是失败的。按照威廉姆森的观点,多值逻辑虽然在提高形式化程度方面致力于解决含混性问题,但它却与含混性问题的哲学动机不一致[1]130。
[1]Williamson,T.Vagueness[M].London and New York:Routledge,1994.
[2]Wright,C.Further reflections on the Sorites Paradox[J].Philosophical Topics,1987,15(1).
[3]Hyde,D.The Sorites Paradox[M]//Giuseppina Ronzitti.Vagueness:A Guide.Dordrecht·Heidelberg·London·New York:Springer,2011.
[4]Hallden,S.The Logic of Nonsense[M].Uppsala:Uppsala Universitets Arsskrift,1949.
[5]Korner,S.Experience and Theory[M].London:Routledge&Kegan Paul,1966.
[6]霍书全.多值逻辑与悖论[J].中国社会科学院研究生院学报,2010,(5).
[7]Eklund,M.Recent Work on Vagueness[J].Analysis,2011,71(2).
