基于多分类器融合的垃圾短信处理系统
2015-08-18刘文龙时镇军中国移动通信集团江苏有限公司南京210003
刘文龙,时镇军(中国移动通信集团江苏有限公司,南京 210003)
基于多分类器融合的垃圾短信处理系统
刘文龙,时镇军
(中国移动通信集团江苏有限公司,南京 210003)
本文提出了利用朴素贝叶斯、社交网络SNS和广告主挖掘多个分类器融合的垃圾短信处理方式,系统基于Hadoop处理平台,从用户发送内容和发送行为两个维度着手堆垃圾短信识别,可以大幅度提升目前垃圾短信治理的召回率和准确率。
朴素贝叶斯;社交网络;分类器融合;垃圾短信处理
目前对于垃圾短信的治理手段,多采用流量和的处理方式。在实际使用时,为了防止误拦截流量策略一般设置较为宽松,只有用户发送行为明显出现异常时才会被检出,对于
策略,一般是从已知的垃圾短信中提取出
,再结合适当的门限值来进行配置,该种策略对于已知的垃圾短信有较好的检出率,但是对于新型短信,或者内容变化较大的短信则较难检出。并且对于采用纯流量和
+流量的治理方式,需要耗费大量的人力来对策略进行维护,当策略数量达到一定数量级后,手动维护已经较为吃力。对于单纯使用文本分类算法来处理垃圾短信的方式,虽然内容判断较为准确,但是由于脱离了用户的发送行为,较容易造成误拦截。
本文提出基于可横向扩展的Hadoop分布式计算、非结构化数据存储和处理能力系统结构,从底层保证系统的大数据处理性能和系统易扩展性能,充分利用经人工审核已确认的垃圾短信作为深入挖掘和智能分析的样本,融合基于短信内容的贝叶斯分类算法和基于用户发送行为的社交网络算法提高系统的查准率,并且利用广告主挖掘算法来大幅提高垃圾短信的查全率,从垃圾短信的根源和本质进行治理,从而可大幅提升垃圾短信的治理效果。
1 系统架构
如图1所示,系统总体软件架构逻辑上共分为4层:数据获取及预处理层、数据存储计算框架层、数据分析层和数据应用层,其中中间3层数据获取及预处理层、数据存储计算框架层、数据分析层以及操作维护为本系统的核心组成部分。
数据获取及预处理层:提供针对不同数据源的数据获取接口,如FTP、数据库接口等用来从数据源获取源数据;预处理部分针对实际处理需要以及数据源的格式等完成统计粒度内数据合并处理、获得数据的结构化处理、源数据格式的处理和转换、源数据抽取、过滤等功能。经过该层的处理后,所获取的源数据保存在由数据存储计算框架层提供的分布式存储中,可供上层数据分析层直接处理。
收稿日期:2015-11-16
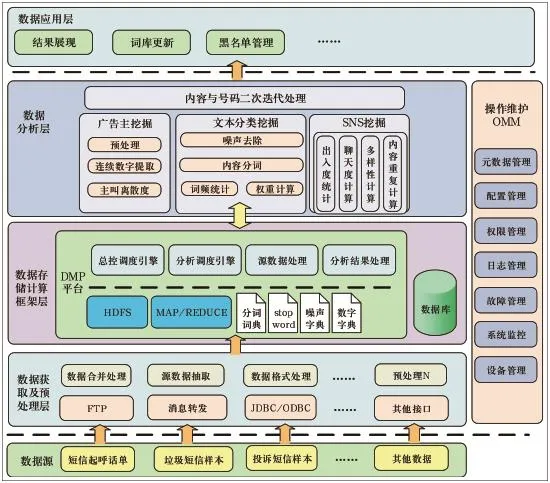
图1 系统架构图
数据存储计算框架层:主要包括由DMP平台封装提供的Hadoop的Map/Reduce分布式并行计算框架和HDFS分布式文件系统,以及用于存储结构化数据和基础结果数据的商用关系型数据库。采用DMP平台集成的Hadoop框架,主要是考虑其分布式文件系统超大的存储空间能够满足短信挖掘高带宽大数据量的存储需求以及Map/Reduce分布式并行计算框架能够满足对数据分析处理性能的要求。
数据分析层:数据分析主要包含广告主挖掘、朴素贝叶斯分类、社交SNS等分类器的分析处理。
操作维护OMM:操作维护包括对整套系统的各种操作维护的需求功能,包括常用的设备管理、故障管理、系统监控、日志管理和权限管理,还包括配置管理和元数据管理。配置管理包括对MAP/Reduce计算系统的配置、统计分析和挖掘分析处理的各种配置。
2 分类算法设计
2.1朴素贝叶斯算法
贝叶斯分类算法是统计学的一种分类算法,它是一种利用概率统计知识进行分类的算法。其中朴素贝叶斯算法作为贝叶斯分类算法的一种,具有算法逻辑简单,易于实现的特点,并且分类过程中对于时间和存储的开销小,算法稳定性和健壮性好,目前被广泛用于文本分类,人工智能等领域。
2.1.1贝叶斯基本公式
由贝叶斯基本公式

可以导出:
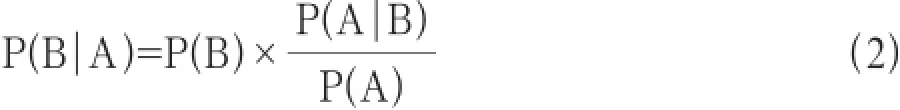
2.1.2统计学转换到垃圾监控领域
P(A)是A的先验概率或边缘概率,它不考虑任何B方面的因素。
P(A|B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
P(B)是B的先验概率或边缘概率,也叫做标准化常量(Normalized Constant)。
转化做垃圾短信监控领域中后:A是一个词,B是一条短信。
P(B|A)就是当A词出现时,短信B是垃圾短信的概率,是后验概率,也就是贝叶斯分类的系数。
P(B)、P(A)和P(A|B)是先验概率,通过对分类器进行训练得出。
P(B)是短信B在所有样本短信中出现概率 = 短信B的条数/所有样本短信条数,由历史全量样本中统计得出。
P(A)是词A在样本的所有特征分词中出现概率 =词A出现次数/所有特征分词出现次数。
P(A|B)是含有词A的短信B是垃圾短信的概率 =出现词A的短信B是垃圾短信的条数/短信B总条数(垃圾短信总条数)。
2.1.3算法说明
衍生的朴素贝叶斯公式:
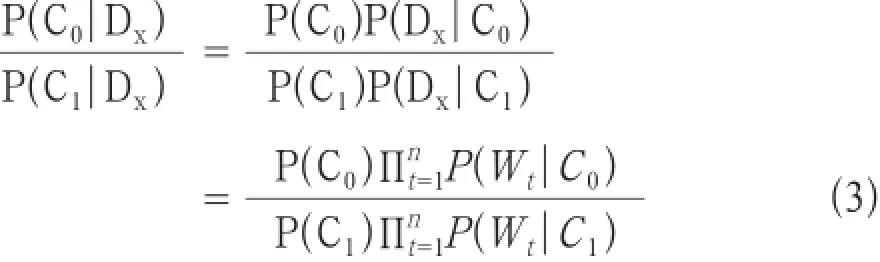
假设垃圾短信样本与正常短信样本的比例为5:95,即P(C0)等于0.05,P(C1)等于0.95。
对短信做加权和降维后产生Dx,进行朴素贝叶斯文本分类:
【无】【本】【税】
【锡】【地】【票】 王经理:138929929290
Dx={税,票,本, 王经理,地, 锡}
通过统计各个分词Wi在垃圾短信样本集里面出现的次数与所有分词数的比值,可以获取P(Wi|C0),类似的可以计算出Wi在正常短信的分布比例,获取P(Wi|C1),上述分词对应的条件概率如图2所示。
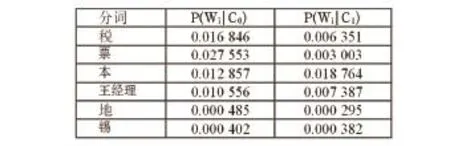
图2 条件概率
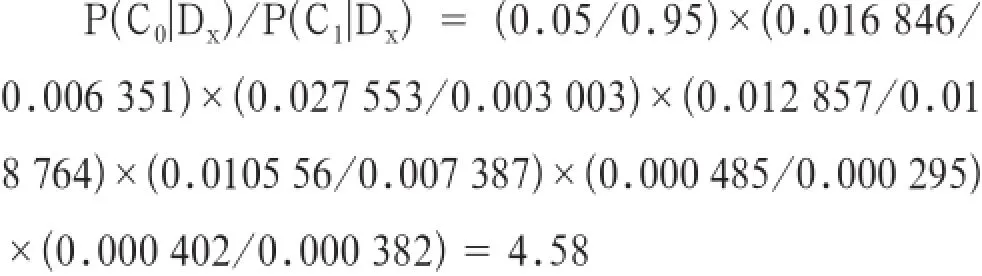
这条消息属于垃圾短信的概率是属于正常短信的概率的4.58倍,贝叶斯分类算法得出该条短信归类为垃圾短信的系数为0.820 8。
2.2社交网络(SNS)
2.2.1算法原理

图3 垃圾短信发送者社交关系图
垃圾短信发送者的社交网络如图3所示,具有出入度大、收发比例不均衡、收发时间、条数、内容分布均匀、接收者之间基本无联系等特点,社会关系网络结果呈扇形对称分布。
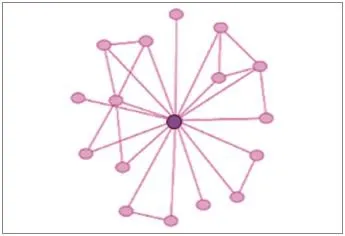
图4 正常短信发送者社交关系图
正常短信发送者的社交网络关系如图4所示,具有出入边数相对稀少、收发比例均衡、收发时间、条数、内容随机分布、接收者之间交往联系特征明显等特点,关系网络呈网络拓扑状。
2.2.2算法说明
2.2.2.1基于图论的用户判定方法
将现网用户的行为做有向图,图5中每个节点都是一个用户,而每条带箭头的线表示用户之间发了一条短信。

图5 正常主叫社交关系图
正常用户的行为:图6出去的箭头(出度)和进入的箭头(入度)处在相同的数量级别。
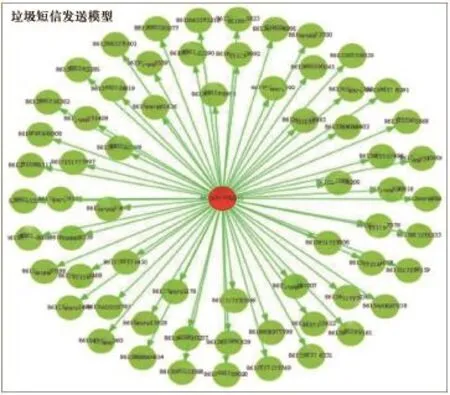
图6 疑似主叫社交关系图
垃圾短信用户行为:图6用户的出度明显大于入度,甚至几乎没有入度。
2.2.2.2短信长度辅助判断
对样本短信进行聚类分析,垃圾短信和正常短信的内容长度呈现完全不同的分布情况。
正常消息的长度集中在1~17和大于55区间内。意味着正常消息大部分是极短的,或者是比较长的。
垃圾消息的长度集中在10~65之间。意味着垃圾消息不会太短,一般也不会使用长消息。
2.2.2.3疑似垃圾短信系数计算
通过计算单个计算周期内,用户出度、入度、发送条数、接收条数、发送时间间隔方差和发送内容长度、长度方差等因素,计算该用户的疑似度。如果用户的出度和发送条数小于限定值(人工设定),则疑似系数为0。
2.3广告主挖掘
2.3.1算法原理
垃圾短信的内容变化多种多样,但是从广告和诈骗类垃圾短信产生的根源分析,短信内容中通常需要包含联系电话、银行账号或者网址等信息;而由于成本及更换困难等多种原因,这些广告主信息通常相对比较固定,是大量垃圾短信中具有的明显特征,而且是比较固定的特征信息。
2.3.2算法说明
定义广义字符库:垃圾短信发送用户为了避免被拦截,往往在其中穿插了各种各样的数字和字母:阿拉伯数字、中文简体数字、繁体数字、谐音数字、带符号的数字和各种象形字母,我们把这些表现形式多样的字符称为广义字符。
广义字符库可配置,包括阿拉伯数字、中文简体数字(如一、二、三)、繁体数字(如壹、贰、叁)、谐音数字、带符号的数字(①、□)、以全角或上下标表示的数字(如1、1、4)和各种相似字母等。在收到短信后根据广义字符库先将短信内容中的广义字符做变换后再进行分析。
定义广告主库:广告主库根据已被判定的垃圾短信内容生成,包含银行卡号、网址、联系电话、邮箱地址等信息,实时进行更新,并且对于一定期限内没有触发过的广告主则进行老化处理。
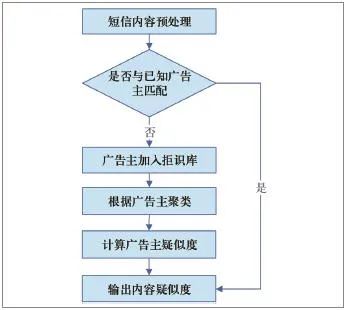
图7 广告主分类处理流程图
广告主分类处理流程图如图7所示。
(1)对待分析短信内容进行预处理,根据预先配置的广义字符库进行变换,得到原始广告主内容。
(2)与已知广告主库进行比对,如果为已知广告主,则直接输出内容疑似度,如果非已知广告主,则加入到拒识库。
(3)以广告主作为特征向量,对拒识库内的所有短信进行聚类。
(4)根据发送该广告主的主叫号码数量,主叫号码的疑似度(由社交网络算法得出),发送总量等信息计算该广告主疑似度。
(5)根据该广告主疑似度进行计算,输出广告主分类器的疑似系数。
3 分类器融合
目前在分类领域中,多分类器融合技术发展迅猛,分类融合技术主要可划分为两类,第一类着重改善分类器的结构,在分类过程中找一个或者一组最优分类器,融合过程不对单个分类器的结果做任何修改,另一类则不对单个分类器做任何更改,主要对各分类器输出结果进行操作,即对单个分类器分类结果进行计算,来确定最终分类结果。对分类器输出进行融合的方法有很多,最常见的方法有多数投票法、加权平均法、Borda计数法、D-S证据组合、贝叶斯方法、神经网络、模糊积分、决策模板等。
结合垃圾短信分类的实际情况,以及本文涉及的单个分类算法,最终采用优化的加权多数投票法,当社交关系分类器计算主叫号码疑似度为0时,进行一票否决。
为了提高整体召回率,当根据各个分类器计算出疑似垃圾短信后,再根据短信内容中的广告主对主叫号码进行召回,提取出包含所有该广告主的短信,去除社交关系分类器否决的部分,然后进行补充输出。
4 实验过程
为了更好的测试各个分类器作用效果,与分类器融合后效果,经过设计后进行实验。
4.1单分类器实验
4.1.1贝叶斯分类器训练
用样本训练出贝叶斯分类器,供贝叶斯算法使用。输入:正常短信样本60万条。垃圾短信样本20万条。输出:分类器文件,供离线贝叶斯分类和实时贝叶斯分类使用。
过程:对样本库进行处理,利用正常样本60万,垃圾样本20万,然后分别对正常样本和垃圾样本进行分词、词频统计,最终为每一个词计算出一个可疑权重,形成贝叶斯分类器。
4.1.2贝叶斯分类器
输入:分类器文件。测试短信样本。
输出:贝叶斯可疑内容详单。
过程:对原始话单的每条消息进行分词,然后计算每个词的权重,由包含词的权重可得到短信的可疑权重值,过滤出其中权重值大于0.5的短信内容,最终输出可疑短信详单。
4.1.3社交网络分类器
输入:测试短信样本。
输出:社交网络分类可疑内容详单。
过程:通过对每个主叫、被叫进行出度、入度,发送消息数量,接受消息数量等进行计算,对每个号码发送的消息中文长度区间进行统计,然后为每个号码计算出一个可疑权重值,抽取出其中权重大于0.5的号码,再根据这些号码输出可疑短信详单。
4.1.4广告主分类器
输入:广义字符字典,广告主字典。测试短信样本。输出:广告主分类可疑内容详单。
过程:根据广义字符字典文件,将话单中的广义字符替换成原本字符,然后将具有广告主特征的连续字符作为广告主,计算这些广告主的出现次数、参与主叫数量等,过滤出其中参与主叫数量大于等于2,出现次数大于等于10次的广告主,最后根据这些广告主输出可疑短信详单。
4.2分类器融合综合评估
输入:测试短信样本。
输出:融合疑似详单文件。
过程:通过对各个分类器系数以及融合权值进行调整,进行综合分类,输出最终疑似话单。
4.3实验结果
离线分类数据的统计结果如表1所示。
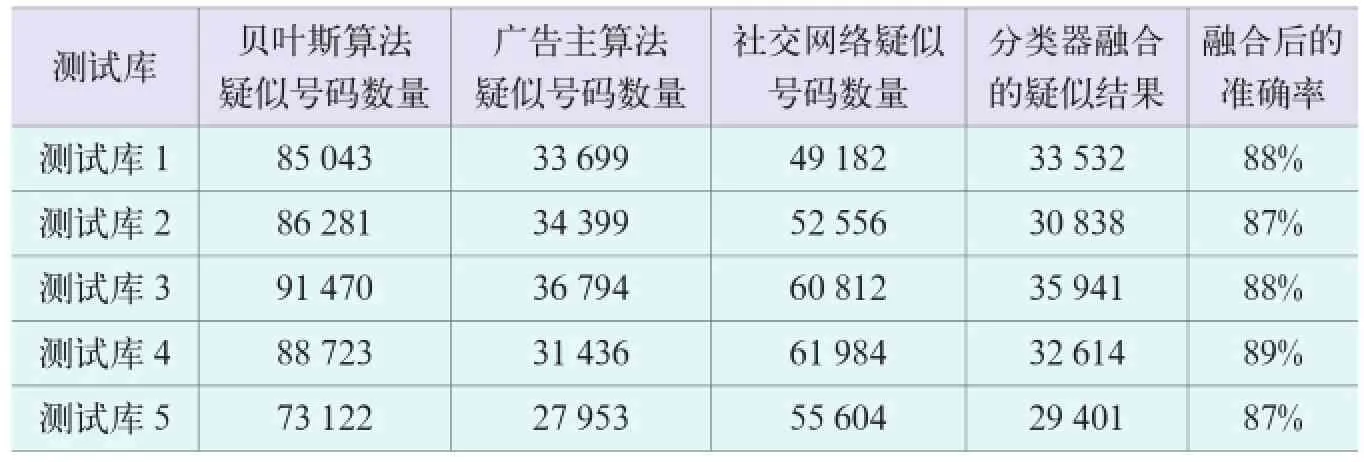
表1 离线分类数据的统计结果
5 结束语
在文本分类领域,通过增加单个分类器结构的复杂度来提高分类精度通常已经不能满足要求,而将多个结构简单的分类器依据不同策略进行融合,来提高整体分类的精度,不失为一种明知的选择。
在垃圾短信处理方法上部分专家也提出使用文本分类的算法来处理垃圾短信,但是在实际使用中,单纯依靠短信内容来判断用户是否发送垃圾短信并不能满足要求, 需结合用户的发送行为进行综合判断。本文提出的基于短信内容+用户行为+广告主判断融合的方法,在实际使用中可以对不同类别的分类器进行替换或者增减,可以大幅提高垃圾短信治理中的召回率和准确率,是一种较为先进的垃圾短信治理系统。
Anti-spam SMS system based on multi classifier fusion
LIU Wen-long, SHI Zhen-jun
(China Mobile Group Jiangsu Co., Ltd., Nanjing 210003, China)
In this paper, we propose use naive bayesian, social networks and extract advertisers to tap the multi classifi er fusion Anti-spam system, the system based on Hadoop platform, according to SMS content and user's behavior to identify spam messages, then the classifi cation accuracy will be improved greatly.
naive bayesian; social networks; multi-classifi er fusion; anti-spam messages
TN918
A
1008-5599(2015)12-0031-06
