基于云填充和蚁群聚类的协同过滤图书推荐算法
2015-08-17毛志勇赵盼盼
毛志勇 赵盼盼
(辽宁工程技术大学工商管理学院 ,辽宁 葫芦岛125105)
基于云填充和蚁群聚类的协同过滤图书推荐算法
毛志勇赵盼盼
(辽宁工程技术大学工商管理学院 ,辽宁 葫芦岛125105)
针对传统协同过滤技术在图书推荐中效率不高、数据极端稀疏性及主观性强等问题,提出一种基于云填充和蚁群聚类的协同过滤图书推荐方法,首先根据蚁群聚类算法得到用户群分类,然后在进行协同过滤前预先通过云模型填充用户——项目矩阵 ,以降低数据的稀疏性。实验结果表明 ,该算法在推荐精度上有明显的提高。
协同过滤 ;蚁群聚类 ;云填充;图书推荐
随着网络技术的不断发展,图书馆服务向个性化、智能化方向发展成为必然趋势。虽然现在各级图书馆都建立了信息服务平台 ,但大部分信息服务平台只是提供简单的查询功能,需要用户主动提交查询的内容,然而随着图书流通数据的不断积累,读者在这种平台中很难快速的获得所需要的信息,智能图书推荐系统则是通过分析不同用户的兴趣所在,主动帮助用户从海量的信息中找出感兴趣的信息,为用户提供个性化的信息服务。因此构建有效的智能图书推荐系统是提高图书馆信息服务水平的重要途径 ,为此研究者提出了很多推荐方法:基于内容的推荐,混合推荐和协同过滤等 ,同时结合先进的技术,如聚类,关联规则,贝叶斯网,神经网络和图论模型等来实现这些方法[1]。
目前协同过滤是应用最成功的推荐技术,在许多领域也得到了广泛的应用。但是它也仍然存在很多的问题。由于用户和资源种类的爆发式增长,用户——项目矩阵成了高维矩阵 ,与此同时,用户评分的资源却很少,一般情况下在1%以下[2]。而图书馆中也会遇到同样的问题 ,图书数目会不断增加,并且随着时间的推移,借阅记录也会成阶梯式增长,数据的极端稀疏性大大降低了传统的协同过滤的推荐效率。目前文献[3-5]提出了用k-means对用户进行聚类 ,以实现对用户——项目矩阵的降维,但由于kmeans算法需要事先指定初始聚类中心 ,而初始聚类中心对聚类结果有较大的影响,所以具有一定的主观性,导致协同过滤图书推荐质量的降低。
针对上述问题,本文提出了一种基于云填充和蚁群聚类的协同过滤图书推荐方法 ,尝试利用改进的蚁群聚类算法对用户进行聚类,然后在得到的小的聚类中,利用云模型对用户——项目矩阵进行填充,最后采用基于用户的协同过滤算法来计算用户间的相似性并找到最近邻居集,得到目标用户对未评分项目的预测评分,形成Top-N推荐。目的在于缩小目标用户最近邻的搜索范围,有效减少搜索开销,从而达到推荐效率的提高,同时,通过云模型填充用户——项目矩阵,有效地缓解数据极端稀疏性和主观性强的问题。
1 基于云模型的数据填充算法
1.1云模型简介
云模型是李德毅院士提出的一种定量定性转换模型[6],能够实现定性概念与其数值表示之间的不确定性转换。正态云模型是最重要的一种云模型,它利用云模型的3个数字特征期望,熵和超熵形成特定的发生器,生成与定性概念相对应的定量转换值。
云发生器分为正向云发生器和逆向云发生器。正向云算法是由云的3个数字特征C(Ex,En,He)通过正向云发生器生成相应的云滴(x,y),而大量云滴聚集在一起形成云,实现定性概念向定量的转换。逆向云计算是由 N个云滴(x,y)通过逆向云发生器生成云的3个数字特征C(Ex,En,He),实现定量值到定性概念的转换。
两朵云之间的相似度可以用两朵云的数字特征向量的夹角余弦来表示,计算如下:

1.2基于云模型的云填充算法
对于任何一个图书馆,读者对图书的评分记录是很少的,从而评估矩阵相当稀疏,导致推荐效果大大降低。为解决该问题,本文采用云填充的方法解决稀疏问题。其基本思想是:首先根据云相似性定义来计算项目之间的相似性,利用用户对相似项目的评分来预测未评分项目的评分[7],填充用户项目矩阵。具体的过程是 ,先找出未评分的项目,采用云模型计算项目之间的相似性,找出该项目的最近邻,最后得出未评分项目的评分。
算法1:基于云模型的云填充算法
输入:用户——项目矩阵Rm×n
输出:填充较完整的用户——项目矩阵
Step1:根据用户——项目矩阵 Rm×n,统计出项目的评分频度向量 Ii,然后通过逆向云计算,得出每一个项目的评分特征向量Vi(Exi,Eni,Hei)(1≤i≤n);
Step2:根据云的相似性度量公式 (1)来计算未评分项目 j和其他项目间的相似性,得到项目相似度矩阵;
Step3:找出未评分项目 j的最近邻居集Mj,邻居集 Mj中的项目与项目i的相似性依次降低;
Step4:利用文献[8]的方法来预测用户对项目 j的评分
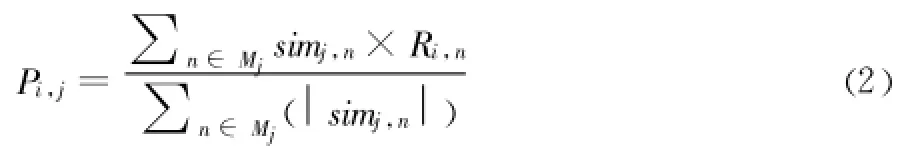
其中 simj,n是项目j和项目n的相似度;Ri,n是用户i对项目n的评分,n是任意的项目p的相似项目。
例如,系统中有4名读者Anne、Tim、John、Joe,5本图书A、B、C、D。假设评分标准为5个级别 ,对应的分值分别为{1,2,3,4,5}。表1中Tim对图书A的评分就是要预测的评分。

表1 R读者评分矩阵
根据算法1,首先统计出每本图书分值出现的频度,记作图书的评分频度向量I=(IA,IB,IC,ID,IE),IA~IE分别表示每本图书相对于5个等级的评价次数,表中给出的5本图书的评分频度向量分别为IA=(1,2,0,0,0),IB=(0,0,0,2,2),IC=(0,0,1,2,1),ID=(2,2,0,0,0),IE=(0,1,1,1,1),利用逆向云计算,分别算出5本图书的评分特征向量VA=(1.25,0.54819,0.37163),VB=(4.5,0.62650,0.45000),VC=(4.0,0.62650,0.73201),VD=(1.5,0.626450,0.45002),VE=(3.5,1.25300,1.06925),很显然,图书A和图书D的评分偏低 ,图书B,C,E的评分偏高。
利用云相似性公式 (1),计算出两两之间的相似度,结果如表2所示:
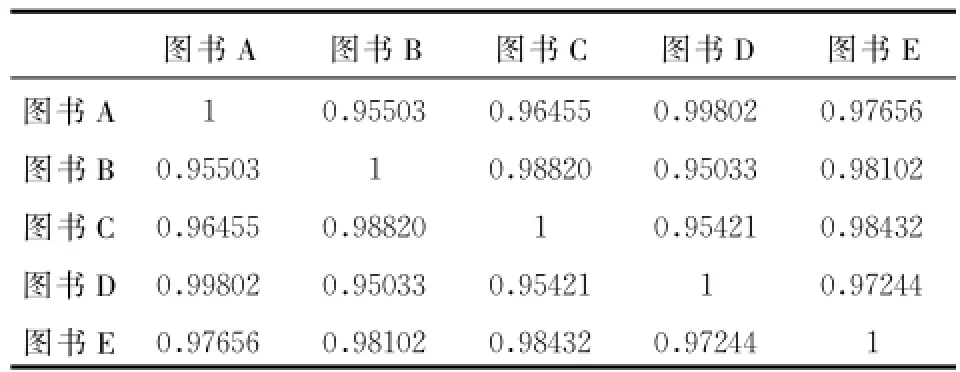
表2 R项目相似度矩阵
由表2可知,图书A和图书D的相似性最高 ,与我们的直观判断一致。利用预测评分公式 (2)计算Tim对图书A的评分为3。以此来填充读者评分矩阵。
2 改进的蚁群聚类算法
2.1蚁群聚类基本原理
基于蚁堆聚类的基本原理是:在工蚁堆积蚂蚁尸体的过程中,小蚁堆通过不断吸引工蚁来堆积更多的蚂蚁尸体,从而形成一个正反馈机制。根据蚂蚁搬运尸体的行为,Deneubourg等[8]提出了BM模型,Lumer等[9]进而提出了LF算法,从而将BM模型运用于数据的聚类分析。但LF算法中的参数的设置没有理论基础,大都是靠经验来主观设定,所以也存在很大的缺陷。徐晓华[10]等给出了一种新型的蚂蚁运动模型,成为AM模型。该模型将每一个聚类的数据看作是一只蚂蚁 ,同样采取了相似度和概率转换来实现聚类,在一定程度上解决了BM模型中的时间成本高的问题。
2.2改进的蚁群聚类算法
本文对基本蚁群聚类的改进主要有以下几个方面:
2.2.1投点问题
在BM和AM模型中,数据采取的是随机投点大方式投射到二维表格中 ,这会导致在聚类初期蚂蚁很容易被捡起或放下,蚂蚁与局部环境中的其他蚂蚁的相似度比较低,从而形成初期分类的时间比较长。本文先对数据进行主成分分析 (PCA),将PCA处理过的前两个主成分投影坐标,由于前两个主成分已经保留了数据的大部分信息,所以相似性比较大的数据在投影之后就会挨得比较近,这样在聚类初期,数据和局部环境中的其他数据的相似性比较高,从而提高算法的运行效率[11]。
2.2.2群体相似度的计算
群体相似度是蚂蚁与其所在局部环境中其他蚂蚁的综合相似度。LF(Lumer Faieta[9])算法中给出了基本的群体相似性度量公式:

其中:L(Oi,r)为蚂蚁 Oi的局部环境,即以 r为半径的圆形区域;d(Oi,Oj)为模式 Oi,Oj之间的距离,通常为欧式距离;n为模式Oi的局部环境内其他模式的个数;α为群体相似系数,它对聚类中心的个数以及算法的收敛速度有重要影响,但是它的调整主要依靠个人经验,缺乏理论指导而难以掌握。所以考虑到 α的影响 ,本文在相似性公式中去掉α,因为相似度本质上是由蚂蚁间的距离所决定的。因此直接用 d来定义相似度,同时由于每一个属性在聚类中的作用是不一样的,所以考虑特征对分类的贡献率[12],利用主成分分析得到属性的贡献率作为属性的权重,使属性在聚类过程中发挥更大的作用,从而有效的改善聚类的质量。其公式如下:
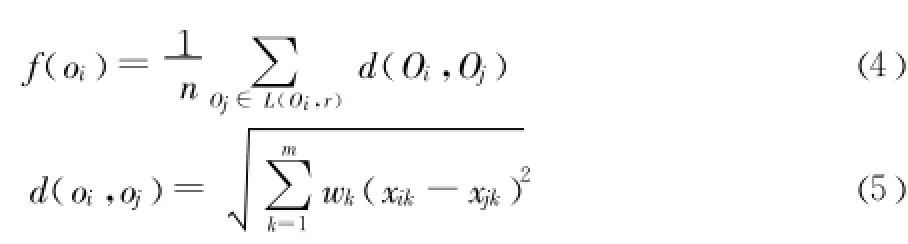
其中w=(w1,w2,…,wm)是与属性相对应的一个权重矢量。wi为该分量的贡献率,刻画了第 i维属性在聚类过程中的重要程度。
2.2.3局部最近邻移动原则
本文中蚂蚁的移动原则是遵循局部最近原则[13],其直接含义是蚂蚁向距离最近的伙伴移动,先在局部找到自己的最近邻,进而找到全局的最近邻伙伴,这符合物以类聚的原理。在这种思想的指导下,给出了蚂蚁移动的下一个坐标的定义:
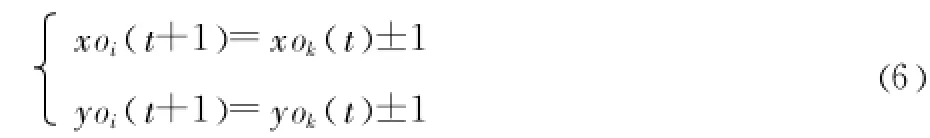
其中 t为循环次数,每次蚂蚁的坐标都不完全重合,相比传统的随机移动方式 ,这种方法能寻找局部最优,尤其在聚类一段时间之后 ,蚂蚁与局部环境中的其他蚂蚁已经有一定的相似性时,这种移动方式更加合理。
与此对应,该算法中不再采用概率转换函数,而是直接设定相似性阈值 F,通过 F与f(Oi)的比较可以看出蚂蚁的状态。这种方法简单易行,并且避免了概率转换函数中参数对算法的影响。
阈值 F必须随算法的进行适当调整,如果 F过大,会导致蚂蚁老是静止不动;过小,会导致蚂蚁一直在动,找不到合适的地方停下来休息。一般移动蚂蚁的数量占总蚂蚁数量的比例为20%时 ,相似性阈值 F比较合理。因此本文提出一种自适应调整阈值的方法 ,具体策略如下:
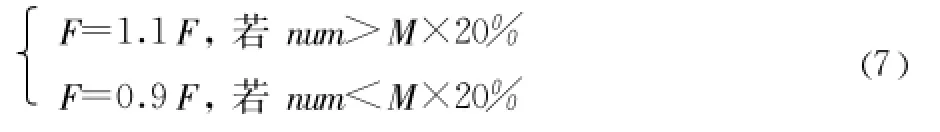
其中:num为此次迭代中处于移动状态蚂蚁的数量,M为总蚂蚁数。
算法2:改进的蚁群聚类算法
Step1:初始化参数,邻域半径 r,相似性阈值 F等,并将所有蚂蚁的状态设置为睡眠状态。
Step2:对待聚类的蚂蚁进行主成分分析,并将处理过的前两维数据投射在二维坐标平面上,并给蚂蚁赋予初始坐标。
Step3:for t=1∶N
for i=1∶M
以蚂蚁 Oi的当前坐标为中心,r为半径,利用式 (4)计算蚂蚁在局部环境中的相似度 f,比较 f与F的大小,若 f<F,则蚂蚁静止不动,否则按照最近邻移动原则 (式(6))更新蚂蚁的坐标值
End(蚂蚁个数循环完毕)
自适应调整阈值F
End(总迭代完成)
Step4:根据聚类结果计算各聚类中心,并输出个聚类的蚂蚁。
3 基于云模型和蚁群聚类的协同过滤
基于云模型和蚁群聚类的协同过滤算法的基本思想是:根据改进的蚁群聚类得到用户的分类,在每一小类中利用逆向云计算的云填充方法来填充用户项目矩阵,寻找用户的最近邻,最终产生推荐集。
具体步骤如下:
Step1:利用算法2对用户进行聚类
Step2:在小类中利用算法1对未评分的项目进行填充
Step3:得到填充较完整的用户——项目矩阵,根据Pearson相关性度量方法计算用户之间的相似性,计算方法如下:
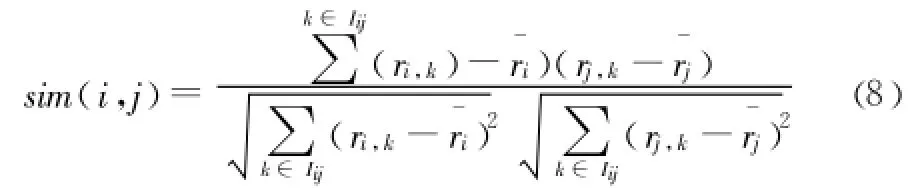
其中,Iij表示经用户i和j共同评分的项目集,ri,k表示用户i对项目k的评分,表示用户i对所有项目兴趣度的平均值。
Step4:将sim(i,j)的值从大到小进行排序,取前 N个邻居组成目标用户的最近邻集合Nu。
Step5:根据最近邻居对项目的评分来计算目标用户对待推荐项目的评分,选择评分比较高的前 N个项目推荐给目标用户,方法如下:
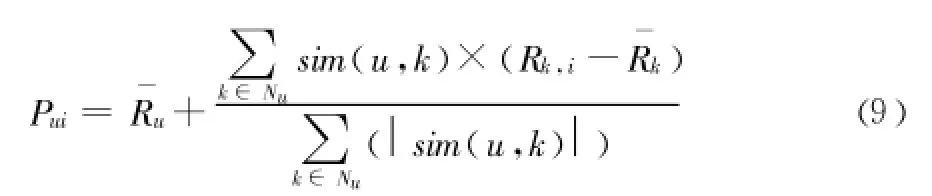
¯Ru和¯Rk表示目标用户u和邻居用户k对项目的平均评分,sim(u,k)表示目标用户 u与邻居用户k对项目评分的相似度,Rk,i表示邻居用户k对项目i的评分。
4 实验结果及其分析
4.1实验数据集
本文从某高校图书馆提取了2012年1月到2013年12月部分用户的图书借阅记录 ,共24 907条借阅数据 ,读者为两个专业共423人,图书选取6个学科2 500册教材和读物。该数据库包括借阅信息表,读者信息表和图书信息表。借阅信息表提供了借阅证号、索书号、评分等属性;读者信息表提供了读者姓名、专业、性别、年级、借阅证号等属性;图书信息表提供了学科、书名、作者、出版社等属性。将实验数据集分为训练集和测试集两部分,其中训练集占整个数据集的80%,测试集占整个数据集的20%。在其基础上做如下处理:
(1)数据清理:对原表中的无效的,冗余的数据进行删除操作,同时由于读者兴趣的变化,删除时间过早的读者借阅记录。
(2)读者借阅号作为读者身份的标示,一般采用字符类型,不便于计算,应该将其转换为数据型。
(3)对数据进行标准化处理,以方便算法的应用。
4.2度量标准
本实验中采取的是评价绝对偏差 (MAE)作为推荐系统质量的度量标准。该方法是通过计算用户实际的评分与通过算法得到的预测的用户评分之间的偏差来衡量衡量的准侧性。MAE越小,预测的就越准确,推荐的质量就越高。
假设预测的用户的评分集合为{p1,p2,…,pN},而对应的用户的真实评分集合为{h1,h2,…,hN},则平均绝对偏差可描述为:

4.3实验结果
实验中利用改进的蚁群聚类方法对用户进行聚类,蚁群算法中采用更简单的相似度度量方法和自适应的阈值调整方法 ,简化了参数的选取,减少了实验的不确定性,提高了算法的实用性。阈值的自适应调整曲线如图1所示。
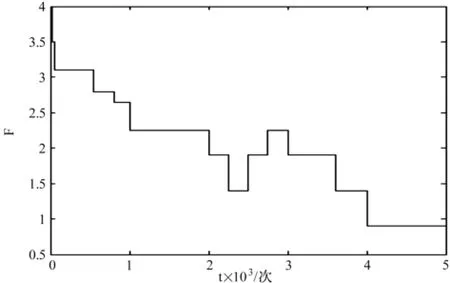
图1 RR阈值的自适应调整
将本文算法与传统的协同过滤推荐算法以及文献 [1]提出的基于用户模糊聚类的协同过滤推荐研究进行比较,在计算MAE值时,邻居数目从10增至55,间隔为5,实验结果如图2所示。

图2 RR各算法MAE值比较
从图2可以看出 ,随着邻居数目的增加,3种算法的MAE值都呈下降趋势,但本文的算法在整体上都具有最小的MAE值,说明本文的算法不仅有效地缓解数据稀疏性的问题,还提高了推荐的效率和质量。
为验证本文提出算法的有效性,使用查准率和误判率[14]来检查实验结果 ,从两个专业中抽取200人,为每位读者推荐20本图书,实验结果如表3所示:

表3 R准率和误判率统计表
从表3可以看出 ,借阅次数为0~30的读者群的推荐效果与借阅次数为90以上的读者群的推荐效果相差较大,并且随着用户借阅次数的增加,推荐效果也越来越准确。
4.4实验结果分析
传统的基于用户的协同过滤算法利用所有用户对项目的评分来计算用户间的相似性,不仅计算量大,并且由于数据的极端稀疏性,同时在推荐过程中将所有用户对项目的评分同等对待,忽略了用户之间的差异性,导致推荐质量的降低。基于用户模糊聚类的协同过滤运用模糊聚类和slope-one对用户项目矩阵进行填充,最终产生推荐,但模糊聚类在数据结果簇是密集的,且簇与簇之间区分明显时效果才比较好,基于用户模糊聚类的协同过滤忽略了孤立点对模糊聚类的影响,同时该算法需要事先指定聚类数目和模糊加权指数,具有一定的主观性。在大数据时代,slope-one在运算过程中会产生巨大的中间数据,对单机来说很难处理,一定程度上降低了运行的效率。而本文摈弃了不必要参数的影响 ,尽量减少主观性,并且利用改进的蚁群聚类实现全局搜索和并行运算,避免聚类陷入局部最优解,同时利用云模型对用户项目矩阵进行填充,综合考虑用户的统计特征,大大提高了近邻用户选取的准确性。实验结果表明,本文提出的算法有效地提高了推荐系统的质量。
5 结束语
本文提出的基于云填充和蚁群聚类的协同过滤图书推荐算法,有效地缓解了数据的稀疏性,避免了主观臆断,提高了推荐的效率。实验结果表明,该算法明显提高了推荐质量和精度。为进一步提高该算法的推荐质量,下一步研究中考虑如何改进蚁群聚类算法中阈值F的自适应调整,提高聚类质量。
[1]李华 ,张宇 ,孙俊华 .基于用户模糊聚类的协同过滤推荐研究[J].计算机科学,2012,39(12):83-86.
[2]Sarwar BM.Sparsity,scalability,and distribution in recommender system [D].Minneapolis,USA:University of M innesota,2001.
[3]Adomavicius G,Tuzhilin A.Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEETranson Knowledgeand Data Engineering,2005,17(6):734-749.
[4]李涛 ,王建东.一种基于用户聚类的协同过滤推荐算法 [J].系统工程与电子技术,2007,29(7):1178-1182.
[5]黄国言,李有超.基于项目属性的用户聚类协同过滤推荐算法[J].计算机工程与设计,2010,31(5):1038-1041.
[6]李德毅 ,刘常昱 .论正态云模型的普适性[J].中国工程科学 ,2004,6(8):28-34.
[7]徐德智,李小慧 .基于云模型的项目评分预测推荐算法[J].计算机工程,2010,36(17):48-50.
[8]Deneubourg J L,Goss S,Frank Net al.The dynamics of collective sorting:robot-like ants and ant-like robots[C]∥Proceedings of the 1st International Conference on Simulation of Adaptive Behavior:From Animals to Animats.Cambridge,MA:MIT Press/Bradford Books,1991:356-363.
[9]Lumer E,Faieta B.Diversity and adaptation in populations of clustering ants[C]∥Proceedings of the 3 rd International Conference on Simulation of Adaptive Behavior:From Animals to Animats.Cambridge,MA:MIT Press/Bradford Books,1994:501-508.
[10]徐晓华,陈崚 .一种自适应的蚂蚁聚类算法 [J].软件学报,2006,17(9):1884-1889.
[11]张蕾 ,曹其新 ,李杰 .一种基于群体智能聚类的设备性能横向比较算法[J].上海交通大学学报 ,2006,40(3):439-443.
[12]林金烁,叶东毅.基于蚁群聚类算法的优化与改进 [J].计算机系统应用 ,2013,22(12):93-99.
[13]张蕾 ,曹其新,李杰 .一种新型的自适应蚁群聚类算法 [J].上海交通大学学报,2009,43(6):1006-2467.
[14]李克潮 ,蓝冬梅 ,凌霄娥 .一种高校读者借阅偏好的个性化图书推荐 [J].现代情报,2013,33(8):1008-0821.
(本文责任编辑:孙国雷)
A Collaborative Filtering Recommendation Algorithm Based on Cloud Model and Ants Clustering
Mao Zhiyong Zhao Panpan
(College of Business Administration,Liaoning Project Technology University,Huludao 125105,China)
A new recommendation algorithm based on cloudmodeland antcolonywasdesigned to reduce the sparsity of user rating data,the efficiency and subjectivity of conventional collaborative filtering recommendation.First,usersare clustered by ants clustering,then the user-item ratingmatrix should be filled through cloud model in advance before collaborative filtering,improving the sparsity of user rating data.The experimental results indicate that the recommendation accuracy of this algorithm is largely improved.
collaborative filtering;ants clustering;cloudmodel;book recommendation
毛志勇 (1976-),男,副教授,研究方向:数据挖掘。
10.3969/j.issn.1008-0821.2015.05.015
TP18;TP301.6
A
1008-0821(2015)05-0078-05
2014-12-20
