融合实用性与科学性的互联网信息分类体系构建*
2015-08-10路永和彭燕虹中山大学资讯管理学院广东广州510006
路永和 彭燕虹(中山大学资讯管理学院 广东广州 510006)
·信息组织与服务·
融合实用性与科学性的互联网信息分类体系构建*
路永和彭燕虹
(中山大学资讯管理学院广东广州510006)
摘要:
分类体系是信息组织的有效形式,传统文献分类体系难以适用分类对象的转变,实用性不足,已有的网络分类体系则缺乏科学性。构建融合实用性与科学性的互联网信息分类体系,能够有效满足用户信息需求,且是自动文本分类技术研究的基础。文章分别以中图法、新浪门户为例,研究传统文献分类法与网络信息分类法的优缺点,提出互联网信息分类体系的实用性、科学性以及均衡性设计原则,基于三个设计原则构建了互联网信息分类体系。为了验证所构建的分类体系的有效性,通过网络爬虫抓取网易门户以及腾讯网的语料作为实验数据,与复旦语料库的分类体系进行对比实验。实验结果表明,相比于复旦语料库的分类体系,文章所提出的互联网信息分类体系具有更高的实用性,且能更为全面地涵盖各种互联网信息,类目之间交叉度小,各个类目信息量接近,文本分类效果更为理想。关键词:
互联网信息;分类体系;中图法;语料库伴随着网络信息的指数增长,海量信息所带来的信息冗余,使得越来越多的信息用户无法有效获取所需信息。特别是在用户无法明确得知关键词以进行信息检索的情况下,如何帮助用户在信息海洋中更加快速有效地获取需求信息,具有一定的研究价值。信息分类是信息组织的有效途径之一,以中图法、杜威分类法为代表的传统文献分类体系能够有效组织大量的文献信息,网络环境下以各个门户网站分类体系为代表的网络分类体系可以组织海量的网络信息,但传统文献分类体系过分强调类目体系严谨科学,体系庞大、术语生僻;网络分类体系注重体系实用性,但存在措词随意,类目之间科学性欠佳等问题。良好的分类体系是实现自动文本分类的基础,如果能对网络中的文档进行处理,使其形成良好的分类,有助于人们组织、挖掘、检索文本信息。同时,伴随着文本分类技术的发展,越来越多的学者迫切需要文本分类语料库以支撑其实验研究,而最便捷最庞大的语料获取来源即为互联网,但这些互联网信息需要一个有效的分类体系将其囊括。分类体系作为构建文本分类语料库的前提,分类体系的好坏,直接影响了一个文本分类语料库的优劣,继而影响自动文本分类技术的研究。构建融合实用性与科学性的互联网分类体系,除了能够有效满足用户信息需求这一实用性要求,还能够促进自动文本分类技术的进步。
1 分类体系研究
一直以来,学者们都试图寻找一个更适用于互联网环境的分类体系。陈树年、张琪玉等先后提出过互联网环境下的分类体系框架,主要划分了一、二级类目,力求涵盖所有互联网信息,但其分类体系过多直接引入传统文献分类法的类目,如陈树年的体系大纲中所出现的“图书馆与参考资料”、“工程技术”等类目,且较少考虑现实情况下的网络信息资源分布,体系重点不明晰,与用户直接使用的指南性网络分类体系有所不同。反观现有的门户网站分类体系,其基于点击率构建、体系适用范围较窄、类名措词随意性大、歧义度高、类目之间交叉明显、网络信息混乱、用户查找困难重重。不仅导致用户在浏览不同网站的过程中存在明显的阅读障碍,更使得用户无法通过分类体系有效获取所需信息,常常出现如点击某一类目后,出现大量与需求信息完全无关的内容等问题。由传统文献分类体系直接改造而来的分类体系框架以及各个门户网站的自编分类体系,无法有效应对海量网络信息环境下的用户信息需求,建立通用性高、更加符合网络信息资源分布现状、适合网络信息组织与传播的互联网信息分类体系具有一定的现实意义。
传统文献分类法与网络信息分类法的分类对象不同决定了传统文献分类法对于互联网信息的不适用性,但两者都是对于知识、信息的组织,这一共性决定了网络信息分类能够借鉴传统文献分类法。传统文献分类法一般以学科为中心建立分类体系,将有关主题的文献集中到学科之下,如《中国图书馆分类法》(下文简称中图法)。传统文献分类体系更倾向于科学性,依据学科属性进行知识体系组织,强调类目体系覆盖全面、稳定,类目命名准确严谨。但存在结构过于庞大、缺乏简明性,划分太细、缺乏实用性,操作复杂、缺乏易用性,体系僵化、缺乏灵活性,单线排列、缺乏多维性等多种问题。而网络分类法以主题为中心或主题结合学科的方式组织分类体系,如新浪门户、网易采用主题与学科结合方式,建立以事物对象为中心的分类体系。网络信息分类法更倾向于依据用户需求来设置类目体系,特别是某些实用性很强的网站,如淘宝网。网络信息分类体系具有更高的实用性,类目名称通俗易懂,但存在着类目交叉明显,如“新闻”一级类目下的“国内”、“深度报道”,用户无法明确选择哪个渠道点击浏览信息,降低网站访问效率,科学性明显不足。对此不少学者提出了自己的建议,陈树年提出建立网上信息的知识分类系统,必须遵循面向网络信息资源、面向网络技术环境、面向网络用户的原则,突出其实用性和易用性。黄如花提出网络信息组织模式应该以用户为中心,遵循实用性和易用性原则,综合运用自然语言和人工语言(分类语言、主题语言),充分利用新兴技术和人们经验的积累。王丽珺等提出网络信息分类体系应具备动态性、多维性、实用性和易用性原则。郑庆胜等认为在构建网络信息分类体系时应注意分类体系的实用性、全面性、规律性、统一性和特殊性。
2 分类体系设计原则
基于上述对传统文献分类法与网络信息分类法的综合分析,并考虑到网络分类体系分类对象的转移以及当前网络信息本身所呈现的特点:数量多、内容庞杂;变化快、稳定性差;类型多、范围宽、用途广;信息组织特殊、控制性差,本文采用以事物对象为中心的方式构建知识体系,并继承传统分类体系科学性、类目体系全面的优点,进一步改进和完善现有网络信息分类体系设计原则,总结提出以下三个原则:(1)实用性原则,即要求类目设置方便用户使用。各大门户在设立分类体系时一个重要的原则就是方便网络用户的查找,互联网分类体系区别于传统文献分类体系,其目的是有效地组织网络信息,并最大效能地满足网络信息用户的需求。只有满足实用性,才能制定出更加符合用户需求的体系,使用户更快更准地查询到需要的信息;(2)科学性原则,其要求类目体系不仅能够全面涵盖几乎任何主题的网络信息,且各个类目具有明显主题范围,能够明显区分类目的主题内涵与外延,大类与子类之间具有逻辑性。目前大部分的互联网分类体系只是基于其本身网站的点击率设计,类目体系全面性不足,大量互联网信息无法实现有效分类,大大弱化了信息的利用率;同时,大量类目重复设置,影响了用户的准确判断。坚持科学性原则,有利于构建更完善的互联网分类体系,且各个类目特征明显,类目上下级符合逻辑,有助于后续语料收集、语料训练等机器自动学习的实现;(3)均衡性原则,即要求分类体系各个类目访问频率相近。从信息论角度来看,可以把网站信息分类体系类比为一个信息通道。一般来说,通道的利用率要高,这要求每个类别包含的元素要尽量均衡,即内容多分得细,内容少分得粗。若不引入类目体系均衡原则,则可能有的类目只有两三层,有的类目则多达十几层,有时用户从分类途径查找某个类名,往往要链接十多个页面,既费时又费力。坚持类目体系均衡原则,有助于体系更加简洁、更加方便。
3 互联网信息分类体系构建
以分类体系设计原则为基础,构建初步互联网信息分类体系。在初步分类体系基础上,采用网络爬虫从新浪网抓取不同频道的信息并人工识别后将其作为训练语料和测试语料,进行文本分类实验测试。依据测试结果,对初步互联网信息分类体系进行修改调整,最终得到各个一级类目分类准确率均高于90%的互联网信息分类体系。该分类体系共有13个一级类目,各个一级类目之下具有2-8个二级类目(见表1)。
4 互联网分类体系有效性实验
为了检验此分类体系对于互联网信息的有效程度,我们利用目前已有的文本分类体系进行对比实验。目前采用网络信息作为语料测试文本分类效果的分类体系主要有:复旦大学文本分类语料库的分类体系(以下简称复旦分类体系)和搜狗文本分类语料库的分类体系(以下简称搜狗分类体系)。复旦分类体系包含20个类目:Art、Literature、Education、Philosophy、History、Space、Energy、Electronics、Communication、Computer、Mine、Transport、Enviorn-ment、Agriculture、Economy、Law、Medical、Military、Politics、Sports。搜狗分类体系包含9个类目:IT、财经、健康、教育、军事、旅游、体育、文化、招聘。由于搜狗分类体系的类目较少,类别全面性不足,诸如娱乐、游戏等相关主题的语料,无法被涵盖,因此本文采用类目更为全面的复旦分类体系作为实验对比体系。

表1 互联网信息分类体系
4.1实验流程
首先通过网络爬虫抓取语料,并将抓取的语料依据不同分类体系进行人工分类,将人工分类所得语料分为训练集与测试集;最后应用文本分类技术,采用KNN分类器进行分类测试。采用KNN分类过程中,主要利用余弦相似度计算以计算各个文本向量空间,设定阀值为20%,即测试文档与类目之间相似程度超过20%,则输出该类别。依据测试文档与不同类目相似程度的不同,按照相似程度从高到低排序,得到测试文档的第一相似类目、第二相似类目和第三相似类目。考虑到当前一个互联网信息文档中涵盖多种主题的现实情况,故而将第一相似类目、第二相似类目、第三相似类目统称前三相似类目,能够有效反映语料的真实分类情况。因而,在传统的文本分类评价指标——分类准确率的基础上进行扩展,提出了两个分类准确率评价指标,包括第一相似类目分类准确率(即传统的文本分类分类率,见公式1)以及前三相似类目分类准确率(见公式2)。具体实验流程如图1所示。

4.2实验数据
由于本文互联网信息分类体系主要参考中图法和新浪网分类体系构建,为保障对比所用语料公平性,本文实验采用的语料来自网易门户与腾讯网,通过网站首页层层遍历抓取,保证实验语料能真实反映网络语料分布现状,抓取所得语料总数为21614条。
抓取所得的语料,需先进行人工分类,即通过人工识别某一语料归属于哪个类目,以作为可用的语料,剔除不可用的语料,得到实验所需的语料集。其中,可用语料率=该体系可用语料数量/抓取所得语料总数量。人工分类统计后,可得到复旦分类体系与互联网信息分类体系的语料情况(见表2)。
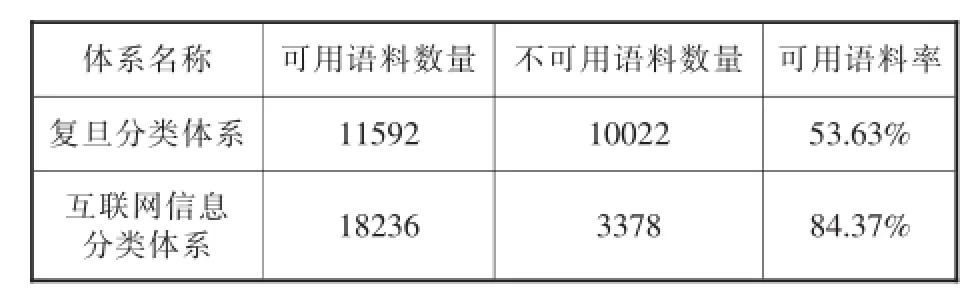
表2 复旦语料库的分类体系与互联网信息分类体系的语料情况
由语料情况可知,复旦分类体系可用语料率仅为53.63%,大量娱乐、游戏、时尚、神秘学等相关互联网信息无法找到相应类目;而互联网信息分类体系可用语料率达84.37%,无法分类的语料主要集中为语料涵盖主题过多,人工无法明确识别类目的语料。因而,相比于复旦分类体系,本文构建的互联网信息分类体系实用性更高,具有包括娱乐、游戏、时尚等多个复旦语料库分类体系所没有的类目,符合实用性原则;同时,也体现出互联网信息分类体系能够更加全面的覆盖多种互联网信息,符合科学性原则所要求的类目体系全面。
本文实验中的训练语料、测试语料依据各个类目语料总数大约1:1划分,根据抓取信息的实际情况,不同类目的训练语料、测试语料数量有所不同。复旦语料库分类体系总训练语料数为5802条,总测试语料数为5790条(具体情况见表3);互联网信息分类体系总训练语料数为9142条,总测试语料数为9094条(具体情况见表4)。
由训练与测试情况可知,复旦分类体系各个类目的语料数量差异较大,语料数量多于1000的类目仅有3个,语料数量低于200的高达11个,相应其训练语料数量将低于100,会极大的影响后续文本分类实验;相比于复旦分类体系,互联网信息分类体系各个类目的语料数量较为均衡,语料数量多于1000的类目有7个,语料数量低于200的仅有2个。由此可知,互联网信息分类体系各个类目包含的语料数量相对比较均衡,诸如“复旦分类体系”中划分的Military(军事)、Politics(政治)类目在互联网信息分类体系中,均为event(时事)的子类,而互联网信息分类体系的训练集、测试集情况也显示Military(军事)、Politics(政治)类目语料数量较少,符合均衡性原则。
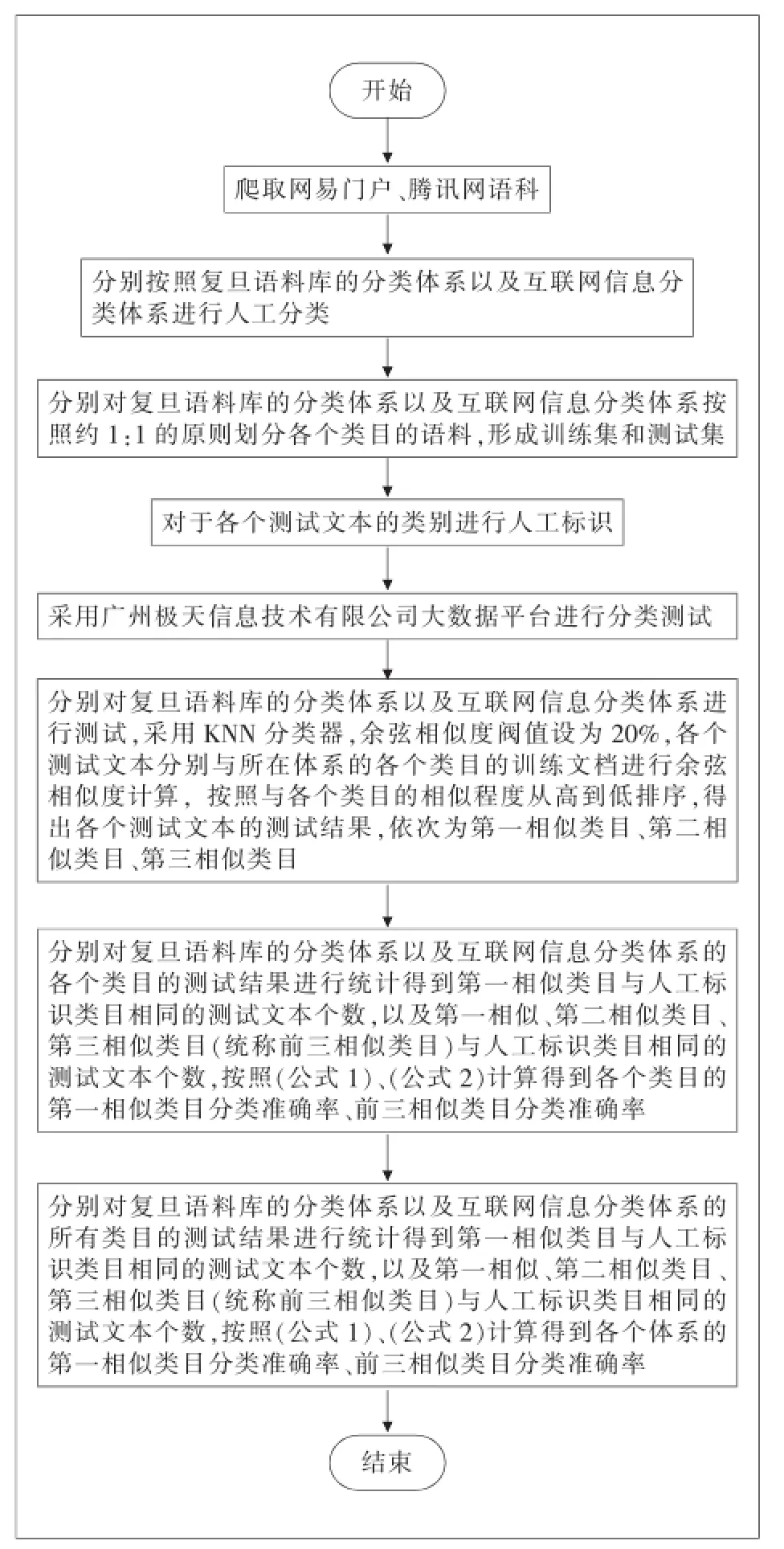
图1 互联网分类体系有效性实验流程
4.3实验结果
通过实验,可分别得到复旦分类体系以及互联网信息分类体系各个类目的测试结果(见表5、表6)。
由两种分类体系的测试结果可知,互联网信息分类体系第一相似类目分类准确率高于90%的类目达5个,低于50%的仅有1个,而复旦语料库分类体系高于90%的仅有1个,低于50%的有10个;互联网信息分类体系前三相似类目分类准确率高于90%的类目有9个,高于80%的有12个,仅有1个低于80%,而复旦语料库分类体系高于90%的仅有4个,高于80%的有11个,低于80%的有9个。由此可知,互联网信息分类体系类目设置具有更高的合理性,类目之间交叉度更低,各个类目特征明显,符合科学性原则所要求的类目之间相互独立。
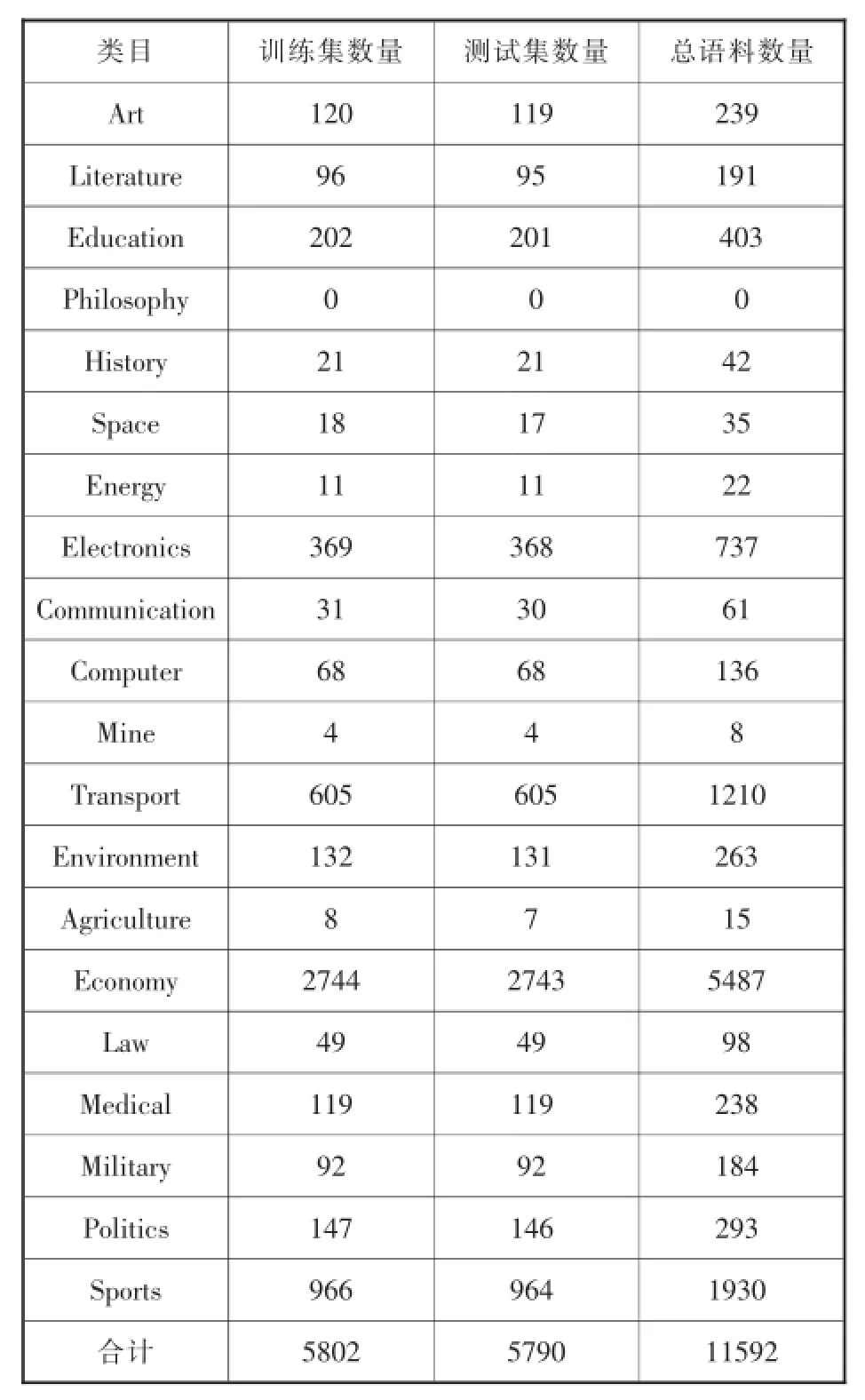
表3 复旦分类体系的训练集、测试集情况
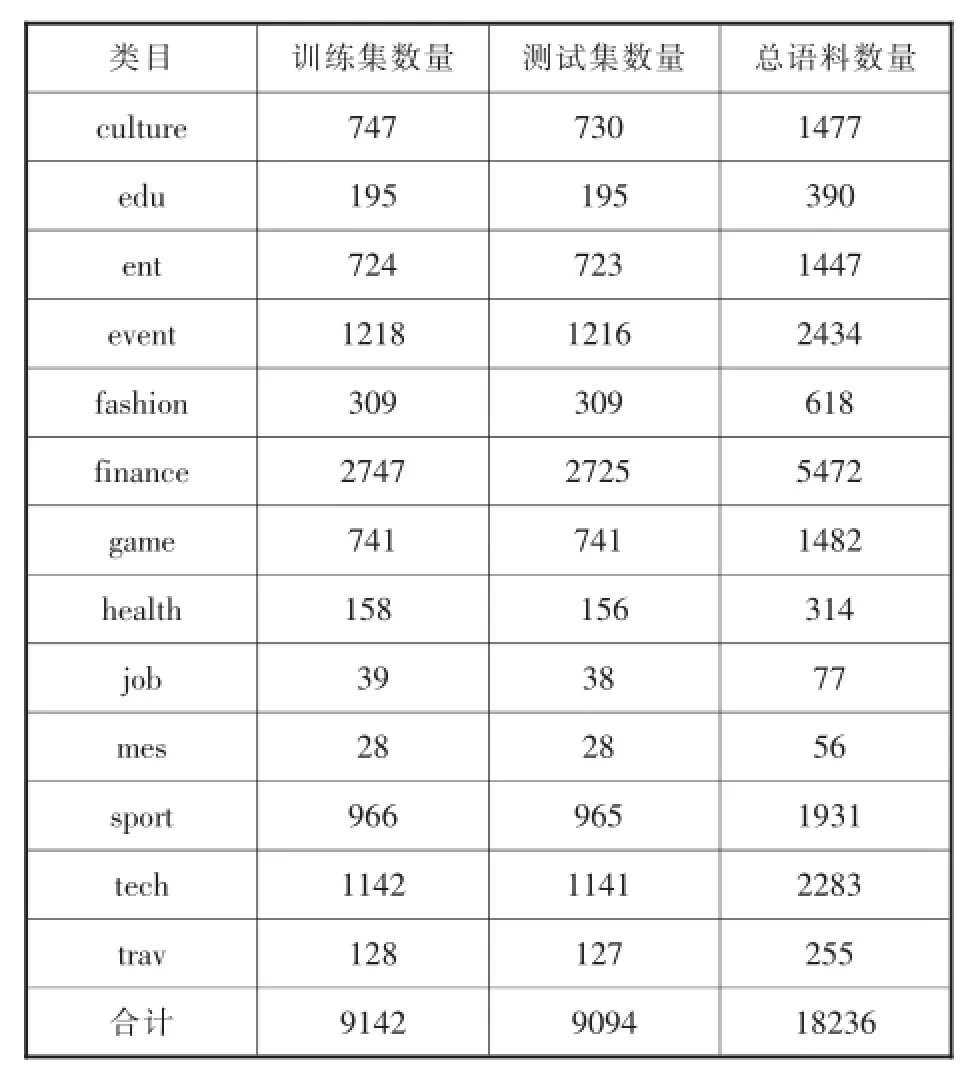
表4 互联网信息分类体系的训练集、测试集情况
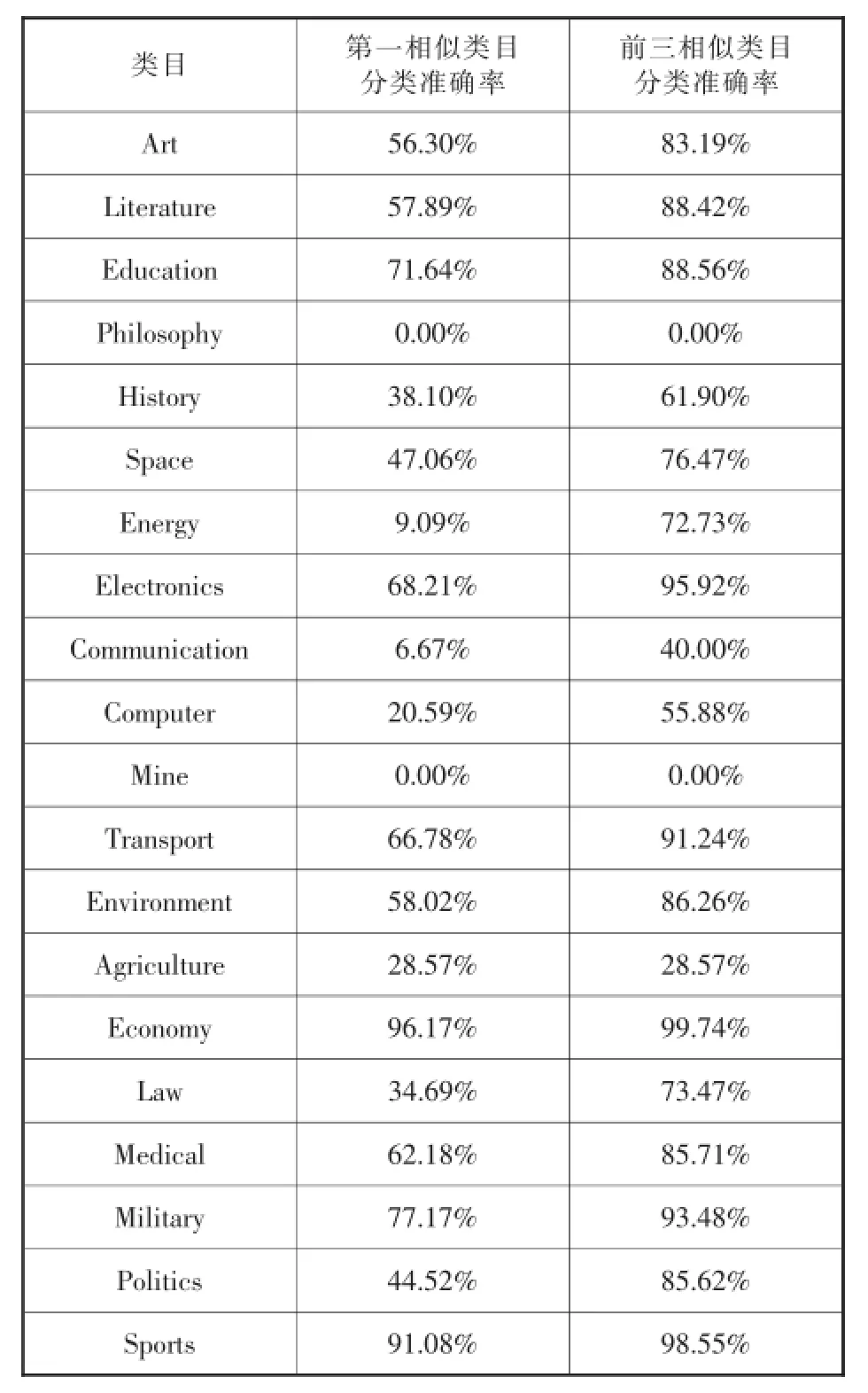
表5 复旦语料库分类体系各个类目的测试结果
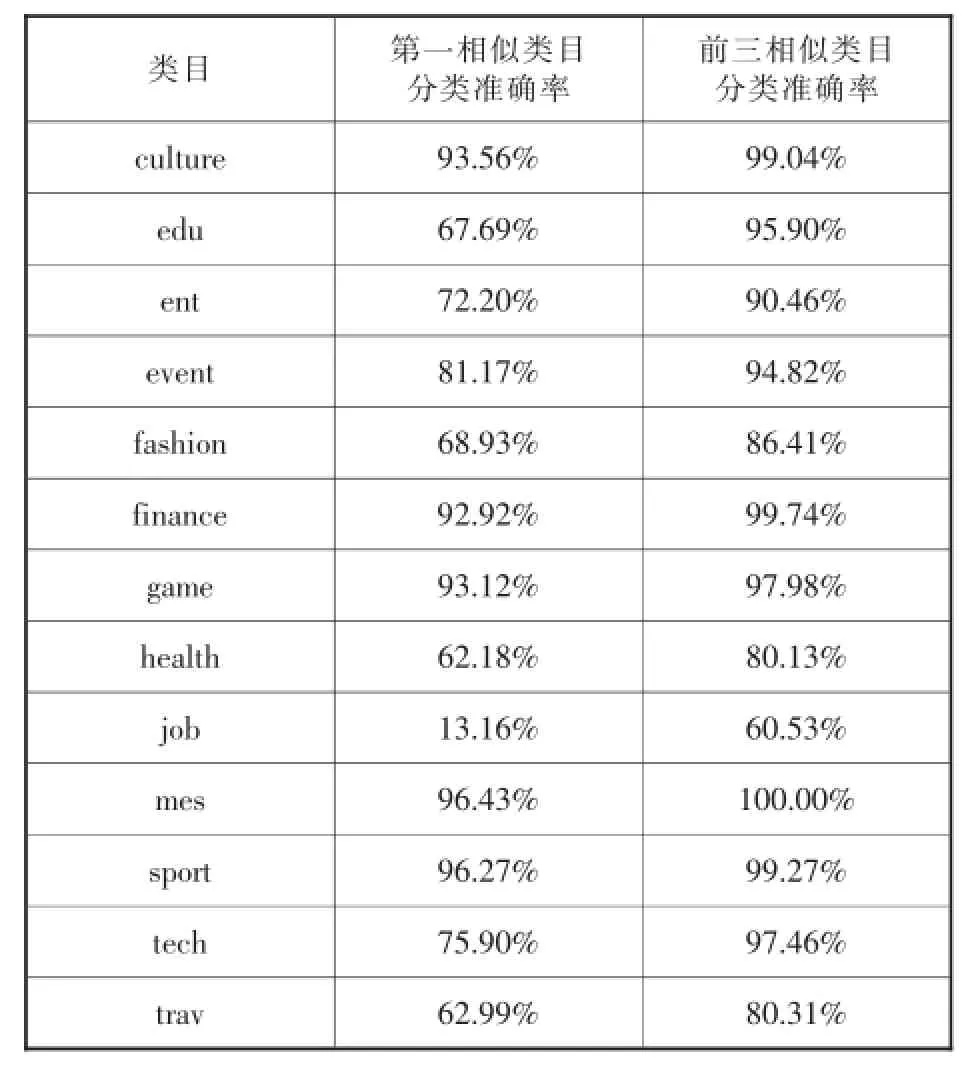
表6 互联网信息分类体系各个类目的测试结果
对于整体数据集,利用文本分类评价指标——宏平均准确率进行评价,即每个类的分类准确率的算术平均值。由于前面各个类别考虑了第一相似类目分类准确率、前三相似类目分类准确率,故而此处考虑第一相似类目宏平均准确率以及前三相似类目宏平均准确率(复旦分类体系与互联网信息分类体系的宏平均准确率见表7)。
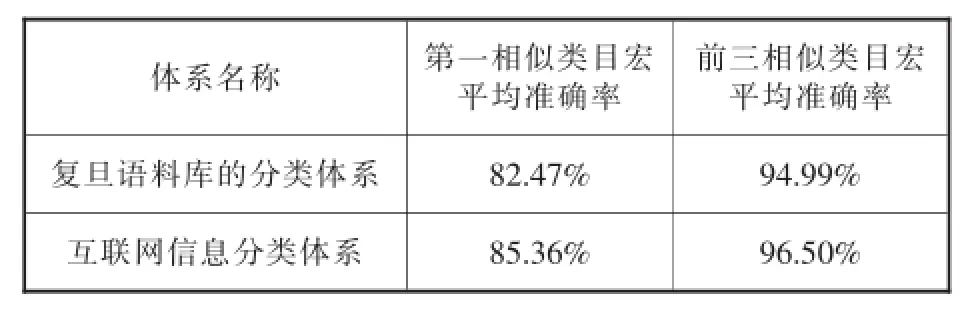
表7 复旦语料库分类体系与互联网信息分类体系的宏平均准确率对比
对比可知,尽管互联网信息分类体系所含语料数目为18236,复旦分类体系所含语料数目仅为11592,互联网信息分类体系语料数大大多于复旦分类体系,即互联网信息分类体系所包含的干扰信息大大多于复旦分类体系,但其第一相似类目宏平均准确率、前三相似类目宏平均准确率均仍高于复旦分类体系,验证了本文所构建的互联网信息分类体系的有效性。
5 结语
针对当前现有的各大网站自建体系科学性不高,用户无法通过分类体系有效获取所需信息,甚至误导用户的现状,本文在对比了传统文献分类法与网络信息分类法的特点基础上,结合网络信息分类法——实用性以及传统文献分类法的优点——科学性,提出了适用于构建互联网信息分类体系的设计原则,并初步构建了具有13个一级类目的互联网信息分类体系。该互联网信息分类体系以事物为中心进行知识组织,在贯彻网络信息分类体系实用性原则的基础上,提高了分类体系的科学性与均衡性。同时,实验结果表明,对比复旦语料库的分类体系,本文所提出的互联网信息分类体系具有一定的有效性,既能有效涵盖更多的互联网信息,且能够保证更高的分类准确率。具体而言,互联网信息分类体系可用语料率达84.37%,远高于复旦语料库分类体系的可用语料率53.63%,涵盖多个较高实用价值的类目,符合实用性原则;同时,较全地覆盖网络信息,能够使更多的网络信息找到相应类别。其前三相似类目分类准确率高于90%的类目有9个,占体系总类目数的69.23%,而复旦语料库分类体系中高于90%的类目占体系总类目数的比率仅为20%,互联网信息分类体系各个类目特征更加明显、相互独立、交叉度低,符合科学性原则。同时,各个类目涵盖的语料数量相近,语料数量低于200的仅有2个,而复旦语料库分类体系的语料数量低于200的高达11个,“Economy”类目语料数量设置多于这11个类目的语料总和,表明互联网信息分类体系各个类目所包含的网络信息量接近,符合均衡性原则。同时,互联网信息分类体系具有更高的分类准确率,前三相似类目分类准确率达96.50%,具有较好的自动文本分类效果,其能够有效解决当下网站自建体系类目交叉明显,类目科学性不强的问题,帮助用户更加便利快捷地查找到需求信息。
尽管本文提出了一个具有较好的文本分类效果的体系框架,但仍存在一些不足:本文所提出的互联网信息分类体系,其主要停留在一级类目体系的构建上,但实际应用过程中,用户需要层层遍历体系以指导其进行信息获取。因而,下一步将会更加深入地研究各个类目的子类目,以期寻求科学的方法将各个大类层层细分。同时,结合自动文本分类技术,在此分类体系的基础上,实现测试语料自动分类,力求构建一个具有自学习能力的文本分类平台,实现子类目自划分、语料数量自增长。
参考文献:
[1]王兴兰,宋文.基于知识组织体系的自动分类研究[J].图书馆论坛,2013,33(6):8-13.
[2]陈树年.搜索引擎及网络信息资源的分类组织[J].图书情报工作,2000(4):31-37.
[3]张琪玉.网络信息检索工具的分类体系——网络信息检索工具发展的方向与提高竞争力的途径(连载三)[J].江苏图书馆学报,2002(4):7-11.
[4]蔡厚勇.论图书馆数字化过程中的信息分类体系重建[J].大学图书情报学刊,2001(3):1-3.
[5]欧洁,俞学宁,朱礼军,等.基于网易的网络信息分类体系研究[J].图书馆学研究,2012(1):50-53.
[6]王忠红.网络信息环境下的传统分类法[J].图书情报工作,1999(2):37-39.
[7]钟莹.传统文献分类法与网络信息分类法之比较[J].学理论,2010(2):118-120.
[8]中国图书馆分类法[EB/OL].[2014-07-28].http://clc.nlc.gov.cn/ztfdsb.jsp.
[9]白国应.论文献分类法的系统特征[J].图书情报工作,1998(11):7-10.
[10]崔慕岳,刘延章,张中秋.《中图法》组织网络信息的可行性、不适应性及其现代化改造[J].郑州大学学报(哲学社会科学报),2001(6):137-140.
[11]新浪门户导航页[EB/OL].[2014-08-25].http://news.sina.com.cn/guide/.
[12]刘星.试论网络信息分类中存在的问题及对策[J].图书馆工作与研究,2008(2):43-45.
[13]鲁晓明,王博文,詹刘寒.淘宝网商品信息组织分析[J].图书情报工作,2013,57(增刊2):244-248.
[14]黄如花.网络信息组织的发展趋势[J].中国图书馆学报,2003,29(4):15-19.
[15]王丽珺,汤亮亮.网络信息分类体系构建策略研究[J].中国科技信息,2009(23):115-116.
[16]郑庆胜,易晓阳.从新浪等网站看网络信息分类体系的建立——兼论综合性中文网站分类体系之建立[J].图书馆建设,2003(1):69-71.
[17] 史学斌.网络信息分类体系[J].图书馆,2002(2):33-35.
[18]常璐.对网络环境下信息分类法的思考[J].科技情报开发与经济,2011,21(8):30-33.
[19]宛玲,赵喜英.中文网络信息分类组织分析[J].图书馆理论与实践,2001(1):46-56.
[20] 复旦大学文本分类语料库[EB/OL].[2014-12-25].http://www.nlpir.org/?action-viewnews-itemid-103.
[21]搜狗文本分类语料库[EB/OL].[2014-12-25].http://www.sogou.com/labs/dl/c.html.
·用户服务与研究·
中图分类号:
G2503文献标识码:
ADOI:
10.11968/tsygb.1003-6938.2015072作者简介:
路永和(1962-),男,中山大学资讯管理学院副教授;彭燕虹(1992-),女,中山大学资讯管理学院硕士研究生。*本文系
国家自然科学基金项目“面向文本分类的多学科协同建模理论与实验研究”(项目编号:71373291)研究成果之一。收稿日期:
2015-06-16;责任编辑:魏志鹏The Classification System Construction for Internet Information both Practical and Scientific
Abstract
The classification system is an effective method of information organization.The traditional classification system can not adapt to the transformation of classification object and is no longer practical;at the same time,the existing network classification system is not scientific.An Internet information classification system both practical and scientific can not only effectively meet the users'information demand,but can also promote the development of automatic text classification.Taking Chinese Library Classification and Sina portal for examples respectively,this paper studies the advantages and disadvantages between traditional document classification and taxonomy of network information,come up with the design principles of the internet information classification system,namely practical, scientific and balance.Based on these three design principles,an internet information classification system was built.In order to verify the validity of the classification system,the web crawler is used to grab corpus of www.163.com and www.qq.com which are as experimental data,and Fudan Corpus classification system is used for the comparative experiment.Experimental results show that,compared to the Fudan Corpus classification system,the proposed Internet Information Classification System has a higher practicality,and can more comprehensively cover all kinds of Internet information,little intersections among categories,more approach between the information of each category,the text classification efficiency is quietly improved.Key words
internet information;classification system;chinese library classification;corpus