数据挖掘技术在学生成绩分析中的应用研究
2015-08-07李巧君李伟
李巧君,李伟
数据挖掘技术在学生成绩分析中的应用研究
李巧君,李伟
数据挖掘作为一种数据处理技术,可以通过从大量数据中提取有效信息,从而为人们的决策提供指导。根据当前学生成绩分析中存在的不足,提出利用数据挖掘 Apriori 算法对其进行分析研究,通过对教务管理系统中大量的学生成绩进行分析,找出所开设课程之间的内在联系,为专业人才培养方案的制订提供参考,为教务管理人员教学工作更科学地安排提供依据。
数据挖掘;Apriori 算法;课程设置;成绩分析
0 引言
众所周知,在学校中考试成绩是衡量学生掌握知识的水平的主要标准,每学期结束后学校会安排期末考试对学生进行考核,考试结束后,任课教师或教务管理人员将学生成绩录入教务管理系统[1]。当前存在的问题是教务管理系统中存放了大量成绩数据,而对这些数据并没有很好利用,仅仅是简单的查询和统计,无法获取成绩之间隐含的大量信息,比如学生为何取得这些成绩,开设课程之间以及学生的成绩与课程的设置之间的联系。如何更好地充分利用这些资源,找出学生成绩之间、课程之间的联系,从而更好地方便我院安排教学任务,制订教学计划等工作,对学院教学工作起到积极的指导作用是目前急需解决的问题[2]。
数据挖掘(Data mining)就是从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。数据挖掘是指一个完整的过程,该过程从大型数据库中挖掘先前未知的、有效的、可实用的信息,并使用这些信息做出决策或丰富知识[3-4]。将数据挖掘技术应用于学生成绩分析,其挖掘出的信息能够使教务管理人员能更快地掌握其内在联系,而且由于采用现代技术,其工作量小,分析及时,便于更快、更及时地进行教学工作。
1 数据挖掘对象及目标
本文中将我院计算机工程系计算机应用技术专业在校三年的学习成绩作为研究对象,成绩从《计算机文化基础》、《C语言程序设计》、《C#程序设计语言》、《操作系统原理与设计》和《数据结构与算法》这5门课程获取,通过利用Apriori算法挖掘出这5门课程的潜在关系,即某课程成绩的等级对其他课程的影响程度,为学院教务工作人员及本专业教师制定人才培养方案提供参考,同时也为其他在校生的课程安排提供帮助。
本文中的成绩数据全部从我院教务管理系统中获得,在每学期结束后任课教师将授课课程的学生成绩录入到教学管理系统中,该数据均产生于教学过程中,真实有效。本文将得到的数据收集并保存至系统学生成绩分析表中,如图 1所示:
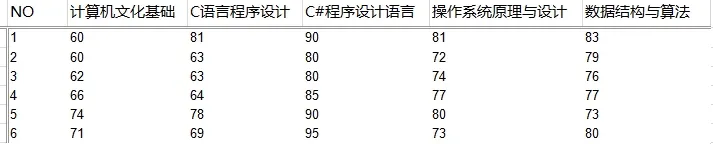
图1 学生成绩分析表图
2 数据预处理
对收集到的数据在进行挖掘之前应进行数据的预处理,将其转换为适合挖掘模型的数据,包括数据清理、数据转换、数据消减等过程,其工作量约占挖掘过程的60%以上[5-6]。根据采集数据的特点,需要对其进行预处理从而满足数据挖掘的需要。
在学生成绩分析基本表中,若存在空缺值的记录,则需要通过数据清理技术对这些空缺进行填补。通常有下面几种方法:人工填写空缺值;忽略元组;使用一个全局常量来填充空缺值;使用同一数据表中的同一个属性的平均值来填充空缺值;使用同类样本中同一属性值的平均值;预测一个最有可能的值来填充空缺值[7-8]。在本文中通过采用忽略元组的方法对空缺值进行填补,即只分析符合条件的学生成绩。由于选取的数据有限,空缺值较少,当对于个别空缺值采用人工填写方式完成,个别的成绩修改不会影响最后的分析结果。
为了方便后续挖掘工作的开展,本文对课程和成绩都转化成特定格式的字符串,课程转化的方法比较简单,具体如表1所示:

表1 课程名称映射表
根据成绩的高低将其转化为5个等级,分别是优秀、良好、中等、及格和不及格。“优秀”为成绩90分以上,“良好”为成绩在80~89分之间,“中等”为成绩在70~79分之间,“及格”为成绩在60~69 分之间,“不及格”为成绩小于59分。在本文中采用数字“1、2、3、4、5”表示“优秀、良好、中等、及格、不及格”5个等级,具体如表2所示:

表2 学生成绩映射表
根据课程名称和学生成绩映射表的使用,部分学生成绩转换前后的数据分别如表3、表4所示:
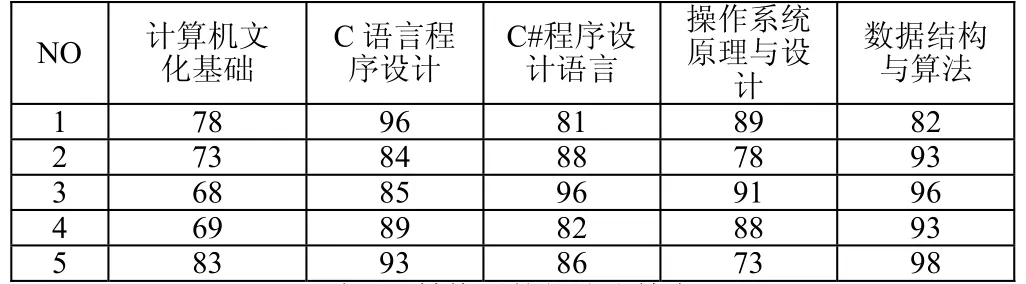
表3 转换前的部分成绩表

表4 转换后的部分成绩表
以“C1”为例,具体代表的含义为“C#程序设计语言成绩为优秀”。
3 Apriori 算法构建及规则提取
在本文中对学生成绩进行数据挖掘,找到课程之间的相互关系以及关联性,从而更好地为以后人才培养方案的制订提供参考。在之前以及对挖掘的数据进行数据预处理,从而满足数据挖掘的需要,本文采用关联规则Apriori算法对数据进行分类和挖掘[9][10]。
关联规则 Apriori 算法是关联规则中的经典算法,该算法使用频繁项集的先验知识,使用一种称作逐层搜索的迭代方法,k项集用于探索(k+1)项集。首先,通过扫描事务(交易)记录,找出所有的频繁1项集,该集合记做L1,然后利用L1找频繁2项集的集合L2,L2找L3,如此下去,直到不能再找到任何频繁k项集。最后,再在所有的频繁集中找出强规则,即产生用户感兴趣的关联规则[11][12]。
关联规则 Apriori 算法伪代码如下:

在本文中应用Apriori 算法对学生成绩进行挖掘的具体实施步骤如下:
(1)建立事务数据表DM_scores。将数据挖掘收集的数据处理后存入到成绩分析数据表。
(2)调用存储过程find_ candidate_1_itemsets。将事务数据表中的成绩等级累计出现的次数统计出来,然后将统计结果存入到frequent_l_itemsets表(即频繁 1-项集表)中。在该数据表中,包含字段Name和Count两个字段,其中字段Name的数据类型为字符型,用于存放项目的名称;字段Count的数据类型为数值型,用于存放各项目在数据表中累计出现的次数。(3)调用存储过程find_frequent_l_itemsets,将字段Count的值小于最小支持度min_sup 的记录从 frequent_l_itemsets 表中删除,从而得到最终的频繁 1-项集。
(4)重复使用第二步骤和第三步骤,通过候选项生成最终的频繁项集。具体流程:首先,通过扫描数据表产生的频繁(n-1) -项集,再通过对频繁(n-1) -项集的扫描,产生 n的候选集,将其以字母升序的方式存入到频繁 n-项集表中。然后,根据扫描数据表 DM_scores的结果计算出候选 n-项集的支持度,并将其存入到数据表frequent_n_itemsets 的Count字段 中。最后,将frequent_n_itemsets 表中小于最小支持度 min_sup 的字段Count 的值删除,在检索过程中若发现某候选项集 Ci=φ,则算法终止,从而达到全部的频繁项集。
(5)从得到的频繁项集入手,计算出频繁n-项集的所有非空子集的置信度,将置信度大于最小置信度阀值的记录筛选出来,并存入到数据表 DM_Rules中,从而生成最终的关联规则。
4 数据挖掘
经过数据挖掘Apriori算法分析后,产生{B2,E1}和{C2,E1} 2 个频繁项目集,根据这2个频繁项集中确定其的子集,使用关联规则挖掘算法,设最小置信度为70%,从而得出 以下4 个关联规则,如表5所示:
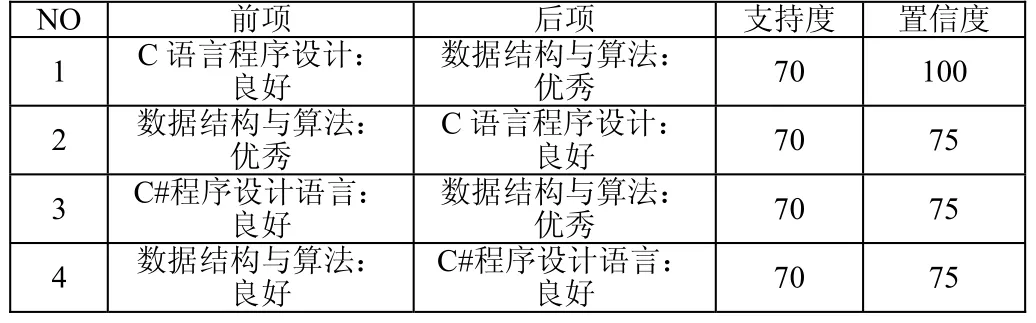
表5 关联规则表
根据关联规则表5可知,专业课程设置是与教学经验相符的,以规则“C语言程序设计:良好=〉数据结构与算法:优秀”为例,说明如下:“C语言程序设计:良好=〉数据结构与算法:优秀”该规则的支持度值为 70,表明学生成绩数据库中有 66*0.7=46条记录满足该规则;另外由于该规则的置信度值为100,则表示若C语言程序设计学生成绩为良好时,那么数据结构与算法课程成绩在100%的情况下是优秀。该规则说明学好《C语言程序设计》课程对学好《数据结构与算法》课程起到关键作用,那么在人才培养方案制订时就需将《C语言程序设计》安排在前,作为《数据结构与算法》的前导课程。
以规则 4“数据结构与算法:良好=〉C#程序设计语言:良好”为例,该规则的支持度值为70,表明学生成绩数据库中有 66*0.7=46条记录满足这条规则;由于该规则的置信度值为 75,则表示若数据结构与算法成绩为良好时,C#程序设计语言课程成绩在 75%的情况下也是良好。通过该项规则说明这两门课程之间有着紧密的联系,若前者成绩为良好,后者课程的成绩也有很大的可能取得良好。其他规则也可同样进行说明。
根据这些数据和信息,学院可以更好地利用其制订人才培养方案,为教师的授课和课程设置提供参考,同时对于教务管理人员来说,可以从宏观上对学生成绩有个整体的把握。
5 总结
根据当前我院教务管理系统在学生成绩分析过程中存在的不足,提出通过数据挖掘技术对数据进行分析和处理,通过对挖掘对象的确定、数据的采集及预处理、Apriori算法的应用等过程详细介绍具体的实施过程从而发现学生成绩之间的深层次联系,为教务管理人员课程安排提供依据,为我院更好地进行教学工作的开展提供参考,从而更好地提高学院教学质量和水平,培养更适合当前社会需要的人才。
[1]唐松.基于数据挖掘的高效评教系统设计与实现[D].成都:电子科技大学,2010.
[2]姜永亮,符传谊.数据挖掘技术在选课系统中的应用[J].微型电脑应用.2009,8.
[3]毛国军.数据挖掘原理与算法[M].北京:清华大学出版社,2005,7.
[4]Jiawei Han, Micheline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2001.
[5]吴瑞祥.智能数据挖掘与知识发现[M].北京:北京航空航天大学出版社, 2004,9.
[6]龚著琳,陈瑛,苏懿,等.数据挖掘在生物医学数据分析中的应用[J].上海交通大学学报(医学版),2011,11.
[7]林郎碟,王灿辉.Apriori算法在图书推荐服务中的应用与研究[J].计算机技术与发展.2011,5.
[8]成淼.数据挖掘在电子商务中的应用[J].科技经济市场. 2010,9.
[9]章利芳.基于关联挖掘的学生成绩分析系统的研究[D].杭州:浙江工业大学,2011.
[10]李丽,韩仙玉,刘洪江.关联规则算法在汽车故障分析系统中的应用[J].计算机与现代化,2012,6.
[11]蔡红,陈荣耀,陈波.关联规则挖掘最小支持度阀值设定的优化算法研究[J].微型电脑应用,2011,6.
[12]刘瑞祥,邹海.对挖掘关联规则中的Apriori算法的一种改进[J].计算机与现代化,2009,7期.
Research on Data Mining in the Analysis of Student Achievement
Li Qiaojun, Li Wei
(Department of Computer Engineering, Henan Polytechnic Institute, Nanyang 473009, China)
As a kind of data processing technology, data mining can help people find out valuable information from large amounts of data so as to provide guidance for decision making. According to the defects of current student performance analysis, it uses data mining Apriori algorithm to analyze and research in this paper. Based on the analysis of student achievements in the educational administration system, it can find out the internal relations between the courses offered and provide reference to the establishment of professional talent training scheme. At last it also can provide the basis for the scientific arrangements for teaching of the educational administration personnel.
Data Mining; Apriori Algorithm; The Course Arrangement; Analysis of the Performance
TP311
A
2015.01.21)
1007-757X(2015)04-0035-02
李巧君(1983-),女,河南省郑州市人,河南工业职业技术学院计算机工程系,讲师,工程硕士。研究方向:计算机应用技术,网络安全,南阳,473000
李 伟(1982-),男,河南省南阳市人,河南工业职业技术学院计算机工程系,助教,硕士,研究方向:嵌入式与物联网技术,视频编解码,南阳,473000
