改进的LSSVM算法在垃圾标签检测上的应用
2015-07-27杨晓雷杨清琳杜英俊广西财经学院现代教育技术部南宁530003
杨晓雷,杨清琳,杜英俊(广西财经学院现代教育技术部,南宁 530003)
改进的LSSVM算法在垃圾标签检测上的应用
杨晓雷,杨清琳,杜英俊
(广西财经学院现代教育技术部,南宁 530003)
为了解决 Folksonomy 存在垃圾标签的问题,提出垃圾标签检测模型。利用向量空间模型表征用户特征,再用支持向量机将Folksonomy 用户二分类。通过检测出隐藏在正常用户群体中的垃圾投放人,以此减少垃圾标签数量。垃圾标签数据集具有数量大,纬度高的特点。面对传统svm算法处理高维大规模数据集上过于复杂,存在速度和精度的瓶颈的问题,笔者曾经提出用lssvm算法进行垃圾标签检测处理,取得一定的效果。但是,lssvm算法本身也存在稀疏性以及处理重要数据点不敏感的问题,所以针对这点,提出了用剪切法进行解决,通过实验表明,改进的LSSVM提高了建模的精度,而稀疏化的处理虽然对精度有一定影响,但大大减少了训练数据量,从而有效减轻了计算负担,使快速性得到了保障。
垃圾标签;Folksonomy lssvm;剪切法
1 引言
随着 Web 2.0 技术架构的推广,社会网络( SN) 的应用逐渐扩大。社会化标签系统广受大众的欢迎。国内外知名的社会化标签系统有Delicious、Flickr、Last. fm、豆瓣网等。由于采用 Folksonomy 的框架,社会化标签系统特别强调用户参与其创建和维护过程。在 Folksonomy中,用户行为十分自由,这为垃圾信息的投放提供了新的途径。这些投放在社会化标签系统中的垃圾信息,称为社会垃圾( social spam) 或垃圾标签。目前检测垃圾标签的主流方法是从用户中检测出垃圾投放人,通过控制垃圾投放人的行为,达到减少垃圾标签的效果[1]。笔者曾经采用lssvm算法进行垃圾标签检测的应用,虽然比起传统的svm方法有一定的改进,但是lssvm算法本身也存在一定问题。
2 算法的改进
在LSSVM中,由于Lagrange乘子均不为零,因此所有的数据向量都是支持向量。那如何区分这些支持向量的重要程度呢?本章引入了“支持向量度”的概念,为每个训练数据定义了一个支持向量度。训练数据(xi,yi)对应的支持向量度为0<si<1,代表了该数据隶属于支持向量的程度。0<si<1值越大,则对应的训练点隶属于支持向量的程度越高。
给定训练数据集{xi,yi,si}Ni=1。在标准LSSVM优化问题(2.2)的第二项中引入支持向量度构成了改进的LSSVM的优化问题
显然,当所有的支持向量度 定义为1时,改进的LSSVM就是标准LSSVM.从这个意义上说,标准LSSVM可以看成是改进的LSSVM的一种特殊情况。
构建Lagrange函数
根据最优性条件,得到
整理上面的方程组,消去变量。得到矩阵形式为
其中,向量S=diag{S1,S2…Sn}是一个由所有支持向量度{Si}Ni=1丝构成的N×N对角阵。其它参数的意义同前。
假定矩阵
可逆,则参数。和b的解析解可通过下式得到
最终得到的改进的LSSVM模型表达式为
改进的LSSVM建模算法的实施。要实施改进的LSSVM,还存在一个问题:既然支持向量度是由Lagrange乘子所决定的,而Lagrange乘子是由LSSVM学习后产生的,那么在算法没有实施之前,如何得到Lagrange乘子来计算支持向量度呢?我们解决这个问题的办法是,首先假定所有的支持向量度{s*}均为1,训练得到Lagrange乘子,然后根据Lagrange乘子的值来确定支持向量度,然后再进行改进的LSSVM的训练。
针对自回归对象模型,改进的LSSVM回归的一般流程可归纳如下:
(1)由得到的数据集{xi,yi}Ni=1进行训练,得到Lagrange乘子{αi}Ni=1;
(2)根据公式(8),选择合适的数0≤δ≤1,利用上次训练得到的Lagrange乘子确定支持向量度;
(3)构建新的训练数据集{xi,yi,si}Ni=1进行改进的LSSVM训练,得到模型参数{αi}Ni=11和b;(4)根据|αi|Ni=1升序排列训练集{xi,yi,si}N
i=1中的数据,剪除一小部分(如5%)具有最小αi值的数据点;
(5)由剩余的Lagrange乘子重新计算8、,由剩余的数据重新构建训练集{xi,yi,si}Ni=1再次进行改进的LSSVM训练,得到新的Lagrange乘子。如果拟合性能下降,则结束训练,得到对象模型;否则,转至(3)。
3 实验与分析
用改进的LSSVM方法辨识上述模型,采用径向基函数作为核函数。
特此说明的是,因为改进的LSSVM采用迭代方式训练得到Lagrange乘子,然后根据Lagrange乘子的值来确定支持向量度,因此训练时间方面会变长,采用训练时间衡量算法性能是没有意义的,因此我们只用训练精度做为衡量标准。
实验的程序使用MATLAB2009a实现,实验硬件环境:CPU为P4,3.0GHz,1GB内存。所有实验运行15次取平均值。本文采用的数据集来自二元分类测试数据集synth、bc本文采取的源数据包含2个数据文件(tas,bookmark),其中tas文件包含用户、tas_id、标签和对应bookmark_id的关系记录,bookmark文件包含资源、资源描述、bookmark_id和对应tas_id的关系记录。为两个数据文件接由tas_id和bookmark_id来接。
第一组:

表1 bc数据集样本及维度
第二组:
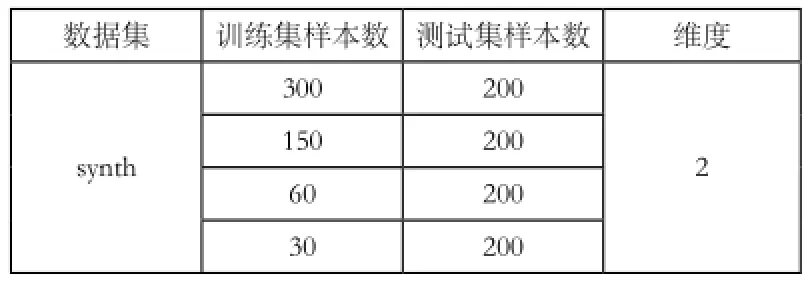
表2 bc数据集样本及维度
实验方案设计分为两组,第一组是训练集样本维度为10的时候,分别采用LSSVM和改进的LSSVM算法进行分类,而第二组是当训练集维度为2的时候分别采用两种算法进行分类。
首先采用标准LSSVM方法分别对bc数据集和synth 数据集取300,150,60,30组采样数据进行训练,然后用200组测试数据进行测试,其中参数由libSVM工具箱自动寻优函数给出,改进的LSSVM中,最小的支持向量度使用上一步标准LSSVM所得出的参数,每迭代一次剪切5%的数据,用200组测试数据得到的测试结果。测试得到的结果如下所示:
第一组:

表3 bc 数据集LSSVM测试结果

表4 bc 数据集 改进的LSSVM测试结果
第二组:
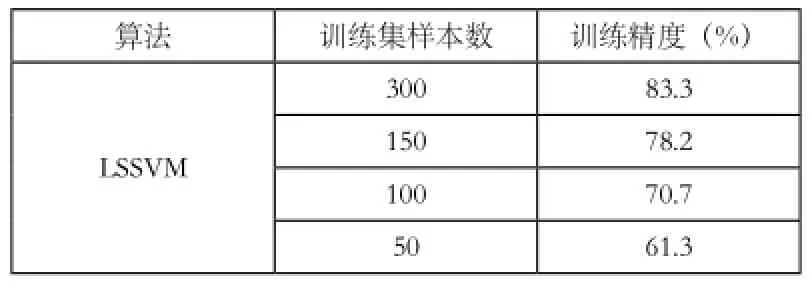
表5 synth 数据集LSSVM测试结果

表6 改进的LSSVM测试结果
由表3和4可以看出可以看出,当我们采用较小数据集做测试时候,比如50,在改进的LSSVM的精度为61.7,而标准 LSSVM为60.5,精度只有微量的提升,而我们增大训练数据集,,采用数据集个数为100和150的时候,精度开始有明显的提高,提高了接近10的百分点。当我们数据量增到到300的时候,提升更是明显,提升了18个百分点。因此,通过实验我们可以发现,采用剪切算法在数据集数量增大的时候,对精度的提高就越明显。同样第二组实验中改进的lssvm算法在低维数据集中,通过表5 和6观察也能得出相同的结论。因此,通过支持向量度的引入采用剪切数据的改进的LSSVM方法,精度要好于LSSVM。因此,通过剪切数据的方法来实现改进的LSSVM算法是可行的。
[1] KIM C J,HWANG K B.Naive Bayes classier.learning with featureselection for spam detection in social bookmarking[C]//Lecture Notes in Computer Science. Berlin: Springer-Verlag,2008.
[2]覃希,夏宁霞,苏一丹.基于支持向量机的垃圾标签检测模型.[J].计算机应用研究,2010,27(10):40-46.
[3]GRAMME P,CHEVALIER J F. Rank for spam dsetection[C]/ /Lecture Notes in Computer Science. Berlin: Springer-Verlag,2008.
[4]Van Gestel, T. Suykens, J.A.K., Baesens, B., Viaene, S., Vanthienen, J., Dedene, G., De Moor, B., Vandewalle, J., Benchmarking least squares support vector machine classifiers", Mach. Learning, vol 54, pp.5-32, 2003.
[5]ADKOUR A,HEFNI T,HEFNY A,et al. Using semantic featuresto detect spamming in social bookmarking systems [C]// LectureNotes in Computer Science. Berlin: Springer-Verlag,2008.
[6]HOTHO A,JASCHKE R,SCHMITZ C,et al.Emergent semantics in BibSonomy[M]. Liskowsky: GI Jahrestagung,2006:305-312.
[7]SALTON G,McGILL M J. Introduction to modern information retrieval[M].New York: McGraw-Hill,1983: 1-12.
[8]http://www.csie.ntu.edu.tw/-cjlin/libsvmtools/datasets/.
[9] BROADLY. Social spam definition[EB/OL].(2008-7-21) .http://www. bryanchen. com /2008 /07 /21 / social-spam /.
[10]Kuh, A., De Wilde, P. "Comments on pruning error minimization in least squares support vector machines". IEEE Trans. Neural Networks, vol 18 (2). 2007.
[11]Lazar, A. Income prediction via support vector machine[C]. New York:Machine Learning and Applications, IEEE 2004' Proceedings,2004.
