基于Spark的海量图像检索系统设计
2015-07-25王迅冯瑞
王迅,冯瑞
0 引言
基于内容的图像检索是指根据查询图像的视觉特征,在图像库中找出与之相似的图像。随着计算机科学技术和数字图像采集技术的迅速发展以及互联网的普及应用,每天从各行各业都产生出大量的多媒体数据,这些数据大部分是以图片和视频等形式表现的,传统基于单节点架构的图像检索系统存在检索速度慢、并发性差,实时性和稳定性无法保障等问题,已经不能满足人们对于检索性能的要求。因此分布式地图像处理、快速及时地图像检索方法成为了研究热门。
本文提出了一种基于 Spark[1]的图像检索方法,能够处理海量图像上的图像检索问题。该系统主要由离线特征提取,视觉词袋模型[2]训练,在线图像检索3部分构成。原始图像集和提取的SIFT[3]特征都存储在Hadoop文件系统HDFS[4]上。集群能够随图像数据的增大,动态地增加集群节点数。
1 基于BoVW的图像检索
视觉词袋模型(Bag-of-Visual-word,BoVW)是将文本检索中的Bag-of-words模型应用于图像检索。和文本检索相似,为了表示一幅图像,我们可以将图像看作是若干个“视觉单词”组成的文档,视觉单词相互之间没有顺序。基于视觉词袋模型的图像检索方法由Sivic和Zisserman等人于03年首次提出。BoVW是一种无监督学习,可以高效的对未经过标注的的图像数据集建立索引。基于视觉词袋模型的图像检索方法主要有如下步骤构成:
(1)特征提取
将图像集中的图像进行特征提取,基于 BoVW 的图像检索一般使用图像的SIFT特征。
(2)视觉词袋模型训练
利用聚类算法对提取的特征进行训练获得视觉词袋模型。
(3)构建视觉词频向量
对于图像的每一个特征,通过最近邻的方法在视觉词典中找到对应的视觉单词。记录每个视觉单词出现的次数,这样一张图像就可以用视觉单词的视觉词频向量(Term Vector)表示。
(4)相似图像检索
根据视觉词袋模型,计算出图像库中每张图像的视觉词频向量。输入查询图像,提取图像特征,根据训练出的视觉词袋模型计算出查询图像的视觉词频向量,然后和图像库中每张图像对应的视觉词频向量计算相似度,相似度靠前的图像即为相似图像。
1.1 特征提取
本文采用SIFT特征作为图像的基本特征。SIFT特征提取方法是一种提取图像局部特征的算法,在尺度空间寻找极值点,提取位置,尺度,旋转不变量。由于SIFT特征具有尺度和旋转不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性。因此,SIFT是基于视觉词袋模型的图像检索方法中中最常用的特征。SIFT征提取算法主要步骤如下:
(1)检测关键点
首先,构建图像的尺度空间,然后,通过关键点检测算法检测图像的关键点,并分配关键点的方向。得到关键点信息:位置、尺度、方向,如图1所示:

图1
图1提取的关键点信息如图2所示:

图2
图中圆心表示关键点的坐标位置,半径表示尺度,角度表示方向。
(2)提取描述子
根据关键点及关键点周围的像素点梯度信息提取图像的SIFT描述子,通常描述子大小为128维,关键点的个数由图像大小和图像梯度分布所决定。
从图1中提取的SIFT特征如下所示,关键点个数:2367,SIFT描述子维度:128

传统的特征提取是在单机下运行的,无法快速处理海量图像数据的情况。在单台机器无法存储海量图像时,需要将图像分批地存放在多台机器上,在进行特征提取时需要在每一台机器上运行特征提取算法,效率低下。这时需要将图像数据集存储在分布式文件系统中,如 Andrew系统,KASS系统,HDFS等。由于HDFS的易用开源,且Spark能很好地兼容HDFS的读取,本文采用Spark来进行图像特征提取,将提取好的特征以二进制形式保存在HDSF中。
1.2 视觉词袋模型
和文本检索中的分词一样,在多张图像之间虽然存在差异,但是在这些差异中存在相同的地方。如在人脸检测中,虽然不同的人脸在视觉上有差别,但眼睛,嘴,鼻子等一些比较细小的部位却是相似的,从而可以将眼睛,嘴,鼻子等这些部位作为人脸的基本特征,从而用来检测人脸。同样,如果我们把同一类图像之间共同的特征提取出来,就可以作为识别这一类目标的视觉单词,从而可以区分相似图像。这是视觉词袋模型用于图像检索的基本思想。
对于提取的SIFT特征,可以利用K-Means聚类算法构建视觉词典。将图像集提取的所有特征进行聚成 K类,每一个类中心代表一个视觉单词,这样就建立了一个视觉词典。K-Means聚类算法是一种无监督的学习算法,可以用于训练未标注的图像数据集。K-Means是一种基于样本间相似性度量的间接聚类方法,算法以K为参数, 把N个对象分为K个簇,目的是使簇内具有较高的相似度,而簇间具有较低的相似度。利用 K-Means算法合并词义相近的视觉单词,过程如图3所示:
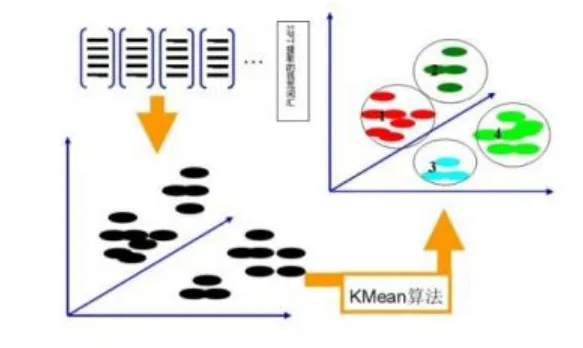
图3 K-Means 过程
K-Means将SIFT特征聚成K类后,每一个类的中心点向量为一个视觉单词,这些视觉单词被看作是组成任意一幅图像的基本单位,K个视觉单词构成一个视觉词典。可视化后的视觉词典如图4所示:
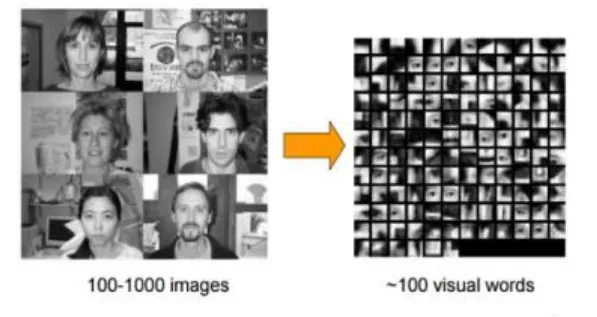
图4 视觉词典可视化
有了视觉词典后,可以用视觉词典中的单词表示一张图像。对于图像中提取的每一个SIFT特征,都可以通过最近邻的方法在视觉词典中找到与之最相似的单词,即该特征与该视觉单词所表示的特征最相近,我们可以认为该视觉单词在图像中出现了一次,对于一张图像的所有SIFT特征,通过统计视觉词典中每个单词在图像中出现的次数,就可以将图像量化为成为一个 K维的视觉单词直方图,即视觉词频向量,如图5所示:

图5 词频直方图
右上角为一张需要量化的图像,词频直方图的高度代表视觉单词出现在该图像中的次数。
对于一个图像数据集,视觉词袋模型的建立的主要流程如图6所示:
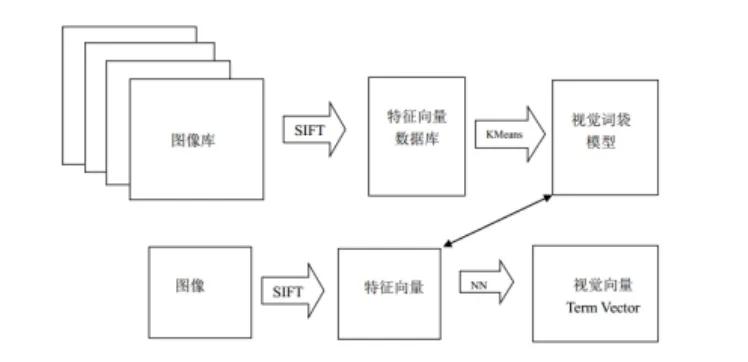
图6 视觉词袋模型建立
1.3 索引与检索
根据视觉词袋模型,计算出图像库中每张图像的视觉词频向量。输入查询图像,提取图像特征,根据训练出的视觉词袋模型计算出查询图像的视觉词频向量,然后和图像库中每张图像对应的词频向量计算相似度,相似度靠前的图像即为相似图像,如图7所示:
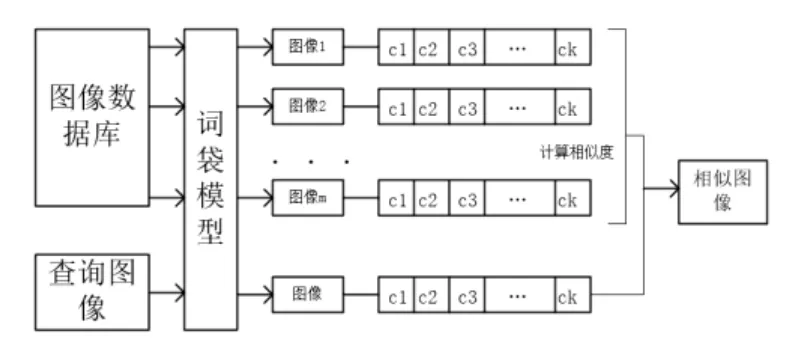
图7 相似图像检索
图像之间的相似度可以用图像词频向量之间的欧式距离度量。对于海量数据集,并且词频向量非常稀疏的情况,可以建立视觉单词-图像倒排索引机制以加快检索的速度。
2 Spark大数据计算平台
传统图像检索系统是在单机上运行的,在海量图像情况下,无法有效地训练视觉词袋模型。本文将Spark计算框架与图像检索技术相结合,该方法在处理大数据图像检索时,具有速度快,可扩展性强等优点,能有效对海量图像进行视觉词袋模型训练。
Spark诞生于伯克利大学AMPLab,是现今大数据领域里最为活跃,最为热门,最为高效的大数据通用计算平台。随着大数据时代的到来,用户对于大数据处理系统的要求也越来越高。而Spark大数据处理框架因为其出色的性能,越来越受到人们的关注。Spark是基于MapReduce思想实现的一个分布式计算框架,Spark继承了Hadoop的MapReduce的优点,但是比Hadoop更为高效。Spark开创性地提出了抽象弹性数据集RDD的概念,使得Spark在处理迭代式,交互式,流式数据时非常高效。
大数据计算中计算过程通常分为多个阶段,在MapReduce中,不同计算阶段之间重用数据,需要将上一个阶段的输出数据保存到外部存储系统中,例如分布式文件系统,这就导致了大量的数据复制、磁盘I/O、序列化,反序列化等开销,这些甚至会占据整个应用执行的大部分时间。而Spark基于内存的计算框架在内存大小足够的情况下,不同计算阶段之间只需要读写内存即可,无需读写磁盘,在磁盘空间不足情况下,也可以像Hadoop一样使用磁盘作为中间结果存储的媒介。对于迭代式的算法,Spark相比Hadoop能提高100倍的速度。
Spark 计算框架使包括 SparkSq、SparkStreaming、MLLib、GraphX子框架,子框架和Spark库之间可以无缝地共享数据和操作,解决了大数据中的 Batch Processing、Streaming Processing、Ad-hoc Query三大核心问题。Spark使用Scala语言编写,运行在JVM上,能够很好地兼容其他基于Java语言的大数据系统,如本文中使用的Hadoop文件系统HDFS。Spark提供的API相比Hadoop更加丰富,Spark程序的编写也更加简单易用,Spark集群的配置相比Hadoop更加简单,这使得Spark成为了大数据处理首选的计算平台,也是本文将Spark应用在海量图像检索系统中的原因。
Spark计算框架如图8所示:
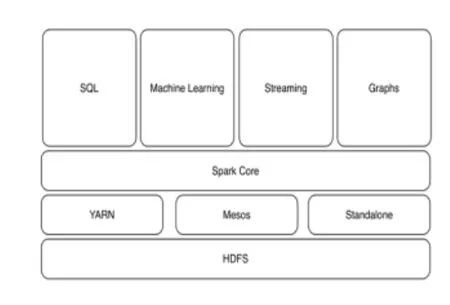
图8 Spark计算框架
3 实验结果及分析
本文提出的计算平台在实验集群上实现。实验集群由1台主节点,4台从节点组成,均为物理机,操作系统皆使用CentOS6.5。集群使用的Hadoop 版本Hadoop-2.4,Spark 版本为Spark1.3.1。
主节点在Hadoop中充当NameNode,在Spark中充当Master。
从节点在 Hadoop中充当 DataNode,在 Spark中充当Worker,如表1所示:
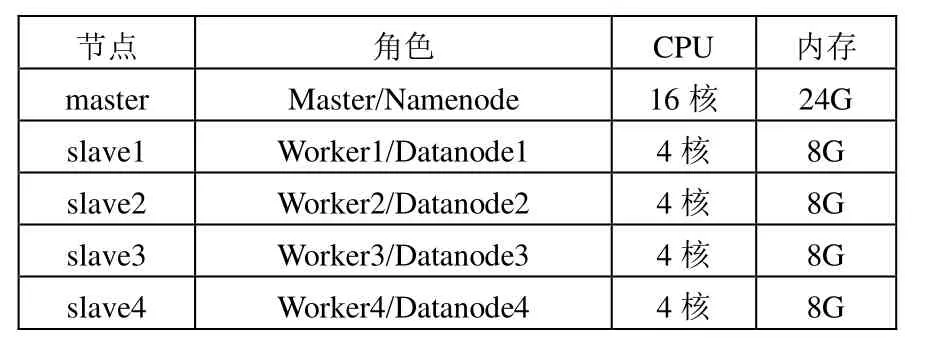
表1 集群配置
本文使用 K-Means聚类算法训练视觉词袋模型。由于K-Means是一种迭代式的计算,用Hadoop的MapReduce框架计算,每次需要将中间的Map结果写到HDFS,然后再从HDFS读取数据,进行下一次 Map。但不同于 MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,从而大大减少了模型的训练时间。
本文在holiday[5]数据集上实验,提取后的SIFT特征集大小为5M,在视觉词典大小分别为100、200、300的情况下,通过改变集群 worker节点数,视觉词袋模型训练的时间测试结果如图9所示:
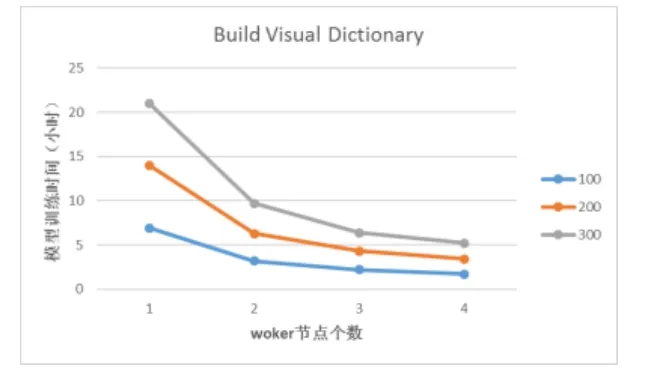
图9 视觉词袋模型训练的时间测试结果
通过实验表明,单机情况无法有效训练视觉词袋模型在holiday数据集上训练大小为300的视觉词袋模型需要21小时。而在 4个 worker节点上训练视觉词典模型只需要 5.2小时,大大减少了模型训练时间,单位为小时,如表2所示:

表2
表 2给出了不同词典大小和不同节点个数下视觉词袋模型的具体时间,与图9对应。
加速比是指同一个任务在单机系统和分布式系统中运行消耗的时间的比率,用来衡量分布式系统或的性能和效果,加速比的计算公式为Sp=T1/Tp,Sp是加速比,T1是单节点下算法的运行时间,Tp是在p个节点下的运行时间。当Sp=p时,是理想加速比。
表2中的测试数据对应的加速比,如图10所示:
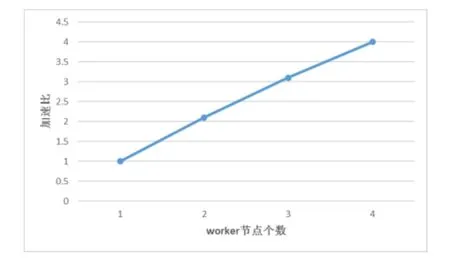
图10 加速比
从图10中可以看出,Spark集群在做视觉词袋模型训练时,因为算法的运行时间远大于网络传输和磁盘IO时间,加速比是随着节点个数的增加而近似线性增长的,这证明算法的性能能够随着节点数的增加而成线性提升,具有良好的可扩展性。通过Spark集群可以高效地训练海量的图像数据,并且可以动态的增加集群节点,以适应图像数据集的增加,具可扩展性,高效性的特点。理论上可以处理任意大小的数据集。
训练好视觉词袋模型后,在holiday数据集上0.1秒内即可查询到相似图像。查询结果如图11所示:

图11 查询结果
4 总结
本论文提出了一种基于Spark的海量图像检索系统,使用 HDFS作为图像和特征的存储系统,用Spark计算框架进行分布式计算。实验表明本系统与传统单节点图像检索系统相比,具有快速,高效,可扩展性强等优点,适合在大规模图像数据集上使用。
[1] Zaharia. M, Chowdhury.M, Franklin.M. J, Shenker.S,and I. Stoica, Spark: cluster computing with working sets.the 2nd USENIX conference on Hot topics in cloud computing, 2010:10[C].
[2] Sivic J,Zisserman A.Video Google: A Text Retrieval Approach to Object Matching in Videos[C]. Nice, France:ICCV, 2003
[3] DAVIDG.LOWE.Distinctive Image Features from Scale-Invariant Keypoints[J]. International Journal of Computer Vision 2004, 60(2): 91-110.
[4] Borthakur.D, “The hadoop distributed file system:Architecture and design,”[C] Hadoop Project Website,2007,11:21.
[5] Herve Jegou, Matthijs Douze and Cordelia Schmid.Hamming Embedding and Weak geometry consistency for large scale image search[C]. Marseille, France:ECCV,2008.
