基于GATE的楚辞语义标注研究
2015-07-05周澍绮南通大学文学院楚辞研究中心江苏南通226019
●周澍绮 (南通大学 a.文学院;b.楚辞研究中心,江苏 南通 226019)
1 现状概述
在人工智能领域,汉语的机器学习一直受到学界的关注。不同于英语,汉语多字成句,没用明显的中断和语义间断,所以汉语的计算机学习需要单独的切分软件辅助,常见的算法有最短路径算法,隐马尔科夫模型算法(Hidden MarkovModel,HMM)。其中的佼佼者是基于HMM的ICTCLAS系统,其凭借高精度分词与高速度分析在众多开放分词软件中脱颖而出。研究发现,该系统在切分标注常规汉语时表现出色,但在对中国传统文献的处理时,结果并不理想。古文中除对仗等特殊网络现象之外,语法规律性并不明显,单纯的优化统计和概率的算法对古文切分的效率提高并不明显。因此,针对古汉语的识别和标引,国内已有研究成果有利用古文注疏切分 《左传》,[1]有利用音韵识别宋诗,[2]有利用中药信息优化医学古籍切分算法,[3]利用互动信息推动“红学”的发展。[4]
本文以先秦楚辞为研究对象,首先利用ICTCLAS系统以《楚辞》[5]为研究标的进行测试样本切分。此书兼具横版古文、白话注释、白话评注等多个方面的语料,能够对切分词算法和标注性能进行多方面性能的评测,如图1。
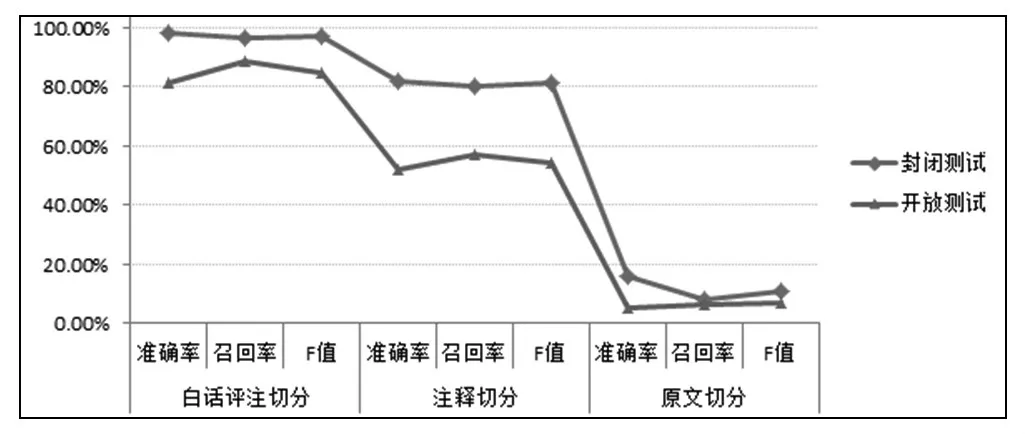
图1 切分词效率
数据显示,内容离现在越远,切分的效率越低,同一内容,开放测试准确率低于封闭测试。在不同内容方面,涉及楚辞的原文切分,在扩大切分词词典的情况下,准确率和召回率依旧低于20%。通过上述实验可以发现,现有切分方式无法直接应用于楚辞,程序和算法无法满足半自动构建楚辞语料库的基本要求。因此,楚辞语义化的首要任务就是寻找一种适用于楚辞的预处理方法。
楚辞的预处理可以从古籍格式、行文语法、特征词表三个方面入手。楚辞文献具有多种古籍版式:横版古文、竖版古文、双行注释、矮字注释、标引注释等不同排版,在断句、行文、标注方式上都存在明显差异,所以在ORC阶段就需要对数字化文献进行校勘。行文语法与特征词表,在ICTCLAS系统中内置语法有相应识别算法和词典,但是仅靠低效率的统计算法和内置词典识别楚辞远远不够。所以提高程序对古文识别率,不仅需优化切分技术的逻辑和算法以切分,[6]对切分文本进行有效标注也很重要。
程序标注技术主要分为字典搭配和自然语言处理(NLP)。字典搭配主要通过举例、频率、互信息等计量学信息通过大样本来寻求词组搭配规律;自然语言处理通过自然语言学习规则找到不同语境下,语素之间的关联和上下位关系,以典型规则推演普通语境来提高机器识别语料的准确率。一般认为,基于规则的方法性能优于基于统计的方法,但是无论规则还是字典,不同时代的文本都有其适用性,制定具有不同时代特征的语料库成为研究重点。
通过分析楚辞的一些基本特性,结合字典搭配和NLP,试图在楚辞语料库建设中寻找一种标注改进方法来提高程序对楚辞文本的识别率,由此减少人的参与度,实现程序化构建楚辞语料库。
2 研究背景
课题选择文本工程通用框架平台GATE,以特征词表与语义规则为重点,结合数据库和语义抽取技术,半自动的提取以体词为主的语义知识。流程如图2所示。

图2 语义提取流程
流程核心是特征词表的整理和语义规则的设计。特征词表是指在目的文本中具有特殊含义词的集合,它在同类作品中多次出现,作用相近,一次处理可形成回溯词库,在后期的标注抽取中重复使用,减少手工标注错误和时间,特征词能作为楚辞语料提供种子库。语义规则是楚辞语法中的行文规范。在不同的题材作品中行文方式不同,白话文亦有千般写法,更何况距今日久的楚辞。利用规则引擎JAPE,以《楚辞语法研究》中的语法规则为基础,将楚辞语法程序化,提高程序识别的准确率。
2.1 GATE
GATE[7](General Architecture for TextEngineering)系统是基于规则的信息抽取系统,始于1995年英国的谢菲尔德大学,包括开发环境和框架,以及更常见的概念表示软件系统组织结构。
GATE作为处理自然语言软件系统,可以有效地分解成不同类型的组件。
(1) 语言资源 (Language Resources,LRs):表示实体,如词典,语料库或本体;
(2) 处理资源 (Processing Resources,PRs):表示主要算法实体,如,解析算法,生成算法;
(3) 可视化资源(Visual Resources,VRs):表示可视化和编辑GUI组件。
GATE支持的文档类型包括XML、RTF、Email、HTML、SGML以及纯文本文件。经历了数年的发展,GATE已经被应用于广泛的研究和项目开发。
GATE对楚辞信息抽取系统提高中文识别准确率的同时,还提供全面的先秦文献词表作为后续语料库的训练语料。
2.2 JAPE
JAPE[8]是Java标注模式引擎 (Java Annotation Patterns Engine)。JAPE提供了基于正规表达式的标注有限状态转换,是CPSL(Common Pattern Specification Language)的一个版本。GATE中标注实体采用规则方式主要由规则解释引擎JAPE触发。
JAPE语法可以分为左侧(LHS) 向右侧(RHS)两个部分,这两个部分由一系列的模式规则构成为标注特征值提供支持,其中右侧规则可以使用Java代码创建更强的控制。规则的左侧(LHS)是一个标注模式,由规则表达操作符(*,?+….)构成。右侧(RHS)是标注操作声明,标注对规则左测的匹配,通过一些模式元素的关系标签实现到规则右侧。左右规则匹配模式可用有三种主要方式指明:① 指明文本的一个字符串;② 指明由Gazetteer,Tokeniser等预先指派的一个标注;③ 指明一个标注的属性(值)。
在每一个语法的开始处,有两个选项设置:一个是控制,它定义了Appelt、Brill、All、Once四种规则匹配方法;另一个是调试,用于处理冲突与匹配;如果出现不止一种的匹配,就会显示冲突;如果没有标注被定义,所有的标注都会被进行匹配。规则从本质上可以分为两种类型:第一种不包括内置词表gazetteer查找功能,可以定义一些小的格式;第二种类型主要依赖内置词表gazetteer,需要更多的规则来描述所有标注,包含了更大范围数据的可能性和更强的处理潜力。
通过JAPE语言的理解,设置规则来识别楚辞语法,结合内置词表gazetteer,提高楚辞文献中名词实体识别的准确率。
2.3 楚辞特征词表
经分析,基于HMM模型和数据平滑技术的算法对楚辞识别效率并不高,同时,通用词表的覆盖面与扩展性有限。更重要的是建设特征词表是建设楚辞语料库的基础。因此,需要建设一个楚辞知识特征词表。
词表的建设要经过分析文本特征。根据现代汉语中词的用法划分,将文本内容用词归类为实词、虚词等四大类十一个小类。[9]按照功用分为注释类、知识类。其中注释类指具有具体含义的实用性名词,以体词、谓词、加词为主,包含子类专有名词,方位名词、形容词、加词(区别词);此类词有具体含义,可追根溯源。知识类是不可量名词,谓词中的动词以及全部副词。此类词主要以抽象指代含义为主。同一个词在不同语境中所指代的含义不同。以此为基础构建满足分类要求的词表以扩充GATE自带词表。设立新的常用词词表,增加虚词、专用名词库,以《楚辞》中《离骚》《九歌》《九章》等21篇,句式整齐的文本作为实验文本,经专家校对修改,形成初始特征词库。
2.4 楚辞语义特性
根据楚辞句式,句法,创作时期[10]对《楚辞》各篇进行区分。楚辞在不同时代有不同的研究版本,根据历代注和疏的版本,专家学者研究成果,参考作者(屈原,宋玉等)、成文时代(怀王时期,襄王时期)、写作风格(说理型,散文型)等多种元素,分析《楚辞》行文语境,将楚辞的行文语境分为三类,即句式型、虚词型、特殊词语,详细分类如下。
(1) 句式型。①“离骚型”(《离骚》《九章》):两句一韵,上句末尾用“兮”;百神翳其备降兮,九疑缤其并迎。②“橘颂型”(《橘颂》《涉江》《抽思》《怀沙》《乱辞》):两句一韵,“兮”字位于下句末;后皇嘉树;橘徕服兮。③“九歌型”(《九歌》各篇):两句一韵,前后皆在句中用“兮”,且兮字都在每句的倒数第三个字;灵偃蹇兮姣服,芳菲菲兮满堂(东皇太一)。
(2)虚词型。屈原利用虚词将四言拓展为长句,所以根据诸多虚词将楚辞断为不同的短语,减少句子的长度更易于标注,如“兮”多做虚词用于表达颂唱和歌唱的节奏,所以“灵偃蹇兮姣服,芳菲菲兮满堂”。根据虚词,分为灵偃蹇、姣服、芳菲菲、满堂。
(3)特殊词语。在楚辞中,连绵词、双声叠韵的使用较为频繁,这些词在标注过程中,常会遇到因为句读不正确而造成大量的歧义;将所有连续出现即ABB结构的词都统一标注,单独列出重言(叠词)、连绵(双声连绵,叠韵)、并列复合词、类义并列复合词、反义并列复合词等特殊词语。
3 楚辞特征信息识别
3.1 ANNIE特征词表
ANNIE是GATE中的一个信息抽取系统。所有的ANNIE组件通信任务通过GATE标注文档和资源。
整体考察余华先锋创作时期内诞生的作品则可以发现,他对于开拓暴力、疯癫、死亡、漫游等叙事的广度与深度可谓是乐此不疲,在《河边的错误》、《古典爱情》、《鲜血梅花》之前及同一时期的《十八岁出门远行》、《现实一种》、《一九八六》等皆有探索,如果说创作的主题是相对单一的,那么这种形式实验便可以被视为是余华先锋创作过程求新求变的表现。而从上述的分析也显示出,作为具有特定形式的传统文体所原有的文学母题为余华的创作既提供了写作素材,也提供了更多思考现代性问题的契机或媒介。
ANNIE词表是ANNIE的一部分,每个独立的词表都是一个普通的文本文件。每一系列有一个lists.def的索引文件用来描述所有这样的词表列表文件,列表文件与索引文件在同一目录下,通常同gazetteer词表同一级。词表查找器从关系库中查找所有在文本中出现的实例,通过词表索引文件获取实例和本体间的关系,然后给出文本中实例的列表。索引文件表述了每个列表的主要类型,次要类型和语言,之间用冒号隔开。新增楚辞词表def文件配置内容,第一列是表名,第二列是主要类型,第三列是次要类型,如图3。这些列表被编译至有限状态,来匹配的任何文本字符串将被指定主要类型和次要类型的特征标注。主要类型,次要类型和语言将作为特征值添加到Lookup标注中。如place.lst词表中,列表与文档中某些文本匹配,词表处理资源将产生一个Lookup标注,特征主要类major指向noun,次要类指向place。

图3 楚辞语料预设关系
楚辞所用词存在古今异义、词义扩大、词义变更等问题,GATE缺乏专业领域词表,自带的基础中文处理组件尚不足标注古文,所以需要在数字化楚辞词典的基础上,借鉴领域专家研究成果,合并切分词训练库,选出古今异义、用法差异的词进行删剔,修改、构建楚辞领域词表。表1是词表归类中的部分名词。依照词性划分楚辞中的词类,制作语义特征词表,见表2。
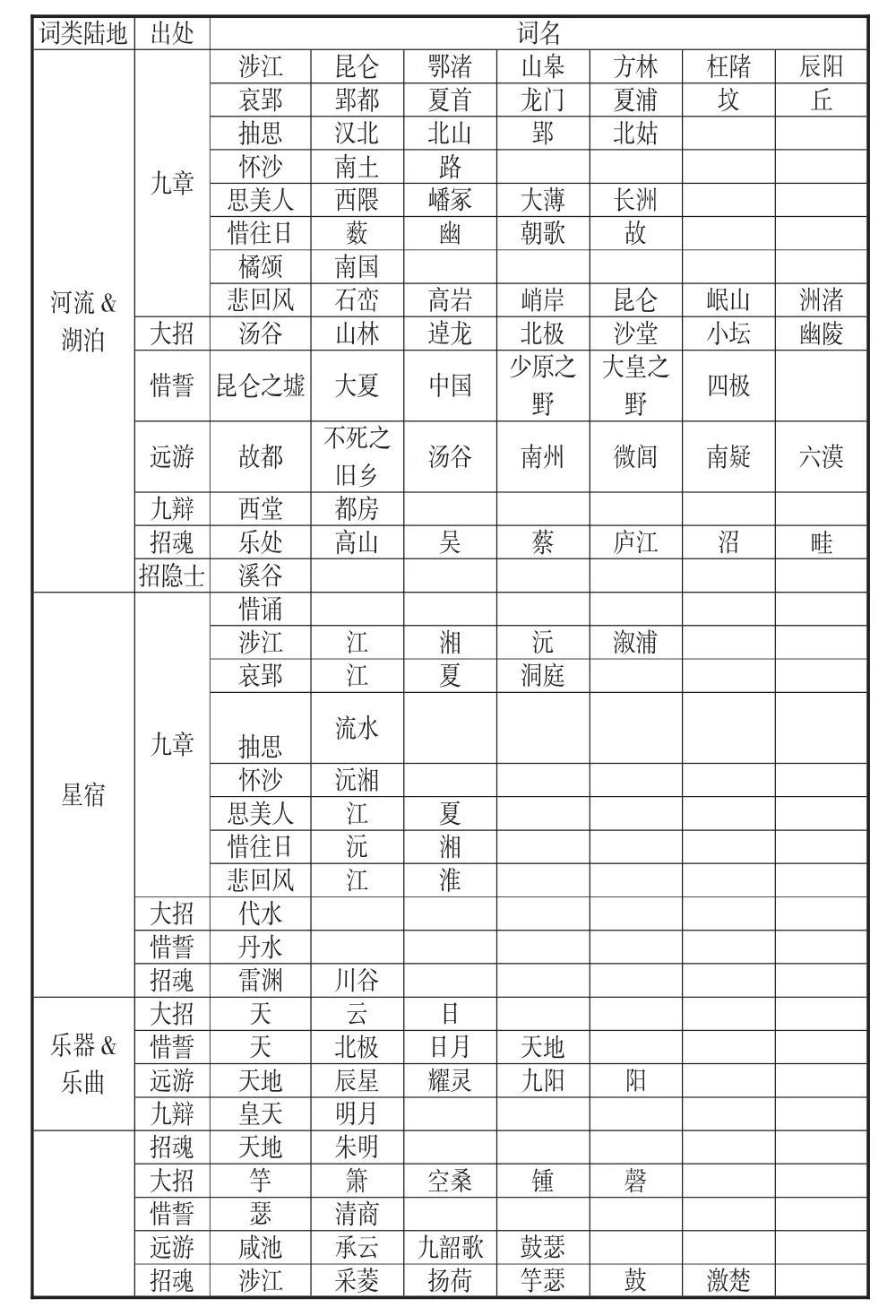
表1 名词词表归类

表2 词性分类与数量
3.2 JAPE规则的设定
在构建楚辞特征词库后,还需要设定标注规则。规则分为两种,一类识别词表中已设定的词,一类标注词表中未录入的词。规则会在词后方添加词性标记,结果以XML格式校对,存档。
第一类规则是楚辞行文中的实体,如人名、官职、神灵名等,其标志符唯一。此类规则主要依附于ANNIE,Gazetteer词表,同时利用命名实体识别规则(统一以jape后缀文件存储)。程序利用lists.def在目标文本和后台词表建立联系(Lookup),系统会标注目标文本中与词典文件中相匹配的词或词组。部分词表代码如下。

凡词表中所录的词会被规则标注,右侧结果在多类规则执行后,目标文档不仅显示人名泛指,也包括植物名、感情类名词等更多的标注结果。在进行词表匹配后,开放式文本中会存在没有被词表收录的词,这类词的词性和分类就需要依靠第二类规则半自动判断未录入词。
未录入词判断是以现代汉语语法为基础,这类规则,需要根据短语的固定结构从已知获得未知。从已知的短语的结构和部分词的词来判断未知词,以固定结构与已知词性相搭配识别未知词。
从行文逻辑上观察,先秦散文楚辞中存在的多种短语。就汉语语法,每一种楚辞短语都存在组成的固定结构,见表3。
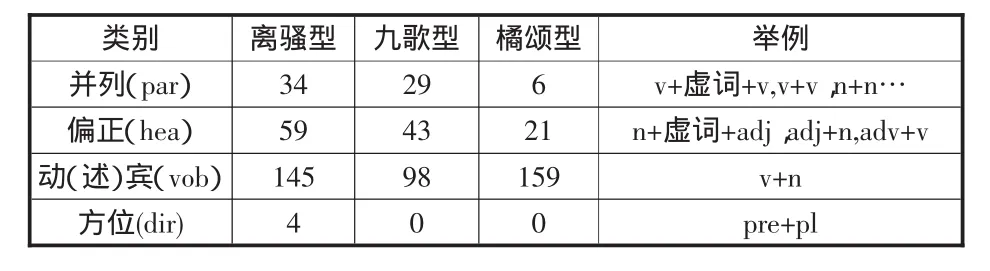
表3 楚辞短语构成
以方位型短语为示例,方位型短语常见结构为:兮+方位名词+方位助动词。
同理可将表3中四类短语转换为规则代码。
(1)并列型。并列型以基本短语出现在楚辞中,句法结构简单,在知识抽取过程中准确率高,关系关联明确。如秋兰兮麋芜,罗生兮堂下《少司命》。
(2)偏正型。偏正型由两部分组成,并且这两部分是修饰和被修饰的关系。修饰部分叫做修饰词语;被修饰部分叫做中心词语。我们标注其中心词语为有效知识。如鱼隣隣,波滔滔《九歌·河伯》。
(3)动宾结构。动宾结构就是这两个成分组在一起,前置位是谓词(动词为主),后置位是体词;谓词+体词(名词或代词),如鸣篪兮吹竽《九歌·东君》。


规则的使用一方面可以重复标注不同文献中的楚辞相关名词,另一方面能够扩大楚辞特征词库。代码将语法层面的短语转换为程序能识别的格式,结合已收集词表,在规则既定的情况下,推理出词表中未录入的词进行词性标注。

表4 标注准确率

图4 虚词比例与标注准确率
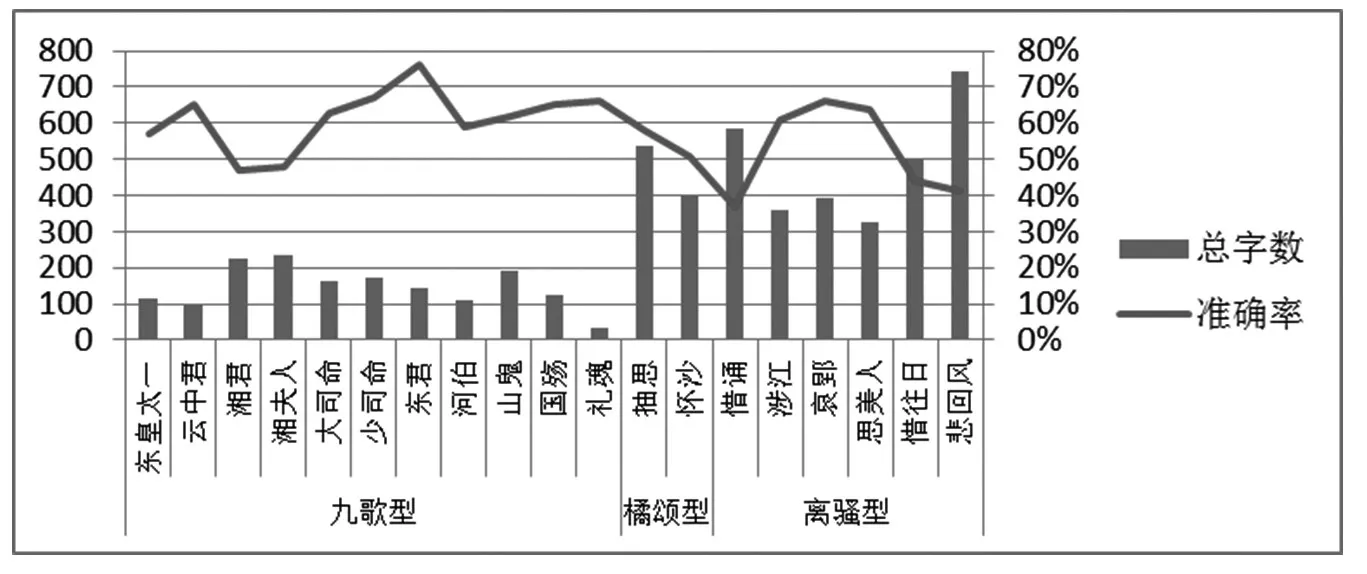
图5 标注准确率与字数关系
3.3 标注结果
结构化的规则设定后,以离骚、九歌、橘颂作为训练样本,以相同类型不同内容的《九章》,《涉江》,《抽思》等篇章为样本进行测试,结果如表4。
虚词比例与标注准确率如图4,准确率多集中于40%-80%,虚词的比例同标注的准确率正比,在以楚辞为代表先秦散文诗中,虚词的位置较为固定,一般存在于句中与句末,主要用于断句。
从图5中可以发现,各类型内部波动较大。有效标注率与字数成反比,整体而言,字数:九歌型<橘颂型<离骚型;准确率:九歌型>橘颂型>离骚型。
规则的设定在考虑语法本身的复杂度时,也要考虑穿插在同一文本中不同语法类型结合的方式。在同一篇文章中,多重格式相互组合,随着篇幅的增长,组合愈复杂,准确率愈低,给人工校对带来一定困难。规则与词表可以将目标文本按词性标注,标注后的文档以有序的自带库或者通用的网页文档存储。无序的楚辞数字文本在标注后以XML存储,方便二次利用和构建楚辞语料库。
楚辞语义标注至此告一段落,但从这次标注过程可以发现,楚辞的程序标注仍有很多方面需要注意。
首先,规则的上下位关系。同一文本需要接受不同规则的识别,规则的执行顺序不同直接影响标注的准确率,按体词,加词,谓词的执行顺序在试验后进行调整的结果,能降低标注的错误率,但具体词性和推导的执行和位置依然值得深入探讨。其次,楚辞语料库规模造成数据稀疏。数据训练集不足不仅造成标注的准确率偏低,也可能导致设定规则的适用性不足,无法系统地评判规则的实施效率,这点不仅需要增加词表的体积和种类,也要在数据平滑技术上加以研究。最后,处理后的文本以XML存储可以给学习和研究增加方便,但是在此基础上的研究才刚刚开始,结合不同算法和挖掘技术来提高XML文档的使用效率也需要进一步的努力。
[1]徐润华,陈小荷.一种利用注疏的《左传》分词新方法[J].中文信息学报,2012,26(3):3-5.
[2]穗志方,等.宋代名家诗自动注音研究及系统实现 [J].中文信息学报,1997,12(2):3-6.
[3]方晓阳,等.TF型中药数据库的建立与应用[J].中国中药杂志,2002(5):2-3.
[4]罗凤珠.以“互动观念”建立“红楼梦网路资料中心”对红学发展之影响[J].红楼梦学刊·一九九七年增刊,1997(2):2-5.
[5]周建忠,贾捷.楚辞[M].南京:凤凰出版社,2009.
[6]钱智勇,等.基于HMM的楚辞自动分词标注研究 [J].图书情报工作,2014,58(4):105-110.
[7] Hamish,Cunningham.DevelopingLanguageProcessing Componentswith GATE Version 7(a User Guide)[J/OL].[2014-10-20].http://gate.ac.uk/.
[8] DhavalThakker,TahaOsman.GATEJAPEGrammar TutorialVersion1.0[J/OL].[2014-10-20].http://gate.ac.uk/sale/tao/splitch8.html#chap:jape.
[9]齐沪扬.对外汉语教学语法[M].上海:复旦大学出版社,2005.
[10]廖序东.楚辞语法研究[M].北京:商务印书馆,2006.
