压缩算法在GSM-R分组域数据传输中的应用研究
2015-07-05王开锋王祖元
王开锋,蒋 韵,王祖元,付 嵩
(中国铁道科学研究院 通信信号研究所,北京 100081)
压缩算法在GSM-R分组域数据传输中的应用研究
王开锋,蒋 韵,王祖元,付 嵩
(中国铁道科学研究院 通信信号研究所,北京 100081)
大量铁路应用业务使用GPRS实现车地之间的数据通信,对GPRS资源的竞争问题十分突出。对游程编码、哈夫曼编码、算术编码、LZSS算法、LZW算法等压缩方法进行研究,通过现场实验,对无线车次号校核信息、调度命令信息、列控动态监测信息等业务数据的压缩效果进行对比分析。
GSM-R;GPRS;压缩算法
我国铁路GSM-R网络采用GPRS承载列车无线车次号校核信息传送、调度命令信息无线传送、列控动态监测等应用。越来越多的铁路应用业务规划使用GPRS实现车地之间的数据通信,如站车信息交互、列车尾部信息传送、灾害监测预警信息等。随着数据量的增大,可能会导致GPRS信道拥塞,影响业务的正常应用,特别是在大型车站、动车运用所等用户相对集中的地段,对GPRS资源的竞争问题更加突出。数据压缩技术是缓解GPRS信道拥塞、提供GPRS资源利用效率的有效途径之一。可以在不丢失信息的前提下,通过采用无损压缩算法,缩减数据量,进而提高其传输、存储效率。
1 常用压缩算法
数据压缩算法可以分为无损压缩和有损压缩两种。无损压缩通过消除统计冗余实现数据的缩减,在数据解压时能够完全还原源数据。有损压缩在允许一定程度信息损失的前提下,移除一些不重要的信息,可以达到更大程度上的数据压缩。在GSM-R网络中,车地之间必须保证数据完整无误的传输,因此只能采用无损压缩技术。在数据压缩领域,采用数据压缩比来描述压缩效果,数据压缩比没有统一的定义,本文采用如下公式[1]:
压缩比= 压缩后数据长度/未压缩数据长度
根据上述定义,压缩比的数值越大,压缩的效率越高。无损压缩的压缩比和数据中统计冗余相关,若压缩后的数据长度和源数据长度相同,压缩比为1;若压缩后的数据长度大于源数据长度相同,则压缩比大于1。无损压缩又可以分为基于统计的压缩算法和基于字典的压缩算法。基于统计的方法首先统计数据中每个字符的出现次数,根据字符出现概率确定不同长度的字符编码,如游程编码、哈夫曼编码、算术编码等。基于字典的方法从一个空串出发,动态构建一个字典,用索引来代替重复出现的字符或字符串,如LZSS算法、LZW算法等[2]。
1.1 游程编码
游程编码是一种简单的统计编码,它统计连续出现字符的频次并使用固定长度的码来代替,例如:对于“AAAAABCCCC”这个字符串,可以用“5A1B4C”代替。可见,游程编码压缩的效果取决于原始字符串中连续字符出现的频次,如果连续出现的字符数较少,游程编码起不到压缩的效果,甚至编码后的数据会增加。
1.2 哈夫曼编码
哈夫曼编码使用变长编码表对源数据进行编码,其核心思想是首先评估源数据中各个字符出现的概率,出现概率高的字符用较短的编码,出现概率低的字符使用较长的编码。这样可以降低编码后数据的长度,从而达到压缩的效果。要实现哈夫曼编码首先需要构造一个哈夫曼树,“chinarailway”可以构造成图1所示的哈夫曼树,出现次数为3的字符“a”用01表示,出现次数为1的字符“c”用0000表示。哈夫曼编码的压缩效率取决于源数据中字符出现概率的分布情况,如果源数据中某些字符出现的概率远大于另外一些字符,采用哈夫曼编码可以得到较好的压缩效果,极端情况下,如果源数据中每个字符出现的概率相同,采用哈夫曼编码无法起到压缩的效果。

图1 哈夫曼树示例
哈夫曼编码生成的数据实际上是由两部分组成:(1)存储的输入字符概率表(用于构造哈夫曼树);(2)是编码数据,这样解码器才能够正常进行解码。
1.3 算术编码
算法编码和哈夫曼编码类似,也需要预先对源数据字符出现的概率进行统计,然后编码,但与哈夫曼编码不同,算术编码并不对每个字符编码,而是将整个源数据编码为[0.0,1.0)之间的小数,编码长度等于各个输入字符概率的乘积。算术编码的压缩效率要高于哈夫曼编码,但算术编码的运算较为复杂。
1.4 LZSS算法
LZSS算法是对LZ77算法的改进,这是一种基于字典的算法,其原理是将源数据中较长的字符串或经常出现的字符构成字典中的数据项,并用较短的数字或字符表示。
1.5 LZW算法
LZW算法是对LZ78算法的改进,编码程序和解码程序都是从一个空字典开始,每次输出一个标记时,创建一个新的短语并加入到字典中。如对于字符串“ABCABD”,将形成如下的字典,如表1所示。

表1 字典表示
2 压缩算法在GSM-R分组域数据压缩中的性能比较
列车无线车次号校核信息、调度命令信息、列控动态监测信息是目前GSM-R中主要传送的分组域数据,本文选取了某条铁路中3类数据各2.1万条,采用各种主流压缩算法对数据进行压缩,图2为数据压缩后的结果。

图2 不同算法的压缩比
从图2看出,游程编码、LZSS算法、LZW算法对于列车无线车次号校核信息可以起到一定程度的压缩效果,游程编码可将源数据压缩为原来的69%左右,对于调度命令、DMS信息压缩效果不明显。这主要是因为调度命令、DMS信息的统计冗余比较小。
哈夫曼编码、算术编码对于各类数据的压缩比均大于1,这是因为采用哈夫曼编码或算术编码时,需要对源数据中字符出现的概率进行统计并保存到压缩后的数据中,而在GSM-R网络分组域数据应用中,每包数据的长度很小,一般在200 byte以下,压缩后数据中字符概率表所在比例较高,使得压缩后的数据反而增大。
为了解决上述问题,本文采用外置输入字符概率表的方法对哈夫曼编码和算术编码进行改进,预先对列车无线车次号校核信息、调度命令信息、列控动态监测信息等各类数据生成字符概率表,对于每条源数据不动态生成也不保存字符概率表。
为了对改进的算法进行验证,从每类2.1万条数据中随机选取0.1万条作为训练序列,统计其中每个字符出现的次数,生成字符概率表,然后对剩余的2万条数据进行压缩,得到图3所示的结果。
如果采用固定的外置的字符概率表后,哈夫曼编码和算术编码均能获得较好的压缩效果,两种算法的压缩比相差不大。对于列车无线车次号校核信息,采用哈夫曼压缩算法可将数据压缩为原来的66%左右。对于调度命令信息、列控动态监测信息,采用哈夫曼压缩算法可将数据压缩为原来的81%左右。
3 结束语
与GPRS应用业务的压缩比和源数据统计冗余有关,从现场实验看,采用游程编码、LZSS算法、LZW算法对无线车次号校核信息可起到压缩作用,对调度命令信息、列控动态监测信息无法进行有效的压缩。采用外置字符概率表的哈夫曼编码、算术编码对各类应用业务数据均能得到较为理想的压缩比。
[1] Salauddin Mahmud. An Improved Data Compression Method for General Data[J]. International Journal of Scientific & Engineering Research, 2012, 3(3):2.
[2] 郑翠芳.几种常用无损数据压缩算法研究[J]. 计算机技术与发展2011, 21(9):73-76.
责任编辑 徐侃春
Application of compression algorithms in data transmission of GSM-R packet domain
WANG Kaifeng, JIANG Yun, WANG Zuyuan, FU Song
( Signal & Communication Research Institute, China Academy of Railway Sciences, Beijing 100081, China )
Train-ground wireless communication was implemented by GPRS for large number of railway application service, therefor, the problem of competing GPRS resource was very prominent. This paper studied on data compression algorithms such as Run Length Coding, Huffman Coding, Arithmetic Coding, LZSS, LZW. Field experimentation was made to contrast and analyze compression effect for the data service such as train number check information, dispatching order information, dynamic monitoring information of train control.
GSM-R; GPRS; compression algorithms
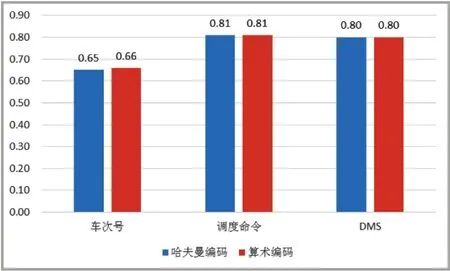
图3 采用外置字符概率表后的压缩比

U285.44∶TP39
A
1005-8451(2015)10-0051-03
2015-02-10
中国铁路总公司科技研究开发计划项目(2014X005-B)。
王开锋,助理研究员;蒋 韵,助理研究员。
