一种新的基于DBN的声学特征提取方法
2015-06-23杨俊安李晋徽
陈 雷,杨俊安,王 龙,李晋徽
(1.电子工程学院,安徽 合肥 230037;2.电子制约技术安徽省重点实验室,安徽 合肥 230037)
一种新的基于DBN的声学特征提取方法
陈 雷1,2,杨俊安1,2,王 龙1,2,李晋徽1,2
(1.电子工程学院,安徽 合肥 230037;2.电子制约技术安徽省重点实验室,安徽 合肥 230037)
大词汇量连续语音识别系统中,为了进一步增强网络的鲁棒性、提升深度置信网络的识别准确率,提出一种基于区分性和ODLR自适应瓶颈深度置信网络的特征提取方法。该方法首先使用鲁棒性较强的瓶颈深度置信网络进行初步特征提取,进而进行区分性训练,使网络的区分性更强、识别准确率更高,在此基础上引入说话人自适应技术对网络进行调整,提高模型的鲁棒性。利用提出的声学特征在多个噪声较强、主题风格较为随意的多个公共连续语音数据库上进行了测试,识别结果取得了22.2%的提升。实验结果表明所提出的特征提取方法有效性。
连续语音识别;瓶颈深度置信网络;区分性训练;ODLR
0 引言
语音识别技术是指机器通过识别和理解把人类的语音信号转变为相应的文本或命令的技术。
目前主流的语音识别系统主要由三部分组成,分别是:特征提取、声学模型以及解码。对于特征提取部分而言,它的主要功能是从输入的原始语音中提取出有利于后续识别的语音特征。本文主要针对上述语音识别系统存在的识别准确率偏低、复杂环境中鲁棒性的问题,重点从特征提取展开研究。但是目前基于BN+DBN的特征提取方法在识别准确率、鲁棒性上的表现仍不尽如人意。本文通过对现有BN+DBN网络的深入分析,找出现存特征提取方法存在的问题及其问题产生的原因,提出一种使用区分性和ODLR自适应的瓶颈深度置信网络进行特征提取的方法。
1 基于BN+DBN的特征提取方法
1.1 深度置信网络
与传统神经网络训练方法不同的是,DBN采用预训练与微调相结合的方式来训练神经网络,其中预训练过程使用了一种基于受限波尔兹曼机(Re-stricted Boltzmann Machine,RBM)[1]的非监督训练方法;微调阶段使用BP网络进行监督式的训练。通过非监督的训练将网络的权重调整到了合适的初始值,进而采用传统的BP算法对权重进行微调,便得到了一个DBN模型。
1.2 基于BN+DBN的特征提取方法
特征提取模块是连续语音识别系统的基本组成模块,对系统起着底层支撑的作用。
传统的特征提取方法都有着相应的问题,MFCC方法难以提取语音数据中深层次的特征,并且相对于噪声的鲁棒性不强。而运用SDC进行特征提取的过程中需要对倒谱参数个数、差分倒谱的帧间间隔、计算差分倒谱的相邻块的帧移以及差分到普块的个数进行调整,这种通过人工对参数进行调整的方式更多地依赖于研究人员的经验,而且操作流程较为复杂,需要大量的计算机资源和训练时间。
瓶颈(Bottle Neck,BN)的思想初次进入视野是在2007年,BN+ANN的特征提取方法在连续语音数据集中取得了较为理想的效果,DBN取代了ANN成为语音识别领域的主流方法之后,相关学者考虑BN+DBN的特征提取方法能否同样给DBN的性能带来相应的提升,最终提出了BN+DBN这一性能出色的神经网络模型。BN+DBN在训练的过程中通常将网络的结构设置为相对于中间层对称,将中间层命名为瓶颈层,瓶颈层所含节点数较少,随后丢弃中间层之后的网络结构,将瓶颈层作为网络的输出。尽管瓶颈层含有较少的神经元,但是通过选取合适的神经元数目,瓶颈层特征能够很好地对语音进行表征,同时由于较少的节点数去除了数据冗余,大大提升了识别速率。BN+DBN的特征提取方法在拥有DBN较强的表征能力、较强的鲁棒性的同时,由于瓶颈层的引入拥有着较高的识别速率[2]。
基于BN-DBN的特征提取兼顾了DBN和BN的出色性能,目前已经得到广泛应用,其在连续语音识别中的优越性主要体现在[3]:
①能够从不同的语音数据集中提取出具有代表性的特征,这些特征成为后续识别过程中的重要依据;
②DBN特有的非监督预训练使网络的传输权重调整到合适的初值,同时也使系统能够充分地利用未标注的数据进行训练,更全面有效地提取语音特征;
③DBN的微调优化部分利用标注数据对网络进行监督训练,对网络模型进行更加精细的调整,提取更有效的特征;
④BN+DBN在原有深度置信网络基础上进行降维处理,这种策略对于系统去冗余有着重大意义,提升了训练速度;
⑤相对于传统的特征提取方法,需要人工调整的参数较少,具有更加广泛的适应性。
2 基于区分性和ODLR自适应的深度置信网络
2.1 基于区分性深度置信网络的特征提取方法
区分性训练在语音识别系统中的应用已经有几十年的历史。随着相关算法的不断提出以及计算机性能的大幅提升,区分性训练不仅仅局限于小词汇量数据集,更是将应用的领域扩展到了大词汇量连续语音识别系统。区分性策略首先选取与模型分类特性紧密相关的目标函数,随后直接对目标函数进行优化来实现模型调整。这种训练方式不仅能够降低模型假设错误,而且更直接地关注系统的识别和优化效果,为构建更为有效的声学模型提供了有力的保证[4,5]。下面本文对DBN准则下的区分性训练理论进行重点介绍。
DBN区分性训练的代价函数和目标函数分别使用符号DSEQ和FMMIE表示,则有:

式中,R为训练样本句子数的总和,θ表示训练过程中的参数的集合,Or表示声学特征序列,Wr则表示词序列。Mr表示训练样本中竞争序列的集合,即混淆集,表示所有可能句子的近似集合。k为声学规整因子。
为了使DBN的输出对应于各个绑定状态的后验概率,首先要将各个状态的后验概率转换成似然值,使用如下公式进行:
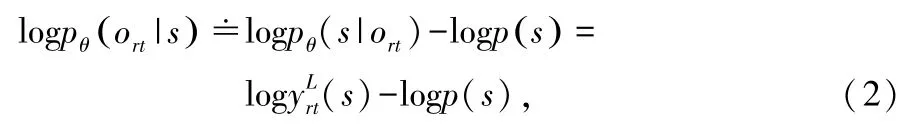
通过链式法则,结合:

进一步得到区分性准则下DBN输出层误差的分量:
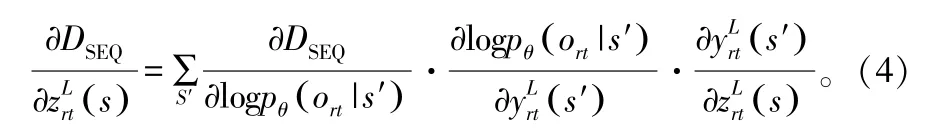
式中,等式右侧第一个表达式的求解可以使用传统GMM+HMM区分性训练中的导数求解方法。

等号右侧第2个表达式使用式得到:

第3个表达式使用如下公式求得:

δs,s′为克罗内克δ函数;s′=s时,δs,s′=1;其他情况下δs,s′=0。
综上,式子的最终形式为:

最终得到;

至此完成了DBN准则下的区分性训练,训练的流程与传统的GMM+HMM的声学模型基础上进行的区分性训练极为相似。主体思路为首先使用lattice得到分子和分母的状态占有率,随后使用上述公式进行计算,最后通过BP算法使误差在隐含层传播,使用SGD算法对DBN参数进行更新。在区分性训练的优化阶段,使用EBW优化算法进行,同时结合i-smoothing平滑技术增强区分性训练的扩展性。
区分性训练流程:
根据最大互信息的目标函数,本文可以分两步实现上述过程:第一步是增加分子项,实现与最大似然准则一样,都是要增加相关特征对模型的相似度;第二步是减少分母项,也就是要降低竞争句子的特征对模型的相似度。这也就是区分性训练准则与最大似然准则的差异之处,要设法降低竞争句子与正确句子的混淆度,以显示正确句子的区分度。
在算法实现上,较为经典的方法为扩展的Baum-Welch算法,具体实现步骤如下:
①瓶颈深度置信网络的训练;
②利用训练好的瓶颈深度置信模型进行标注的强制对齐,使用瓶颈特征的深度置信网络模型做强制切分,使得每一帧特征严格对应到模型的各个音素上;
①采用Filter Bank特征作为输入,使用瓶颈深度置信网络进行训练,分别产生正确句子与竞争句子的词图;
②忽略原来的声学得分,根据词图进行有限制的识别,识别后在词图上产生新的声学分数;
③利用扩展的Baum-Welch算法计算前向及后向概率,以此计算出的概率判断竞争句子与正确句子的混淆度;
④根据步骤③计算出反向概率,可知每个词段所必须做的反向训练程度,这便是正向与反向统计信息;
⑤根据统计信息对当前模型做参数更新求取新的模型。
2.2 ODLR自适应深度置信网络的特征提取方法
ODLR(Output-space Discrininative Linear Re-gression)是一种直接对DBN网络进行自适应的方法,其基本思想是针对每个具体的说话人,使用少量的数据对DBN网络的最后一个隐含层输出进行变换,具体原理如图1所示。[6-8]:
假设最后一个隐含层的输出特征变换为:

MLP的输出层的激活值表示为:

变换阵M的梯度表示为:

图1 ODLR自适应深度置信网络
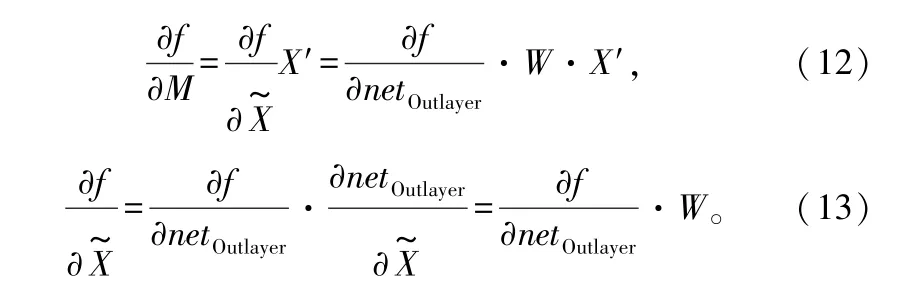
偏置B的梯度表示为:

3 公开数据库实验结果与分析
3.1 数据库
本文使用的数据集规模较大,信噪比普遍较低,背景噪声多样,使用该数据库对所提出的基于区分性和ODLR自适应BN+DBN的特征提取方法进行验证。

表1 数据库
3.2 实验结果及分析
实验一
实验一主要对区分性训练的基本理论进行验证,首先在BN+DBN基线系统上进行了区分性训练;随后在此基础上对VTLN[9]、网络结构调整和状态输出对系统性能带来的影响进行实验[10];最终将各个技术点与区分性训练相结合,测试总体性能实验结果如表2所示:

表2 区分性DBN实验结果
由上述结果,首先,在信噪比较高的数据集上学者已经证明了区分性训练的有效性,表2的实验结果说明在噪声水平较高的数据集上进行区分性训练同样能够增强网络的区分性,达到较为理想的效果。新特征提取方法方法使识别系统的识别准确率平均提升10.6%,说明在瓶颈深度置信网络上进行区分性训练能够达到预期效果。
其次,声道长度规整技术能够对模型产生积极的效果,识别准确率取得了一定提升,表明了VTLN技术从一定程度上滤除了说话人对识别造成的不利影响;第三组实验在第二组的基础上进行了网络状态调整和状态输出累积,识别准确率又取得了进一步的提升,证明了网络状态调整和状态输出能够有效地提升DBN网络的鲁棒性,更加精细的网络结构保证了识别性能的提升;最终第四组实验提升效果最为明显,表明了VTLN、网络结构调整和状态输出能够与区分性DBN完美地结合,这些技术的引入最终使区分性DBN的识别准确率取得了19.5%提升。
实验二
实验二中本文主要针对自适应技术进行实验,验证在瓶颈深度置信网络中引入自适应技术的可行性。
在区分性训练之后进行自适应的实验,进行了ODLR自适应的实验,在测试集上得到如表3结果。
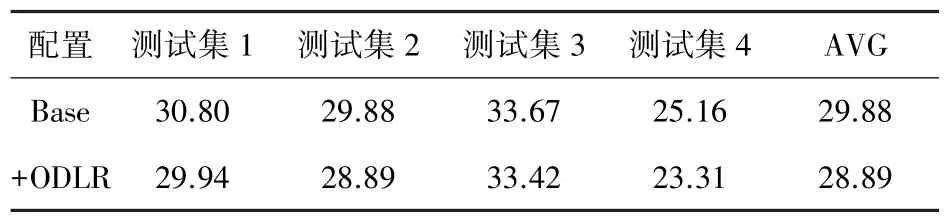
表3 区分性自适应DBN特征提取方法的实验结果
表3的结果表明,在区分性瓶颈深度置信网络的基础上进行说话人自适应又取得了3.3%的效果提升。新的特征提取方法总体取得了22.2%的识别准确率提升,性能提升效果较为明显。实验结果表明在基线系统下区分性训练和说话人自适应能够比较完美的共存。
由于要使用到切分、解词图等技术,本文所提出的特征提取方法需要多个程序分步运行,因此特征提取的时间难以准确测算。此外,虽然模型训练阶段耗时较长,但考虑到模型预先训练完成之后,识别时可直接使用,无需反复训练,引入区分性训练和说话人自适应对实际测试过程的耗时影响不大,所以这里没有对训练时长做定量分析。
4 结束语
针对现有BN+DBN特征提取方法存在的区分性不强和自适应能力较差的问题,将区分性训练和ODLR自适应技术与瓶颈深度置信网络相结合,提出了基于区分性和自适应瓶颈深度置信网络的特征提取方法,区分性训练的引入使BN+DBN网络更直接地强调模型的分类特性,为系统识别准确率的提升提供了依据;自适应技术有效地提升了系统的泛化能力,同时考虑区分性和自适应能否在BN+DBN模型上取得协同作用,在区分性训练的基础上进行了说话人自适应的训练,通过不同背景噪声,会话主题风格的数据库上进行的实验验证了新的特征提取方法的有效性。
[1]Mohamed A,Dahl G,Hinton G.Acoustic Modeling Using Deep Belief Networks[J].IEEE Transactions on Audio,Speech,and Language Processing,2012,20(1):14-22.
[2]Mohamed A,Sainath T,Dahl G,et al.Deep Belief Networks Using Discriminative Features for Phone Recog-nition[C]∥Proceedings of the IEEE International Con-ference on Acoustics,Speech,and Signal Processing. 2011,Prague,Cech Republic,2011:5060-5063.
[3]Sainath T,Kingsbury B,Ramabhadran B.Auto-Encoder Bottleneck Features using Deep Belief Networks[C]∥Proceedings of the IEEE International Conference on A-coustics,Speech,and Signal Processing,Kyoto,Japan. 2012:4153-4156.
[4]Valtchev V,Odell J J,Woodl P C.Lattice-Based Discrimi-native l Yaining for Large Vocabulary Speech Recognition[C]∥Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),1996(2):605-608.
[5]Kingsbury B.Lattice-based Optimization of Sequence Clas-sification Criteria for Neural-Network Acoustic Modeling[C]∥Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),2009:3761-3764.
[6]Hinton G,Srivastava N,Krizhevsky A,et al.Improving Neural Networks by Preventing Co-adaptation of Feature Detectors[C]∥CoRR,2012:1207-1210.
[7]Kuhn R,Junqua J C,Nguyen P,et al.Rapid Speaker Ad-aptation in Eigenvoice Space[J].IEEE Transactions on Speech and Audio Processing,2000,8(6):695-707.
[8]张志华.说话人自适应技术研究及其在电话信道下的关键词检出系统应用[D].郑州:解放军信息工程大学,2005:112-116.
[9]Siniscalchi S M,Dong Yu,Li Deng,et al.Speech Recogni-tion Using Long-Span Temporal Patterns in a Deep Network Mode[J].IEEE Signal Processing Letters,2013:20(3):201-204.
[10]BaoYebo,Jiang Hui,Liu Cong,et al.Investigation on Di-mensionality Reduction of Concatenated Features with Deep Neural Network for LVCSR Systems[C]∥Pro-ceedings of the IEEE 11th International Conference on Signal Processing(ICSP2012),Beijing,China,2012:562-566.
A New Feature Extraction Method Based on Bottleneck Deep Belief Network
CHEN Lei1,2,YANG Jun-an1,2,WANG Long1,2,LI Jin-hui1,2
(1.Electronic Engineering Institute,Hefei Anhui 230037,China;2.Key Laboratory of Electronic Restriction,Hefei Anhui 230037,China)
In order to further improve the robustness and recognition rate of deep belief network in Large Vocabulary Continuous Speech Recognition system,this paper presented a novel bottleneck deep belief network to extract new features,which was based on speaker adaptation and discriminative training.Firstly,a bottleneck deep belief network was adopted to get the feature.And discriminative training performed on this basis gave a more distinguished network to improve the recognition accuracy.Simultaneously,a more robust speaker adaptation method was introduced to adjust the network.The proposed method was tested on several public continuous speech databases with strong noise and casual themes and a relative 6.9%promotion of the recognition accuracy was obtained.The result proves the superiority of the proposed method compared to the conventional one.
Continuous Speech Recognition;Bottleneck Deep Belief Network;Discriminative Training;ODLR
TN912.34
A
1003-3114(2015)06-41-5
10.3969/j.issn.1003-3114.2015.06.11
陈 雷,杨俊安,王龙,等.一种新的基于DBN的声学特征提取方法[J].无线电通信技术,2015,41(6):41-45.
2015-07-13
国家自然科学基金项目(60872113)
陈 雷(1990―),男,硕士研究生,主要研究方向:语音识别。杨俊安(1965―)男,教授,博士生导师,主要研究方向:信号处理、智能计算等。
