QPSO-KM算法在葡萄酒品质分级中的应用
2015-06-20云南农业大学教务处云南昆明650201云南农业大学植物保护学院云南昆明650201云南农业大学基础与信息工程学院云南昆明650201
(1.云南农业大学教务处,云南昆明 650201;2.云南农业大学植物保护学院,云南昆明650201;3.云南农业大学基础与信息工程学院,云南昆明 650201)
邱 靖1,彭莞云2,吴瑞武3*,张海涛1
葡萄酒品质评定一般是通过有资质的评酒员进行品评后对酒的各项指标进行打分,对其求总分后以确定葡萄酒的质量。但葡萄酒的品质与酿酒葡萄和葡萄酒的理化指标及芳香物质都有密切的联系,因此构建一个有效实用的葡萄酒分级模型,使之更客观有效地对葡萄酒进行分级有重要意义。不少学者对此进行了研究,并取得了一定的研究成果,如神经网络[1]、K 均值[2]、Copula 函数[3]及最小二乘支持向量机[4]等。笔者利用QPSO优化KM算法建立分级模型,以期取得较好的分级效果。
1 算法分析
量子粒子群算法(QPSO)具有较强的全局搜索能力,能够在整个可行解空间搜寻最优解。KM算法是一种基于划分的算法,通过不断更新迭代聚类中心,从而找到较优的聚类结果。但QPSO算法与KM算法如何有效地结合,从而使聚类效果好,运行速度快,且不陷入局部最优解。在利用QPSO算法优化KM算法时,主要是找到一个有机的结合点,利用局部最优位置和全局最优位置更新K均值,当QPSO陷入局部最优时,引入KM算法提高收敛速度和全局搜索性能。适应度函数为:
式(1)中,n为酒样个数,xi为酒样,xi表示属于第j类酒,cij表示第i个粒子速度。具体算法如下:①初始化种群。种群初始化时,先选n个酒样做为聚类中心,计算各类聚类中心值,种群数N、最大迭代次数、初始化粒子速度,粒子群粒子的最好位置pi和全局最好位置pg。②根据迭代次数,调整收缩扩张系数。③根据适应度函数,计算每个粒子的适应度值,比较其适应度值与所经历的适应度值,判断是否更新粒子最优位置和粒子群最优位置。④根据QPSO进化方程调整粒子速度、局部和全体最优位置。⑤根据聚类中心计算每个酒样到中心的距离,并根据最小距离对酒样重新划分,将每个酒样划分到最近的类。⑥按照聚类原则重新划分新的聚类中心。⑦判断是否满足终止条件,聚类中心适应度更优,更新粒子并结束,否则转到步骤②。⑧输出全局最优聚类结果。
2 试验讨论
2.1 数据处理 2012高教社杯全国大学生数学建模竞赛A题中总计有红葡萄酒27个样品,白葡萄酒28个,以及评酒员的评分数据,各葡萄酒酒样的理化指标及芳香物质。
分析酿酒葡萄与葡萄酒的理化指标之间的联系,由于酿酒葡萄的理化指标较多,可以先利用统计分析中主成分分析将许多相关的随机变量压缩成少量的综合指标,同时又能反映原来较多指标的信息。按照主成分分析的理论,若前R个主成分的累计贡献率达到了85%原则,则这R个主成分能反映足够的信息。
由表1可知,反映葡萄酒质量的主要成分有17个指标,分别为总酚、单宁、花色苷、DPPH自由基、蛋白质、可溶性固形物、固酸比、VC含量、酒总黄酮、白藜芦醇、柠檬烯、3-甲基-1-丁醇、丁二酸二乙酯、乙酸乙酯、乙醇、3-甲基-1-丁醇-乙酸酯、苯甲醇。
2.2 组别差异性检验 由于2组评酒员对不同酒样的评价结果不同,因此该问题可以转化为多因素无重复方差分析。因子包含了组别、评酒员、酒样及评价结果,组别用1、2表示,评酒员用1、2、3、…、20表示,酒样红白葡萄酒统一标号,红葡萄酒用1~27表示,白葡萄酒用28~55表示。
利用spss19.0,对其进行无重复观测值无交互作用的方差分析,总计有4个变量,组别、评酒员、酒样及评价结果。分析结果如表2所示。
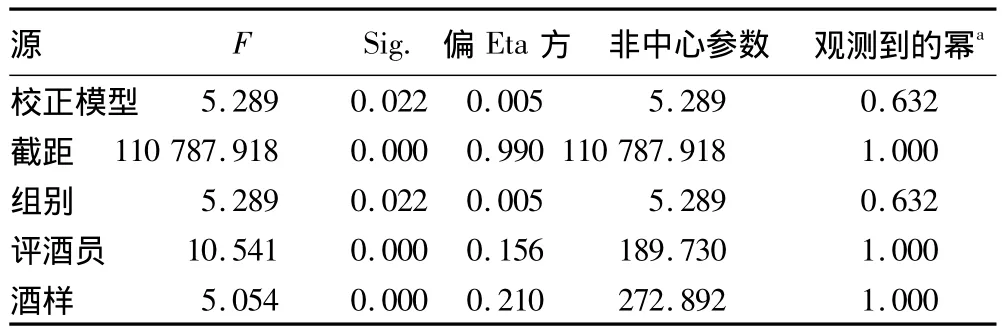
表2 组别评价结果分析
从表2 可知,组别间F=5.289,P=0.022 <0.05,表明两组评酒员的评价结果差异显著。
从表3可知,第2组的标准误差比第1组的小,所以第2组比第1组的评酒员更可信。

表3 组别的标准误差
评酒员评分可信度可以通过评酒员对酒样评分的方差评价,即计算每组中每个评酒员对每个评价指标相对该组评酒员对该指标的平均值偏差平方和。方差平方和越大也即越不稳定,其评价分数可信度低。总体样本方差定义如下:
式(2)中,S2为总体样本方差,i为酒样数,j为评酒员,k为酒样的10个评价指标,xijk为第j个评酒员对第i个酒样的第k个指标的评分为10个评酒员对第i个酒样的第k个指标的平均值。
利用各评酒员的评分数据,算出每组评酒员的总体偏差平方和,结果如表4所示。

表4 2组酒样评分总体样本方差比较
由表4可知,第2组评酒员的评分无论是红白葡萄酒为一整体还是红白葡萄酒各为一整体,其总体样本偏差平方和均小于第1组评酒员评分的总体样本偏差平方和,所以第2组评酒员的评分相对第1组评酒员的评分更稳定,因此,其分数更可信。
综合表3和表4的结果,说明人们在判定葡萄酒质量时,以第2组评酒员的评分结果判定其质量的好坏。
2.3 葡萄酒分级 根据利用的QPSO算法优化KM算法建立的葡萄酒分级模型,以及利用主成分分析法得到决定葡萄酒质量的理化指标和芳香物质,结合评酒员的评分结果,对红葡萄酒和白葡萄酒酒样进行分级试验。
红葡萄酒分级试验,种群个数为27,粒子长度为17(影响葡萄酒质量的理化指标和芳香物质),迭代次数为500,学习率为 C1=0.8,C2=1,权重系数 ω 从0.8 到0.3 线性减少,进行100次试验求平均值,算法比较如图1所示。
从图1可知,QPSO-K算法的适应度值明显比其他算法的适应度值小,且该算法的迭代次数明显比其他2种算法的多,说明该算法更能在全体解空间搜索全局最优解,不易陷入局部极值。利用该算法求葡萄酒分级结果如表5所示。

表5 葡萄酒分级结果
3 结论
该研究利用QPSO算法优化KM算法,建立了葡萄酒分类模型。从试验分析看,QPSO-K算法的适应度值明显比其他算法的适应度值小,解决了PSO算法易陷入局部极值的缺点,并得到了红葡萄酒和白葡萄酒较好的分级结果。说明该算法应用在葡萄酒分级问题上有效可行,是一种较优的聚类方法。
[1]曾祥燕,赵良忠,孙文兵,等.基于PCA和BP神经网络的葡萄酒品质预测模型[J].食品与机械,2014,30(1):40-44.
[2]凌佳,言方荣.K均值聚类在葡萄酒分级中的应用[J].食品工业科技,2013,34(6):104 -107.
[3]凌佳,言方荣.Copula函数在葡萄酒分级中的应用[J].酿酒科技,2013,226(4):57 -60.
[4]吴瑞红,王亚丽,张环冲,等.一种基于最小二乘支持向量机的葡萄酒品质评判模型[J].华侨大学学报:自然科学版,2013,34(1):30-35.
