基于Hive的海量Web日志分析系统设计研究
2015-06-19江三锋王元亮
江三锋 王元亮
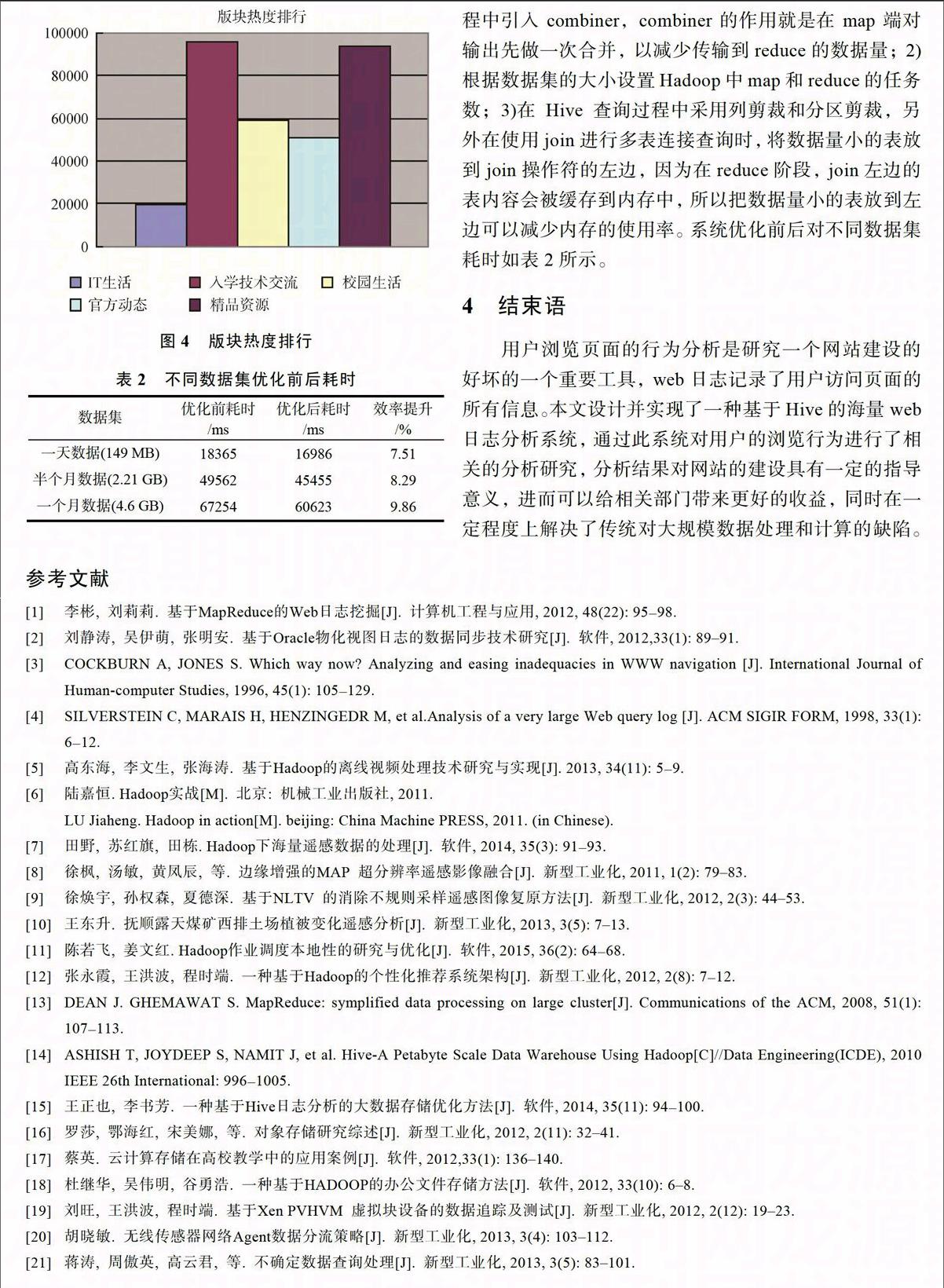


摘要:针对于传统对海量数据处理和计算的瓶颈,提出了一种基于Hive的海量web日志分析机制。通过Hadoop分布式系统架构以及Hive数据仓库对海量web日志做了分析处理,并对用户的浏览行为进行了分析研究。对用户浏览行为中的浏览量和跳出率、IP数、版块热度排行的分析结果对于网站建设和大数据分析系统优化都具有一定的指导意义。
关键词:Hive;Web日志;Hadoop;网站建设
中图分类号:TP391 文献标识码:A DOI:10.3969/j.issn.1003-6970.2015.04.021
0.引言
随着互联网技术的普及,网络上的信息量呈指数级增长。毋庸置疑,web已经是世界上最大的信息系统。作为这个系统中重要的组成部分之一,web日志记录了用户浏览网页的所有信息。通过处理和分析这些日志信息,我们可以了解到用户的行为特征,从而改造网页的布局,提高网站的流量,进而给企业带来更高的收益。
通过数据分析技术和数据挖掘技术,从web日志中获取用户的行为特征已经成为商业界关注的焦点。早在1996年,Cockburn,Jones等人就对网页用户浏览行为做了调研分析。20世纪90年代末,Sliverstein,Maraus等人对Web搜索引擎日志进行了大规模的分析。
然而,随着用户量的急剧增加,web日志记录的信息量也越来越庞大。传统方法在处理海量数据集的时候一般都是通过分治的思想或者采用多线程多任务的方法来处理。如果仅仅靠提升计算机的存储量以及性能显然不能从本质上解决这一问题。本文通过采用hadoop平台,设计并实现了基于Hive的海量web日志分析系统。
1.相关技术介绍
1.1Hadoop分布式系统
HadoopTM作为Apache软件基金会下的一个分布式开源框架,在众多的大型企业中得到了广泛的应用。分布式文件系统HDFS(Hadoop Distributed File System)和Map/Reduce并行编程模型是Hadoop的两大核心。Hadoop主要是通过HDFS来实现分布式存储的底层支持,并且通过Map/Reduce来实现分布式并行计算任务处理的程序支持。所以用户能够在不了解分布式底层细节的情况下开发分布式程序。endprint
