基于分类优化的物联网节点负载均衡策略
2015-06-13韩晓艳赵宏伟于繁华
赵 东,韩晓艳,赵宏伟,于繁华
(1.吉林大学 计算机科学与技术学院,长春130022;2.长春师范大学 计算机科学与技术学院,长春130032;3.吉林农业大学 信息技术学院,长春130118)
0 引 言
负载均衡算法优化技术相对来说已比较成熟。毛誉熹等[1]利用IA-DSR(基于干扰感知的负载均衡路由协议)改进了网络的整体吞吐量。郑相全[2]通过跨层优化路径的方法提高网络的吞吐量来优化负载节点。文献[3]利用于多信道技术改善无线网络的通信,以优化传输速率,提高网络负载。王敏等[4]采用最大路径的方法进行负载均衡处理,其方法的主要缺点是没有考虑所选信道的拥塞情况。其中文献[5-6]还提及利用无线传感器网络,在不考虑节点密度分布的情况下对节点进行处理,能够有效地改善其负载性能。文献[7]对异构无线网络节点性能与代价进行处理和评估,从而优化部署实施策略。朱永娇等[8]使用遗传聚类方法对路由算法进行改进,实现无线传感网负载均衡。
本文运用Hadoop 技术原理将Slave 节点的数据汇集成数据节点,根据其Slave 节点的数据特点进行分类处理,使特征相似的Slave 节点归为一类。同一类别Slave 节点,其处理能力及目前状态可能非常相近,类别的不同决定其处理能力及当前状态的显著不同,因此根据其类别特点按照其资源空闲状况进行有效排序,再通过Master节点进行协调和分配Slave 节点任务,进而达到节点优化和提高资源效率的目的。本文结合MapReduce 模型、动态多因素组合及KNN 分类方法对网络节点进行分类及资源配置,以实现优化网络负载均衡的目的。
1 K 近邻模型
KNN 最近邻模型[9]是一种比较传统的分类模型,具有稳定、成熟、思路简单、易实现、无需训练过程、适合稀疏事件分析处理的机器学习方法之一。KNN 分类模型的原理如下:对于某一给定的Slave 节点,在样本特征空间有K 个最相似的集合,而这K 个相似的集合大多属于同一类别,通过该算法对Slave 节点进行聚类。K 近邻算法在分类上有比较成熟的经验,同时也可以进行回归预测。其优点为:简单、适合多分类问题、应用范围广,因而对类域的交叉或重叠较多的聚类问题,K 近邻模型更为合适,同时由于其模型不需要预先构建,故此可以用SQL 语句实施,操作方便、快捷。同样,K 近邻模型由于其自身的特点,也具有一些不足之处,如:最近邻算法是懒惰的学习算法,其计算都是在线进行的,这无疑增大了算法的时间复杂度,并消耗大量的存储空间。当两类样本容量相差悬殊时,通过K 近邻模型预测可能会造成误判,从而降低其准确率。为了保证算法的准确性,实验时需要大量训练数据,由于训练数据增多,搜索空间加大,给搜索带来难度,同时也会消耗大量内存。距离权重的计算方法产生的函数难以确定,同时其结果与K 值数量存在紧密关系。KNN 方法基于这样的前提条件,即预测的样本与其邻居样本具有相似的属性值。
针对这种情况,我们可以通过筛选掉分类作用不大的样本或者采用重新抽样法使之按某一方向抽取样本。也可以根据与该样本的距离动态匹配权值。采用这种方式,对每一个待分类的样本都要进行权值计算,而这些工作都要推迟到分类阶段来完成,因此增加了算法的时间复杂度。还可以动态调整K 值,使其达到最优状态。由于KNN 算法需要进行点与点之间的距离计算。为了使算法更加清晰,我们假设x = (x1,x2,…,xn),y=(y1,y2,…,yn),n 为输入特征的维数,则两点之间距离系数dXY具有如下性质:

此外,由于对两点间距离运算方式的不同,动态因素的选择有如下情况:
(1)绝对距离(曼哈顿距离,absolute distance):

如构造一组数据:x=matrix(c(0,4,5,3,0,7,6,3),ncol=2)

其曼哈顿距离为:
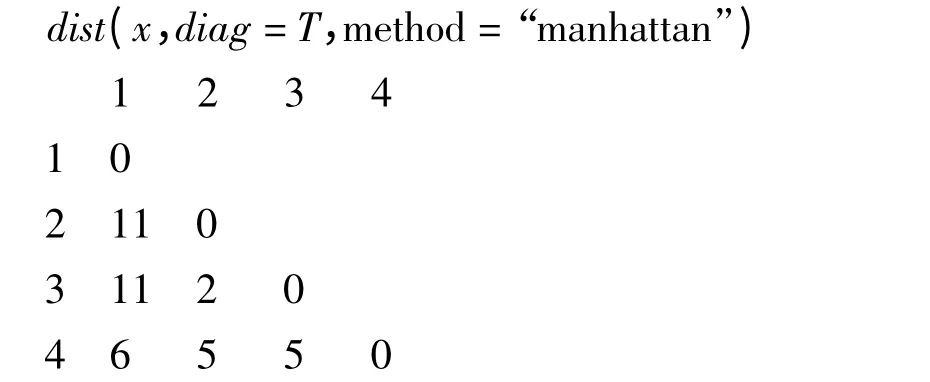
(2)欧氏距离(Euclidean distance):
上例数据的欧式距离为:
dist(x,method=“euclidean”,diag=T,upper=FALSE)
结果如下:

(3)明氏距离(Minkowski distance):

当r 比较小时,对比较小的差异较敏感,适合于相似度很大而差异较小的数据分类。
上例数据的明式距离为:dist(x,diag=T,method=“minkowski”,p=3)

(4)切比雪夫距离(Chebyshev Distance):
上例数据的切比雪夫距离为:

(5)Canberra 距离:
上例数据的Canberra 距离为:dist(x,diag=T,method=“canberra”)

(6)马氏距离(Mahalanobis Distance):

其中s 为样本协方差矩阵。
为了保证实验的准确性,在实验中采用马氏距离实验法进行实验。根据具体训练样本和新数据的属性特点进行分类,在K 个样本中找到属于某类最多的样本,并把这些样本归为此类。例如根据两个主要特征权重为24 个节点进行分类。
R 语言程序源码如下:

产生的图形如图1 所示。
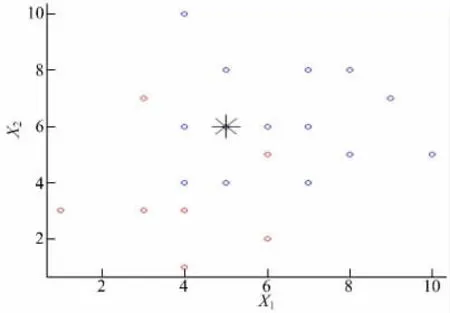
图1 两点关系图Fig.1 Two point diagram
图示结果显示通过KNN 预测,其类别为2。
2 算法设计与实现
节点分类流程如图2 所示。
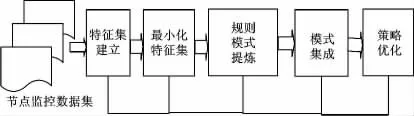
图2 节点分类流程图Fig.2 The flow chart of node classification
最小描述模型建立过程分为以下步骤:
(1)特征集的建立:将Slave 节点划分成数据属性,形成属性向量。
(2)最小化特征集:根据特征集中节点属性的特征向量运算,运用数据挖掘的聚类算法。
(3)对节点进行分类处理:对每一对数据(pa,pb),计算其属性相似度,然后取其中的最大值作为该最终相似度,将相似度大于某一阈值的所有节点分类到一起,形成小世界集合。
(4)规则模式提炼:根据文中定义的规则进行小世界集合提炼,从而得到对应的候选描述模式,并记录下模式出现的次数;选取其中模式出现次数大于某一阈值的模式加入到描述模式集合。为提高节点运行的效率,必须最小化模式,得到一最小的描述集合,作为节点的描述模式集合。
(5)模式集成:初始化模式集S,将候选模式集S'中当前模式PScurrent与模式集S 中的现有模式匹配,若匹配成功,定义其状态为1,否则为0。当状态为0 时,表示模式集S 中没有此模式,将当前模式PScurrent初始化为新的模式PSnew,加入到模式集S 中。若模式状态为1,则将模式进行归并处理。
(6)策略优化:根据上述模式,对特征数据进行有计划的分类处理,使机器任务由繁忙节点向空闲节点过渡。
(7)属性优化:由于在进行节点优化的过程中要考虑多种因素,而因素过多对分类会造成一定的影响。在实验过程中充分考虑到多因素的相互过程,以使节点分类结果达到最优。
3 实验仿真与分析
本文根据终端设备Slave 节点及网络的特点,对某公司大型数据处理系统进行监控,产生设备内存、空间、CPU 情况等状态数据。并根据状态数据的特点,对其进行标准化处理、字段删减、类型定义、分箱处理,在此基础上构建模型。最后将该模型运用到该数据集上,产生相关分类。其数据处理过程如图3 所示。
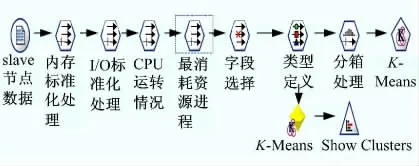
图3 数据处理过程Fig.3 Data processing
根据数据处理结果产生分类统计数据,如图4 所示。根据其数据特点不同该模式被分为十类。其中类一主要反映CPU、I/O、数据承载量等使用情况,类二反映内存和承载量情况。从图4中可以看出由于各机器设备运行的数据不同,其执行的内容也不尽相同。根据分类情况的描述,Master 能够较快调整各节点设备,使其能够进行均衡运转。
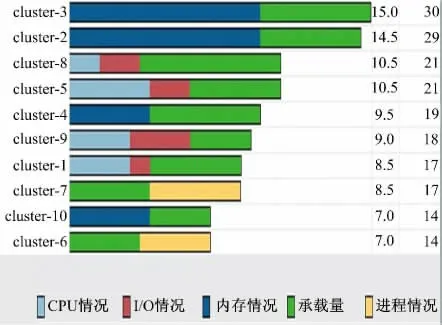
图4 分类统计数据结果Fig.4 Classification statistics results
为使研究具有实用意义,本文所采用的数据集为某集团公司办公网络,根据Map-Reduce 模型,将节点分成Master 和Slave 两部分,其中Master 节点主要负责监控及计算资源,Slave 负责节点运行。根据Slave 节点特点,将该数据集按照其网络使用程度分类为办公、研发、运维、软件、硬件、市场、工程、维护、管理、人事10 个类别,分为训练集和测试集两部分。其中,办公为25 台,研发为85 台,运维为44 台,软件为21 台,硬件为43 台,市场为49 台,工程为150 台,维护为28 台,管理为22 台,人事为20 台,总计为487 台。为使算法具有简捷性,本文从以上10 类数据中选取5类进行归类分析,即研发、运维、硬件、工程、管理。采用决策树分类算法、贝叶斯分类算法、神经网分类算法、SVM 分类算法与KNN 算法进行有效比较,通过对比实验对各类算法进行优化性对比。上述方法构造的分类器均在SPSS CLEMENTINE环境下开发。根据各机器设备属性信息,结合分类算法可以构造如表1 所示预测矩阵。

表1 算法预测表Table 1 Algorithm predicting table
在表1 中,1 代表研发,2 代表运维,3 代表硬件,4 代表工程,5 代表管理。
由于考虑到各因素的作用可能影响到机器节点的分类,因此需要对各因素相互作用进行分析,其分析结果如表2 所示。
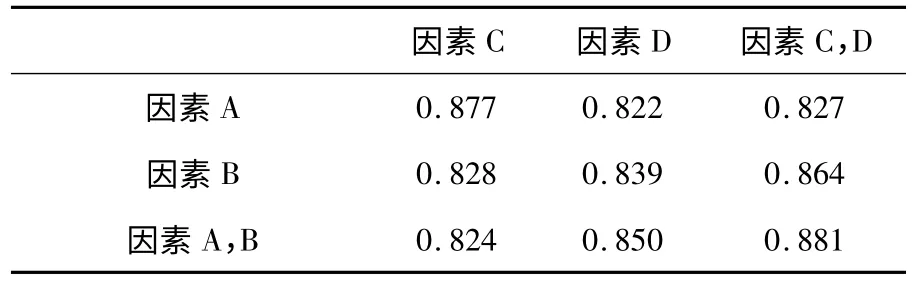
表2 多因素综合测试表Table 2 Multi-factor comprehensive test table
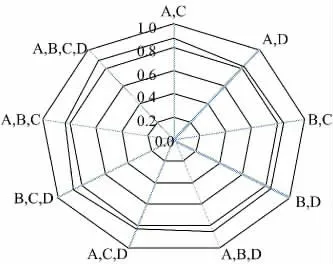
图5 多模型组合准确率Fig.5 The combined model accuracy
图5 为多模型组合准确率,其中因素A 代表CPU 使用情况、因素B 代表内存使用情况、因素C代表进程使用情况、因素D 代表I/O 状况。
为了客观评价此分类系统的性能,实验时需要对评价指标进行评定,其中最常用的是准确率和召回率的方法统计。对每个分类的准确率precision、召回率recall 以及F1 的计算方式分别如公式(7)(8)(9)所示。

表3 的数据信息表明,通过KNN 分析方法构造的分类器准确率及召回率优于决策树分类器、贝叶斯分类器、神经网分类器及SVM 分类器。

表3 各算法评估表Table 3 The algorithm evaluation table
4 结束语
本文使用KNN 算法对Slave 节点进行分类处理,根据其分类结果,与其他方法相比能最先识别出资源空闲较大的一类机器,并根据这类机器的运行状况,对Slave 节点进行有效调控,进而优化资源负载均衡,最终提高机器设备的最大可用率。实践证明,运用KNN 算法结合多因素有机组合能有效地对各服务器节点进行分类,其效果要优于其他算法。
[1]毛誉熹,卢汉成,卢昊.WMN 中一种基于干扰感知的负载均衡路由协议[J].通信技术,2014(04):401-405.Mao Yu-xi,Lu Han-cheng,Lu Hao.An interfere-nce-aware load balancing routing protocol for wireless Mesh networks[J].Communications Technology,2014(04):401-405.
[2]郑相全.一种基于跨层设计和蚁群优化的自组网负载均衡路由协议[J].电子学报,2006,34(7):1199-1208.Zheng Xiang-quan.A cross-layer design and a-nt-colony optimization based load-balancing routing protocol for Ad Hoc networks(CALR-A)[J].Acta Electronica Sinica,2006,34(7):1199-1208.
[3]Lin Kai,Rodrigues,Joel J P C,et al.Energy efficiency QoS assurance routing in wireless multimedia sensor networks[J].Systems Journal,IEEE,2011,5(4):495-505.
[4]王敏,李士宁,李志刚.基于蚁群算法的WSN 多路径负载均衡路由[J].计算机工程,2011,14:1-4.Wang Min,Li Shi-ning,Li Zhi-gang.Multipath R-outing with load balancing based on ant col-ony algorithm in WSN[J].Computer Enginee-ring,2011,14:1-4.
[5]尹安,汪秉文,胡晓娅,等.无线传感器网络负载均衡路由协议[J].华中科技大学学报:自然科学版,2010,38(1):88-91.Yin An,Wang Bing-wen,Hu Xiao-ya,et al.Load balancing routing protocol in wireless sensor network[J].Journal of Huazhong University of Science and Technology(Natural Science Edition),2010,38(1):88-91.
[6]Wu Dan,Cai Yue-ming.A cooperative commu-nication scheme based on dynamic coalition formation game in clustered wireless sensor net-works[J].IEEE Conference on Global Telecommunications(GLOBECOM 2011),2011:1-6.
[7]阮杨杨,徐恪.异构无线网络节点性能与代价优化部署策略[J].中国科技论文,2012,7(7):518-522.Ruan Yang-yang,Xu Ke.Station and relay node deployment strategy for optimizing performance and costs in heterogeneous wireless networks[J].China Sciencepaper,2012,7(7):518-522.
[8]朱永娇,阎巍,左伟明.基于遗传聚类的无线传感器负载均衡路由算法[J].电子设计工程,2011,19(11):4-7.Zhu Yong-jiao,Yan Wei,Zuo Wei-ming.A load balanced wireless sensor network routing algorithm based on genetic clustering algorithm[J].Electronic Design Engineering,2011,19(11):4-7.
[9]Giuseppe A,Falchi F.KNN based image classification relying on local feature similarity[J].SISAP,2010:101-108.
