开源网络爬虫在垂直搜索引擎应用
2015-05-30刘伟光
[摘 要]分析了聚焦爬虫的工作原理和关键技术,对几种开源网络爬虫的功能特点和使用范围进行比较,而后通过改造Heritrix软件的关键模块和功能接口,以抓取中国西藏网新闻为例,实现了开源爬虫软件在垂直搜索的应用。
[关键词]垂直搜索;聚焦爬虫;Heritrix
[中图分类号]TP393 [文献标志码] A
Application of the Open-Source Web Crawler on Vertical Search Engine
Liu Weiguang
(1.Library of Xizang Minzu University , Xianyang Shanxi 712082,China)
Abstract: The thesis analyzes the working principle and key technology for focused crawler, and compares the characteristics function and use range for several kinds of open-source web crawler. After that, through modifying heritrix software module and function interface, the open-source web crawler has been applied in vertical search engine to test Chinese Tibet news Web as an example .
Key words: Vertical Search Engine; Focused Crawler; Heritrix
0 引 言
在信息化时代,针对通用搜索引擎信息量大、查询准度和深度兼差等缺点,垂直搜索引擎已进入了用户认可和使用周期。垂直搜索是针对某一个行业的专业搜索引擎,是对网页库中的某类专门的信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户[1]。相比通用搜索引擎则显得更加专注、具体和深入。目前,垂直搜索引擎多用于行业信息获取和特色语料库建设等方面,且已卓见现实深远成效。
网络爬虫是一个自动提取和自动下载网页的程序,可为搜索引擎从互联网上下载网页,并根据既定的抓取目标,有选择地访问互联网上的网页与相关的链接,获取所需要的信息。按照功能用途,网络爬虫分为通用爬虫和聚焦爬虫,这是搜索引擎一个核心组成部分。
1聚焦爬虫的工作原理及关键技术分析
1.1聚焦爬虫的工作原理
聚焦爬虫是专门为查询某一主题而设计的网页采集工具,并不追求大范围覆盖,而是将目标预定为抓取与某一特定主题内容相关的网页,如此即为面向主题的用户查询准备数据资源。垂直搜索引擎可利用其实现对网页主题信息的挖掘以及发现,聚焦爬虫的工作原理是:
(1)爬虫从一个或若干起始网页 URL 链接开始工作;
(2)通过特定的主题相关性算法判断并过滤掉与主题无关的链接;
(3)将有用链接加入待抓取的URL队列;
(4)根据一定的搜索策略从待抓取 URL 队列中选择下一步要抓取的网页 URL;
重复以上步骤,直至满足退出条件时停止[2]。
1.2聚焦爬虫的几个关键技术
根据聚焦爬虫的工作原理,在设计聚焦爬虫时,需要考虑问题可做如下论述。
1.2.1 待抓取网站目标的定义与描述的问题
开发聚焦爬虫时,应考虑对于抓取目标的定义与描述,究竟是带有目标网页特征的网页级信息,还是针对目标网页上的结构化数据。前者因其具有结构化的数据信息特征,在爬虫抓取信息后,还需从结构化的网页中抽取相关信息;而对于后者,爬虫则直接解析Web 页面,提取并加工相关的结构化数据信息,该类爬虫便于定制自适应于特定网页模板的结果网站。
1.2.2 爬虫的URL搜索策略问题
开发聚焦爬虫时,常见的URL搜索策略主要包括深度优先搜索策略、广度优先搜索策略、最佳优先搜索策略等[3]。在此给出对应策略的规则分析如下。
(1) 深度优先搜索策略
该搜索策略采用了后进先出的队列方式,从起始 URL 出发,不停搜索网页的下一级页面直至最后无 URL 链接的网页页面结束;爬虫再回到起始 URL地址,继续探寻 URL的其它URL 链接,直到不再有 URL 可搜索为止,当所有页面都结束时,URL列表即按照倒叙的方式将搜索的URL队列送入爬虫待抓取队列。
(2) 广度优先搜索策略
该搜索策略采用了先进先出的队列方式,从起始 URL 出发,在搜索了初始web的所有URL 链接后,再继续搜索下一层 URL 链接,直至所有URL搜索完毕。URL列表将按照其进入队列的顺序送入爬虫待抓取队列。
(3) 最佳优先搜索策略
该搜索策略采用了一种局部优先搜索算法,从起始 URL 出发,按照一定的分析算法,对页面候选的URL进行预测,预测目标网页的相似度或主题相关性,当相关性达到一定的阈值后,URL列表则按照相关数值高低顺序送入爬虫待抓取队列。
1.2.3 爬虫对网页页面的分析和主题相关性判断算法
聚焦爬虫在对网页Web的URL进行扩展时,还需要对网页内容进行分析和信息的提取,用以确定该获取URL页面是否与采集的主题相关。目前常用的网页的分析算法包括:基于网络拓扑、基于网页内容和基于领域概念的分析算法[4]。下面给出这三类算法的原理实现。
(1)基于网络拓扑关系的分析算法
基于网络拓扑关系的分析算法就是可以通过已知的网页页面或数据,对与其有直接或间接链接关系的对象作出评价的实现过程。该算法又分为网页粒度、网站粒度和网页块粒度三种。著名的PageRank和HITS算法就是基于网络拓扑关系的典型代表。
(2)基于网页内容的分析算法
基于网页内容的分析算法指的是利用网页内容(文本、数据等资源)特征进行的网页评价。该方法已从最初的文本检索方法,向网页数据抽取、数据挖掘和自然语言等多领域方向发展。
(3)基于领域概念的分析算法
基于领域概念的分析算法则是将领域本体分解为由不同的概念、实体及其之间的关系,包括与之对应的词汇项组成。网页中的关键词在通过与领域本体对应的词典分别转换之后,将进行计数和加权,由此得出与所选领域的相关度。
2几种开源网络爬虫性能比较
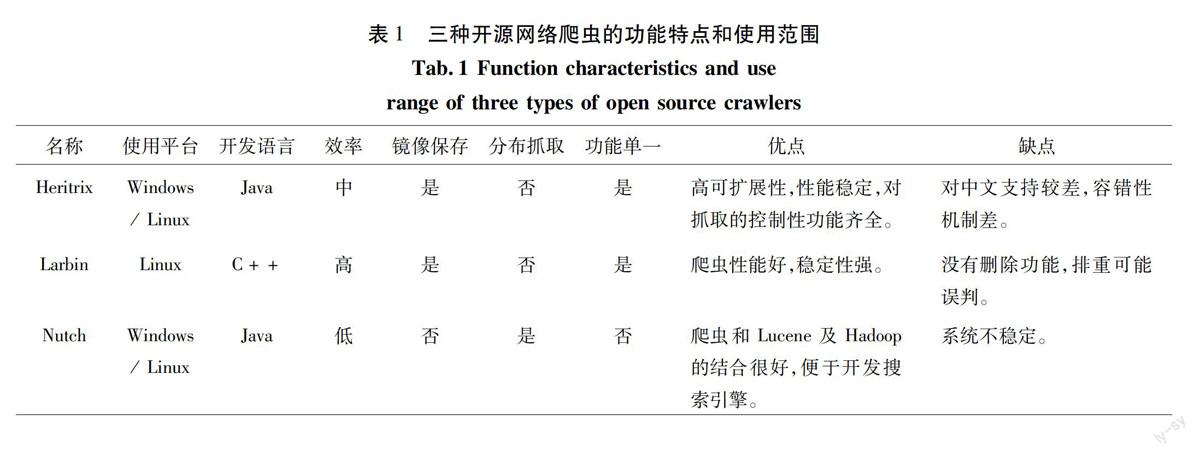
目前,互联网上推出有许多的开源网络爬虫,易于开发和扩展的主要包括Nutch、Larbin、Heritrix等,下面即针对这三类爬虫进行实用性内容介绍[5]:
(1)Heritrix 是Java 开发的开源 Web 爬虫系统,是Internet Archive 的一个爬虫项目。这是开源、可扩展、Web范围内并带有存档性质的网络爬虫。该系统允许用户选择扩展各个组件,进而实现自定的抓取逻辑。Heritrix默认提供的组件能够完成通用爬虫的功能,用户即可根据实际需求定制相应模块,也可实现聚焦爬虫的功能。
(2)Larbin是一种由C++开发的开源网络爬虫,larbin能够跟踪页面的URL进行扩展的抓取,从而为搜索引擎提供广泛的数据来源。该程序由法国人 Sébastien Ailleret独立开发,只是2003年后,Labin已退出了更新。
(3)Nutch是Apache的子项目之一,且是Lucene下的子项目,重点是其中自己提供了搜索引擎所需的全部工具,当然,Nutch只获取并保存可索引的内容,却无法保持抓取网页原貌。
在此,研究可得三种开源网络爬虫的功能特点和使用范围比较,具体如表1所示。
表1 三种开源爬虫功能特点的和使用范围
Tab.1 Function characteristics and use range of three types of open source crawlers
名称 使用平台 开发语言 效率 镜像
保存 分布抓取 功能
单一 优点 缺点
Heritrix Windows/ Linux Java 中 是 否 是 高可扩展性,性能稳定,对抓取的控制性功能齐全。 对中文支持较差,容错性机制差。
Larbin Linux C++ 高 是 否 是 爬虫性能好,稳定性强。 没有删除功能,排重可能误判。
Nutch Windows/ Linux Java 低 否 是 否 爬虫和Lucene及Hadoop的结合很好,便于开发搜索引擎。 系统不稳定。
通过如上内容分析,可以得出以下结论:
(1)从功能方面来说,Heritrix与Larbin的功能类似,都是一个纯粹的网络爬虫,提供网站的镜像下载。Nutch则是一个网络搜索引擎框架,爬取网页只是其功能的一部分。
(2)从分布式处理来说,Nutch支持分布式处理,而其它两个尚不支持。
(3)从爬取的网页存储方式来说,Heritrix和 Larbin都是将爬取所获内容保存为原始类型的内容。而Nutch是将内容保存到其特定格式中去。
(4)对于爬取所获内容的处理来说,Heritrix和 Larbin都是将爬取后的结果内容不经处理直接保存为原始内容。而Nutch却将对文本进行包括链接分析、正文提取、建立索引等深层处理。
(5)从爬取的效率来说,Larbin效率较高,因为其实现语言是c++并且功能相对单一,但是该程序缺乏必要的更新服务。
在进行了有关软件的扩展性、镜像保存方式及软件更新等方面因素的综合分析比对后,本文将择取并利用Heritrix开源软件来实现聚焦爬虫的设计。
3 基于Heritrix软件聚焦爬虫的设计
在利用开源Heritrix软件进行聚焦爬虫设计时, 以中国西藏网http://tb.tibet.cn/为例,针对有目标网页特征的网页级信息配置正则表达式,采用深度优先搜索策略进行URL扩展,利用网页内容关于“主题相关度”[6]的分析算法进行主题判断,实现聚焦爬虫的网站采集功能。
3.1开源Heritrix软件工作原理
Heritrix开源软件采集网页的方法是采取深度优先搜索策略,遍历网站的每一个URI,分析并生成本地文件及相应的日志信息等,Heritrix软件抓取的是与原网页一致的、完整的深度复制,包括图像以及其他非文本内容,抓取后并存储相关的内容。在网页采集过程中,Heritrix软件不对页面上内容进行修改,爬行相同的URL不进行替换。Heritrix软件通过Web用户界面启动、监控、调整、允许弹性地定义要获取的URL。Heritrix软件包含核心模块和插件模块。核心模块能够配置但不能覆盖,插入模块配置是否加载,也可以由第三方模块取代。
3.2 开源Heritrix 软件关键模块的改进
3.2.1 修改Extractor解析器
修改Heritrix的Extractor解析器时,可采用正则表达式的方式扩展待抓取的网页。例如,在抓取中国西藏网的新闻时,在Extractor解析器配置正则表达式:http://tb.tibet.cn/[0-9a-z]*/[a-z/]*/[0-9]*/[0-9a-z-]*.htm(|l)$,这样就把服务器域名下的网页所有信息全部抓取下来。但是,考虑垂直搜索引擎的使用范围和聚焦爬虫对网页主题的过滤功能,需要设计与实际主题搜索应用相匹配的专用解析器,专用解析器extract(CrawlURL)要实现以下功能:
(1)对所有不含有要抓取的结构化信息页面的 URL、又不含有可以集中提取前者 URL 的种子型 URL,都不作处理。
(2)从可以集中提取含结构化信息页面 URL 的种子型 URL(如地方新闻目录 URL),提取全部的含结构化信息页面的 URL(如地方信息列表 URL)。
(3)从含结构化信息页面的 URL 提取所需的结构化信息,并加以记录。
3.2.2 扩展 Frontierscheduler模块
FrontierScheduler 是一个 PostProcessor,其作用是将 Extractor所分析得出的链接加入到 Frontier 中,以待继续处理,聚焦爬虫实现关键词对主题的判断算法就在该模块中构建并执行。主题相关度判断的关键代码如下:
public void GetCount(String path,CandidateURI caUri)
{//判断待抓取网页与主题是否相关
try {
String s=sb.getStrings();//s 取网页正文字符
Len=length(s);//求网页字符数
float d=0;//初始化 d,用于计算所有导向词的权重和
for(int i=0;i<100;i++)//遍历选取 100 个导向词
{count=0,int j=1;//count为导向词出现次数,j 为导向词在字符串的位置
t= length(a[i]);//求第 i 个导向词的字符个数
While(j<=len){
int index=s.indexOf(a[i],j,len);//查找字串在 j+1 到 end 之间第一个字符首次出现的位置
if(index!=-1)//找到后,继续在余下的字符串中找
{count++;
j=index+t+1;}
Else
Break;
}
D(i)=count*b(i);//D(i)是第 i 个导向词的权重,b(i)表示 i 个导向词的权值。
d=d+ D(i);//将所有导向词的权重求和
}
k=1/len * 1/100 * d;//k 是网页主题相关度,len是文章字符数,100个导向词
if(k>0.6) ; //相关度判断
{System.out.println("count:"+count);//表示输出
getController().getFrontier().schedule(caUri); //当前 url 加入 heritix 采集队列 }
}
3.3 Heritrix聚焦爬虫接口的设计
Heritrix 网络爬虫是一个通用的网页采集工具,需要对Heritrix 抓取和分析网页的行为进行一定的控制,修改Extractor和 Frontierscheduler模块后,需要对其各个功能接口进行操作调试,由此保证聚焦爬虫功能的全面实现。下面即对重要功能接口进行必要介绍。
(1)应用接口
在设计聚焦爬虫时,应定制一个应用接口模块以供用户使用,具体将负责与Heritrix 软件关联,以提供启、停爬虫、获取网址、采集关键词等功能实现。
(2)数据库查询和修改接口
在设计聚焦爬虫时,应设计相应的数据库接口,负责下载并发现与主题相关的网页信息、再保存到数据库的表中。存储的字段包括:网页URL,本地存储相对路径,下载时间,HTTP头中抽取的网页编码,关键词id等。
(3)去重接口
因为Heritrix对相同的URL不进行替换,爬虫工作时会下载大量重复的网页,为了节省空间、并获取准确的采集结果,就必须按照设定规则对重复下载的网页进行删除。
4 结束语
通过以上对开源Heritrix软件的改进,聚焦爬虫已能根据预设的关键词进行网站抓取,并按照算法判断,当网页的主题相关度阈值大于0.6时,即聚焦爬虫下载网页,至此爬虫实现了指定网站的主题搜索。综上可见,可以改进开源网络爬虫并使其在垂直搜索引擎中获得成功立项使用。
参考文献:
[1]刘运强. 垂直搜索引擎的研究与设计[J]. 计算机应用与软件,2010, 127(7): 130-132.
[2]刘伟光. 一种基于改进向量空间模型的藏文主题网页采集方法[J]. 图书馆学研究,2014, 16:55-62.
[3]陈欢. 面向垂直搜索引擎的聚焦网络爬虫关键技术研究与实现[D]. 华中师范大学, 2014.
[4] 焦赛美. 网络爬虫技术的研究[J]. 琼州学院学报, 2010, 18(5): 28-30.
[5] 网络爬虫浅析[EB/OL]. [2011-03-05].http://xiangxingchina.iteye.com/blog/941349.
[6] 罗刚,王振东.自己手动写网络爬虫[M].北京:清华大学出版社,2010:34-36.
