基于概念聚类的Web数据挖掘搜索引擎的设计与实现
2015-05-30刘典型等
刘典型等

摘 要:针对Web数据挖掘的搜索过程,其准确度很大程度取决于用户输入的关键词的数量,以及搜索引擎对关键词的语义的解析与用户原意的吻合度,而搜索引擎对关键词的解析,包括基于链接的聚类方法和基于概念的聚类方法。本文克服基于链接的聚类方法的缺陷,采用基于概念聚类的方法,从二分图的概念和存储方法入手,设计和实现了个性化的Web数据挖掘搜索引擎,并验证了其优越性。
关键词:二分图;邻接矩阵;聚类;数据挖掘;搜索引擎
中图分类号:TP311.1 文献标识码:A
1 引言(Introduction)
众所周知,关键词数量越多,单个词越能清晰表达查询需求,搜索引擎就越能准确计算网页相关度,用户就越能准确得到所希望的查询结果。然而绝大多数用户在使用搜索引擎时,输入的关键词都少于三个,且很多情况下,关键词不能正确表达用户的查询需求,使得查询结果不尽如人意。本文采用概念聚类的方法,设计个性化搜索引擎,针对Web数据挖掘,能很大程度地提高搜索的准确率。
聚类就是将一个对象的集合通过某种算法分成几个类,分类后不同的类中的对象是不相似的,同一个类中的对象是相似的[1]。查询聚类是为了将相似需求的查询表达式聚为一类,从中选取关键词个数较多的作为这一类需求的表达,这样对查询表达式进行扩充,从而提高搜索的准确率[2]。
2 二分图及其存储(Bipartite graph and its storage)
设计中,联合考虑关键词和对应文本,即根据关键词所形成的词簇信息对文本进行聚类,聚类过程的数据结构定义如下:
定义1:设G=
对G采用实现存储,设eij为边[i,j]的权值,则记
(1)
为G的邻接矩阵。
3 聚类算法(Clustering algorithm)
使用中的很多搜索引擎在计算查询关键词与网页的相关度时,是根据网页内包含关键词的个数来定的,由于用户输入的关键词比较短,且一般不超过三个,加上有的关键词有歧义,而且由于网页内容的多样性,导致查询到的网页与用户的需求存在较大的差距。除了可以采用锚文本来对网页内容进行补充和描述的方法来提高查询准确率外,另一种有效的方法就是利用用户的点击率作为网页内容的补充了。从搜索引擎的日志中获取的用户点击数据可以在一定程度上反应关键词与页面之间联系,可以作为相关度计算的加权参数。
基于二分图的聚类算法有两种:基于超链接的聚类算法和基于概念的聚类算法。基于超链接的算法中,每当用户点击一个链接,就认为该链接和关键词是相关的,认为只要两个不同的关键词有相同的链接就将两个关键词聚类在一起,这样,由于关键词的语义多样性,很可能将语义不同的关键词进行聚类,加上Internet上很少有相同的链接,两个随机关键词被用户选择相同链接的概率仅为6.38*10-5,所以基于超链接的算法存在很大的缺陷[3]。
选择采用基于概念的聚类算法,对于设计一个高准确率的Web数据挖掘的个性化的搜索引擎系统,能达到更好的效果。构造概念聚类的二分图模型如下:
把所有的查询构造成顶点向量集合Q,关键词涉及的概念构造成顶点向量集合C,关键词与概念之间的关系构造成边集,即可得到概念聚类的二分图模型如图1所示。
例如当关键词为apple ipad、apple、apple iphone时,涉及的概念则包括ipad、fruit、iphone、product,构造的概念二分图如图2所示。
conceptual clustering
根据二分图,如果关键词涉及的概念相互重叠得越多,则关键词的相似度越高。设N(x)是节点x的邻节点的集合,N(y)是节点y的邻节点的集合,关键词的相似度按如下公式计算:
(2)
由式(2)可以看出,两个关键词涉及的概念集的交集越大,则查询的相似度越高。下面是构造二分图算法的伪代码:
4 系统模块设计(The system module design)
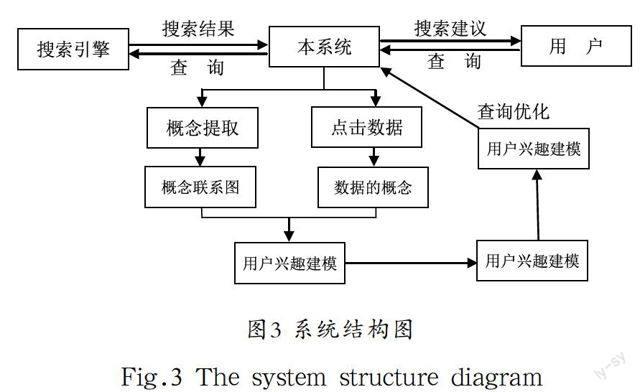
本系统的设计目的,是设计和实现一个为用户提供使用搜索引擎的平台,为用户提供搜索界面,并将用户输入的关键词提交给搜索引擎,再将搜索引擎的搜索结果反馈给用户。整个交互过程的数据比如查询关键词、搜索结果、用户点击的链接等数据都由该中间件收集起来并存储,为下一步的用户建模、查询聚类做准备[4]。
系统由四个主要模块组成:数据收集模块、数据库及管理模块、用户兴趣模块和查询聚类模块。系统流程分五步:数据收集、概念提取、用户建模、查询概念聚类、查询优化。系统各个模块的划分和模块之间数据传递方向如图3所示。
5 结论(Conclusion)
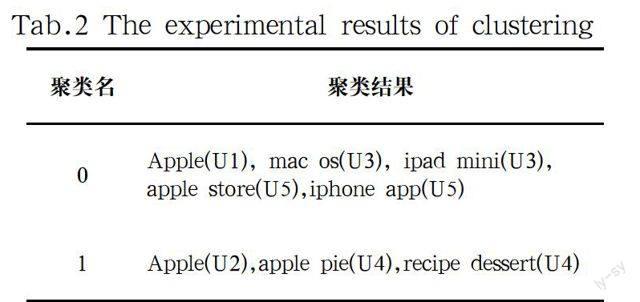
模拟五个用户,分别按表1输入查询关键词。其中第一二用户输入的关键词相同,但第一用户的兴趣点是apple数码产品,而第二用户的兴趣点是apple水果。
实验聚类结果如表2。结果表明,第一二用户虽然查询关键词相同,但由于兴趣点不同而被分到不同的类型中。类型0中的查询结果都与数码产品相关,而类型1中的结果都与水果相关,说明聚类结果能较好地按概念区分关键词。
实验表明,当聚类参数为0时,概念聚类的二分图中,低相关度的关键词被聚到一类,导致查准率比链接聚类查准率低;而当聚类参数较大时,概念聚类的查准率明显高于链接聚类的查准率,平衡保持在较高的范围内。
参考文献(References)
[1] 吴湖,等.两阶段联合聚类协同过滤算法[J].软件学报,2010,
21(5):1042-1054.
[2] 马恩穹.基于Web数据挖掘的个性化搜索引擎研究[D].南京
理工大学,2012.
[3] Guandong Xu,Yanchun Zhang,LinLi.Web Content Mining[J].
Web Information Systems Engineering and Internet
Teehnologies,2011,6(2):65-69.
[4] 王和勇,等.基于聚类和改进距离的LLE方法在数据降维中的
应用[J].计算机研究与发展,2006,43(8):1485-1490.
作者简介:
刘典型(1973-),男,硕士,副教授.研究领域:软件,网络
技术.
刘完芳(1972-),男,硕士,副教授.研究领域:数据库.
钟 钢(1975-),男,本科,高级实验师.研究领域:软件
开发.
