基于MapReduce的大数据时代数据处理技术研究
2015-05-29杜艳绥
杜艳绥
摘要:最近几年,随着互联网技术和云计算技术的极大普及和广泛应用,网络中的数据正在以前所未有的迅猛速度增长和积累,根据Facebook的统计,每天将近产生500TB的数据,可见大数据时代已经开始走入了我们的生活之中,那么如何能够更好的对这些隐藏的数据进行分析和挖掘有价值的数据便显得尤为重要,在这样的大数据环境之下,传统的数据库很难解决和处理如此庞大的数据,因此,基于MapReduce的数据处理方式变成为主流技术致意。大数据时代的到来,让我们感受着信息的便捷、获取着巨大的利益,同时,也为我们带来了从未有过的挑战。
关键词:MapReduce;Hadoo;大数据时代;数据挖掘
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2015)10-0001-02
自从2004年Google提出了MapReduce的这种并行编程环境以来,这种基于MapReduce的算法便在日益倍受关注的大数据领域得到广泛应用。诸如雅虎中国(Yahoo)、脸谱(Facebook)、亚马迅(Amazon)等知名大型的互联网公司也都纷纷的应用MapReduce来处理大数据的相关问题。与此同时,学术界等科研部门也开始对MapReduce的相关算法进行研究,极其有效的推动了MapReduce的相关知识内容的发展。
1 大数据时代的相关背景
1.1 大数据的概念
“大数据”这三个字在电视、报纸、网络等媒体中每天都会听到,人们越来越关注大数据这样一个概念,尤其随着互联网的发展与普及,以及云计算等相关技术的诞生和发展,互联网中的数据正在以一种前所未有的速度在增长和累积,可以毫不夸张的说,大数据已经走进了我们每个人的日常生活之中。正如我们从字面的理解来看,大数据指的就是庞大的数据规模。但是现在无论是工业环境还是学术界对于大数据都没有太过具体的概念,集中的概括,就是利用一些常见的软件作为工具,对大小超出常规的数据库中的数据进行获取、存储、管理和处理分析数据的能力的数据集。
1.2 大数据的特点
在我们生活存在的大数据时代,受到了各界人士的广泛关注,目前对于大数据的特点主要是按照Grobelnik M.所给出的3V 的阐述。即:1)规模性(Volume),数量庞大、规模扩充;2)多样性(Variety),包含了传统数据库的结构化数据,已经半结构或无结构化的数据;3)高速性(Velocity),主要体现在对大数据的产生和更新的频率上面,时刻都在产生和更新着庞大的数据。
另外,目前对于大数据的特点,还有一点被人们所关注,那就是价值性(Value),因为现在大数据的环境之下,有些大数据并不是有价值的,只有具备价值的大数据才是真正的大数据。
1.3 大数据的计算环境
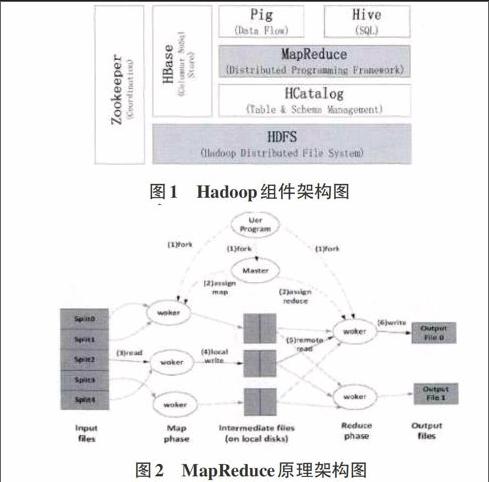
目前对于大数据环境的计算主要有两种方式,一种就是以Storm为代表的实时处理计算环境,Storm是一个分布式的、容错的实时的计算系统,可以很迅速的以秒为级别的处理大数据;另一类就是能够批处理计算的环境,比如MapReduce,而且,因为MapReduce自身具备着良好的扩展性、可用性以及容错性,所以目前MapReduce已经成为了处理大数据的并行计算环境中最为主流的方法。Hadoop是目前实现MapReduce思想最重要的开源,得到学术界和工业等的广泛关注,同时也得到了许多知名网站公司的大力支持。Hadoop 的组件架构图如1所示。
其中HDFS(Hadoop Distributed File System)是Hadoop的分布式文件系统,Hcatalog是对于表和底层数据管理的统一服务平台,MapReduce是分布式计算框架,分为三个阶段:map阶段、shuffle阶段和reduce阶段。HBase是基于列的数据库系统,Hive是数据仓库,Pig是数据流处理平台,Zookeeper是提供同步和配置集群等功能的分布式协作服务,其中HDFS和MapReduce是最重要的核心组件。
2 基于MapReduce的大数据处理技术
2.1 关于MapReduce
大数据正在迅速的增加和累积,为了能够更好的分析和挖掘这些数据中隐藏的信息,必须要将这些有价值的数据移植到容错性强的分布式计算环境当中进行处理,这样的情况之下,传统的数据结构已经不能满足快速分析大数据的功能,除了已有的特点之外,新型的数据处理技术还应当有良好的扩展性、较好的容错性、接口的易用开放性,并且支持异构结构,因此,MapReduce这样一种并行的编程模型和HDFS的分布式存储系统便可以双剑合璧,具备一切所需的特点,而且MapReduce由具备了map函数接口和reduce函数接口,map可以对数据进行过滤处理,reduce则可以对数据进行聚集的处理,这样可以屏蔽低层的并行控制,极大程度的减轻了程序员在进行并行程序开发的工作量。MapReduce的原理架构图如2所示。
2.2 基于MapReduce的数据处理算法
2.2.1基于MapReduce的连接算法优化
在海量的数据之中,正如大家所知,如何能够将庞大的数据在进行查询的操作之时,可以节省数据之间关连的操作,是用户最为期盼的,因此,对数据之间的连接算法进行优化可以极大的提高数据查询的效率。目前,对于MapReduce连接算法的优化,主要是对传统MapReduce的连接算法的优化、基于索引的连接算法的优化以及基于改进MapReduce的连接算法的优化这样三种。
基于传统的MapReduce的连接算法的优化主要是要解决两表等值连接、多表等值连接、相似度连接、数据倾斜时的连接、以及任意连接的算法的优化问题;基于索引的连接算法的优化主要是利用索引机制减少读取数据量或者是减少网络传输,从而提高数据连接效率,一直以来,索引技术都是提高数据查询和分析的重要手段之一,对于MapReduce进行批处理的模型算法是没有索引机制的,对于任意的一个查询的操作,都需要将所有的数据全部加载在系统中进行处理的,但是MapReduce却不具备索引机制,因此也成为它的弊端之一,学术界的研究人员在Hadoop基础之上增加了索引机制,进行了优化;基于改进的MapReduce连接优化算法主要是增加了接口,系统更加容易地进行连接算法的优化。因为传统的MapReduce的进行连接查询时,网络的传输量巨大,需要很多轮的MapReduce任务,学术界希望针对MapReduce的模型做一些尝试,对数据连接进行优化。
