内容管理系统的文章关键词提取组件分析与优化
2015-05-28□陆钊
□陆 钊
(玉林师范学院 计算机科学与工程学院,广西 玉林 537000)
1 前言
据CNNIC截至2015年6月的统计,仅中国的网站数量就有357万个,搜索引擎用户人数达5.36亿,使用率为80.3%[1].分析数据发现:中小型规模网站的基数很大,它们涉及地方门户、机构事务、企业宣传、科技情报、资讯传播等众多领域,以图文内容服务为主,蕴含海量的信息.另一方面,虽然搜索引擎用户多、使用率高、搜索结果量大,但是只有排名靠前的搜索结果被用户访问,排名越靠后则访问量骤降.目前,推荐引擎技术逐渐能够解读用户从而实现精准推荐,但主要应用于网上购物平台、网页广告投放等方面,需要的是中小网站所不具备的强大技术支持和运营成本.因此,SEO(Search Engine Optimization)仍是当前中小网站提升搜索结果排名的主要方法.
SEO需要对网站进行文本内容、代码结构等调整和优化,改进网站在搜索引擎中的关键词排名最是重要的环节,需要对关键词进行关注量分析、竞争对手分析、关键词与网站相关性分析、关键词布置、关键词排名预测等工作[2].关键词的获得可通过程序初选提取和人工筛选决策相结合的方法来实现.CMS(Content Management System)普遍带有文章关键词提取组件,利用程序初选可节省大量的时间和人力,但选择结果的优劣会影响人工筛选决策环节,最终影响网站的搜索引擎排名.中小网站绝大多数基于CMS进行二次开发创建,例如仅基于DedeCMS的安装量就达70万份[3].所以,优化CMS系统的文章关键词提取组件,能让中小网站广泛受益.
本文的主要工作是:研究DedeCMS的文章关键词提取组件,分析和优化算法,找到改进的思路和方法,提出可行的解决方案.
2 相关理论研究
关键词提取属于自然语言处理领域中的综合应用.在自然语言中,类似英文文本信息的单词与单词之间有空格分隔,但中文文本信息没有,而且中文词语没有清晰的定义,所以中文是自然语言中的较难处理的语类.要获得关键词最基础工作是先将由汉字连续组成的字串切分为词的序列,即进行中文分词.目前技术较成熟、使用较广的中文分词方法主要包括机械分词法和基于统计的分词法[4].
(1)机械分词法是基于词串匹配的分词方法,按照一定的策略将待分析的汉字串与一个“充分大的”词典中的词条进行匹配,若在词典中找到对应的词,则匹配成功(识别出一个词).其优点是分词速度快,实用性强,算法简单且易于实现,但是词典的完备性不能得到保证,歧义处理能力较弱,分词效果不够理想.代表算法是最大正向匹配分词法(FMM)[5]及其衍生算法.
(2)基于统计的分词法通过统计语料库中汉字共现频率等相关信息,定量描述汉字之间的结合紧密度,作为词语切分依据.该方法不仅考虑了句子中词语出现的频率信息,同时也考虑到词语与上下文的关系,具备较好的学习能力,对歧义词和未登录词(OOV)的识别有良好的效果,使得中文分词准确度比之前其他方法有了很大的提升,但处理速度相对较慢[6].相关模型有最大概率分词模型、最大熵分词模型、NGram元分词模型等[7].
鉴于两种分词方法优劣互补,一些学者提出了基于机械和统计相结合的分词方法:先采用机械分词法或其改进方法进行快速的中文粗分,再采用统计的方法进行歧义消解,提高分词准确性.综合方法保证分词准确率的同时,也兼具较快的分词速度,但实现算法比较复杂.相关算法有回溯正向匹配法[8]、基于正向最大匹配的概率分词算法[9]等.
一般分词系统的处理工作流程,如图1所示:

图1 分词处理流程图
3 组件分析与优化
3.1 DedeCMS的关键词提取组件
经过对DedeCMS的源文件进行分析,关键词提取组件分别由五部分文件组成,具体如表1所示:

表1 DedeCMS关键词提取组件列表
(1)输入文件:网站后台提供内容文档添加/编辑时的操作界面,存储文章并将汉字串作为变量赋值给处理文件;
(2)处理文件:从输入文件中得到需要分词的汉字串进行粗分,然后对粗分的短句子进行二次逆向最大匹配法(RMM)的方法进行分词,分词后对分词结果进行优化,得到最终的分词结果.执行过程中需要调入词典文件进行检测对比;
(3)词典文件:一个unicode字符格式的词语库,采用类似哈希(Hash)的数据结构进行存储,对于比较短的字符串分词,只需要占极小的资源,比其他一次性载入所有词条的实际性要高得多,但词典容量大小会影响分词执行的速度.在处理文件执行过程中被调用;
(4)数据库/表:存储由处理文件提取出的关键词,记录在keywords字段中,提供前端页面调用;
(5)输出语句/文件:网站前端文章页面采用{dede:field.keywords/}标记调用对应同ID的关键词,可用在title标签中以利于SEO;输出在后台article_edit.php页面中重新编辑或者article_keywords_main.php页面中批量编辑;
结合表1的标记,DedeCMS的关键词提取组件工作的数据流图如图2所示:
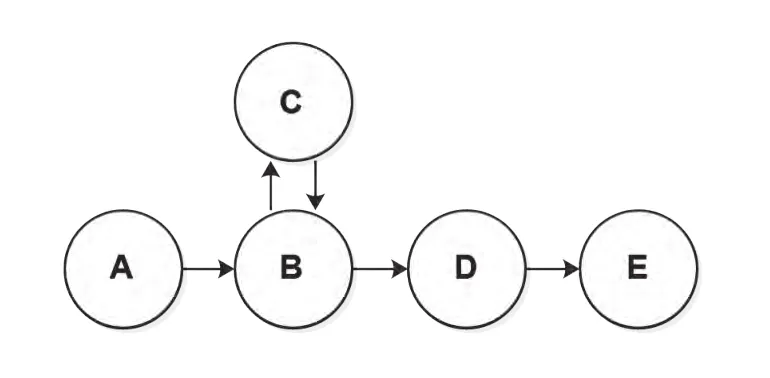
图2 数据流图
3.2 组件优化
组件的优化可从上述文件分别进行.首先,使用一些快速方法就能提高关键词的质量.例如:在后台的文章编辑页面(article_edit.php)显示了组件所生成的关键词,可手动进行修改.同时还可以修改组件生成关键词的个数,让该页面呈现更多的关键词以利于人工筛选[10].在关键词批量编辑页面(article_keywords_main.php)中,整体删除或禁用某些无用的关键词,给保留的关键词添加链接地址,也能较好的利于SEO.
其次,处理文件splitword.class.php采用的是机械分词方法,它的两个核心内容(词典结构和分词算法)都有可优化的方面:
(1)词典优化
base_dic_full.dic(主词典)文件收录了175406个词(含词性、词频),但它与words_addons.dic(辅助词典)文件已经四年没有更新,很多新词没有收录显然会影响分词的效果.解决的办法是更新或者替换原词典:
①更新词典需要将原词典反编译成可编辑的.txt类型文件,按“词,词频,词性”的格式添加新词,再编译成新词典.编译程序核心代码如下:

DedeCMS源程序中未提供该编译组件,可以通过使用第三方phpanalysis组件[11]来实现.
②可将其他开源分词系统的词典按格式转换后替换原词典.本文通过多方面的比较,选择采用NLPCN包含3669216个词汇的词典[12],它包含了很多新词,词量是原词典的21倍,文件大小适中.
另外,增加词量也造成词典文件的增大,通用的词典是无法兼顾多专业领域词汇的收录问题[13].对于缺乏本专业词典的站长,可以先整理出足够大的专业语料文件,再使用开源系统进行词典的创建.例如使用Stanford Word Segmenter进行分词,再使用Stanford POS Tagger标注词性,最后使用编程语言统计词频而得到.
(2)分词处理程序(算法)优化
分词处理文件splitword.class.php关闭或调低了一些预留参数,以节省网站在低配置虚拟主机空间的资源消耗,但也损失了部分功能和分词的准确性.splitword.class.php可开启或调整项如下表2所示:

表2 可优化代码列表
4 检测对比及分析
为检测上文3.2优化方法的有效性,采用原系统组件与优化后组件分别处理同一文本(组)的方法,对比两者在分词效果、执行消耗两方面的情况.为避免CMS其他组件的影响,设计独立测试程序实现检测需求,调用splitword.class.php参数接口,其他代码可参考引文[11]的程序,执行消耗的检测关键代码如下:

功能如程序截图3所示:

图3 测试程序界面
检测环境包括:
①硬件配置:CPU Intel i5 M450、内存4G、硬盘PLEXTOR PX-128M6S
②软件配置:Windows 10系统、APMServ 5.2.6 Web服务器组件、DedeCMS-V5.7-UTF8-SP1源码、Chrome 45.0浏览器
③网络配置:Localhost无延迟
(1)分词效果对比
从时政、科技、体育等各领域的文章随机提取100句进行分词操作,整理得到记录片段如下表3所示:

表3 分词效果记录

续上表
(2)执行消耗对比
选择两篇文章进行分词操作,从输出结果中获得内存使用和执行时间情况,得到记录如下表4所示:
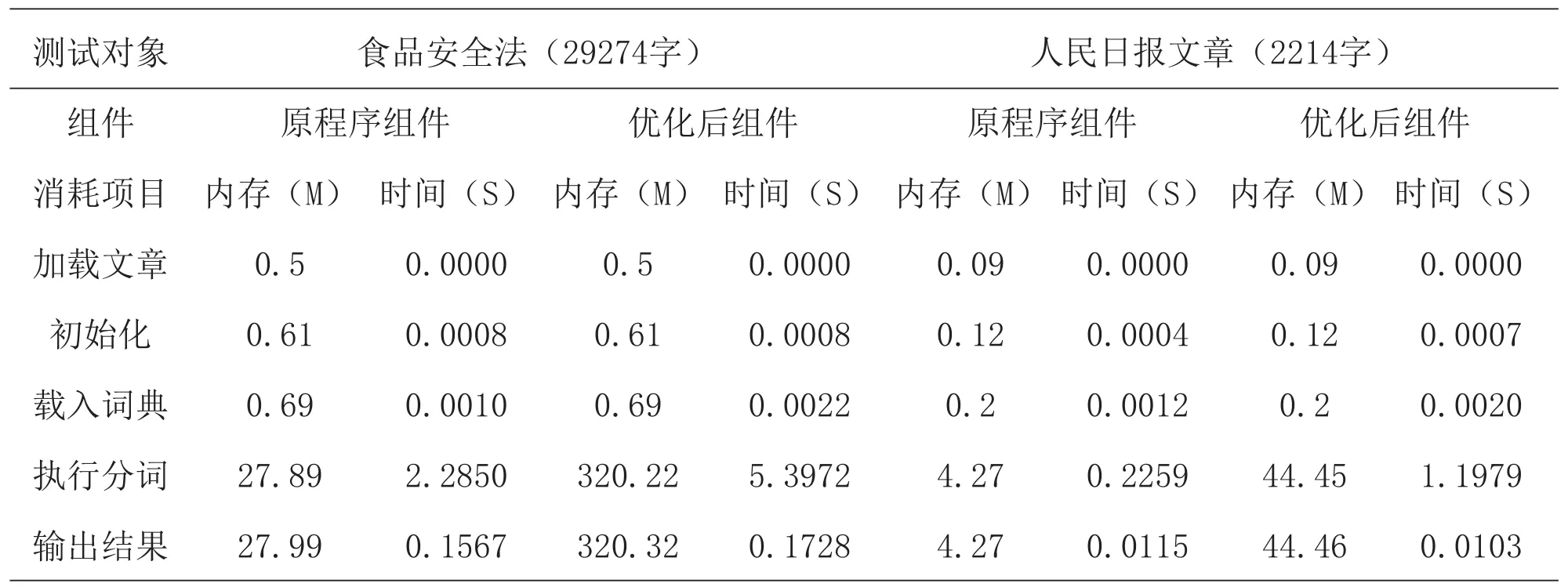
表4 执行消耗记录
从记录中发现,在加载文章、初始化、载入词典前三个阶段,内存使用和执行时间都很少,几乎可以忽略.在执行分词、输入结果两个阶段,内存使用相对增大,执行分词阶段的时间也较长,而且优化后组件的消耗比原系统组件要多,但都在可以接受的范围,特别是对比较常见的2000字左右的文章.优化后组件的消耗大的原因在于词典文件较大,这与分词效果形成了一种制衡关系.
5 总结与展望
实验对比结果表明,经过优化后的组件确实能够提高DedeCMS的关键词提取效果.该系统的安装量巨大,细小的调整和优化也能产生广泛的影响.在应用方面,本文设想,对于源码代码优化部分,网站管理员可手动修改或者官网提供系统更新补丁以方便在线升级.对于词典部分,网站管理员自己整理更新有一定难度,可借鉴杀毒软件模式,由官网进行整理并定期更新,由网络空间服务商(IDC)存储并为所辖的网站提供接口服务.该模式能形成一种良好的链条关系,避免资源浪费,同时提升服务品质和增加用户粘性.在研究方面,DedeCMS的文章摘要生成效果还比较差,有较大改进空间,它的组件与关键词提取组件有较大关联,可作为下一步研究的方向.
[1]CNNIC. 第36次中国互联网络发展状况统计报告[EB/OL]. [2015-07-22]. http://www.cnnic.net.cn/hlwfzyj/hlwxzbg/hlwtjbg/201507/t20150722_52624.htm.
[2]百度百科. SEO[EB/OL]. [2015-08-19]. http://baike.baidu.com/view/1047.htm.
[3]百度百科. 织梦CMS[EB/OL]. [2014-12-29]. http://baike.baidu.com/subview/2208013/6159188.htm.
[4]周俊,郑中华,张炜. 基于改进最大匹配算法的中文分词粗分方法[J]. 计算机工程与应用. 2014,(02):124-128.
[5]王瑞雷,栾静,潘晓花,等.一种改进的中文分词正向最大匹配算法[J].计算机应用与软件,2011,28(3):195-197.
[6]韩冬煦,常宝宝. 中文分词模型的领域适应性方法[J].计算机学报. 2015, 02期:272-281.
[7]江兆中.基于语境和停用词驱动的中文自动分词研究[D].合肥工业大学,2010.
[8]奉国和,郑伟. 国内中文分词技术研究综述[J].图书情报工作,2011,第2期(2):41-45.
[9]何国斌,赵晶璐. 基于最大匹配的中文分词概率算法研究[J]. 计算机工程. 2010,36(5):173-175.
[10]百度经验.dedecms技巧:关键字长度修改[EB/OL].[2011-12-23]. http://jingyan.baidu.com/article/14bd256e132923bb6d261218.html.
[11]IT柏拉图. PHPAnalysis无组件分词系统[EB/OL].[2014-11-27]. http://www.phpbone.com/phpanalysis/.
[12]NLPCN. 360万中文词库包含词性词频[EB/OL].[2014-08-13]. http://www.nlpcn.org/resource/25.
[13]修驰.适应于不同领域的中文分词方法研究与实现[D].北京工业大学,2013.
