自动文摘的关键技术
2015-05-15骆俊帆
骆俊帆
(四川大学计算机学院,成都 610065)
自动文摘的关键技术
骆俊帆
(四川大学计算机学院,成都 610065)
随着互联网上信息爆炸性地增长,信息过载问题给人们造成了困扰,检索过程中如何有效地命中所需信息成为一个亟待解决的问题。为了从互联网上更加效率地浏览和吸收信息,自动文摘技术在保留原文主要内容的前提下,对文档进行压缩表示。探讨自动文摘的概念和意义,并对当前自动文摘的关键技术做一个较为全面的综述性介绍。
检索;自动文摘;效率
0 引言
随着信息时代的飞速发展,互联网中累积了大量的文本信息,然而通常人们的兴趣点只是其中极少的部分,如何迅速有效地从海量信息中找到它们是亟待解决的问题。信息检索技术的出现缓解了这个问题带来的压力,但成千上万的检索结果与人们的实际需求还相差甚远。
自动文摘技术[1]的目标是在保留原文核心内容的前提下,对原始文本进行信息压缩表示。文摘准确全面地反映了某一文献的核心内容,它是一种简洁连贯的短文,而自动文摘技术则用于自动地从文档中提取文摘。传统的信息检索技术在面对信息过载危机时并不能达到一个很好的效果,而自动文摘技术可以在一定程度上起到辅助作用[2]。首先,信息检索过程中可以使用优质的文摘替代原始文本进行检索,极大提高了检索信息的效率。其次,在检索结果的可视化中利用优质文摘,用户不需要对大量的原始检索结果进行浏览便能轻松取舍,不但能提高需求信息的命中率,用户负担也大大地降低了。因此自动文摘技术逐渐成为当前信息检索领域的研究热点之一。
自动文摘技术可被分为摘要(abstract)和摘录(extract)两类[3],摘要方法[4~5]试图在对文本主要内容的理解基础上,使用简短连贯的自然语言将原文主要内容描述出来,即会使用新的句子组成摘要。而摘录方法则首先从原始文档中抽取出重要的句子,然后再将这些句子连贯到一起形成摘要。其中句子重要性由一些统计和语言学特征所决定。当前自动摘要技术大多都是基于摘录的方法,通常自动文摘包含文本预处理、文本分析处理以及生成文摘三个步骤,并且存在一些不同的文摘评估方法。本文接下来将对自动文摘技术做一个概述性的介绍。
1 文本预处理
经过预处理,原始文本有结构化的表示。一般包括三步:
句子边界识别。英文文本中,常常利用句点本身,再考虑句点上下文信息制订一些规则进行句子边界识别[6]。
去除停用词。对于一个特定的目的,停用词可以是任意类别的词语。一般停用词可分为两类:人类语言常出现的功能词和应用十分广泛的词。所谓功能词是不包含任何实际意义的词语,如“am”、“is”、“are”、“the”、“what”等。而对于第二类词语,如“want”,广泛地出现在各种文档中。
还原词根。词根还原的目的是,获取到能表达词义的原始词根形态。表1是一个词根还原示例。
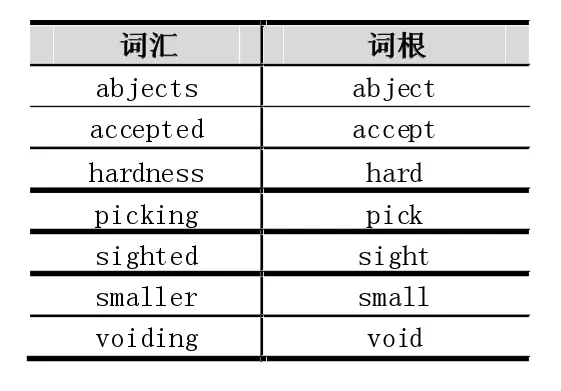
表1 词根还原示例
2 文本分析处理
文本分析处理过程输出一个涵盖了原始文本主要内容的中间表示文本,并对文本中的每个句子赋以重要性得分,这里列举一些常用的方法。
2.1 词逆向文档频率(TF-IDF)方法
文献[7]中使用词频和逆向句子频率构建句子级别的词袋子模型,其中逆向句子频率就是文档中包含给定单词的句子的频率。查询相关的文摘系统中,构建好这些句子向量之后,通过计算和查询的相似度,高相似度的句子可用作摘要。一般性的文摘系统中,可以将一些文档中的高频词作为查询词集,因为这些高频词可以视作是文档的一些主题词。
2.2 基于聚类的方法
人们通常是一个主题接一个主题地组织一篇文档,这些不同的主题会显式或隐式地分布在不同的章节部分中,这种现象在自动文摘中也可以用到。直觉上,摘要涉及到文档的每个主题,因此有自动文摘技术通过聚类的方法,将同一主题下的句子聚到一起,进而生成合适的摘要。这类自动文摘系统输入的是经过聚簇的文档,每个簇是文档的一个主题,主题用簇中TFIDF[8]值高的词汇集表示。句子重要性得分由句子和主题的相似度度量,另外句子在文档中出现的位置信息也能考虑进去,例如在新闻文章中,开头位置的句子就更重要一些。
2.3 基于图论的方法
从前面的方法可以看出,识别文档中主题是一个必要的环节。文献[9]提出一个基于图论的方法来识别这些主题,用一个无向图表示文档,图中节点表示文档中的句子。如果两个句子有一定数量的相同词汇,或者说它们的余弦相似度超过一定阈值,那么这两个句子间存在一条边。如图1所示,不相连的子图其实就是文档的不同主题块,而重要性越大的句子节点即有越多的边连接。图1中就包含有3~4个主题,大的实心黑圈则表示重要性大的句子。
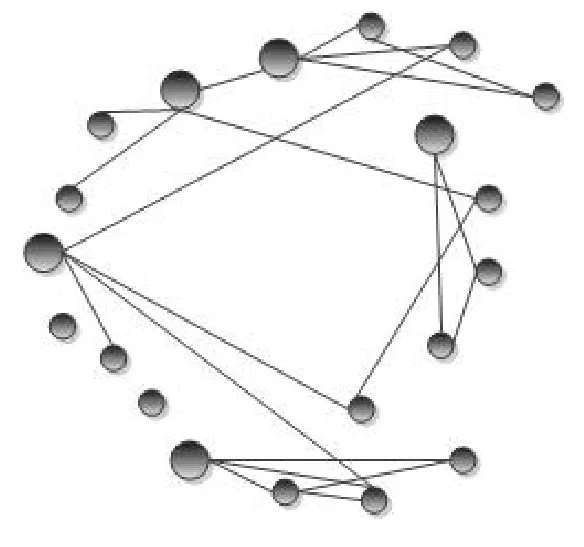
图1 基于图论的方法示例
2.4 基于机器学习的方法
给定训练文档和相应摘要的集合,自动文摘可以看作是一个分类问题:基于一些语言学特征和上下文特征,文档中的每个句子被分为摘要类句子和非摘要类句子。文献[10]中,利用大规模训练语料和贝叶斯分类器计算每个句子属于摘要型句子的概率:
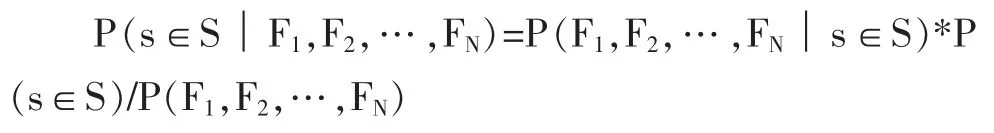
其中s表示文档中的句子,S是最终生成的摘要,F1…FN是分类用到的特征。
3 生成文摘
最终文摘生成的复杂度取决于用户不同的需求,目前实用系统所能生成的摘要是把从原文中抽取的片段和句子稍作润色及修改得到的结果。如果只需要简单地罗列出来原文的信息片段所包含的语义信息,那么几乎可以省略掉生成摘要这步工作。而如果最终需要的是一篇语句连贯、内容完整的短文,达到与人工水平相提并论的程度,那这一步工作就非常复杂了。因为文摘的目的是提高信息检索命中文献的速度和效率,润色及修改工作不会做出太大贡献,反而检索系统的处理时间会消耗更多。所以虽然语言学知识有利于增强文摘的可读性,但自动文摘系统大多情况下并不需要它。
4 文摘评估
自动文摘的评估[12~14]也是一项非常重要的任务,一般来说文摘评估策略分为内部(intrinsic)评价和外部(extrinsic)评价两种。内部评价要利用到人工主观性感觉,语句通顺、句间语义连贯并且不包含主语悬挂现象的文摘是优质的文摘。而外部评价策略则是一种基于任务的评价方法,例如针对信息检索任务设计评估策略,文档正确检索率就可以作为评价指标[15]。两种评价方法各有利弊:内部评价方法需要人工评价,主观性太强,并且评价结果可能因人而异,但是评价方法不局限于特定的任务;而外部评价方法虽然是客观性的评价,易于对比不同的文摘系统,但是评价方法局限于一个特定的任务。
5 结语
自动文摘技术可以将冗长的文档内容进行精简,并且不损失主要信息,在一定程度上能辅助检索系统解决信息过载问题。挑战在于从海量的文本信息中,针对特定的用户需求能迅速地生成高准确率、低冗余的摘要。本文从文本预处理、文本分析处理、生成文摘和文摘评估四个方面对自动文摘技术进行了综述。
[1] Mani I.,Maybury M.,eds.1999.Advances in Automatic Text Summarization[M].MIT Press
[2] 柴晓丽.自动文摘技术的研究与应用[D].长春理工大学,2007
[3] Vishal Gupta,Gurpreet Singh Lehal.A Survey of Text Summarization Extractive Techniques[J].Journal of Emerging Technologies in Web Intelligence,2010:258~268
[4] G Erkan,Dragomir R.Radev.LexRank:Graph-based Centrality as Salience in Text Summarization[J].Journal of Artificial Intelligence Research,2004:457~479
[5] Udo Hahn,Martin Romacker.The SYNDIKATE Text Knowledge Base Generator[C].Proceedings of the First International Conference on Human Language Technology Research,2001
[6] Read,Jonathon,Rebecca Dridan,Stephan Oepen,Lars Jrgen Solberg.Sentence Boundary Detection:A Long Solved Problem[C].In Proceedings of COLING,2012:985~994
[7] H.P.Luhn.The Automatic Creation of Literature Abstracts[R].Presented at IRE National Convention,1958:159~165
[8] Yong zheng,Nur,Evangelos.Narrative Text Classification for Automatic Key Phrase Extraction in Web Document Corpora[C].WIDM,2005:51~57
[9] Canasai Kruengkari,Chuleerat Jaruskulchai.Generic Text Summarization Using Local and Global Properties of Sentences[C].Proceedings of the IEEE/WIC International Conference on Web Intelligence(WI’03),2003
[10] Horacek H,ZockM,ed.New Concepts in Natural Language Generation:Planning,Realizations and Systems[M].London:Pinter Publishers,1985
[11] Salton G,Singhal A,Mitra M.,Buckley C.Automatic Text Structuring and Summarization[C].IP&M,1997:193~207
[12] Ani Nenkova,Rebecca Passonneau.Evaluating Content Selection in Summarization:The Pyramid Method[C].HLT-NAACL,2004: 145~152
[13] Chin-yew Lin.A Package for Automatic Evaluation of Summaries[C].in Proc.ACL Workshop on Text Summarization Branches Out, 2004
[14] Eduard Hovy,Chin-Yew Lin,Liang Zhou,Junichi Fukumoto.Automated Summarization Evaluation with Basic Elements[C].In Proceedings of the 5th International Conference on Language Resources and Evaluation(LREC),2006
[15] Kathleen Mackeown,Ani Nenkova,David Elson,Rebecca Passonneau,Julia Hirschberg.A Task Based Evaluation of Multidocument System[C].SIGIR,2005
作者简介:骆俊帆(1990-),男,湖北黄冈人,在读硕士研究生,研究方向为数据挖掘
The Key Technologies of Automatic Summarization
LUO Jun-fan
(College of Computer Science,SCU,Chengdu 610000)
With the explosive growth of the Internet information,the information overload problem trouble people.How to effectively hit the required information in retrieval has become a problem to be solved.In order to view and absorb information from the Internet more efficiently,automatic summarization technology can compress the document by keeping the original main content.Discusses the concept and significance of automatic summarization,and makes an introduction for the key technologies of the automatic summarization.
Retrieval;Automatic Summarization;Efficient
1007-1423(2015)02-0035-04
10.3969/j.issn.1007-1423.2015.02.009
2014-12-02
2014-12-16
四川省科技创新苗子工程(No.13-YCG058)
