面向数据规模可扩展的并行优化K-means算法
2015-05-15李尧坤
李尧坤
(四川大学计算机学院,成都 610065)
面向数据规模可扩展的并行优化K-means算法
李尧坤
(四川大学计算机学院,成都 610065)
传统的K-means算法迭代过程中需要加载全部的聚类样本数据,并且更新类中心过程是非并行的。针对传统K-means算法处理数据规模小和类中心更新慢的问题,提出一种改进的K-means算法,面向解决K-means单台机器处理数据规模扩展问题,和处理器利用率低效问题。实验验证,该方法能够高效地处理大规模数据聚类。
K-means;大规模;更新类中心;并行
0 引言
聚类是用于划分空间中的数据方法,将相似的数据聚成相同簇,不相似的聚成不同簇,是数据挖掘、机器学习的基本工具。K-means算法是科研和应用中常用的聚类算法,是由Steinhaus于1955年,Lloyd于1957年Ball,Hall于1965年,McQueen于1967年各自独立提出[1]。自K-means算法提出以来,许多研究者对它进行了改进和优化,主要包括:初始类中心选择[2]、K-means算法并行化改造[3]、近似K-means算法。虽然K-means历经改进,研究人员和工业界最常用的依然是Lloyd提出的经典的K-means算法框架,K-means的各种衍生版本一般用于特定的场合。商用聚类工具——CLUTO[4],采用的也是经典K-means算法。近年来,随着大数据的提出和研究应用需求的扩展,K-means作为大数据最为广泛使用的基础工具之一,得到了更为长足的发展,同时也面临着新的挑战——如何解决大规模数据的聚类问题。传统的K-means算法需要加载所有聚类样本到内存,当需要聚类的数据规模超出进程内存限制时,算法便不能运行,同时由于算法类中心更新过程是非并行的,处理器利用效率低。一些研究者提出了基于Hadoop Map-Reduce[5]的改进算法,能够一定程度地解决大规模数据聚类问题,然而算法是基于Hadoop框架,必须先要架设Hadoop并且要求较高的硬件资源配置,否则因为Hadoop分布式框架本身的通信,调度开销,甚至会低于单台机器聚类效率。本文提出的算法可实现单台机器上规模可扩展的和充分利用处理器处理效率的K-means算法。
1 传统的K-means算法及背景
1.1 K-means的优化目标
对于给定的聚类任务样本集合S={v1,v2,…,vn},vi∈Rd,K-means的优化目标就是找到K个划分P={p1,p2,…,pk},对于任意vi,被分到K个划分中的某一个pj,K个划分的中心为:
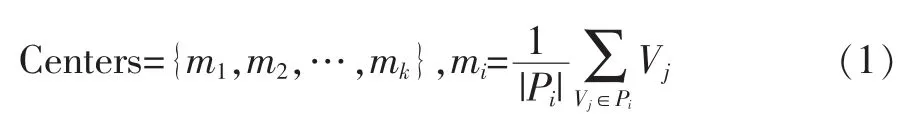
使得下式取得最小值,

式(2)的意义是,找出K个划分,使得每个划分的成员向量与对应划分均值向量差的平方和最小。已经证明最优化J(C)是一个NP-Hard问题,因而研究者从启发式求解方法入手解决该问题。K-means是一种贪心思想的最优化J(C)的方法,初始类中心后,每次迭代重新分配样本到欧氏距离最小的类中心所属类,然后再更新类中心,直到类中心不再移动,收敛到固定的位置。
1.2 传统K-means算法流程

重新计算聚类样本集S的每个样本同Centers的距离,分配到距离最小类
更新Centers为每个类的均值向量,并记录类中心移动的偏移量绝对值之和offset
Until offset<ξ//ξ为设定迭代停止的一个较小的阈值
2 本文改进的K-means算法
针对传统K-means算法不能大规模聚类和更新类中心处理非并行问题,首先,将聚类数据预处理为二进制向量块,按批次读入样本向量到内存更新类中心可以解决因数据规模大而不能运行的问题;其次,更新类中心过程,各个样本向量同类中心间计算距离是独立的,可以将其并行化处理,最大化利用处理器效率,更快地完成聚类。
2.1 数据预处理
预先将聚类样本向量转储为二进制浮点形式,可以避免每次读入数据从字符向量到浮点向量的解析开销。同时分块存储,批量导入到内存,既可以解决数据规模扩展问题,同时保证高效地将数据加载到内存。设定二进制向量块的最大文件长度为S_Size,读入字符串表示的样本向量并解析为浮点值表示向量写入到向量块文件,当超过S_Size时,另外开辟新的向量文件进行存储。

图1
每个文件块的最大长度为S_Size,每一行存储一个向量——浮点型的二进制值。整个文件块存储整数个向量直到所有向量空间超过S_Size时,另外开辟新的文件存储。预处理后,便于后续算法快捷批次读入向量数据到内存。
2.2 改进的算法流程


算法采用批次读入聚类样本到内存,并行计算更新类中心,可充分利用处理器和解决传统K-means因聚类样本数据量过大无法聚类问题。
3 实验设置及结果
实验环境为Windows7操作系统,处理器为i5-3230m(2核)4G内存笔记本电脑。算法基于.NET framework 4.0和C++实现。设定实验参数2.1中S_Size=600M,算法中批次读入内存向量最大占用内存为160M。实验采用了数据规模为10^6,10^7,10^8 64维双精度浮点向量,同传统K-means进行实验对比,类中心K=1000。
从表1可以看出本文处法能够处理传统K-means算法已经不能处理的10^8规模级别数据,验证了本文算法对于数据规模的可扩展性;比较10^6和10^7数据,可看出本文算法大致快2倍,处理器为2核,说明充分利用了处理器效率,同时也说明本文算法改进使用硬盘存储聚类样本数据,批次导入内存带来的额外开销小,聚类数据规模较大情况下可以忽略。
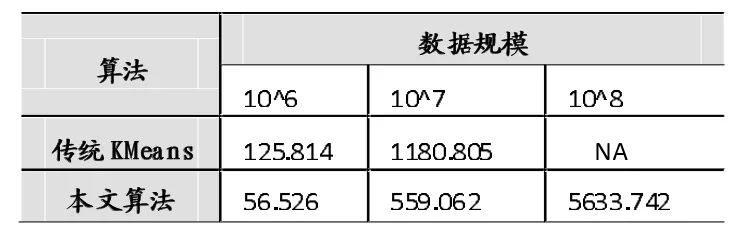
表1 传统K-means同本文算法运行时间对比(s)
4 结语
K-means算法是研究和应用常用到的基本工具,本文改进的K-means算法较传统算法,解决了聚类数据规模可扩展问题,同时也优化了算法处理器效率利用低问题。相比在没有Hadoop软硬件平台支撑的前提下,本文算法可应用到更广泛的实际问题中。
[1] 王千,王成,冯振元,叶金凤.K-means聚类算法研究综述[J].电子设计工程,2012(07)
[2] Arthur,D.and Vassilvitskii,S.K-means++:the Advantages of Careful Seeding[J].Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms.Society for Industrial and Applied Mathematics Philadelphia,PA,USA.pp.1027~1035,2007
[3] W Zhao,H Ma,Q He.Cloud Computing[C].springer.2009
[4] Karypis Lab.http://glaros.dtc.umn.edu/gkhome/views/cluto
[5] 周丽娟,王慧,王文伯,张宁.面向海量数据的并行K-means算法[J].华中科技大学学报(自然科学版),2012(s1)
Parallel Optimization K-means Algorithm Facing the Data Size Scalable
LI Yao-kun
(College of Computer Science,Sichuan University,Chengdou 610065)
Traditional K-means algorithm need to load all the sample data into memory,and updating the class center is a non-parallel process.For the problem of the number of processing data is small and updating class centers with low speed in traditional K-means algorithm,proposes an improved K-means algorithm to solve the problems of processing data scale expansion and the processor utilization inefficient. Experiment shows the method can efficiently deal with large-scale data clustering.
K-means;Large-Scale;Updating Class Centers;Parallel
1007-1423(2015)02-0003-03
10.3969/j.issn.1007-1423.2015.02.001
李尧坤(1989-),男,湖南郴州人,研究生,研究方向为多媒体计算
2014-11-18
2014-12-16
