大数据时代的食品安全检测和预警
2015-05-08李夏冰凌文婧
李夏冰+凌文婧
随着互联网以及其他产业数据量爆炸式的增长,大数据、云计算等概念越来越多地被人们提及。2012年,联合国发布了大数据政务白皮书,指出大数据对于联合国和各国政府来说是一个历史性的机遇。公认的大数据四个特征为:数据量大(Volume)、类型繁多(Variety)、价值密度低(Value)、速度快时效高(Velocity)。这与食品安全监测所获取的数据特征相符合。其中数据量大对应的是每天成千上万种食品在生产、加工、销售、检疫时产生的海量数据;类型繁多对应的是食品监测数据类型的多样化,如:分光光度值、气相及液相色谱值、甲基红试验染色值、荧光光度值等等;而在这些海量的数据中,寻找潜藏的食品安全隐患和发展趋势犹如大海捞针;食品作为快速消耗品,由于较短的保质期限制,在生产出来之后迅速被消费和消耗,因此食品安全监测数据的时效性非常重要。因此,海量的食品安全预警数据适合使用大数据的思维方式、处理手段进行分析和处理。使用大数据进行食品安全预警将成为食品安全监测手段发展的新趋势。
大数据时代食品安全数据的特点
大数据时代,数据的颗粒度、维度、活性、规模、关联度成为衡量数据价值最重要的性质。
数据的颗粒度反映的是数据的精细化程度,对于单个食品而言,单一的检测指标往往难以反映该食品质量的全貌,2008发生的三聚氰胺事件,暴露了我国食品检测手段及方式的漏洞,增加食品监测数据的颗粒度,有助于为食品安全提供更加全方位的信息。
数据的维度指的是数据来源的丰富性。信息时代,食品安全数据不仅限于企业和监管部门,计算机网络信息、媒体报道、舆情资讯等等渠道,同样能为食品安全监测和预警提供重要的数据来源。这些渠道为食品质量提供了最及时、最客观的逆向反馈,许多食品质量问题在食品的加工销售和运输途中往往难以发觉,在消费者手中才得到了及时的揭露。近期暴露的食品安全问题有不少是由于消费者举报,获得媒体报道后才引起相关部门的调查和重视的,因此,网络、媒体及大众言论为食品生产企业和监管部门掌握第一手材料提供了可能,应当作为食品监测数据的来源之一。
数据的活性指的是数据被更新的频次,从食品安全监测数据上看,数据的活性较大,表现在数据获取频繁:如一周一检、一天一检、不少生鲜食品甚至一小时一检,这些频繁获取的数据在很大程度上增强了数据的活性、使得数据实时、可信、可靠。
数据的规模指的是数据量的大小,我们就液态牛奶从原奶到上市期间的检验数据为例,来估测其数据量大小:原奶运输到工厂后需进行质量检验,检验指标共计117项,包括感官、滋味、气味、理化特性、微生物含量等多个方面;牛奶在储存之后需进行原奶检验,检验指标包括上述各类,附加对容器、仓储条件的检验;在牛奶经过巴氏消毒后,需进行储存检验,储存检验参照巴氏杀菌乳国家标准,共有10项必检,包括理化标准、微生物指标、感官指标、储藏方式等;储存检验后,进行保温试验,必检的项目包括64项,外加风险监测项目44项。整个牛奶生产过程需要进过4个部分累计达到899项指标的检验。这些检验过程受到农业主管部门和质量监督部门的监管。在流通过程中,需进过工商部门、出入境检验检疫部门的抽检,合格后方能在超市上架或通过海关流通,期间需进过工商部门、出入境检验检疫部门、媒体大众等相关单位的监管和监督。工商部门检验的项目共计12项,出入境检验检疫部门需检验的项目共计60项。笔者粗略估计了一下,单盒液态纯牛奶从生产源头到消费者手中,共需经历检验最少六次抽查,总体971项指标,还不包括对奶牛和饲料的检验指标。我国2012年全年共计生产牛奶3744万吨,按照每1ml牛奶的重量是1.0288,每盒牛奶250ml,每个检测指标的储存占4个字节。计算,一年仅因牛奶检测而产生的数量量达到5.653×1014≈514T。这些数据生产出来后大多数被丢弃。
数据的关联度指的是数据之间的相关程度,如上文所述,食品安全数据指标各不相似、表现了食品安全指标的方方面面,然而这些数据之间关联性很差,如:食品添加剂的数据检测值和食品中农药残留值在理论上无相关性,然而基于各类食品的不同特征,挖掘食品安全指标中的潜在规则能为食品安全预警提供数据参考和经验借鉴。上文已介绍了不少文献使用数据挖掘领域中关联规则挖掘数据价值的方法,在此不再赘述。
大数据时代食品安全数据的获取方式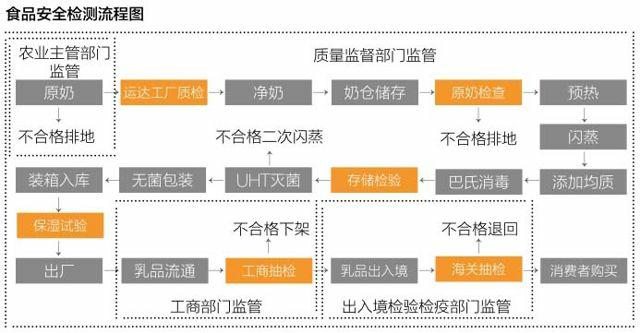
按照传统方式可在食品生产、流通过程中收集到大量的、可靠的食品安全数据,按照上文的介绍,这些数据量已经非常庞大。以下介绍几种食品安全预警数据的其他获取方式:
媒体大众渠道的食品安全数据获取方式。食品消费的终点是消费者手中,对于食品的安全质量,消费者最具有发言权,传统的食品安全数据仅仅来源于食品生产部门和监督管理部门,来源单一、片面。利用大数据对于数据的收集、处理方法,可以方便快捷地收集到网络媒体、微博、论坛中关于食品安全的消费者反馈。并通过对自然语言的分析判别正面负面信息,对食品安全预警具有非常重要的指导性意义。另外,通过对食品安全言论相关信息分析,可精确判别食品质量问题发生的区域、时间、受害群体,对食品安全问题做出实时、精确、精准的预报。
基于食品安全追溯系统的数据获取方式。食品安全追溯系统的建立旨在实现视频“从田间到餐桌”的一条龙式质量监管,以期在食品的生产和销售过程进行无疏漏跟踪,确保食品的质量。现在国内外许多企业、政府部门正在大力加强和促进该系统的建立建设,可预见食品安全追溯系统在未来将被迅速建立、并具有长足的发展。在食品安全追溯的过程中,众多数据被实时监控并记录了下来,其中不仅仅包括食品加工、原材料的数据,还可包括如:食品容器、食品储存环境、食品来源地等许许多多的附加信息,这些信息对于消费者购买流食品提供了非常全面的信息。对于食品安全预警而言,这些实时连贯性的数据可以更方便地进行时间维度上的趋势拟合和预警分析。
大数据时代食品安全数据的处理方式。
使用大数据思路和分析方法对食品安全进行检测和预警,首先要充分使用数据科学的处理方法,由于不同的数据和来源渠道,非结构化数据代替结构化数据成为分析和处理的主要对象,常见的数据有以下几类:表格、点集、时间序列、图像、视频、网页以及其他的网络数据。每一种非结构化数据都应当对应相应的处理方式,如,点集可使用概率分布方法进行拟合;时间序列数据可采用随机过程(如隐式马氏过程)方法进行处理;图像可通过随机场(如吉布斯随机场)进行分析;网络数据可通过图模型、贝叶斯模型来处理。
进行初步处理后的数据,可通过以下方式判别其价值,如:相关性(若所得数据与其他数据具有弱相关性,则可考虑丢弃)、排序(对数据的重要性进行排序,如食品中重金属含量的重要性要远高于蛋白质含量,可考虑增加其权重或在数据建模中优先考虑)、分类和聚类(使用分类和聚类方法能快速寻找到数据之间的相互关联,找到其相似性。对相似特点的数据进行统一处理,减少后续处理的数据量)。
在上述数据处理的基础上,可考虑对数据价值的进一步提取和分析,如:建立度量空间,讨论数据之间范式距离的远近以及关联性的大小;建立网络拓扑结构,讨论数据之间的空间关联性及分布情况;建立函数结构,讨论数据之间的统计学规律(如相关性、回归系数、主成分分析)等。
另外,处理食品安全大数据,需要引进大数据管理系统和技术流程。广泛使用的大数据管理系统有Hadoop/ Hive系统,常用的底层支持框架有Core/ Avro等,常用的数据存储系统有Hbase/ MapReduce等分布式、非关系型数据库,常用的文件系统有HDFS等。值得一提的是,当今大数据技术有大量的开源软件,开源算法,大大丰富和方便了人们在其之上进行编程和应用,为使用大数据思维和方法处理食品安全数据提供了技术支持。
