基于改进的加权累积差分法的人体行为识别
2015-05-05张治学
张治学,陈 曦
(河南科技大学 网络信息中心,河南 洛阳 471023)
基于改进的加权累积差分法的人体行为识别
张治学,陈 曦
(河南科技大学 网络信息中心,河南 洛阳 471023)
针对两帧差分法和三帧差分法难以提取到完整的运动剪影的问题,提出了一种基于改进的加权累计差分法的人体行为识别方法。通过使用改进的加权累计差分法能通过计算帧的相似度,用于对权值进行自适应变化,从而提取到较为完整的人体运动剪影,然后采用提出的关键帧的模板选取方法和分块特征提取来进行行为的特征提取,最后利用支持向量机构造分类器进行识别。实验结果表明采用改进的加权累积差分法能有效提高人体行为识别率。
人体行为识别;加权累积差分法;支持向量机
当今世界处在一个高度信息化和智能化发展的阶段,随着视觉传感器、人工智能技术的发展,以及计算机图形芯片处理速度的提高,使得近些年来人体行为识别技术成为在安保、医疗、动画游戏等众多领域有着广泛应用前景的一个研究热点,主要应用于智能监控系统,人机交互界面和运动分析等。
有资料表明人类约有80%以上的信息来源于其视觉系统[1],视觉图像具有直观、具体的特点,是人类获取外界信息的主要途径和来源。由于计算机是计算和存储设备,无法像人类一样具有直接观察理解图像内容与含义的能力,所以需要将图像中所包含的信息提取表示为计算机能够去处理的数据结构,再通过模式识别过程建立其特征与语义标签之间的映射关系,从而使得计算机能理解图像的内容和含义。因此人体行为识别一般分为运动检测、特征提取和行为识别3个组成部分。
运动检测是指从视频图像中将目标的运动检测出来,其目的是为了分割静态的背景图像与发生了运动的前景图像,从而实现对运动目标的跟踪。目前运动检测方法主要有:帧间差分法、背景减除法和光流法[2]。其中背景减除法需要背景建模,能提供较为完整的前景,但算法受环境影响较大;光流法算法较为复杂,需要较高的硬件计算成本。帧间差分法又称为时间差分法,其原理是将图像序列中时间相邻的图像帧所对应的像素进行作差,将像素发生变化较大的提取出来作为发生运动的前景。常用的帧间差分法有两帧差分法[3]、三帧差分法[4]和加权累积差分法[5]。帧间差分法通过对全局运动补偿并能较好适用于背景发生变化的情况,但在检测过程中会发生孔洞和重叠现象[6],造成无法提取较为完整的前景图像。针对这一问题,本文提出一种改进的加权累积差分法,能较为完整地提取人体运动前景来用于行为表示,同时避免背景图像的噪声积累。本文还采用关键帧模板选取方法和分块特征提取方法相结合,来提取人体行为图像统计特征,最后结合支持向量机对提取人体的行为特征进行分类识别。
1 加权累积差分法的改进
在使用两帧差分法或三帧差分法来进行运动检测时,其获得前景的完整性往往依赖于图像帧的选取,如果所选取的邻近图像帧之间没有发生明显的变化,就难以检测到相对完整的运动前景。因此可以用当前图像帧分别与不同时刻的图像帧进行两帧差分,然后将得到帧间差分图像进行加权累积,从而得到运动前景。文献[5,7]采用加权累积差分法来进行运动检测和分割,取得了良好效果。其中文献[7]提出了一种基于双边加权的累积差分运动检测方法,该方法充分考虑了不同时刻图像帧对当前图像帧的影响,给不同帧间差分图像赋予不同的权值,使得经过加权累积得到的图像能较好地表示人体行为的运动前景。
若It(x,y)表示为在t时刻的当前图像,It-n(x,y)表示为在t-n时刻的图像,n为自定义参数,本文取4。则通过式(1)计算出2n+1帧图像的加权累积差分图像diff(t)
(1)
由于当前时刻的图像帧与其他不同时刻图像帧之间的差异一般是不同的,所以可以根据当前时刻图像帧与其他不同时刻图像帧之间的时序关系建立与之相对应的权值,其中文献[7]通过建立时间相关的变量,给出了3种基于时间的权值选取经验公式
(2)
(3)
(4)
式中:权值wi大小只与所选取用于差分的图像帧对应的时间有关,权值不能反映出当前图像帧与其他不同时刻的图像帧之间在图像差异上的联系,因此提出一种改进的权值选择方法,通过寻求当前图像帧与其他不同时刻图像帧之间的图像相似性来计算其帧间差分图像所对应的权值,从而使检测出的前景区域更为完整。
首先,定义A为M×N分辨率的灰度图像帧,B为M×N分辨率的灰度图像帧,Ax,y和Bx,y为对应图像在点(x,y)处的像素值,则2帧图像的相似度ri为
(5)
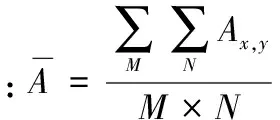
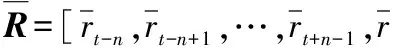
由于当前帧与其相似度较高的其他时刻图像帧进行差分时,帧间差分图像变化的区域较小,因此应赋予较低的权值,而与相似度较低的历史帧作差时,帧间差分图像变化的区域较大,因此应赋予较高的权值。最后根据这一原则,利用式(7)计算出的帧间差分图像所对应的权值矩阵W中的元素为
(7)式中:i=t-n,t-n+1,…,t+n,W=[wt-n,wt-n+1,…,wt+n-1,wt+n]。
加权累积差分算法流程如图1所示,为了更好地提取运动前景,减少不必要的背景噪声,在对图像进行累积加权之前要将帧间差分图像转化为二值图像,做膨胀运算并填充空洞后,通过形态学滤波的方法去除背景噪声,从而避免了噪声的累积,提高背景分割的效果。如图2所示,从左到右依次为:原始灰度图像,加权累积差分法得到的人体剪影和改进的加权累积差分法得到的人体剪影。对比可以看出经过改进后的加权累积差分法得到的剪影图像增加了人体前景区域,如图中对人体的脚部提取得更加完整,从而能够提供更加精确的运动特征描述。由于本方法在每帧图像做差分的过程中都使用了形态学去噪,从而避免了噪声的积累,提高了人体感兴趣区域提取的效果。本文将通过对比改进前和改进后的加权累积差分法的行为识别结果来证明改进后的方法能提高行为识别率。
KARCHER秉承全球化的战略思维、精益求精的严谨作风、丰富的制造工艺及以市场为中心和客户至上的运作理念,使公司发展成当今拥有一百个子公司、一万多名员工且年销售额超过20亿欧元的全球清洁业巨型跨国集团。2003年,KARCHER上海分公司正式成立,公司将通过坚持创新和不断研发,源源不绝地为中国家庭用户和企业用户提供最尖端的清洁设备和清洁解决方案。
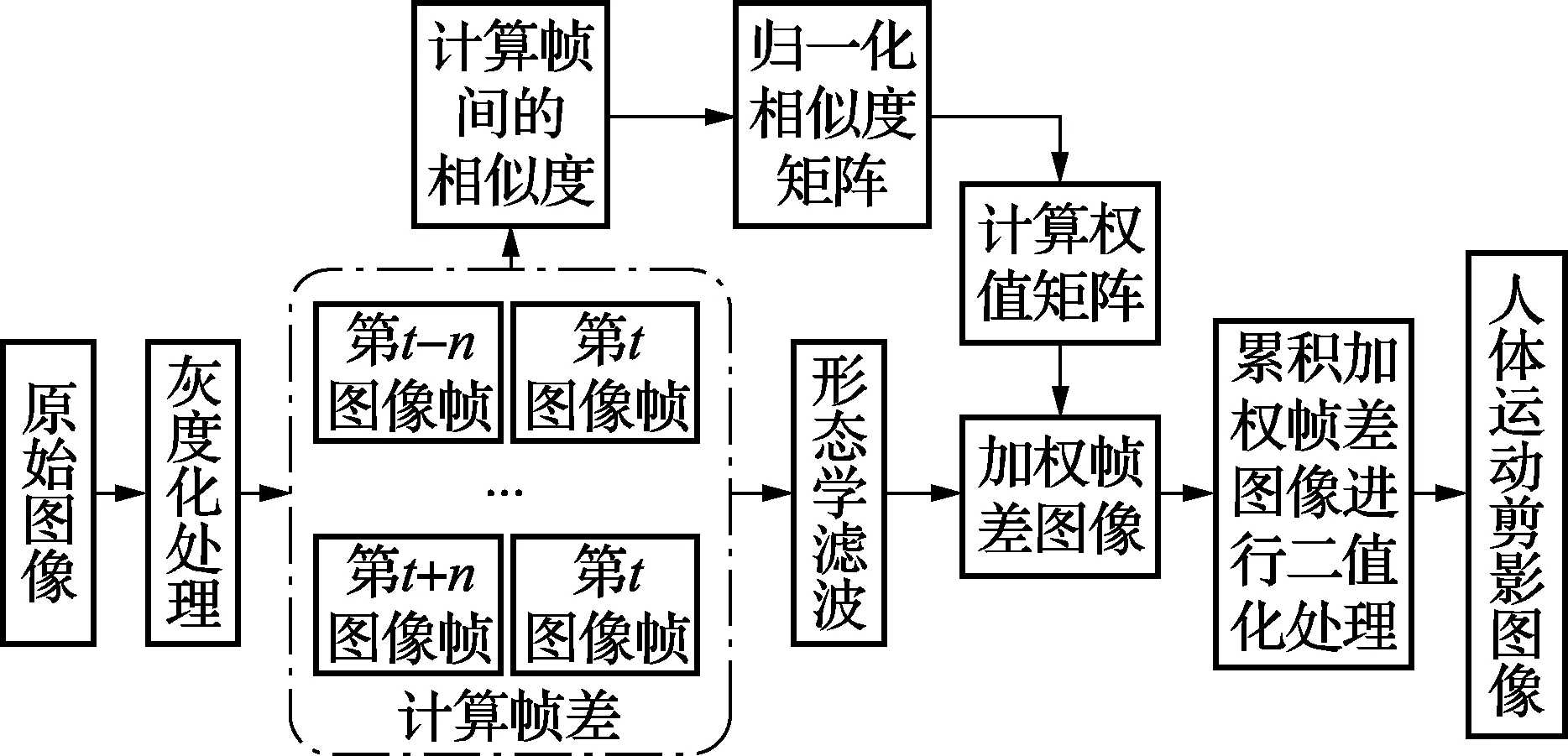
图1 改进的加权累积差分法流程图

图2 改进后的加权累积差分法对比图
2 关键帧模板提取
由于人体行为可以表示为一个连续的动作图像序列,因此如何选取动作图像的关键帧作为人体行为运动的模板,决定着基于模板匹配行为识别方法的性能。常用的关键帧选取方法有两种:一种是根据人的主观经验判断来选取,该方法需要做大量的人工分类和标记工作[8];另一种是用聚类的方法来选取[9],根据不同的图像特征选取合适的关键帧,能充分表示人体的运动特征,但是聚类算法增加了模板设计算法的复杂度。本文提出3种关键帧模板选择方法,通过结合支持向量机对其进行模板匹配识别,并对结果进行对比分析。
通过采用加权累积差分法对魏兹曼科学院行为数据库中的10类行为共90个视频样本进行运动检测,将每个视频样本得到的人体运动剪影序列用于该样本的关键帧的模板选择,下面提供了3种关键帧模板选择方法:
1)模板选择方法1
如图3所示,截取每类行为的每个样本中人体运动剪影的最小外接矩形,然后计算出每个最小外接矩形中前景像素的个数,选取该样本运动前景的二值图像序列中具有前景像素个数最多的图像帧作为该样本的模板。

图3 模板选择方法1得到的关键帧模板
2)模板选择方法2
如图4所示,截取每类行为的每个样本中人体运动剪影的最小外接矩形,计算出最小外接矩形面积,选取该样本运动剪影的二值图像序列中最小外接矩形面积最大的图像帧作为该样本的模板。

图4 模板选择方法2得到的关键帧模板
3)模板选择方法3
如图5所示,将方法1和方法2结合,计算出前景像素个数和最小外接矩形面积,将二者求和,选取该样本运动剪影的二值图像序列中和值最大的图像帧作为该样本的模板。

图5 模板选择方法3得到的关键帧模板
3 分块特征提取
在数字图像处理中,常常利用其统计特性作为特征向量,可以对接近其统计特性的图像进行匹配识别。因此本文通过对提取的关键帧模板进行分块处理,利用每一个分块中像素的统计特征来构建模板的特征向量,用于基于模板匹配的行为识别。提取了时域的图像关键帧之后,接下来要对关键帧的二值图像进行特征提取。分块法是一种常见的二值图像划分方法,文献[10]通过将人体的感兴趣区域按照不同的比例尺度均匀划分为若干个大小相等的分块图层,然后计算每一个块中前景像素占块中总像素的比例作为特征向量用于人体行为识别,取得了良好的识别效果。本文主要采用2种不同的分块方法,然后提取块中像素的统计特征,通过结合支持向量机对分块特征提取的效果进行对比分析。

图6 分块方法流程图
1)分块方法1:如图6所示,对采用上述模板选择方法得到的关键帧模板,求出其最小外接矩形,然后将最小外接矩形均匀划分为10×10的分块,用式(8)计算每一个分块矩形中前景像素所占该块像素数的比例v
(8)
将得到的100个比例值作为该模板的特征向量。这样每个样本的二值图像模板就被量化编码为一个特征向量V=[v1,v2,…,v100]。
2)分块方法2:将最小外接矩形按照5个不同的比例尺寸分别划分为2×2,3×3,4×4,5×5,6×6的均匀大小的分块,然后分别计算这5个不同比例尺寸分块下每个分块的前景像素所占该块像素数的比例,然后将其组成为一个特征向量V=[v1,v2,…,v90]。最后将分块方法1和分块方法2得到的特征向量用支持向量机进行识别。
4 行为识别实验结果
支持向量机(Support Vector Machine,SVM)是由Cortes和Vapnik[11]提出的一种建立在统计学习理论上的一种监督式学习方法,常应用统计分类和回归分析。通过给定一个分别标记为两个不同类别的训练数据集,支持向量机的训练算法可以建立模型用于分配新样本到两个不同的类别,使其成为一个非概率二值线性分类器。
由于本文要处理的人体行为是一个多分类问题,而由于MATLAB自带的支持向量机工具包无法直接处理多分类问题,需要通过构造子分类器来处理多分类,因此本文采用Libsvm类库结合MATLAB作为实验平台来对行为特征进行分类识别。Libsvm类库能对支持向量机参数进行调节,可以采用默认参数来解决分类问题,也可以通过类库提供的函数寻找最优参数。
实验采用3.4 GHz CPU主频,4 Gbyte内存的计算机作为硬件平台,选择C-SVM类型的支持向量机,使用径向基函数核作为核函数,对于支持向量机与核函数的参数根据Libsvm自带的函数进行寻优,多分类采用默认的一对一法。对分块方法1、分块方法2分别与3种模板选择方法相组合所提取的特征进行分类识别,采用网格搜索方法[12]来选取参数c和g。测试方式采用K-折交叉测试,即将初始采样分为K个子样本,一个子样本被用来作为验证集,其余K-1个子样本作为训练集,然后交叉检验K次,直到每个子样本都作为一次验证集,最后平均K次的识别结果,该交叉检测方法能有效避免分类器的欠学习和过学习。图7和图8分别为模板选择方法1与分块方法1和分块方法2组合的识别率。

图7 模板选择方法1与分块方法1组合的识别率

图8 模板选择方法1与分块方法2组合的识别率
识别结果如表1所示,通过使用参数优化的径向基函数核的支持向量机能够取得最高为84.44%的识别率,因此进一步证明支持向量机在处理小样本、非线性、高特征维数分类问题时具有明显的性能优势。
表1 不同模板选择方法和分块方法对应的识别率 %

不同分块方法模板选择方法1模板选择方法2模板选择方法3分块方法1833381117000分块方法2844480007111
另外为了验证改进的加权累积差分法对识别结果的影响,分别选择使用权值经验公式1的加权累积差分法和本文改进的加权累积差分法进行检测,结合关键帧模板选取方法1与分块方法1和分块方法2进行行为识别,实验结果分别如图9和图10所示。
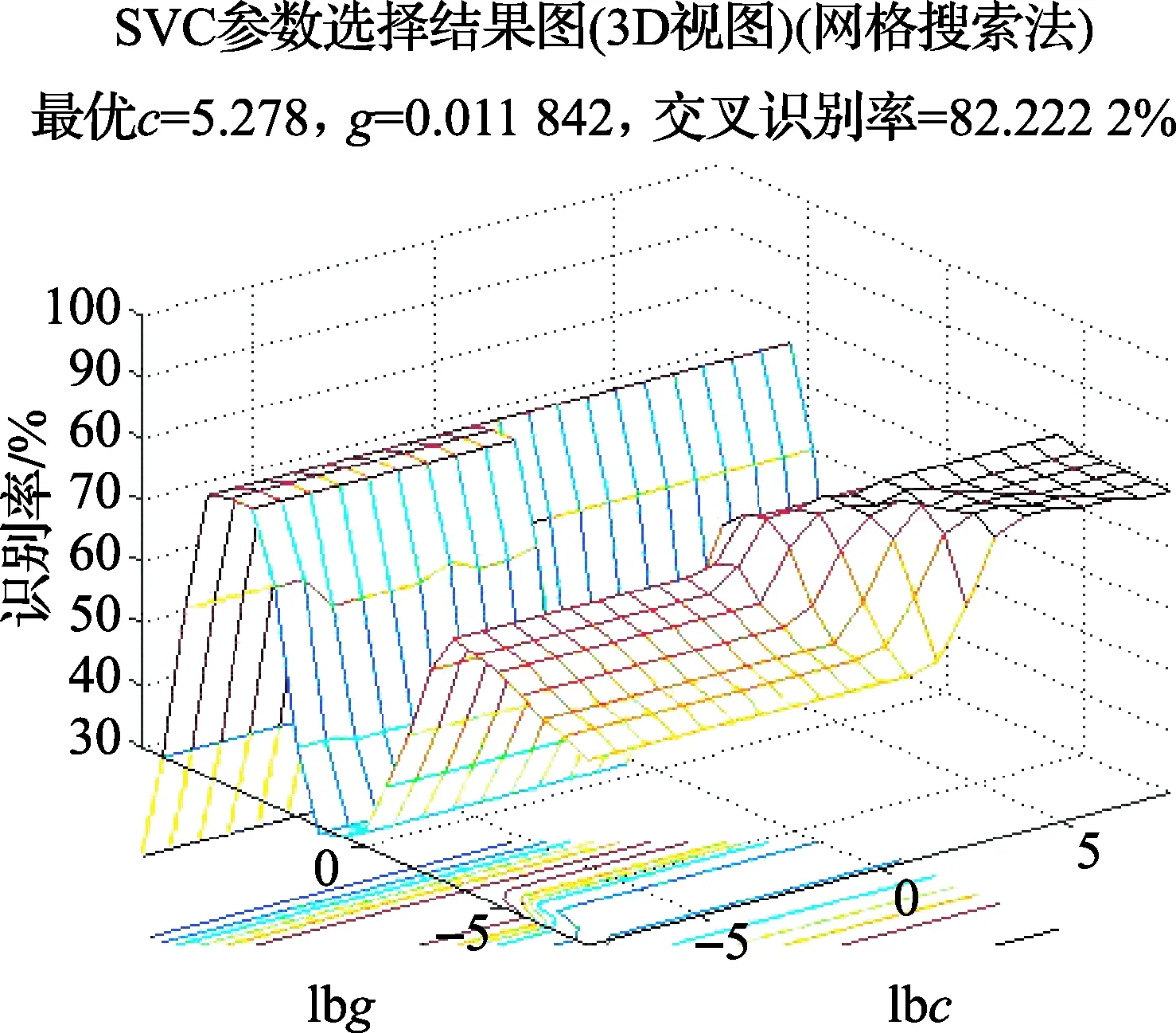
图9 使用权值经验公式1与分块方法1的识别率

图10 使用权值经验公式1与分块方法2的识别率
相对于使用经验公式1进行加权累积检测,使用本文改进的加权累积差分法能够检测到更为完整的人体运动剪影,从表2可以看出使用本文改进的加权累积差分法进行运动检测能提高行为识别率,证明了本方法的有效性。
表2 不同加权累积差分法的识别率 %
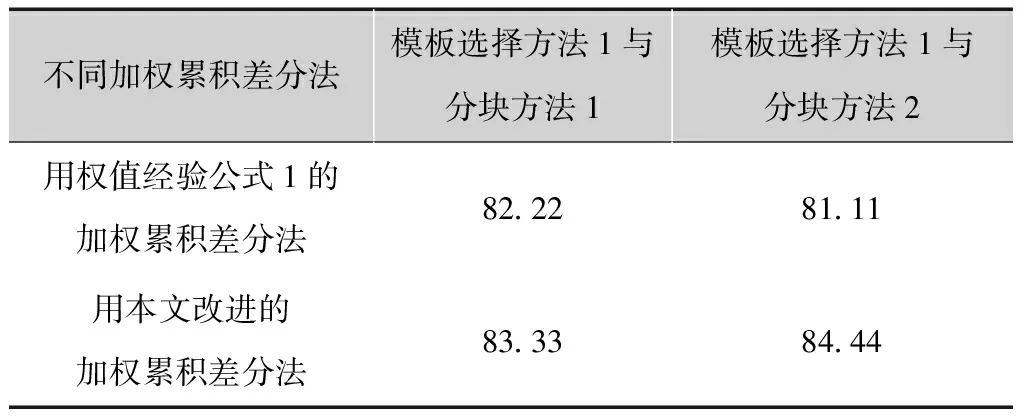
不同加权累积差分法模板选择方法1与分块方法1模板选择方法1与分块方法2用权值经验公式1的加权累积差分法82228111用本文改进的加权累积差分法83338444
5 总结
本文提出了一种改进的加权累积差分法,通过计算当前图像帧与其他不同时刻图像帧的相似性,用于权值计算,使得改进后的算法能提取更加完整的运动前景,并且由于本方法对每帧差分图像都进行了形态学去噪,从而减少了噪声的累积。本文还采用基于图像区域的行为表示与特征提取方法,并对比3种关键帧选择方法与2种分块方法相结合的效果,提取图像每一分块中像素的比例特征来构建行为模板的特征向量,用于人体行为的识别。最后采用径向基函数核的支持向量机用于处理多分类的行为识别问题,并且能取得84.44%的识别率,证明了支持向量机在处理小样本、非线性、高特征维数的人体行为识别任务时具有良好的效果,也表明采用本文改进的加权累积差分法能提高行为识别率。
[1] 伍彩红. 基于视觉的人体行为识别研究[D].武汉:华中师范大学,2011.
[2] HORN B K,SCHUNCK B G. Determining optical flow[EB/OL].[2015-02-28].http://dspace.mit.edu/handle/1721.1/6337.
[3] LIPTON A,FUJIYOSHI H,PATIL R. Moving target classification and tracking from real-time video[C]//Proc. IEEE Workshop on Applications of Computer Vision. Princeton,NJ:IEEE Press,1998:8-14.
[4] COLLNS R,LIPTON A. A system for video surveillance and monitoring: VSAM final report[EB/OL].[2015-02-28].http://www.researchgate.net/publication/245100343_A_system_for_video_surveillance_and_monitoring_VSAM_final_report.
[5] 左风艳,高胜法,韩建宇,等. 基于加权累积差分的运动目标检测与跟踪[J].计算机工程,2009,35(22):159-161.
[6] 黎洪松,李达. 人体运动分析研究的若干新进展[J].模式识别与人工智能,2009,22(1):70-78.
[7] 鲁梅,卢忱,范九伦,等. 一种有效的基于时空信息的视频运动对象分割算法[J].计算机应用研究,2013,30(1):303-306.
[8] 王科俊,吕卓纹,孙国振,等. 基于分层分数条件随机场的行为识别[J].计算机应用,2013,33(4):957-959.
[9] 赵海勇, 刘志镜, 张浩,等. 基于模板匹配的人体日常行为识别[J]. 湖南大学学报:自然科学版, 2011, 38(2): 88-92.
[10] YAMATO J,OHYA J,ISHII K. Recognizing human action in time-sequential images using hidden Markov model[C]//Proc. IEEE Computer Society Conference on Computer Vision and Pattern Recognition,1992. [S.l.]:IEEE Press,1992:379-385.
[11] CORTES C,VAPNIK V. Support-vector networks[J]. Machine Learning,1995,20(3):273-297.
[12] 李琳, 张晓龙. 基于RBF核的SVM学习算法的优化计算[J].计算机工程与应用,2006,42(29):190-192.
Human Behavior Recognition Based on Improved Weighted Accumulative Frame Difference Method
ZHANG Zhixue, CHEN Xi
(NetworkInformationCenter,HenanUniversityofScienceandTechnology,HenanLuoyang471023,China)
For two frame difference method and three frame difference method is difficult to extract the complete motion silhouettes, a method is presented based on improved weighted accumulative frame difference method for human behavior recognition. By using the improved weighted accumulated frame difference method to compute the similarity of frames for adaptive weights change, a relatively complete human movement silhouette can be extracted, and then proposed key frame template selected method and block features extraction method are used to extract behavior features. At last, support vector machine is used to construct classifiers for recognition. Experimental results indicate that this improved weighted accumulative frame difference method can be used to improve human behavior recognition rate.
human behavior recognition; weighted accumulative frame difference method; support vector machine
河南省教育厅自然科学研究项目(12B520019)
TP391.4
A
10.16280/j.videoe.2015.17.029
2015-04-28
【本文献信息】张治学,陈曦.基于改进的加权累积差分法的人体行为识别[J].电视技术,2015,39(17).
张治学(1963— ),实验师,主要研究方向为网络信息通信、图像处理;
陈 曦(1987— ),硕士生,主要研究方向为仿生智能与仿生机器人、数据中心网络、图像处理等。
责任编辑:任健男
