社会保险数据碎片化现状分析*
——基于对A省11种基金的调研
2015-05-04吕天阳邱玉慧杨蕴毅
吕天阳 邱玉慧 杨蕴毅
(1 审计署计算机技术中心,北京,100830;2 黑龙江大学政府管理学院,黑龙江哈尔滨,150080;3 审计署审计科研所,北京,100086)
社会保险数据碎片化现状分析*
——基于对A省11种基金的调研
吕天阳1、3邱玉慧2杨蕴毅1
(1 审计署计算机技术中心,北京,100830;2 黑龙江大学政府管理学院,黑龙江哈尔滨,150080;3 审计署审计科研所,北京,100086)
社会保险管理信息系统多年来积累了大量电子数据。这些数据已经成为社会保险制度建设的宝贵财富,其集中存储和管理具有重要意义,也是社保信息化建设的目标之一。但是,对A省11种社会保险数据的管理现状的调研表明:数据碎片化情况严重,部分险种碎片化的比例高达90.91%,严重制约了以保险关系转移接续为代表的社保公共服务水平的提高。
社会保险; 电子数据; 碎片化; 人员转移
一、背景
作为支撑中国社会保险体制建设的重要基础设施,[1]社会保险管理信息系统经过近20年的建设,已积累了大量的电子数据。这些数据详尽地刻画了各险种参保人或参保企业的每一条缴费或支付信息。从粒度上看,是当前最细致、全面的数据;既是经办各类社保业务的依据,也是相关统计数据的本源,因此具有极强的权威性和研究价值。[2]
社会保险数据的集中存储与管理对于减少信息化建设的重复投资、减少“信息孤岛”、提高社会保险公共服务水平具有核心意义。数据集中也是满足企业职工基本养老保险省级统筹六项标准之一“使用统一的应用系统”的重要基础。因此,自“金保”工程实施以来,实现社保数据集中就成为社保信息化建设的重要目标之一,并在多份信息化建设的纲领性文件中得到体现,包括《人力资源和社会保障信息化建设“十二五”规划》(人社部发〔2011〕99号文)、《劳动和社会保障信息化建设“十一五”规划》(劳社部发〔2007〕15号)等。
但是,我国各地域、各险种的社会保险数据仍然面临着存储位置分散、管理机构众多、管理水平参差不齐等问题。学术界一般将社会保障领域中的类似问题称为“碎片化”问题,用以描述社保制度中的各种差异性。[3]一般认为碎片化不利于制度的公平、统一,不利于参保人员的自由流动。[3][4]
相关学者虽然已经对社会保险政策、管理碎片化的根源、现状和弊端开展了较为丰富的研究,[3][5]但是对于社会保险信息化建设碎片化的分析仍然稀少。尤其是对数据管理碎片化的现状,或是囿于条件无法研究,或是视为技术细节不够关注。少量相关研究多为社保一线人员的工作感悟。[2][6][7]人保部等各方公布的资料中也缺乏对社会保险数据实际管理现状的分析资料,即:相关机构尚未给出某种社会保险数据目前分散在多少县、市的哪些机构。
可见,研究者和监管部门虽然认识到社保数据的重要意义,[2][8]但是对于社会保险数据碎片化现状的分析仍处于稀缺状态。这不利于研究者和相关部门提出有针对性的政策建议。例如,研究者虽然普遍认识到信息化建设对于社保关系转移的重要意义,[9][10]但是却很难具体指出当前的社保信息系统难以实现人员转移的症结所在。
为此,本文对2012年A省近70个县的社会保险数据的碎片化现状进行了调研,调研范围涵盖11种基金数据,包括:城镇企业职工基本养老保险、城镇居民社会养老保险、新型农村社会养老保险、机关事业单位养老保险、被征地农民养老保险、城镇职工基本医疗保险、城镇居民基本医疗保险、新型农村合作医疗保险、失业保险、工伤保险、生育保险。这些基金代表了当前社会保险的主要基金类别。按基金类别统计,调查结果中有效的县数占全部县的比例最高为66.15%、最低为12.31%,部分所占比例较小的险种是由于A省内开展该险种的地区较少。总的看,调研结果具有一定的代表性。
对调查结果的汇总分析表明:社会保险数据管理的碎片化程度已经超出预期,部分险种高达90.91%的数据由所在县分散管理,而由省级机构集中管理的比例低至0%,从而形成了最细小且高度分散的数据碎片。鉴于电子数据在社会保险体制中的基础性作用,数据的高度碎片化的影响将辐射到方方面面,本文着重分析了数据碎片化对社会保险关系转移接续的影响。
二、数据碎片化现状调研
在设计调查表时,需要尽可能体现影响数据集中管理的多种因素,从而为后期多种角度的分析奠定基础。参照前期研究成果,[8]我们分析了8种因素:政策、险种、业务环节、管理部门、统筹层次、设计标准、数据库和数据存储位置对数据碎片化的影响,概略的分析参见表1。

表1 影响社会保险数据碎片化的要素分析
说明:各因素的影响程度分为四级:严重影响(标为●)、一般性影响(标为◎)、影响轻微(标为⊙)、几无影响(标为○)。
因此,我们从表1提炼出四种影响数据集中管理程度的主要因素,并在调查表中加以体现。如前所述,数据存储位置是数据碎片化现状的直接体现,其他三个因素为险种、业务环节、统筹层次。值得注意的是:这些因素对社保数据集中情况的影响将随着时间演进和地域差异而变化,所以调查表中还应体现地域和时间两个因素。
表2给出了数据碎片化情况调查表的局部表样。概要说明如下:表中第1-3列可以具体定位到全国任一省、市、县,便于开展全国范围的调查。第4列反映了数据管理情况的历时性变动,时间范围可酌情确定,本次调查的时间点为2012年。第5-9列反映一个险种的数据管理情况,其他10个险种的调查项与之类似。其中,第5列为当地当年该险种统筹层次情况,分省、市、县/区三级统筹填列;该项与第1-3列一起可反映行政区划与统筹级次间的差异,例如某县A险种为省级统筹、B险种为县区级统筹。第6-7列、第8-9列分别按照管理环节反映征缴和拨付数据*支付数据中包括个人账户数据。如果某一基金存在个人账户数据,则待遇发放通常与参保人员的个人账户信息有关,或是核算应发待遇、或是冲减个人账户金额。而在征缴过程中,这种关联相对弱化;很多社保信息系统仅在需要时根据各月缴费明细核算个账总额,而不实际记录。因此,调查中将个人账户数据与支付数据合并统计。这种处理方法虽然不能涵盖某些特殊情况,却能在保证总体准确程度的前提下,减小数据采集人员的工作量。的存储位置;如果数据管理情况在年中某月发生变化,则可以通过第7、第9列体现,例如2012年7月征缴数据的管理情况发生变化,则记录为201207。表2仅给出了包括地域、时间和机关事业养老保险部分的调查表局部,完整的调查表包括第1-4列的地域和时间的险种间的公共信息项,以及每个险种5列的调查项,共计59列。
总的看,该调查表已经能够反映不同地域、时间、险种、统筹层次、业务环节条件下社会保险数据的碎片化现状,形成了较好的调研基础。
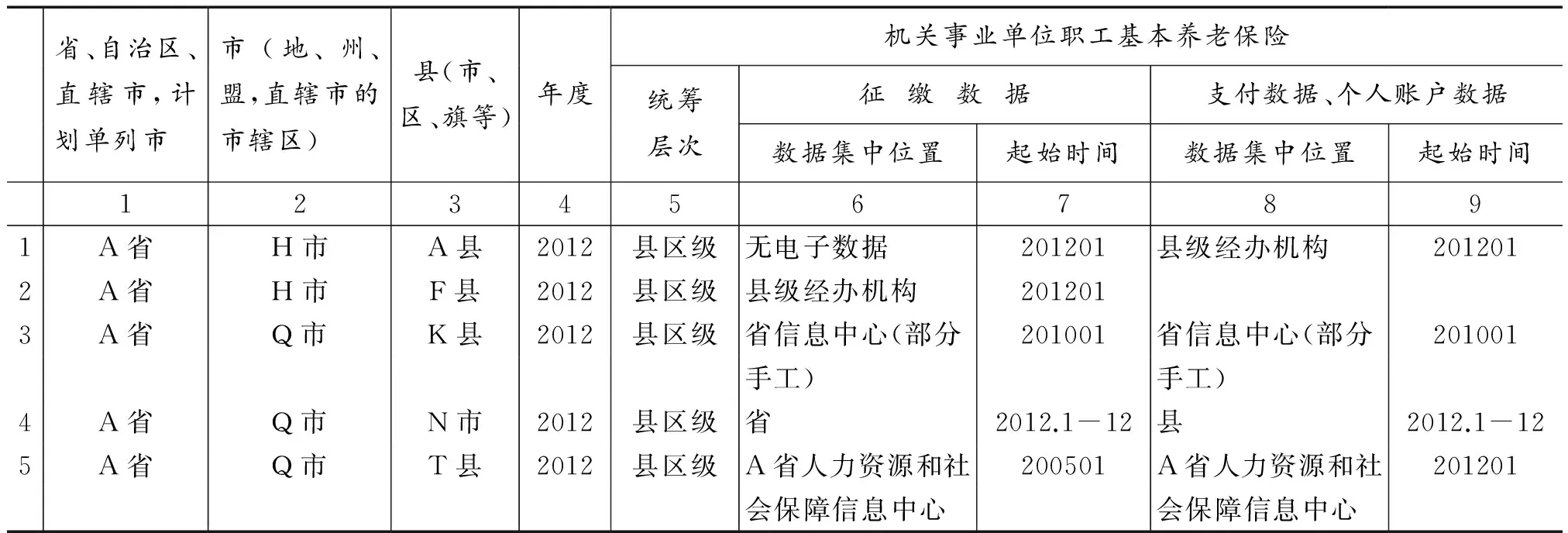
表2 《社会保险数据碎片化现状调查表(局部)》示例及填报实例
三、A省数据集中现状的实证分析
在调研过程中,我们通过各级审计机关将表2所示的调查表发放给A省近70个县的11种社会保险基金的经办机构,并要求各经办机构返回调查结果时加盖本单位公章。这一措施能够有效地提高调查结果的准确性。由于很多机构经办多种社会保险,因此实际累计发放了160多份调查表,经确认填回有效的调查表数量为84份。无效的调查表或是因为未加盖公章、或是因为填报质量过低,而不具分析价值。
表2给出了部分原始填报数据的实例截图。由表可见,所获得的各地社会保险数据的管理情况复杂多样:存在无电子数据的情况,如第1行A县填报结果;存在对同一存储位置称谓不同的情况,如第3-5行第6列所指均为省信息中心;存在征缴、支付数据存储位置不一致的情况,如第4行N市(县级市)分别在省和县管理;存在填报结果缺失的情况,如第2行发放数据的存储位置缺失,虽然很多情况下是由于该经办机构并不管理相应的险种,但也确实存在填报疏忽的情况。由于社保经办人员填报调查表的方式多样,最终结果均依靠人工逐条核对、确定其存储位置和管理层级。
对有效调查表的详细汇总结果参见表3。表3以不同的统筹层次为主要划分依据,统计了某一险种分别由省级机构管理(简称省管)、市级机构管理(简称市管)、县级机构管理(简称县管)的有效县数。很明显,县管数据意味着数据的高度分散,成为最差的碎片化情况。
由于部分险种的数据存储位置未作填报,同时部分险种在很多地区尚未开展,因此各险种有效县的个数变化很大。有效县数占全部县数的比例最高为城镇企业职工基本养老保险和失业保险的66.15%,最低为被征地农民养老保险的12.31%。总的看,调研结果具备了一定的代表性和分析价值。
表3表明:统筹级次对数据的碎片化现状有较强的影响。例如城镇企业职工基本养老保险、居民养老保险等主要为省级统筹,因此较大比例的县的数据由省或市级机构集中管理;而对于职工医疗、居民医疗等主要为县区级统筹的险种,较大比例的县的数据为本县自存自管,较为分散。统筹层次不同的两个险种的征缴及发放数据存储位置的对比效果图参见图1。这就从电子数据集中管理的层面说明了尽快提高统筹层次[4]的另一个重要意义。
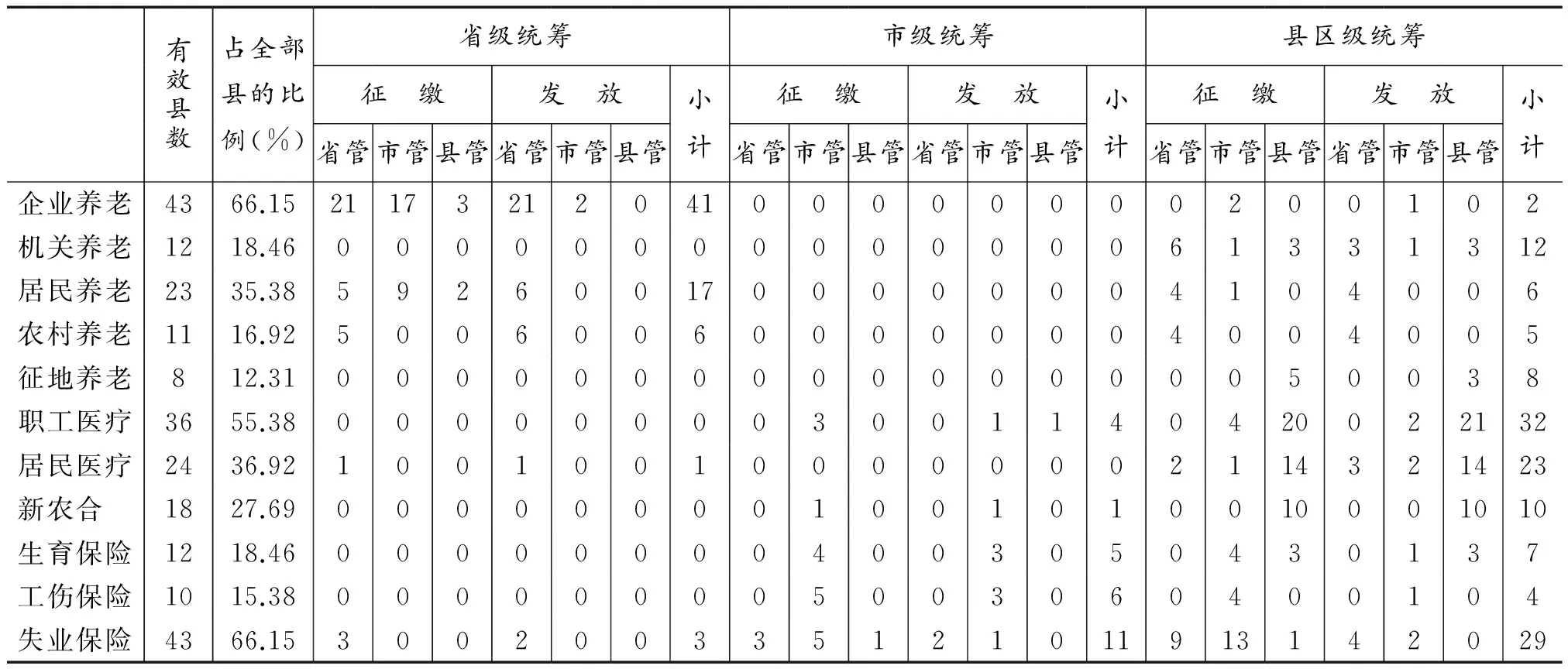
表3 各类基金数据集中管理位置统计*由于部分县未完整填报缴费或支付数据的存储位置,表中“小计”与征缴、支付数据对应的省管、市管、县管县数的累加和不一定相等。

图1 统筹层次不同的两个险种的征缴及发放数据存储位置的对比
以表3统计结果为基础,表4和图2给出了11个险种的数据分别由省、市、县管理的县的数量及其占有效县数的比例。一般而言,数据由省集中管理为最佳情况,由所在县自存自管为最差的碎片化情况。后者也不符合社会保险信息化建设的目标。
由表4和图2可见:A省各类基金的数据普遍存在由所在县自存自管的现象,部分险种的比例高达90.91%,部分险种由省集中管理的比例低至0%。除了城镇企业职工基本养老保险、城镇居民社会养老保险、机关事业单位养老保险、新型农村基本养老保险和失业保险的比例高于50%,城镇居民基本医疗保险比例为18%之外,其他5种基金的数据由省级机构管理的比例均为0%。这些低比例的基金的数据大多由所在县自存自管,少量由所属市管理。
而从全国范围看,A省是实现企业职工基本养老保险信息系统和数据省级统一管理的少数省份之一,这一点从企业职工基本养老保险数据集中管理的情况可以得到佐证。因此其数据集中管理的情况在全国各省中应属较好。据此可以合理推断,除少数直辖市外,其他省的数据管理情况亦不乐观。
调研结果表明:社会保险数据的碎片化情况不容乐观,部分险种数据的碎片化管理的情况已经超出了主管部门和社会的预期,形成大量的“信息孤岛”。
考虑到社会保险的信息化建设在社会保障信息化建设中处于领先水平。以此推知,社会保障信息化建设的现有状态不能满足我国社会保障体制建设的需要,与提高公共服务水平的目标并不相称。
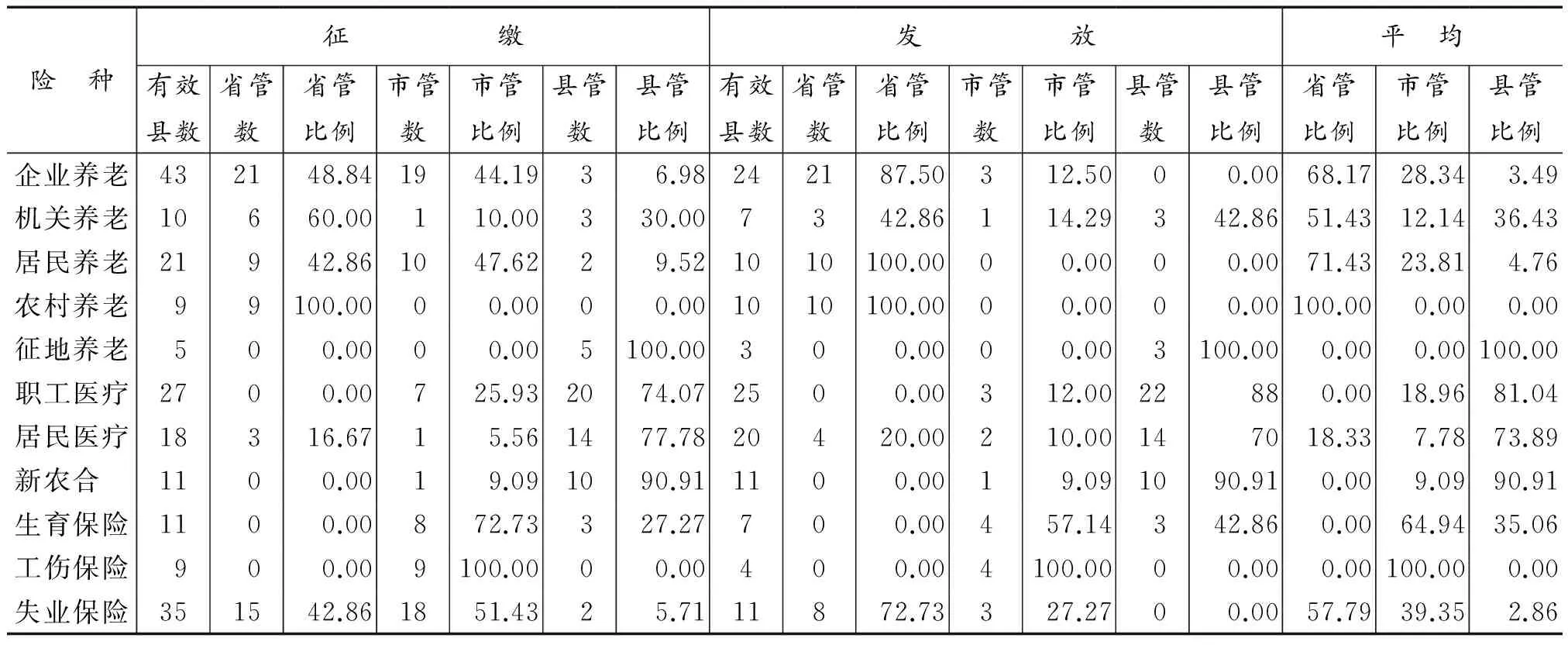
表4 不同险种的数据由省、市、县管理的县的数量及其占有效县数的比例 单位:%
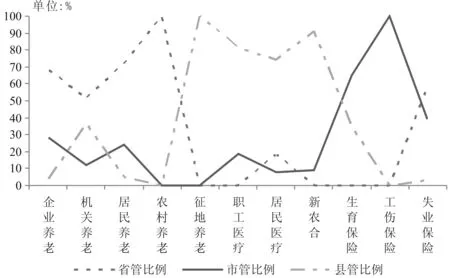
图2 不同险种由省、市、县管理的县的数量占有效县数的比例
四、社会保险数据碎片化的影响
社会保险电子数据是办理各类社会保险业务的基础。鉴于其基础性地位,社保数据当前过于碎片化的现状将影响到社会保险体制的方方面面。例如异地重复参保、不同险种间选择性申报缴费基数等重要管理问题,都需要对不同地域、不同险种的数据开展集中分析才能得到遏制。
本节以城镇企业职工基本养老保险关系转移接续问题为具体实例,分析数据碎片化对提高社会保险公共服务水平的影响。养老保险关系转移接续是构建全国统一劳动力市场,[4]维护参保人权益的重要课题。[11][12]很多学者都指出了信息系统建设对于养老保险关系转移接续的重要意义。[9][10]但是限于研究资料的匮乏,研究者尚未清晰指明:为何当前的社保信息化建设不能很好地支撑养老关系的转移,其困难究竟源自何处?
从信息技术角度看,养老关系转移的本质是数据交换问题,所交换的即是参保人的缴费个人账户信息。因此,当转移人员转入地与转出地的数据为某一机构集中管理时,这一过程所涉及的数据交换可以由一个简单的数据库操作完成。但是,当转入地与转出地的数据分散管理时,数据交换过程就涉及不同信息系统间的互联互通、信息格式的异构化等复杂的技术问题。其中,不同信息系统间的互联可以通过政务网的建设得到解决,但是信息格式的异构化问题则既是信息技术的难点问题,也是社会保险体制碎片化不可避免的副产品。[8]简单地说,信息的异构化是指:在所描述的客观对象相同的前提下,其信息的记录方式所存在的差异性。表5给出了两个分散管理的基本养老保险信息系统中在职个人账户信息的记录格式差异的实例;可以看出两者的明显差异,左侧的个人账户信息详细记录了个人账户中单位划入与个人缴纳部分的本金利息,右侧的则补充了做实金额、利息等信息。
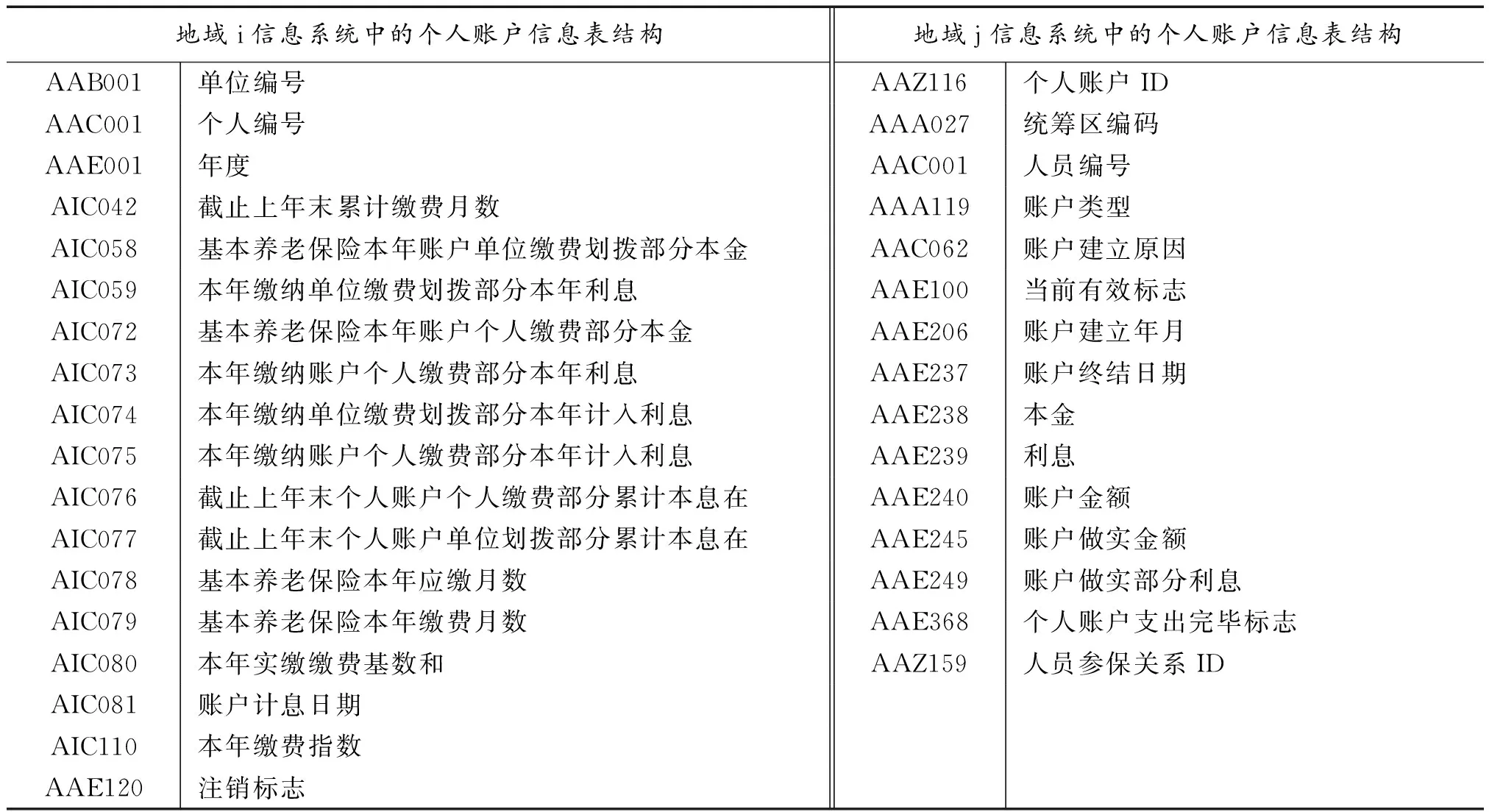
表5 两个分散管理的基本养老保险信息系统中在职个人账户信息的记录格式
可见,当数据因分散管理而呈现碎片化时,不同管理者所记录的个人账户信息的异构性将不可避免。此时,如果缺乏一种标准规范,转出地的数据将很难转换为转入地的信息样式。这一难度大体源自两个方面:其一,转入地与转出地个人账户记账、计息的规定和管理方式存在差异,这从根本上决定了信息的转换必然带来信息的损失;其二,转入地与转出地之间互不了解对方的信息格式,也不一定了解某一具体信息的实际含义。例如“本年个人缴费总额”这一看似明晰的信息,一些社保经办机构就以“业务年度”而非自然年的1-12月进行核算,此时其他社保经办机构可能并不认同。这一实例既体现了业务经办的差异,也体现了确定信息实际含义的复杂性。
结合前文对A省的实际调研结果,可以看到即使少数实现了企业职工基本养老保险信息系统和数据省级统一管理的省份,也有33.85%的数据由所在县分散管理。因此,即使是省内的关系转移也必然存在转移信息自动化交换的困难。我国共有3000多个行政区,以A省的情况推算,全国性关系转移所面临的数据分散、异构的困难将更为严重。
这就从数据碎片化的程度解释了社保信息化建设不能很好支撑养老关系转移的客观原因。这个看似属于细枝末节的技术问题已经开始制约我国宏大的社会保险体制的建设。值得注意的是,当前的数据之所以过于分散管理,其实质仍然源于社会保险体制的碎片化。在各地社保各管一摊、政出多门的现状下,再先进的信息技术也无力从根本上解决这一问题。
该问题的解决将依赖于社会保险体制研究者、设计者和执行者在清楚认清当前社会保险数据高度碎片化现状的前提下,从体制建设层面就开始兼顾社会保险信息化基础设施的重要性,开展多种学科交叉的分析。针对当前数据已经分散管理的客观情况,除在政策层面加紧开展提高统筹层次的工作之外,在信息技术层面:一方面需要以较高的成本实现历史数据的迁移和集中,全国存量数据的去碎片化处理成本可能将以百亿计;另一方面需要对新建设的险种或已有险种的新数据抓紧制定并切实贯彻统一的规范,逐步实现增量数据的集中管理。
[1]郑功成:《中国社会保障改革与发展战略》,96~97页,北京,人民出版社,2011。
[2]侯绍军:《数据:社保的核心资产》,载《中国社会保障》,2010(10)。
[3]郑秉文:《中国社会保险“碎片化制度”危害与“碎片化冲动”探源》,载《社会保障研究》,2009(1)。
[4]郑功成:《中国社会保障30年》,82~86页,北京,人民出版社,2008。
[5]郑秉文:《“碎片化”或“大一统”》,载《中国社会科学院报》,2009-04-30。
[6]聂明隽:《社会保险数据管理任重而道远》,载《中国劳动保障报》,2010-10-19。
[7]赵学谦:《论加快推进社会保险信息化工作的重要意义》,载《劳动保障世界》,2009(12)。
[8]吕天阳、杨蕴毅、邱玉慧、黄少滨:《社会保险信息系统差异性分析》,载《社会保障研究》,2012(6)。
[9]褚福灵:《职工基本养老保险关系转移现状的思考》,载《社会保障研究》, 2013(1)。
[10]赵曼、刘鑫宏:《中国农民工养老保险转移的制度安排》,载《经济管理》,2009(8)。
[11]刘传江、程建林:《养老保险“便携性损失”与农民工养老保障制度研究》,载《中国人口科学》, 2008(4)。
[12]杨宜勇、谭永生:《全国统一社会保险关系接续研究》,载 《宏观经济研究》,2008(4)。
(责任编辑:H)
The Analysis of Fragmentation of Digital Data of Social Insurance—Based on the Survey of 11 Types of Social Insurance of A Province
LU Tianyang QIU Yuhui YANG Yunyi
With the construction of information management system of social insurance,large amount of digital data has been accumulated,which is one of the most cherished treasures of Chinese social insurance system.Centralized storage and management of social insurance data are of great importance in information construction.However,there still lack researches of the fragmentation situation of social insurance data.The paper carries out the investigation of the fragmentation of 11 types of social insurance of A Province .Analysis result shows that the fragmentation situation of data is very serious.For instance,90.91% data of one insurance are segmented and managed by different counties.The fragmentation situation has caused severe damages to the improvement of public service level of social insurance,especially the transfer and sequence of basic endowment insurance.
social insurance,digital data,fragmentation,transfer and sequence
*本文为国家自然科学基金面上项目“基于社会计算的社会保障国家审计政策功能研究”(71272216),国家社科基金重大项目“中国特色社会主义政治发展道路的理论阐释与实践路径研究”(12&ZD058),教育部人文社会科学研究规划青年基金项目“代际正义视角下中国基本养老保险制度研究”(13YJCZH143),黑龙江省哲学社会科学研究项目“代际正义视角下中国城镇企业职工基本养老保险绩效审计研究”(12D038)的阶段性研究成果。
