图像并行集群复原校正方法研究
2015-04-30华夏等
华夏等
摘要摘要:论述了图像校正算法的并行集群实现方法。针对图像复原问题,对复原算法结构与流程的并行处理进行研究,提出了整体数据传输、按行分片计算复原的并行处理方法。该方法在基于MPI的计算机并行集群系统中的8个计算节点上通过了测试,给出了集群校正实验结果和MPI并行计算时空图。实验结果表明,基于集群计算的并行复原方法十分有效,可缩短计算时间,提高计算效率。
关键词关键词:图像复原;并行处理;MPI;集群计算
DOIDOI:10.11907/rjdk.151061
中图分类号:TP317.4
文献标识码:A文章编号
文章编号:16727800(2015)004014203
0引言
退化图像的快速复原是成像探测研究的重要课题。传统的复原方法是在目标图像点扩展函数确定的情况下,用去卷积的方法来实现图像复原。然而,在复杂条件下,点扩展函数很难测定与预先获得[1]。基于极大似然估计准则的正则化图像复原算法利用序列多帧退化图像数据,采用极大似然估计方法来寻找最相似于退化图像的点扩展函数和目标图像,从概率意义上达到极大程度恢复图像的目的[2,3]。由于该复原算法采用迭代的方式,因此计算量大,计算速度较慢。为了缩短计算时间,加快计算速度,人们对算法的结构优化和计算方法进行了研究[4],但要将计算负担降低一半以上仍存在困难。因此,对该算法采用高性能并行化处理值得深入研究。
高性能计算技术在国内外受到高度重视,其在科学研究、工程技术以及军事技术方面的应用已取得了巨大成果。目前,利用相对廉价的微机和高速网络构建高性能的并行与分布式集群计算系统来完成高性能计算任务已越来越普遍[5]。集群计算在图像校正方面有着广阔的应用前景。建立算法并行模型的问题即是解决算法如何并行的问题,如何把单机运行的图像处理算法改造成在并行集群上运行的算法。并行计算的目的是充分利用计算集群系统资源,缩短计算时间,提高计算效率。并行计算的实现方法是将一个大计算量的计算任务分解成多个子任务,分配给各个节点进行并行计算。由于计算上的内在关联性,计算节点之间必须进行数据交换,然而图像复原校正处理中图像的数据量通常较大,所以并行计算不可避免地会引入额外的节点间的通信时间。额外的通信时间过大,将降低并行计算的运行效率。如果通信时间大于算法并行计算节省的计算时间,并行集群计算系统运行速度将低于一台计算机的运行速度,并行计算则失去了意义。因此,建立算法的并行模型,需要确定算法哪一部分运算需要进行并行计算,哪一部分不并行,如何并行处理直接决定着并行计算的运行效率。
建立算法并行模型过程分为3步:①对算法模型与流程进行分析,找出算法中运算量最大的几个计算量或步骤,也即需要并行计算的部分;②对需要并行计算的计算量进行分析,找出并行实现的方法;③分析并行计算的可行性,如果计算耗时远大于并行计算需要的额外通信耗时,并行计算则是高效和可行的;如果计算耗时小于额外通信耗时,或者与通信耗时相当,并行计算则是低效的。
MPI(Message Passing Interface)是目前比较流行的并行计算开发环境之一。MPI是一个并行计算消息传递接口标准,其现已成为被产业界广泛支持的并行计算标准,具有可移植性,因此选择MPI来构建并行校正计算系统。
1基于空间域按行分片的并行计算处理方法
流场点扩展函数具有衰减性质,有意义的支撑区域(其值大于零)集中在峰值附近[6]。点扩展函数的支撑区域一般比图像的支撑区域小得多。因此,对点扩展函数而言,只需要估计点扩展函数空间支撑域范围内的有效值。
由复原校正算法可知,若图像大小为N×N,点扩展函数支撑域为M×M,则在每次迭代中,计算点扩展函数和目标图像的加法和乘法运算量正比于N2M2,在图像空间域进行计算时,计算工作量较大,图像恢复较慢。为了缩短计算时间,加快计算速度,有必要对基于EM计算的最大似然估计复原校正算法(简称EM算法)进行并行化处理。
从算法流程可知,EM算法是一个多次迭代过程,每一次迭代过程都包含多个计算步骤。因此没有必要把每一个计算步骤都并行化,因为并不是每个计算步骤都需要并行化,对计算量过小的计算步骤并行化,引入的通信时间会大于并行计算节省的计算时间,反而会降低算法运行速度。所以,只需选取计算量较大的计算步骤进行并行化,计算量小的部分在根节点上单机计算,在实现并行计算的同时达到减少节点间通信量的目的。
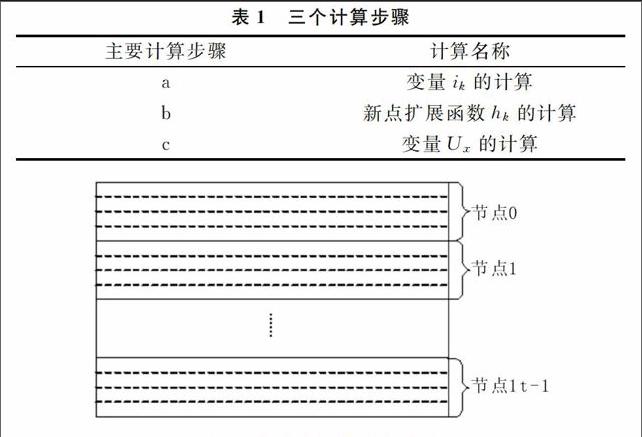
对单机上运行的串行EM算法每一次迭代过程中的各个步骤计算时间进行了记录。从单机运行的时间结果来看,一次迭代过程中a、b、c三个计算步骤(见表1)用时占一次迭代计算总时间的99%以上,只要把这三个计算步骤进行并行化,则可以大大降低计算耗时。其它几个步骤计算量较低,没必要分配到各节点进行并行计算,否则节点间的数据通信和计算同步需要的时间可能会大于3ms,反而降低计算速度。所以,现将a、b、c三个计算步骤分配到各个节点上进行并行计算,其它步骤在根节点(进程号为0的节点)上用单机计算。
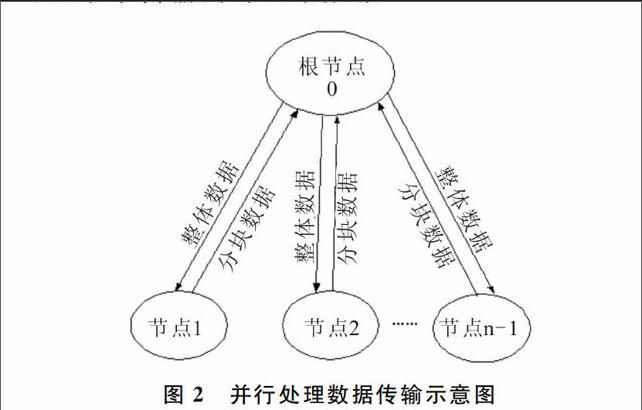
并行计算即把计算任务分配到各个计算节点上,a、b、c三个计算步骤需并行处理的计算值ik、hk及Ux,均可看成具有M行和N列的二维图像(见图1)。由于每一块的计算涉及到整体图像数据,所以提出整体数据传输、分块计算复原的并行处理方法:即将整个图像数据传输到每一个计算节点上,在每一个节点上计算每一块的数据值,然后传回到根节点上,再整体传输到各节点上进行分块计算,直至计算结束为止。采用的分配方法是细粒度任务划分方法,把图像分成若干个子块图像并按行存放,为便于分片并行计算处理,按行对图像进行分配计算。把整个图像根据并行计算节点数量按行平均分为n个子块图像,计算任务分配如图1所示。按行分片,每个子块图像的计算在同一个计算节点上进行,不同子块图像计算在不同计算节点上进行。具体方法如图2所示。
2基于MPI环境的并行计算与实现
利用内部局域网把各台独立的计算机连接起来组成一个并行计算集群。集群系统采用并行计算方法,把图像处理中计算量大的计算任务分解成各个子任务,然后分配给各个节点进行并行计算。由于计算上的内在关联性,节点之间必然存在数据交换,而由于图像的数据量相当大,内部网络传输数据的速率是整个系统计算速度的瓶颈。尽量高的传输带宽和尽量低的传输延时 (Latency)是图像处理集群系统高并行效率的基本要求[7]。因此,采用千兆光纤网络来传输内部网络数据。
MPI并行计算进程必须由mpirun命令启动[7],mpirun命令只支持以命令提示符的方式启动并行计算进程。因此,无法在软件的主界面中调用MPI函数,只能通过命令行调用mpirun命令启动并行计算进程。主程序和MPI并行计算程序是两个独立的进程,各个进程的存储区独立,进程与进程之间不能直接传递数据。并行计算输入参数和输入图像的传递利用共享内存映射方法实现。建立共享内存映射即建立一段共享内存,该内存不属于某个进程独有,每个进程都可以通过这段内存的名字来访问它。在MFC中CreateFileMapping函数可用来建立一段内存映射。主进程创建了共享内存以后,MPI进程和主进程都可以使用这段内存空间,主进程首先把并行计算需要的参数和输入图像都拷贝到共享内存空间,然后启动MPI进程进行并行计算,MPI进程计算完毕后仍然把计算结果图像拷贝到这段共享内存,主程序读取共享内存后将其释放。通过这个过程完成了算法的MPI并行计算。
Windows提供了程序调用命令,可以在一个进程中创建另一个进程。程序调用命令为:int system( const char *command ),其中command即为要调用的程序及参数。在软件系统中编制程序代码启动MPI命令,调用并行计算命令,启动并行程序。EM算法的MPI并行程序名称设为EMRec_MPI.exe,该文件和应用程序存放在一个目录下,用GetModuleFileName命令获得当前应用程序所在路径,即可得到并行程序所在路径。在mpirun命令中,使用了-np与-localroot参数。变量nodeNum指定参与并行计算节点的数目,该变量由用户通过校正软件人机交互界面设置。现使用默认节点设置,参与计算的节点在图像校正软件系统启动之前配置完成。
图像复原软件系统主程序进程和图像恢复并行计算程序进程是两个独立的进程,各个进程的存储区独立,进程和进程之间不能直接通过变量或内存地址的方式传递数据。用共享内存文件映射的方法实现主进程和并行计算进程间的数据传递。共享内存文件由某一个进程创建,该文件映射对象的内容能够为多个其它进程所映射,这些进程共享的是物理存储器的同一个页面。因此,当一个进程将数据写入此共享文件映射对象的内容时,其它进程可以立即获取数据变更情况。
首先,主进程通过CreateFileMapping()函数创建一个内存映射文件对象,并把该文件对象命名为EM_rec_mem,在并行计算进程中,即可通过这个名字找到该内存文件。如果创建成功,则通过MapViewOfFile()函数将此文件映射对象的视图映射到地址空间,同时得到此映射视图的首地址。首先,计算需要创建的内存文件大小。其中40个为头信息,并保存算法的输入参数等信息。内存文件创建成功以后,把输入数据,包括图像恢复参数、输入图像帧数,扩展函数行、列数,迭代次数、多帧输入图像数据等,写入共享文件内存。完成了初始化工作,即可调用并行计算程序。并行计算进程由mpirun命令启动以后,首先用CreateFileMapping()函数创建一个名称为EM_rec_mem的内存文件,然后获得输入数据,并把输入数据用MPI_Bcast的方法广播到各个计算节点上的进程,开始并行计算。并行计算完成后把处理结果写入共享内存文件,完成算法的MPI并行计算。
3实验结果与分析
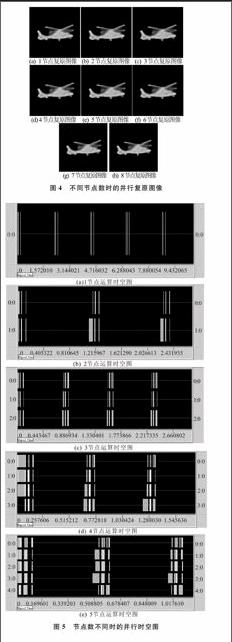
实验以空间域按行分片复原算法为基础,引入并行计算,用VC6.0编程进行实现。将并行系统校正方法在计算机并行集群系统(微机主要配置均为CPU Intel Pentium IV,2.66 GHz,1024 MB内存)上运行。以红外直升机目标图像的并行集群校正为例,下面给出在该并行集群系统运行通过的两个并行校正实验结果。3帧退化图像如图3所示,为便于对比,分别采用1~8个节点进行并行复原校正,其中迭代次数均为80次。不同节点复原图像如图4所示,当节点数设置不同时,由从输入相同的模糊图像中复原出来的结果图像相同,说明各个节点并不改变算法参数和图像数据,只参与并行计算,以提高计算效率。不同节点数耗费时间对比见表2。由表2可知,随着节点数增加,计算耗时几乎成比例地减少,这是由于各个节点平均分担了计算任务。不同节点数并行运算的时空图如图5所示,其中横向细实线宽度表示计算所用时间,横向块宽度表示数据传输及广播所用时间。分析时空图可知,节点之间数据通信所耗费的时间相对于整个计算时间较短。但随着节点数目增加,通信量增多,数据通信耗费时间增加。因此,节点数并不是越多越好,当节点数目达到一定数量(8节点)时,复原算法耗费时间将达到稳定。
4结语
针对图像校正算法迭代次数多、耗时长等问题,为提高计算效率,本文引入了并行集群计算。对复原校正算法的结构与流程进行了研究,提出了整体数据传输、按行分片计算复原的并行处理方法,有效解决了校正算法的并行集群处理问题。并行集群实验计算结果表明,本文提出的并行方法十分有效,可缩短计算时间,提高计算效率。通过研究了解图像处理算法MPI并行化方法,实现了基于MPI的并行计算集群,解决了MPI并行程序与Windows窗口的集成连接问题,建立了一个并行计算图像校正软件平台。由此证实MPI并行计算在气动光学效应图像校正处理中具有实用价值。
参考文献参考文献:
[1]张天序,洪汉玉,张新宇.气动光学效应校正[M].合肥:中国科学技术大学出版社,2013.
[2]洪汉玉,张天序,余国亮.航天湍流退化图像的极大似然估计规整化复原算法[J].红外与毫米波学报,2005,24(2):130134.
[3]洪汉玉,张天序,余国亮.基于Poisson模型的湍流退化图像多帧迭代复原算法[J].宇航学报,2004,25(6):649654.
[4]洪汉玉,王进,张天序,等.红外目标图像循环迭代复原算法的加速技术研究[J].红外与毫米波学报,2008,27(1):433436.
[5]都志辉.高性能计算之并行编程技术—MPI并行程序设计[M].北京:清华大学出版社,2001.
[6]J G NAGY,R J PLEMMONS,T C TORGERSEN.Iterative image RESToration using approximate inverse preconditioning[J].IEEE Trans.on Image Processing,1996,5(7):11511162
[7]吕捷.并行与分布式图像处理系统的实现与应用[D].武汉:华中科技大学,2004.
责任编辑(责任编辑:黄健)
