基于柔性神经树的Internet流量早期识别模型
2015-04-29彭立志张宏莉
彭立志 张宏莉
摘 要:在互联网产生的早期阶段对其进行准确有效的识别,对于网络管理和网络安全来说都有着极其重要的意义。鉴于此,近年来越来越多的研究致力于仅仅基于流量早期的数个数据包,建立有效的机器学习模型对其进行识别。本文力图基于柔性神经树(FNT)构建有效的互联网流量早期识别模型。两个开放数据集和一个实验室采集的数据集用于实验研究,并将FNT与8种经典算法进行对比。实验结果表明,FNT在大多数情况下,其识别率和误报率指标优于其他算法,这说明FNT是一种有效的流量早期识别模型。
关键词:流量识别;机器学习;早期特征;柔性神经树
中图分类号:TP391.41 文献标识号:A 文章编号:2095-2163(2015-)02-
Early Stage Internet Traffic Identification Model based on Flexible Neural Trees
PENG Lizhi, ZHANG Hongli
(School of Computer Science and Technology, Harbin Institute of Technology, Harbin 150001, China)
Abstract: Identifying Internet traffic at their early stages accurately is very important for network management and security. Recent years, more and more studies have devoted to find effective machine learning models to identify traffics with the few packets at the early stage. This paper tries to build an effective early stage traffic identification model by applying flexible neural trees. Three network traffic data sets including two open data sets are used for the study. Eight classical classifiers are employed as the comparing methods in the identification experiments. FNT outperforms the other methods for most cases in the identification experiments, and it behaves very well for both of TPR and FPR. Thus, FNT is effective for early stage traffic identification.
Keywords:Traffic Identification; Machine Learning; Early Stage Features; Flexible Neural Trees
0 引 言
近年來,Internet流量早期识别越来越受到关注,因为在流量发生的早期阶段对其进行快速识别切合实际应用的真实需求。传统的基于机器学习的流量识别技术都是针对完整的流量样本提取特征,进而对其进行识别。这种基于完整流的特征集用于离线研究非常有效,但在实际情况下,当流已经结束后对其进行特征提取,然后再进行识别是没有实际意义的。因为无论从网络管理还是安全的角度讲,流结束后,已经无法对其进行有效管理与控制。因而实际应用的Internet流量识别技术必须具备在流量发生的早期对其快速准确识别的能力,只有这样,针对流量的后续管理与安全策略才能正常实施。所以,近年来,越来越多的研究者开始致力于构建有效的识别模型,用于Internet流量的早期识别。
1 相关工作
L. Bernaille等于2006年提出了一个著名的早期流量识别的方法[1],其中直接使用TCP流的前属多个数据包的包大小作为特征,然后使用K均值聚类方法对10种典型的Internet应用流量进行识别,获得了比较理想的识别结果。A. Este等在2009年针对流量早期特征提取问题做了一项重要的研究[2],研究使用早期数据包的RTT、包大小、包到达时间间隔和包方向等作为早期特征,应用信息理论进行分析,并用多种分类器进行验证试验。研究结果表明,早期数据包能携带足够用于流量识别的信息,而且这些原始特征中,数据包大小是最有效的特征。N. Huang等2008年研究了Internet应用在发生早期的行为特征,并将这些行为特征用于流量的识别[3]。最近,又进一步通过对应用开始的早期阶段的协商过程的行为进行分析,抽取流量的早期特征,然后将这些特征应用到基于机器学习的识别模型中,取得了很高的识别性能[4]。基于此,B. Hullár等则提出一种计算资源与内存资源消耗代价很小的早期P2P流量识别模型[5]。此外,A. Dainotti也提出一种高效的混合分类器用于早期流量识别[6]。
柔性神经树(Flexible neural trees,FNT)是一种采用树形结构的特殊神经网络[7-9],可广泛应用于各种分类与预测问题中[10-12]。FNT模型与普通神经网络相比,有着灵活的柔性结构,使得这种模型能通过树结构优化算法如免疫编程(IP)[13]和PIPE[14]等对网络结构进行自动优化调整,克服了普通神经网络的结构优化困难的问题。通过网络结构的自动优化,FNT 对各种分类与预测问题有着强大的自适应能力,并获得很高的分类与预测精度。另外FNT还具有自动特征选择的天然特性:在网络结构自动优化过程中,FNT通过对运算算子与输入特征的随机组合构建备选结构,这一过程自然地选择出有效的输入(即有效特征)。本文在前期对互联网流量早期特征有效性研究工作的基础上[15, 16],应用FNT进行互联网流量的早期识别研究,力图通过FNT良好的识别性能与泛化能力,以及自动特征选择能力,构建一种新的高效互联网流量早期识别模型。
2柔性神经树
在FNT的树形网络结构中,主要有叶节点和非叶节点两种。其中,叶节点是输入节点,对应着目标问题中的一个具体特征;非叶节点则是神经元,对应着一个具体的运算算子。因而FNT模型中包含两种类型的指令:柔性神经元指令(函数指令)和终端指令。具体地,柔性神经元指令用于树结构的非叶节点连接其子树,终端指令则是各输入特征。函数指令集合F和终端指令集合T可以表示为:
S = F∪T = {+2, +3, …, +N}∪ {x1, x2, … , xn},……………………………(1)
其中,+i (i = 2, 3, … , N)表示非叶节点指令有i个参数。x1, x2, … , xn则是叶节点指令,没有参数,实际上就是输入变量。非叶节点的输出按图1(a)左部分所示的柔性神经元计算模型计算。
(a) 一柔性神经元 (b) 神经树结构
(a) A flexible neuron operator (b) A representation of FNT
图1 柔性神经树
Fig.1 Flexible neural tree
在神经树的创建过程中,如果一个非叶节点指令,即+i (i = 2, 3, … , N)被选择,则产生i个随机实数作为该节点与其下属的i个子节点之间的连接强度。另外,还产生两个可调节的参数ai和bi作为柔性激活函数的参数。在本文的研究中,使用如下所示激活函数。
…………………………………………………(2)
柔性神经元+n的输出则按式(3)计算。
…………………………………………………(3)
其中,xj(j = 1, 2, … , n)是该柔性神经元的各输入,则该节点的总激励为:
…………………………………(4)
图1(b)是一个典型的柔性神经树模型,神经树的总输出可以用递归的方法从左至右深度优先计算得出。
3 实验设置
3.1 数据集
本文采用两个开放数据集和一个在校园网实验室采得的流量数据集,对应地可分别称为Auckland II数据集、UNIBS数据集和UJN数据集。所选数据集的应用类型、样本数以及字节数等特征如表1所示。
表1 各数据集特征
Tab.1 Characteristics of the selected data sets
Auckland II数据集
UNIBS数据集
UJN数据集
应用类型
样本数
总字节数
应用类型
样本数
总字节数
应用类型
样本数
总字节数
ftp
251
136 241
bittorrent
3 571
6 393 487
Web Browser
11 890
58 025 350
ftp-data
463
5 260 804
edonkey
379
241 587
Chat
11 478
60 212 804
http
23 721
1.39E+08
http
25 729
1.07E+08
Cloud Disk
1 563
1.1E+08
imap
193
86 455
imap
327
860 226
Live Update
2 169
28 759 962
pop3
498
98 699
pop3
2 473
4 292 419
Stream Media
810
785 556
smtp
2 602
1 230 528
skype
801
805 453
803
2 092 862
ssh
237
149 502
smtp
120
43 566
P2P
326
2 521 089
telnet
37
21 171
ssh
23
39 456
Other
1 408
3 635 558
3.2 對比算法
本文采用8种广泛使用的机器学习分类器用于识别实验,这些分类器都在著名的数据挖掘软件Weka上实现,所有的实验也是在Weka环境下执行。前面部分所述生成的特征数据集都采用Weka数据格式进行格式化,生成“arff”数据文件用于识别实验。依据Weka的分类,这8种分类器可区分为五类,如表2所示。
表2 对比算法
Tab.2 Compared algorithms
算法
类型
算法
类型
BayesNet
贝叶斯分类器
NBTree
树分类器
Bagging
元分类器
RandomForest
树分类器
OneR
规则分类器
SVM
函数分类器
PART
规则分类器
RBFNetwork
函数分类器
3.3 性能评估指标
一般来说,对识别模型的性能评估方法有很多种,简单地可以采用正确率(Acc)对模型性能评估,Acc只是从总体上反映模型对数据的一个识别正确率,并不考量各类样本之间错误分类的样本数对模型性能的影响,因而对模型的性能评估不够全面。本文采用真阳性率(True Positive Rate, TPR)和假阳性率(False Positive Rate)两个指标对模型性能进行评估。TPR又称为识别率,FPR也称为误报率。对于一个只包含正样本(阳性样本)和负样本(阴性样本)的二分类问题,模型的分类结果包含四个基本量:正确分类的正样本数TP,正确分类的负样本数TN,错误分类的正样本数FP,以及错误分类的负样本数FN。则TPR 定义为:
…………………………………………………(5)
而FPR定义为:
…………………………………………………(6)
4 实验结果与分析
本文将九种对比算法在三个数据集上进行识别实验,由于每个数据集有多个流量类别,每一种流量类别在实验中都有相应的TPR和FPR,因而本文对每个数据集的实验结果中所有流量类别的TPR和FPR计算平均值,用平均值作为最终结果,并以柱状图的方式直观地显示各种算法在该数据集上的识别率和误报率。
4.1 实验结果
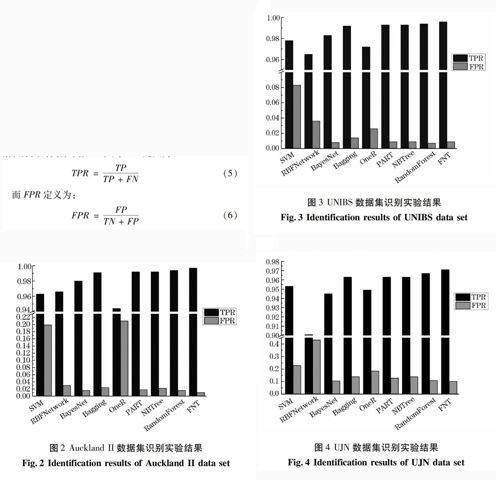
图2显示了各种对比算法在Auckland II数据集上的实验结果。在所有对比算法的识别率(TPR)结果中,Bagging、PART、NBTree、RandomForest 和FNT都获得了超过99% 的识别率,其中FNT的TPR最高,并明显高于其他算法。其他四种算法的识别率均小于98%,与前五种差别较为明显。从TPR 上看,FNT获得了最好的识别性能。再观察漏报率(FPR)指标,除SVM和OneR之外,其他算法的FPR均在3%的较低水平以下。FNT的FPR同样是最低的,FNT 在获得最高的识别率的情况下,同时能保持最低的漏报率,说明其在Auckland II数据集上的识别效果比较理想。
图2 Auckland II数据集识别实验结果
Fig.2 Identification results of Auckland II data set
图3给出了在UNIBS数据集上的实验结果。与Auckland II数据集的实验结果一样,FNT在UNIBS数据集上同样获得了最高的识别率,并明显高于其他算法,Bagging、PART、NBTree 和RandomForest四个算法也获得了比较高的TPR。从误报率的角度看,FNT未获得最小的误报率,但其FPR与BayesNet、PART、NBTree和RandomForest 等其他几个算法的FPR 區别很小,均在1%以下。
图3 UNIBS数据集识别实验结果
Fig.3 Identification results of UNIBS data set
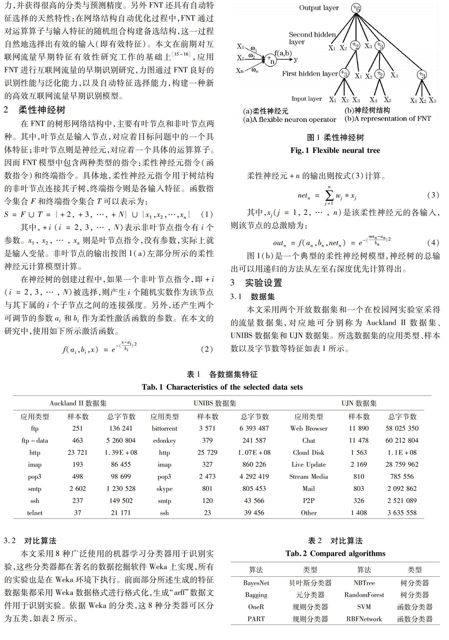
从图4显示的UJN数据集的实验结果看,各算法的行为模式大体与其在UNIBS数据集上的行为模式类似,但总体的识别精度有所下降。Bagging、PART、NBTree、RandomForest和FNT五个算法的识别性能明显高于其他几个算法。FNT再次获得了最高的识别率,同时也获得了最低的误报率。这一实验结果也进一步说明FNT 的识别性能要好于其他算法。
图4 UJN数据集识别实验结果
Fig.4 Identification results of UJN data set
4.2分析与讨论
从三个数据集的结果总体上分析,不难看出:
(1)首先实验中大部分算法利用仅仅6个早期数据包大小就能获得较为理想的识别性能,说明利用数据包大小进行早期识别是完全可以适应实际识别要求的。
(2)FNT在三个数据集上均能获取最高的识别率(TPR),这就意味着FNT在早期识别中有效地将目标流量类型样本识别出来;另外FNT在获得高TPR的同时能保持低水平的FPR,说明FNT 在准确识别目标流量类型的同时,不容易产生误报,确保识别结果的有效性。
(3)作为经典的函数分类器,SVM和RBFNetwork在识别实验中的表现明显略逊于其他几个性能较好的分类器。这与这两个模型的复杂性有关,参数的调节对模型的性能影响比较大,如果针对具体数据集对SVM 和RBFNetwork进行进一步的参数调节可能会获得更好的识别性能。
5 结束语
本文研究柔性神经树FNT在流量早期识别中的应用,采用进化算法对柔性神经树进行结构优化,进一步应用PSO算法对选择的树结构进行参数优化,这一求解过程反映了FNT的灵活性及其对解空间搜索的全面性。本文实验中采用6个早期数据包大小作为特征进行识别,从实验结果的分析可以得出以下结论:FNT能对各类流量数据获得比较理想的识别率,并在高识别率下保证较低的误报率,是一种高性能的早期流量识别模型。
参考文献:
[1] BERNAILLE L, TEIXEIRA R, AKODKENOU I, et al. Traffic classification on the fly[C]//Procedings of ACM SIGCOMM'06, Pisa, Italy: ACM, 2006:23-26.
[2] ESTE A, GRINGOLI F, SALGARELLI L. On the stability of the information carried by traffic flow features at the packet level[C]//Procedings of ACM SIGCOMM'09, BARCELONA, Spain: ACM, 2009:13-18.
[3] HUANG N, JAI G, CHAO H. Early identifying application traffic with application characteristics[C]// Proceedings of IEEE Int. Conference on Communications (ICC'08), Beijing, China: IEEE, 2008:5788-5792.
[4] HUANG N, JAI G, CHAO H, et al. Application traffic classification at the early stage by characterizing application rounds[J]. Information Sciences, 2013,232(20):130-142.
[5] HULLAR B, LAKI S, GYORGY A. Early identification of peer-to-peer traffic[C]//2011 IEEE International Conference on Communications (ICC). Kyoto, Japan: IEEE,2011:1-6.
[6] DAINOTTI A, PESCAPE A, SANSONE C. Early classification of network traffic through multi-classification[J]. Lecture Notes on Computer Science, 2011,6613:122-135.
[7] CHEN Y, YANG B, DONG J, Nonlinear systems modeling via optimal design of neural trees[J]. International J. Neural Syst, 2004,14:125-138.
[8] CHEN Y, YANG B, DONG J, et al. Time Series Forecasting Using Flexible Neural Tree Model[J]. Information Sciences, 2005,174:219-235.
[9] CHEN Y, CHEN F, YANG J Y. Evolving MIMO flexible neural trees for nonlinear system identification[C]// IC-AI 2007, Hyderabad, India: IEEE, 2007:373-377.
[10] CHEN Y, YANG B, ABRAHAM A. Flexible neural trees ensemble for stock index modeling[J]. Neurocomputing, 2007,70: 697-703.
[11] QU S, LIU Z, CUI G, et al. Modeling of cement decomposing furnace production process based on flexible neural tree[C]//Proc. of the 2008 International Conference on Information Management, Innovation Management and Industrial Engineering, Taipei, China: IEEE, 2008:128-133.
[12] ZHOU J, LIU Y, CHEN Y. ICA based on KPCA and hybrid flexible neural tree to face recognition[C]//Proc. of the 6th International Conference on Computer Information Systems and Industrial Management Applications, MN, USA: IEEE, 2007:245-250.
[13] PETR M, ADRIEL L, MAREKT R, et al. Immune Programming[J]. Information Sciences, 2006,176: 972-1002.
[14] SALUSTOWICZ R P, SCHMIDHUBER J. Probabilistic incremental program evolution[J]. Evol. Comput, 1997,2(5):123-141.
[15] PENG L, ZHANG H, YANG B, et al. Feature evaluation for early stage Internet traffic identification[C]//The 14th International Conference on Algorithms and Architectures for Parallel Processing (ICA3PP2014), Dalian, China: IEEE, 2014:511-525.
[16] PENG L, ZHANG H, YANG B, et al. How many packets are most effective for early stage traffic identification: An experimental study[J]. China Communications, 2014,11(9):206-216.
1 基金項目:国家973重点基础研究发展计划( 2011CB302605); 国家863高技术研究发展计划(2011AA010705, 2012AA012502, 2012AA012506); “十一五”国家科技支撑计划(2012BAH37B01); 国家自然科学基金 (11226239, 6110018, 61173144, 61472164)。
作者简介:彭立志(1975-),男,山东济南人,博士研究生,主要研究方向: 机器学习、流量识别、信息安全;
张宏莉(1973-),女,吉林榆树人,博士,教授,博士生导师,主要研究方向:信息内容安全、网络测量和建模、并行计算。
