大数据解析技术在大气环境监测中的应用研究
2015-04-26徐富春程子峰
李 蔚,胡 昊,徐富春,程子峰
环境保护部信息中心,北京 100029
当今社会发展已经进入了信息爆炸的时代。各行各业每时每刻产生大量的信息,通过高速发展的通讯、传媒通道,传送到社会各个数据层面和节点,为公众服务。巨量信息的产生、流动、交互、反馈已成为现今社会的一个显著特点。伴随巨量信息的产生,信息的计算和处理技术也取得了日新月异的进展,全球最快的超级计算机“天河二号”的运算能力已达到每秒33.86千万亿次的浮点运算速度。同时,应需而生的大量基础和应用软件的开发,也为数据的存储、运算、处理提供了多种方式和能力。环境保护各部门、各系统每日每时都产生大量信息:环境监测部门所得到的大气、水、土壤、海洋等环境要素的质量信息,环境监察部门获得的污染源排放数据,环境统计所获得的社会、经济、环境保护工作数据,环境科研、调研获取的科研信息。另外,环保部门还从与环境保护工作密切相关的气象、水利、海洋、农林渔业、能源、卫生、交通等部门交换了大量信息,这些信息为环境科学研究人员提供了认识、分析、研究环境问题的机遇和条件,也为环境管理、环境决策提供了分析、认识问题的基础。但是,由于环境问题的多样性和复杂性,从不同渠道获取的数据之间可比性较差,不同类型的数据之间呈现多元、非线性的相互关系,这对数据的分析、利用带来了巨大的困难和挑战。
面对巨量信息及不同数据类型之间的复杂关系,一种探求数据类与类之间的相互关系、相互影响的大数据解析技术迅速发展起来[1]。大数据解析技术应用数据采集、统计计算、系统模拟和参数识别、随机过程分析、神经网络分析、系统智能自学及半自学等各种数据分析技术,对多元、非线性的数据类之间的关系进行解析,达到分析预测研究目标函数的变化规律,为利用巨量信息分析研究环境问题提供了一种有力的手段。
本文拟以大数据解析技术在城市局地PM2.5浓度计算为例,对大数据解析技术在环境科学研究中的应用方法进行一些探索性的分析,企盼对从事环境科学研究的从业者有所启迪。
1 选题依据
中国近年频发大范围的PM2.5污染问题,引起了社会公众的高度关注,PM2.5已成为环境保护工作的突出问题。公众关心PM2.5的污染问题,自然关切自身所在地点PM2.5浓度问题。由于设置大气自动监测站(含PM2.5浓度的监测)一次投资金额较大(一个站点大约需人民币200万元),加上运行维修费、人工成本等费用,就一个城市而言,不可能投资建设太多的大气自动监测站。以北京为例,每100 km2左右才有一个大气自动监测站,难以代表该区域内每个局地点的PM2.5浓度。因此,研究计算局地PM2.5的浓度是有意义的。
2 大数据解析技术方法和原理简介
应用大数据解析技术对局地大气污染浓度计算的流程见图1:
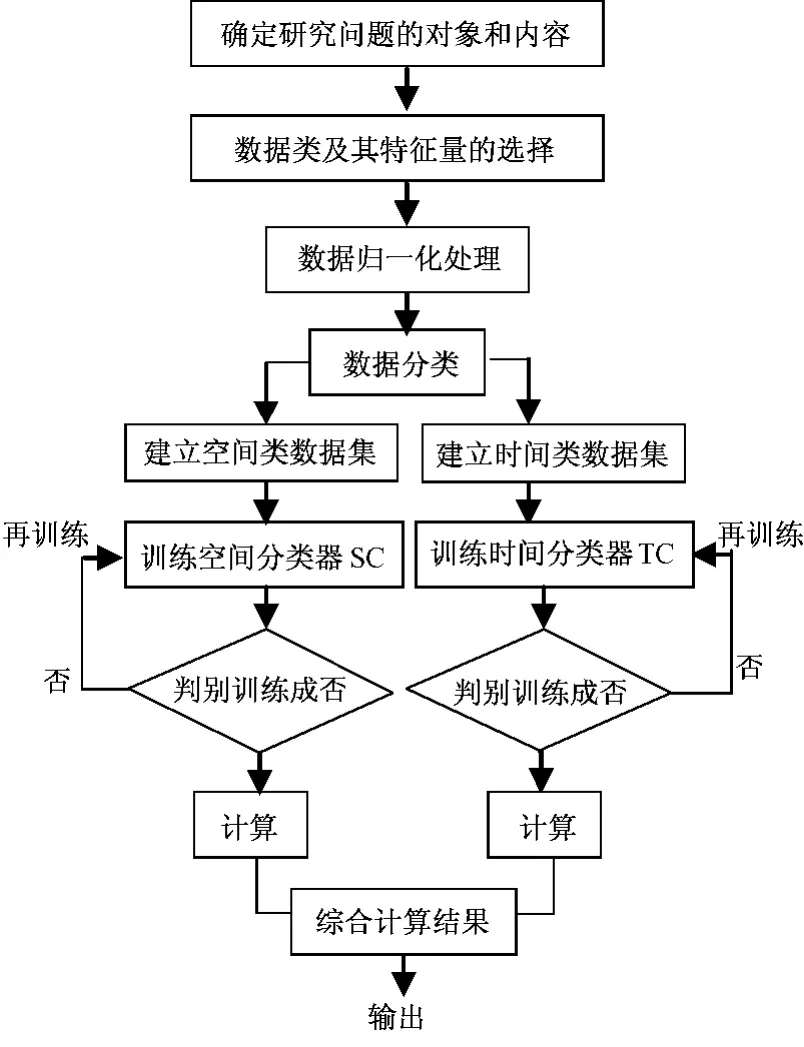
图1 大数据解析技术预测大气污染浓度流程
2.1 研究对象和研究内容
由于大数据解析技术面对的是众多相互之间关系复杂的数据类,因此大数据解析技术在遵循数据分析原理的基础上,在处理和解决不同的问题类型时具有多样性、灵活性的特点。应用大数据解析技术时,要先确定研究对象和研究内容。以城市的局部地区为研究对象,以城市局部地区PM2.5的平均浓度为研究内容。首先将目标城市按一定的标准划分为单元网格(如1 km×1 km),研究对象可表达成 G(g1,g2,… ,gi,… ,gn),每个gi代表一个范围为1 km2的地点;研究内容可表达为 C(cg1,cg2,… ,cgi,… cgn),其中 cgi表示 gi局地网格的PM2.5浓度。研究内容在大数据解析中被称为目标函数,可表示为J(Ci)。J(Ci)中的Ci有两类,一类是设有大气自动监测站的网格C1,其PM2.5的浓度已知,另一类是未设有大气自动监测站的网格C2,C2所在的局地网格PM2.5浓度未知,是需要应用大数据技术进行解析的目标值。
2.2 数据类及特征量的选择
为了尽可能准确的获知C2,需要选择大量与C2相关的城市数据进行解析。选择这些数据类的原则是“可能”“需要”。“可能”是首要的,只有有数据才能选择;“需要”则需对各种数据类进行分析,选取与目标函数J(Ci)有一定相关性的数据类。相关性可强可弱,与目标函数J(Ci)的关系也可简单可复杂。就环境研究领域中的问题而言,数据类之间的关系,大多呈现多样性、非线性的复杂关系,这也是大数据解析技术研究问题的难点所在。为了研究局地PM2.5浓度,根据环境科学的基本原理和基础知识,以及现有数据条件,可选择以下几类数据:1)有大气自动监测站所在网格的PM2.5浓度历史数据;2)气象条件数据;3)交通状况数据;4)人群活动情况数据;5)网格道路状况数据;6)网格内与空气污染有关的特征单位数据,例如:工厂、加油站、餐饮业、车站、购物中心、运动场、公园等数据;7)每个网格的坐标。
在大数据解析技术中,对目标函数的研究,主要是通过各类数据所包含的特征量对目标函数的影响来解析的,因此,必须合理的从各类数据中确定特征量。对已知浓度网格的PM2.5浓度数据,由于研究目标是网格PM2.5小时平均浓度,取网格内PM2.5浓度值也应将历史上PM2.5小时平均浓度作为特征量;对气象条件,取气温、气压、风速、相对湿度等作为特征量;对交通状况,取总车辆数、平均车速、平均车速方差及在不同车速下的车辆数(例如:可采用将车速分为三档,0<V1≤20,20<V2≤40,V3>40)作为特征量,此处车速单位均为km/h;对人群活动情况,取进出网格的人数作为特征量;对网格道路状况,取高速公路长度、一般公路长度、交叉路口的数量等作为特征量;对网格内与空气污染有关的特征单位数据,可取工厂、加油加气站、餐饮业、车站、购物中心、运动场、公园、旅馆等的数量作为特征量。
从上述所选取的各个特征量,要计算其对目标函数J(Ci)的影响,须对特征量数据进行归一化处理,计算公式如下
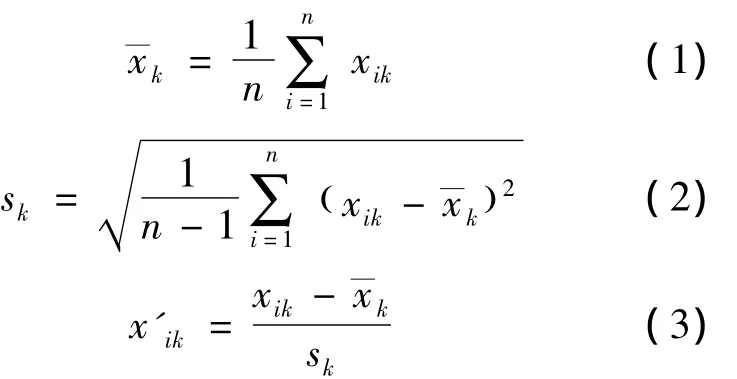
式(1)~式(3)中:xik为归一化前的特征量数据,下标K为第k个特征量,i为第K个特征量的第i个数值;x—k为第k个特征量的平均值;sk为第k个特征量的标准差;x'ik为归一化后的特征量k的第i个数据,n为第k个特征量数据个数。
当选定特征量并对每个网格的特征量数据进行采集时,有直接和间接两种途径,其中间接数据采集是在直接采集数据的基础进行分析和处理得到的再分析数据,例如人群的进或出的数量、车辆的平均车速及数量的采集是根据文献[2、5]的方法进行处理后得到的。
上述选择的特征量有两个明显不同属性:一类特征量随时间的变化而变化,另一类特征量不随时间而变化。由于这两类不同的特征量对目标函数J(Ci)的影响过程及解析途径有所不同,在大数据解析过程中,通常将特征量分成两类:一类是与空间相关的数据集(Spatial Data Set),在分析这类数据对目标函数的影响过程中,是通过自学或半自学的方法,构建成空间分类器(Spatial Classifier,SC),运用SC对目标函数进行预算得到预期结果。另一类是随时间变化的相关数据集(Temporal Data Set),在分析这类数据对目标函数的影响过程中,也通过自学或半自学的方法,构建成时间分类器(Temporal Classifier,TC),运用TC对目标函数进行运算得到预期结果。
选取的数据类中,其中网格道路状况、网格内与空气污染有关的特征单位数据,以及每个网格的坐标数据类所包含的特征量应归为与空间相关的数据集;PM2.5浓度的历史数据、气象条件、交通状况及人群活动情况数据类所包含的特征量应归为与随时间变化的相关数据集。由于SC和TC的性质特征不同,其建立和训练的途径和方法也不同,SC和TC的建立是大数据解析技术的关键步骤。
2.3 空间分类器
SC所包含的特征量不随时间的变化而变化,它是一个静态过程。SC所包含的特征量对目标函数的影响是多层多节点的传递过程,传递路线是线性的,传递过程在节点的输出可以是线性的或非线性的,因而SC具有静态神经网络结构的特征。神经网络法本身是模拟复杂系统、解析大数据非常有用的工具,因此选用由输入部分(Input Generation,IG)、人造神经网络部分(Artificial Neural Network,ANN)组成的 SC来模拟预测局地网格PM2.5浓度。
IG的作用是用各类空间特征量构建ANN的输入值。从建有大气自动监测站的网格中随机选取两个局地坐标为l1和l2的网格,每个网格中包含二个特征量和污染物浓度值,分别用f11、f12,f21、f22和c1、c2表示;x代表某一待预测的网格,其局地坐标用lx表示,x网格中二个特征量和待估污染物浓度用fx1、fx2和cx表示。由IG构成的对ANN的输入数据生成流程见图2。
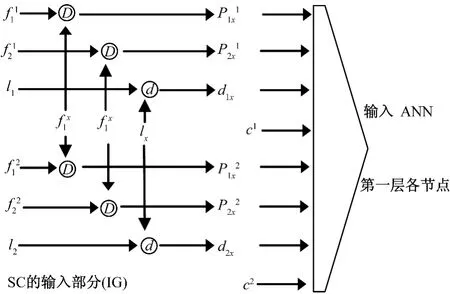
图2 空间分类器IG数据生成流程
图2中,d表示一种算法,例如:两网格坐标点之间的几何距离;D也表示一种算法,例如:两网格某一特征量间的皮尔逊(Pearson)距离。p、d则表示计算结果,构成ANN的输入数据。其数学表达公式如下
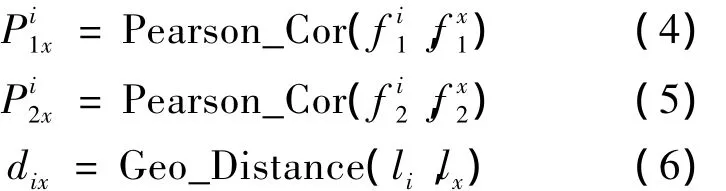
ANN是在接受输入数据后,通过神经网络节点和传递,最终产生对目标值的影响。为理解神经网络的传递过程,神经网络某节点的传递过程见图3。
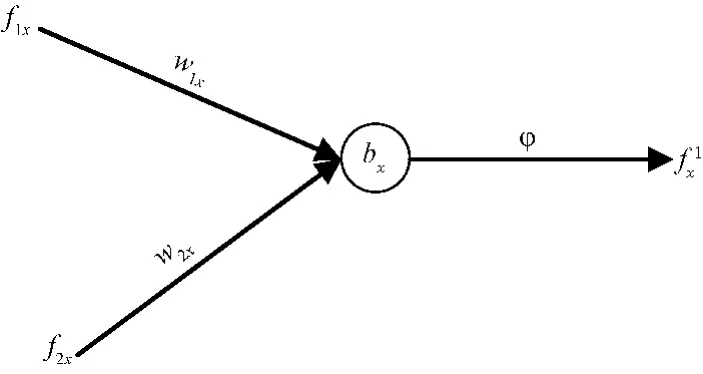
图3 神经网络节点输入输出流程
图3表示神经网络一个节点输入输出关系。f1x、f2x表示该节点的两个输入;f'x表示该节点的输出;w1x、w2x表示两个输入权重;bx表示该节点输入输出的偏移,即神经感知偏移;φ表示输出为非线性输出的变换函数。则该节点的输入输出之间的关系见公式(7):
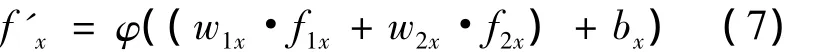
若神经网络节点输出为线性输出,则式(7)可简化表示为式(8):
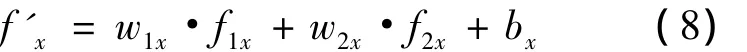
在神经网络分析中,广泛采用只有一个隐藏层的网络结构。若输入有P项,神经网络的第一层接受节点有q个,输出层的节点有r个,则神经网络输出结果可由式(7)扩展成式(9):
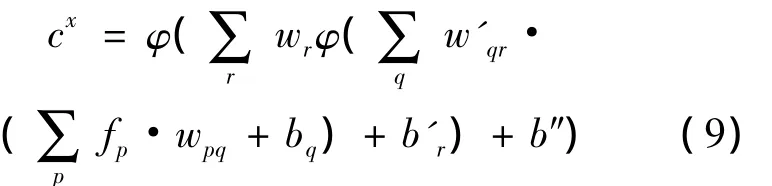
式中:fp表示输入特征量,w表示各层各节点输入特征量的权重,w'表示隐藏层权重,bq、b'r、b″表示各层各节点的神经感知偏移,节点输出非线性变换函数(φ)最常选用的是sigmoid函数[5],cx表示最终输出值。
从式(9)中可以看出,由神经网络构造的空间分类器SC预测某局地点大气污染浓度,要解决神经网络中各感受层、各个节点的权重、节点神经感知偏移和非线性函数变换问题。目前广泛使用解决该问题的方法是反演法(Back-Propagation),或称BP法[6]。其思路是与实际神经网络感受由左向右相反,由右向左将残差(估算值与实测值之差)分配到各输入权重上,一层一层向左进行,直到最后分配到IG的输出特征量的各权重上。按最优模拟模型参数估值最小二乘法推演[7],残差分配到各权重上,即权重的更新,是将残差按输入值大小比例分配到各权重上。这种方法在模型学习过程中称为Widrow-Hoff学习规则。φ的影响亦是以线性方式体现的,即在权重上加一个比例系数。在解决实际问题时,k可选用有大气污染自动监测站的网格数据,不断反复模拟训练SC,即SC的不断反复的自学习过程。SC模拟学习过程是否完成,是用残差大小来判别的,当残差值小于设定值,表示SC模型趋于完善。
2.4 时间分类器
综上所述,大数据解析过程中,包含对随时间变化的特征量的解析。在对局地点大气污染浓度预测的实例中,气象条件类中的气温、气压、风速、相对温度;交通状况中的网格内车辆总数、平均车速、平均车速方差、不同车速车辆的分配值;网格中人员进出的数量,都为此类特征量,记为xij,i表示某网格点,j表示某个特征量,则可进一步表示为 X={x1,x2,…,xn},其中:xi={xi1,xi2,…,xij,t},t表示某一时刻。
局地点大气污染物浓度亦是一个随时间变化的特征量,记为yi,i表示某网格点,则可记:Y={y1,y2,…,yn},它代表了某一时刻要被预测的大气污染物浓度值,是某一时刻的状态函数,为一随机变量。当特征量X确定的条件下,随机变量yi具有马和科夫特性,即yi仅与相邻的yi-1的值有关,而与其他的yk值无关,其数学表达为
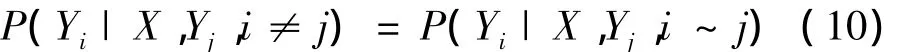
式中:P表示概率,i~j表示i状态变量与j状态变量在给定域中相邻。
在给定特征量X序列条件下,估计值y出现的概率被定义为正态分布函数,它由x条件下状态特征函数exp(u·s(yi,xi,i))和由状态i- 1 转移到 i时的转移特征函数 exp(λ·t(yi-1,yi,x,i))决定。在这两个特征函数中,yi、yi-1定义同前,x表示某特征量,i表示某状态,s表示状态函数,t表示转移函数,u、λ是训练过程中的待估参数。由概率论而知,两事件相交的概率为两事件概率相乘。当特征量X有k个状态,特征量为j个时,则估计值y出现的概率为
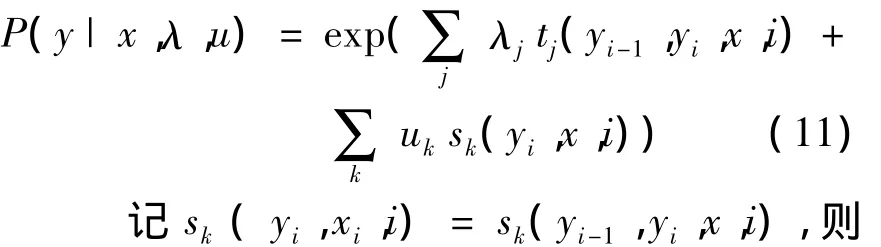
式(11)可改写为
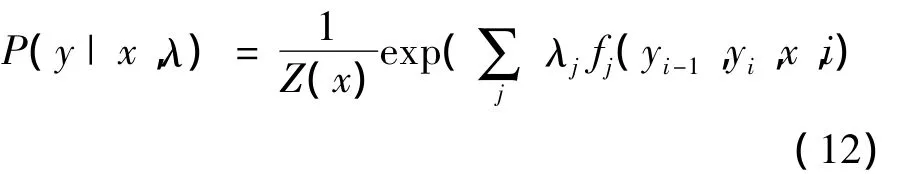
式(12)中:Z(x)为正态分布标准化因子,文献[8]中有详细介绍,fj表示j个特征量。为解决权重参数λ的估值问题,可对式(12)作简单的对数变换,得到:
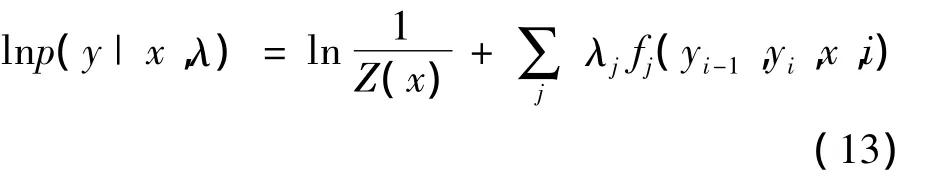
由式(13)可以看出,条件概率函数已变换成线性函数关系,可使用常用的线性函数参数估值的方法,估出λ值。与SC中的权重w一样,条件概率函数的权重λ值也是在不断自身学习过程中加以修正。经反复学习,构建成了训练好的TC。TC构建的整个过程实质上是对条件随机场(Conditional Random Field,CRF)的解析过程[8]。
通过对大数据集中相关特征值的解析、推演,可得到趋于最优的TC、SC,使其能对各研究对象中的研究内容进行估算。在计算城市局地大气污染物浓度的应用中,能用训练好的SC、TC,对各未知网格中的 PM2.5浓度进行估算,得出最终估算值:
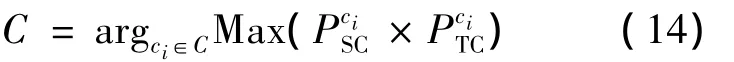
3 讨论
大数据解析技术的基本思路是筛选出某些具有相关关系的数据类,精心选择数据类的特征量,针对各种不同的研究对象和研究内容,采用灵活、多样的数学分析方法对特征量进行解析运算,对包含不同特征量的各种因素之间相关关系进行分析,达到解决研究问题的目的。该技术提供了一种研究解决多元、非线性因素之间关系的方法。目前,大数据解析技术在各行各业中的应用越来越活跃,其研究应用的深度和广度都在不断向前取得进展,该文所进行的介绍还是相当粗浅的,许多问题有待进一步实践和探讨。
大数据解析过程中有几个关键点,需要特别予以注意。1)基础数据的收集和处理:现有的数据经常会有不准(甚至错误的数据)、不全、不能直接获取等问题,有些不能直接获取的特征量,还需运用各种统计分析方法获取。2)数据类和数据类中特征量的选取,是分析研究问题的关键所在:合理的特征量的筛选对解决所研究问题起相当重要的作用,并且对保证研究结论的准确度也会有相当大的帮助。3)解析数据类特征量数学工具的选择:对同一问题的解析,往往可有若干种数据处理的途径和方法,准确选择数学工具对解决研究问题的重要性是不容置疑的。
环境问题是典型的多因素、多元、非线性相互关系问题。城市、农村、流域、区域都有大量关系复杂的因素包含在其中;大气、水体(河流、湖泊、海洋、地下水)、土壤、固体废物堆放等种种环境污染问题,有许许多多数据类之间的相互影响需要解析;研究当今能源、气候变化、生态系统破坏等重大环境问题的对策,大数据解析也是一种有用的工具;人口、资源、交通发展变化趋势需要进行预测;有毒有害物质、食品安全、人群身体健康等许多问题需要进行风险评估。凡此种诸多环境问题,大数据解析都有用武之地。总之,大数据解析技术在环境问题应用中前景广阔。
[1]黄哲学,曹付元,李俊杰,等.面向大数据的海云数据系统关键技术研究[J].网络新媒体技术,2012,1(6):20-26.
[2]Yuan J,Zheng Y,Xie X.Discovery regions of different functions in a city using human mobility and POIs[C]//The 18th ACM SigKdd Conference on Knowledge Discovery and Data Mining.New York:Association for Computing Machinery,2012:186-194.
[3]Zheng Y,LiuY, XieX.Urbancomputingwith Taxicabs[C].Proc of the 13th Int Conf on Ubiquitous Computing.New York:Association forComputing Machinery,2011:89-98.
[4]Rodgers J L,Nicewander W A.Thirteen ways to look at the correlation coefficient[J]. The American Statistician,1988,42(1):59-67.
[5]罗兵,黄万杰,杨帅.基于Tan-Sigmoid函数参数调整的BP神经网络改进算法[J].重庆大学学报:自然科学版,2006,29(1):150-154.
[6]刘鹰,赵琳.神经网络BP算法的改进和仿真[J].计算机仿真,1999,16(3):12-15.
[7]程子峰,徐富春.环境数据统计分析基础[M].北京:化学工业出版社,2006.
[8]Lafferty J,Callum A M,Pereira F.Conditional random field:Probabilistie models for segmenting and labeling sequence data[C]//In Proceeding of 18th International Conference on Machine Learning.Massachusetts:International Machine Learning Society,2001:282-289.
