Construction method of Chinese sentential semantic structure
2015-04-24LUOSenlin罗森林HANLei韩磊PANLimin潘丽敏WEIChao魏超
LUO Sen-lin(罗森林), HAN Lei(韩磊), PAN Li-min(潘丽敏),, WEI Chao(魏超)
(School of Information and Electronics, Beijing Institute of Technology, Beijing 10081, China)
Construction method of Chinese sentential semantic structure
LUO Sen-lin(罗森林)1, HAN Lei(韩磊)1, PAN Li-min(潘丽敏)1,, WEI Chao(魏超)1
(School of Information and Electronics, Beijing Institute of Technology, Beijing 10081, China)
A new method is proposed for constructing the Chinese sentential semantic structure in this paper. The method adopts the features including predicates, relations between predicates and basic arguments, relations between words, and case types to train the models of CRF++ and dependency parser. On the basis of the data set in Beijing Forest Studio-Chinese Tagged Corpus (BFS-CTC), the proposed method obtains precision value of 73.63% in open test. This result shows that the formalized computer processing can construct the sentential semantic structure absolutely. The features of predicates, topic and comment extracted with the method can be applied in Chinese information processing directly for promoting the development of Chinese semantic analysis. The method makes the analysis of sentential semantic analysis based on large scale of data possible. It is a tool for expanding the corpus and has certain theoretical research and practical application value.
sentential semantic structure; Chinese sentential semantic model; conditional random field; dependency parse
There are three levels for the computer to “understand” a sentence: the lexical level, the grammar level and the semantic level. When the computer is able to “understand” the sentence on one of the levels, it would analysis the language works based on the linguistic features. Since last 80s, the main emphasis of natural language processing (NLP) research has shifted to the semantic annotation and there has been a revived interest in semantic parsing by applying statistical and machine learning methods.
Many researchers have been working on this and some forms on semantic level have been proposed by now. One of the forms is the FrameNet project[1]which began in 1997 at University of California Berkeley, based on frame semantics. You Liping[2-3]used it to build Chinese vocabulary knowledge base using dependency grammar for sentences process. Another form is the PropBank project[4-5]. It tags the semantic role on the syntax tree node of Penn TreeBank[6]to realize the shallower level of semantic representation using case grammar for sentences process[7]. Focused on analyzing Chinese sentential semantic, another form called Chinese sentential semantic model (CSM) whose instantiate object for a sentence is sentential semantic structure (SSS) is proposed[8]. CSM is the structure expression of components and relations of components based on Chinese semantics[9]. In 2012, a CSM corpus named Beijing Forest Studio-Chinese Tagged Corpus (BFS-CTC)[10-11], which has been constructed since October, 2009, is made public. With the emerging of CSM and BFS-CTC, there are a lot of aspects to be studied. In this paper, a method for auto-constructing SSS is proposed.
1 Chinese sentential semantic model
1.1 Basic form
CSM is generated from a logical structure as shown in Fig.1. It consists of topic which is composed of argument, and comment that is composed of predicate and argument.

Fig.1 Logical structure of CSM
In general, CSM is divided into four levels, i.e. sentential type level, description level, object level and detail level. The sentential type level describes the sentential semantic type, which indicates the complexity and the amount of layers. As the first division of CSM, the description level indicates the objects described (i.e. topic) of a sentence and the description of the objects (i.e. comment). The object level is a further division of topic and comment. Each object corresponds to a predicate or an argument, in the form of word, phrase or sub-sentence. The predicate and the basic argument related directly to the topic and comment constitute the basic framework of CSM. A common argument is used to describe and restrict the predicate and the basic argument, such as restricting time, place, scope, etc. And, a common argument can also be used for modifying another common argument.
The detail level describes the object with more details than the object level, however does not belong to the basic form of CSM. Thus CSM uses the dotted line to indicate that the detail property has no direct relationship with components. Detail level, which is extensible, is applied to describe objects’ properties, scope, nature, etc. Not all of the components are required to be described by the detail property, so not all objects have the detail properties. In addition, there are several specific properties need to be described at present, including the predicate aspect and the space scope information which can be obtained from the meaning of the word.
1.2 Sentential semantic types
Based on Chinese semantics, the SSS covers four types, namely simple sentential semantic, complex sentential semantic, compound sentential semantic and multiple sentential semantic. Simple sentential semantic only expresses one proposition, whereas complex and compound sentential semantic express more, in that they both contain no less than one simple sentential semantic, acting as the sub-structure. Multiple sentential semantic contains no less than one complex or compound sentential semantic structure as the sub-structure, which again includes simple sentential semantic. Thus, simple sentential semantic is defined as the basic unit and its form is the basic form. The other three forms are extensions of the basic form.
In a sentence of complex sentential semantic, a sub-sentence of the basic unit acts as a basic or common argument. As a simple example, in the sentence of
拒绝(refuse)零食(snacks)完全(absolutely)没有(no)必要(necessary).
“Refusing to snacks is absolutely unnecessary.”
A sentential semantic analysis will represent the sub-sentence “拒绝零食 (refusing to snacks)” as the agentive case (basic argument) of the sentence, and this sub-sentence belongs to the sentences of simple sentential semantic in Chinese.
The sub-sentence of basic unit is acting as a clause in a sentence of compound sentential semantic. For example, in the sentence of
中国队(Chinese team)输掉(lost)了(LE)比赛(competition), *pro*球(football)迷们(fans)很(awfully)伤(hurt)心(heart).
“Chinese team lost the competition, which hurt football fans’ feelings awfully.”
The two clauses “中国队输掉了比赛 (Chinese team lost the competition)” and “球迷们很伤心 (which hurt awfully their fans’ feelings)” are forming a compound sentence, and the two clauses are both the sentences with simple sentential semantic. The sub-sentence of a multiple sentence is a sentence with complex or compound sentential semantic, thus, the nested multilayer sentential structure might exist. For example, in the sentence of
法塔赫(Fatah)把(BA)阿巴斯(Abbas)打造(make)成为(become)现在(now)最(most)具(with)影响力(influence)的(DE)政治(politics)人物(figure).
“Fatah makes Abbas become the most influential political figure nowadays.”
It contains a complex sub-sentence “成为现在最具影响力的政治人物 (become the most influential political figure nowadays)” as the result case (basic argument), in which it again contains a sub-sentence of simple sentential semantic that is “现在最具影响力 (the most influential political figure nowadays)” as the description case (common argument).
1.3 Comparison with FrameNet and Propbank
Nowadays, semantic analysis researches focus on word sense disambiguation (WSD)[15]and semantic role labeling (SRL)[16]. Generally, CSM expresses formally the sentences’ components, coupled with their syntagmatic relations (Tab.1).
The examples of FrameNet and PropBank are shown in Fig.2 and Fig.3 separately.
Compared with FramNet and PropBank, CSM has more semantic features: the sentential semantic type, the topic and comment, the relations among all components of the sentential semantic and the detail properties et al. The most unique character is that the CSM is a method to analyze the semantic of whole sentence.

Tab.1 Distinctions and connections among FrameNet, Propbank and CSM

Fig.2 Form of FrameNet
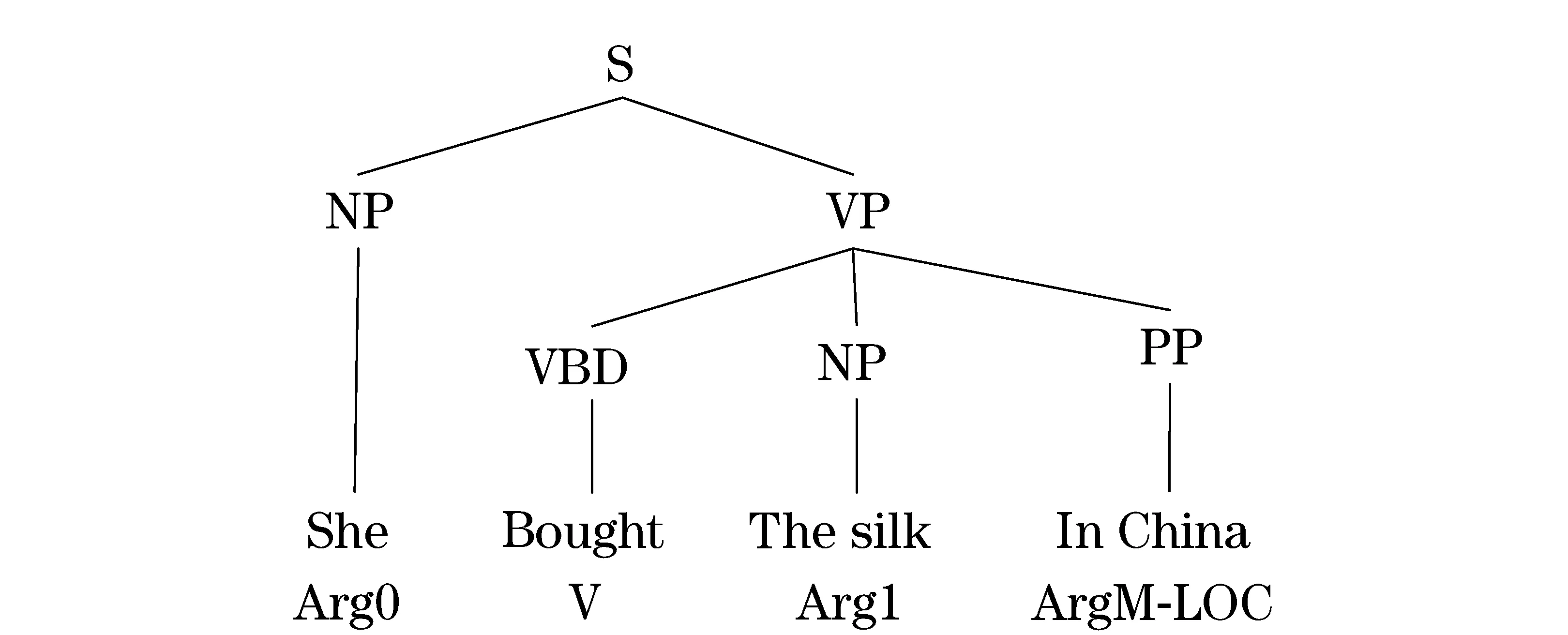
Fig.3 Form of PropBank
2 Constructing method
The proposed method constructs sentential semantic structure by using dependency parser and CRF++. There are three main procedures, namely CRF++ training and testing, dependency training and testing and SSS constructing. The principle of the method is shown in Fig.4.

Fig.4 Principle of the method
2.1 CRF++ training and testing
CRF++[12]is applied to obtain the predicates, case types, relations among predicates and basic arguments (R2), and meaningless words. Four models, also called model set, are adopted to tackle different tasks. In the procedure, the data are translated to one word per line format. The sentence of “余程万师长立即将孙长官电文公布周知。(Division commander Yu Chengwan made public the consolation telegraph from commander Sun immediately.)” is illustrated for an
example in Tab.2. In Tab.2, the first column is the word order (WO) in a sentence labeled from 1. The 5thcolumn represents the meaningless word (M). The 6thcolumn namedR2is the case type defined by BFS-CTC.R2contains 5 types of predicates and 4 types of basic arguments. The 5 types of predicates and 4 types of basic arguments are shown in Fig.5 and Fig.6 respectively. There are four training processes corresponding to the model set, namely predicate training, meaningless word training,R2training and case type training. The first 4 columns serve as the input to achieve predicate training. The label P in the 4thcolumn means the word in the line is a predicate. The first 5 columns which 0 means meaningless are as the input to achieve meaningless word training. The first 6 columns are as the input to achieveR2training. The label BTS, BC and C in the table means ①, ② in Fig.6 and ① in Fig.5. All of the columns in Tab.2 are as the input to achieve case type training. There are 7 basic cases and 12 common cases in BFS-CTC. Each training process above has unique template and parameters.
There are 4 steps in testing stage. The sentence in Tab.2 is chosen to illustrate. Firstly, in order to get predicates, the first 3 columns of Tab.2 are used. Secondly, the meaningless words are tested with the output of the first step as input. Thirdly, theR2is tested with the output of the second step as input. At last, the case types

Tab.2 One word per line format of a sentence

Fig.5 Five types of predicates

Fig.6 Fourtypes of basic arguments
are tested with the output of the third step as input. The output is the Tab.2.
2.2 Dependency training and testing
The dependency parser[13-14]is applied to obtain the relations between words (R1). According to the CSM, the relations between words in a sentence are defined as the follows: ① each word only has one father word and several words may have the same father word; ② only a main predicate which expresses the core semantic of the sentence is the root word; ③ no meaningless words are allowed in CSM. There is a little difference from dependency parsing. Therefore, the meaningless words should be removed firstly. While in training stage, the data are translated to CoNLL-2009 one word per line format. The output is relations between words in a sentence without meaningless words. Some of the preposition and auxiliary (e.g., “的(of)”) are defined as the meaningless words according to CSM.
2.3 SSS constructing
The inputs of SSS constructing are the previous results. The SSS of “余程万师长立即将孙长官电文公布周知。(Division commander Yu Chengwan made public the consolation telegraph from commander Sun immediately.)” in Tab.2 is shown as Fig.7. Firstly, the results ofR2are employed to construct the main frame of the CSM. Secondly, the results ofR1are employed to connect the words. At last, the case types are attached to the SSS. In addition, the sentential semantic type is decided by the number of predicates.

Fig.7 Sentential semantic structure of a sentence
3 Experiment
Two experiments are designed to choose the CRF++ training parameters and verify the method, namely parameters selection and method assessment.
3.1 Data set
The data set is the 10 000 sentences in BFS-CTC. The number of words in a sentence is 17.9 on the average. The maximum number of words in a sentence is 53 and the minimum number is 3.
3.2 Evaluate
There are three values to evaluate the result of experiments, namely precision (P), recall (R) andF1(F). The SSS and the components of the SSS are defined as semantic tree and nodes respectively. The computing process begins from the root node of CSM. It recursively compares the child nodes between the annotated and tested CSM.Cis defined as the number of correct tested nodes which mean the annotated and tested nodes are the same;Tis defined as the number of all tested nodes;Lis defined as the number of all annotated nodes. The formulas for calculating the value ofP,RandFare asP=C/T,R=C/LandF=2PR/(P+R).
3.3 Results
3.3.1 Parameters selection
For training parameters of 4 CRF++ models, the grid method is applied to select the bestCandF. The value ofCranges from 0.2 to 6 with the step length of 0.2. The value ofFranges from 1 to 5 with the step length of 1. The parameters which have the highest precision in testing are used to train the models. Take the model for predicates testing as an example to show the parameter choosing result. Nine features are used for the model training, including POS, word etc. Based on these features, the part of results of precision are shown in Fig.8. The best result is 98.7% for predicates testing whenCequals 0.6 or 0.8 andFequals 2 or 3. Considering theCvalue is the smaller the better,Cvalue of 0.6 andFvalue of 3 are chosen to train the model. The process of selecting parameters of the other 3 models is the same.

Fig.8 Part of the parameters selection results of predicate training
3.3.2 Method assessment
In the close test of semantic tree, the values of precision, recall andF1of 10 experimental groups are shown in Fig.9. The average values of precision, recall andF1are 95.83%, 96.47% and 0.961 5 respectively. In the open testing, the results are shown in Fig.10. The average values of precision, recall andF1are 73.63%, 71.81% and 0.727 1 respectively.

Fig.9 Close testresult of sentential semantic structure

Fig.10 Open test result of sentential semantic structure
The results of each procedure in close and open test are shown in Fig.11 and Fig.12. The abbreviations in the figures are the same as in Tab.2. Since the number ofR1between tested and annotated is the same, the precision value is recorded only.

Fig.11 Each procedure in close test

Fig.12 Each procedure in open test
The result in close test is better than that in open test. According to the figures, the values of predicate and meaningless word change a little between close and open test. Meanwhile, the values ofR1,R2and type decrease evidently in open test. This may be caused by the following reasons. Firstly, the meaningless words are excluded inR1testing, which is different from dependency parsing. Secondly,R2and case types testing are all multiple classification problems. The machine learning algorithms directly used in the method may not be fit enough. In a word, semantic analysis is a difficult task and this is the first method to analyze SSS. There are some issues to be improved in future research.
4 Conclusions
Chinese sematic analysis is one of the significant aspects in natural language processing. Devoting to automatic analyzing the Chinese sentential semantic model in BFS-CTC, a method based on CRF++ and transition-based parser is proposed. On the basis of CRF++, the method acquires the predicates, relations between predicates and basic cases, and type of cases. Meanwhile, the method applies the dependency parser to acquire the relations between words in a sentence. By using the information above, the proposed method constructs the SSS of a sentence. Two experiments are designed to choose the training parameters and verify the valid of the method based on BFS-CTC. The results show that the method can auto-construct SSS of a sentence absolutely and provide more semantic features as sentential semantic types, topic and comment et al. which can be used in Chinese analysis applications. Meanwhile, the method makes the SSS analysis of a sentence for large scale data possible. The method is a tool both for applications and expanding the corpus.
Studying how the method could be applied to applications will be the next step. The CSM provides many semantic features, such as the sentential semantic type, the topic and comment, and the predicates and arguments. Based on these semantic features provided by the proposed method, the performance of the applications would be promoted.
[1] Baker C F,Fillmore C J, LoweJ B.The berkeley frameNet project [C]∥ACL’98 Proceedings of the 36th Annual Meeting of the Association for Computational Linguistics and 17th International Conference on Computational Linguistics, Stroudsburg, PA, USA,1998.
[2] You Liping. A research on the construction of Chinese FrameNet [D]. Shanghai: Shanghai Normal University, 2006.(in Chinese)
[3] You Liping,Liu Kaiying.Building Chinese FrameNet database[C]∥Natural Language Processing and Knowledge Engineering, NJ, USA, 2005.
[4] Palmer M,Gildea D, Kingsbury P. The proposition bank: an annotated corpus of semantic roles[J]. Computational Linguistics,2005, 31(1):71-106.
[5] Palmer M,Xue N, Babko-Malaya O, et al.A parallel Proposition Bank Ⅱ for Chinese and English[C]∥In Proceedings of the Workshop on Frontiers in Corpus Annotations II: Pie in the Sky , Stroudsburg, PA, USA,2005.
[6] Xue N, Xia F, Chiou F, et al. The penn Chinese treebank: phrase structure annotation of a large corpus[J]. Natural Language Engineering, 2003, 11: 207-38.
[7] Yuan Yulin. The fineness hierarchy of semantic roles and its application in NLP[J]. Journal of Chinese Information Processing, 2007, 21(4):10-20. (in Chinese)
[8] Luo Senlin, Han Lei, Pan Limin, et al. Chinese sentential semantic mode and verification [J]. Transactions of Beijing Institute of Technology, 2013, 33(2): 166-171. (in Chinese)
[9] Jia Yande. Chinese semantics[M].Beijng: Peking University Press, 2005: 249-265. (in Chinese)
[10] Luo Senlin, Liu Yingying, Feng Yang, et al. Method of building BFS-CTC: a Chinese tagged corpus of sentential semantic structure[J]. Transactions of Beijing Institute of Technology, 2012, 32(3): 311-315. (in Chinese)
[11] Liu Yingying, Luo Senlin, Feng Yang, et al. BFS-CTC: A Chinese corpus of sentential semantic structure [J]. Journal of Chinese Information Processing, 2013, 27(1): 72-80. (in Chinese)
[12] Lafferty J, McCallum A, Pereira F. Conditional random fields: probabilistic models for segmenting and labeling sequence data [C]∥Proceedings of the 18th International Conference on Machine Learning 2001 (ICML 2001), San Francisco, CA, USA, 2001.
[13] Bohnet B,Nivre J. A transition-based system for joint part-of-speech tagging and labeled non-projective dependency parsing [C]∥EMNLP-CoNLL, Stroudsburg, PA, USA, 2012.
[14] Bohnet B,Kuhn J.The best of bothworlds-a graph-based completion model for transition-based parsers [C]∥Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics (EACL), Stroudsburg, PA, USA, 2012.
[15] Chen P, Bowes C, Ding W, et al. Word sense disambiguation with automatically acquired knowledge[J]. IEEE Intelligent Systems, 2012, 27(4): 46-55.
[16] Gildea D, Jurafsky D.Automatic Labeling of semantic roles [J]. Computaional Linguistics, 2002, 28(3): 245-288.
(Edited by Cai Jianying)
10.15918/j.jbit1004-0579.201524.0116
TP 391.1 Document code: A Article ID: 1004- 0579(2015)01- 0110- 08
Received 2013- 07- 23
Supported by the Science and Technology Innovation Plan of Beijing Institute of Technology (2013)
E-mail: panlimin_bit@126.com
猜你喜欢
杂志排行

Journal of Beijing Institute of Technology的其它文章
- Numerical simulation of the delay arming process of initiating explosive brakes
- Optimized design of biconical liner by orthogonal method
- Wideband acoustic source localization using multiple spherical arrays: anangular-spectrum smoothing approach
- Influence of eddy current on transient characteristics of common rail injector solenoid valve
- Designing the cooling system of a hybrid electric vehicle with multi-heat source
- Novel miniature pneumatic pressure regulator for hopping robots