计算密集型海量数据查询处理关键技术分析
2015-04-21郭川军
李 俭,郭川军,姜 微
(哈尔滨金融学院 计算机系,黑龙江 哈尔滨150030)
随着社会的数字化变革、因特网的蓬勃发展及国民经济的迅猛崛起,全球各个领域的数据呈爆炸式增长。数据作为信息的载体,已成为包括金融经济、交通物流、国家安全和社会生活等各个领域最核心、最有价值的资源。因此,为了发现数据背后隐藏的巨大价值,从商业应用领域到科学计算领域,面对海量数据的计算密集型应用需求日益增加,许多电子商务网站和社交网站需要存储海量异构的页面信息、用户信息以及访问日志等,并对这些数据进行快速而准确地访问以及面向商业市场前景的智能计算。这些典型的计算需求包括用户购买能力分析、定向广告投递效果查询、产品增值的市场分析等,这些已成为互联网中的核心问题。基于这些海量数据的查询分析,从中获取有利于互联网用户体验的信息,从而形成商业利益的有效价值链是十分有意义且充满挑战的工作。实现对计算密集型海量数据的有效查询,需要从各项技术角度加以协调。
1 关键技术介绍分析
1.1 大规模分布式存储技术
大规模分布式可靠存储系统可为计算密集型查询任务提供重要的后台支撑,同时满足系统在读写效率、查询速度和吞吐量上的要求。在互联网中,计算机用户实现大规模的文件存储、共享和交换时,基本上都是基于P2P技术,比较著名的基于P2P的分布式存储系统有 Napster、Kazaa、Ocean Store等。其中,Napster将系统中所有计算机节点认为是同一级别,文件标识号和文件存储节点间存在一个约定好的映射关系,这使得用户在查找某个文件时,可以通过计算快速定位到文件存储节点,从而建立连接并下载文件。
随着计算机技术的飞速发展,个人计算机进行独立工作的能力越来越强,而且会有大量的计算和存储资源处于闲置状态,并且一天当中会有近半数以上的计算机处于开机联网状态。要想在互联网的结构特点上,以现有资源为基础,更有效地发挥互联网的作用,就需要整合互联网上众多零散的个人计算机,将其作为统一的节点进行管理,并充分利用它们各自的空闲存储空间,形成一个高可靠、高性能、海量而廉价的分布式存储系统。
因此,可以将节点Node和用户文件File作为系统中的独立实体,实现分布式存储系统。该存储系统在节点通过网络连接起来的基础上,用户文件以副本的形式存储到多个较近的节点中,文件内容会随着用户的操作随时同步更新。对于大文件而言可以直接存储;对于小文件来说,直接存储会浪费存储空间,所以可采用将多个小文件进行聚集压缩而形成一个复合文件的形式来存储,而在访问时可以不解压而直接对文件进行各种操作。另外,各节点除了提供存储空间,还可以提供计算资源,从而使系统更加高效。
从系统功能的角度可以将系统由下至上分为物理层、路由层、数据层、会话层和应用层。物理层是采用网络将各独立节点进行连接,是整个系统的物理基础;路由层通过路由算法进行节点和文件定位,以便就近存取文件;数据层通过冗余的文件副本提供数据容错,同时提供平衡负载和文件压缩等功能,以便提高文件访问效率;会话层为用户提供节点登录和目录管理功能,并保证了数据安全和高效的数据传输;应用层为用户提供了统一的虚拟海量存储空间接口,用户在系统任意一个结点上登录都可以自如地访问分布式存储空间,包括上传、下载文件,还可以实现文件共享。
由于存储的数据涉及到结构化和非结构化数据,鉴于结构化数据适于实时访问以及方便存储敏感数据的优点,以及非结构化数据的低成本、高性能、自由性强、可扩展程度的优点,在存储数据的同时,可以将结构化数据和非结构化数据融合存储,有效整合,以简代繁,实现数据访问与共享的有效隔离。分布式存储系统的系统层次结构如图1所示。
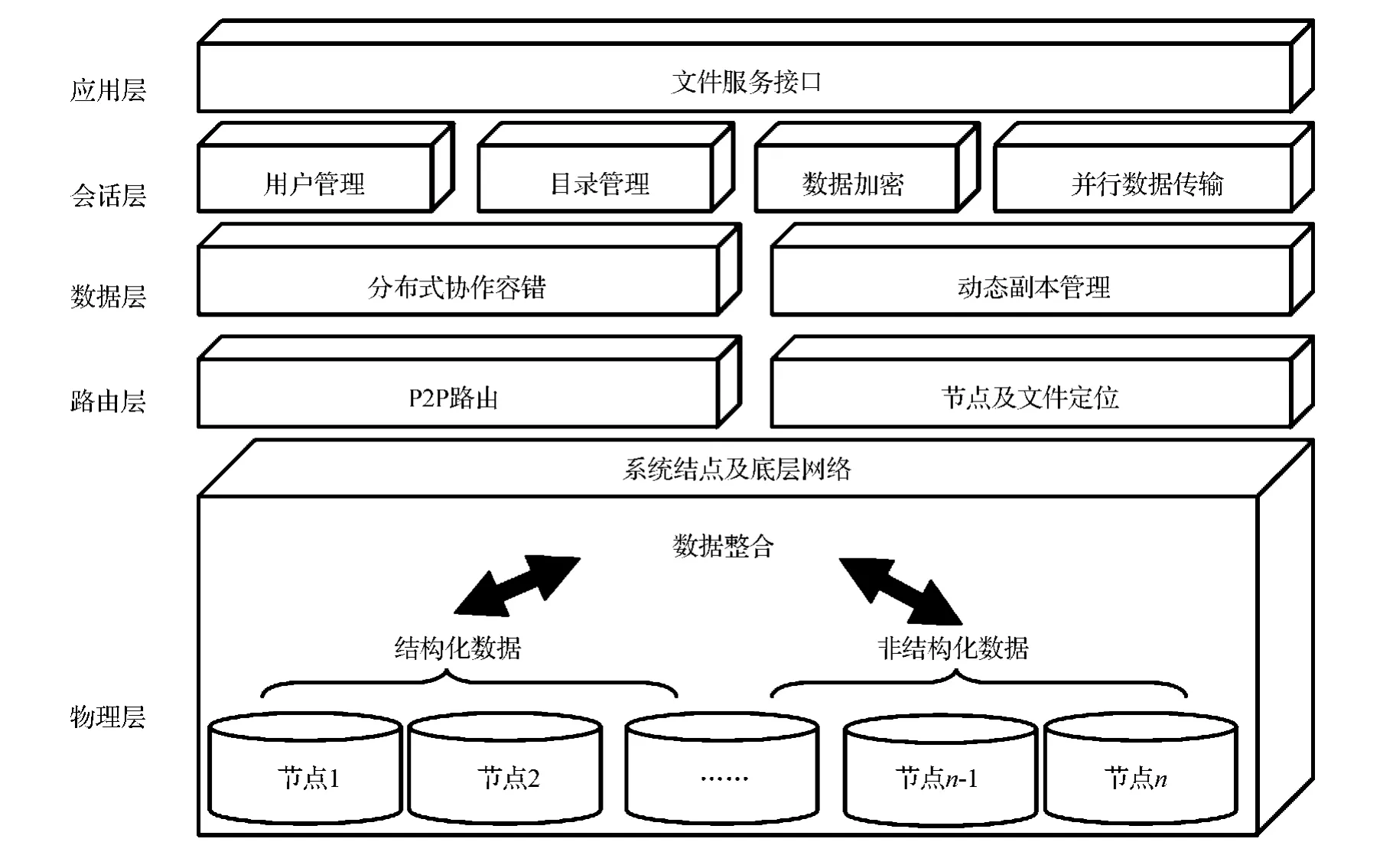
图1 分布式存储系统层次结构
1.2 面向海量数据的索引机制
在数据库研究领域,数据通常被分成结构化数据和非结构化数据两种类型。结构化数据具有统一的纲要,关系表中的每个元组都有相同的属性和数据类型(比如数值或字符串),关系数据库可以对它们进行统一的存储和管理。相比之下,非结构化数据包括文本文件、XML数据、社交网络数据等,这些数据没有统一格式,无法用关系数据库实现。在复杂的实际应用中,系统甚至可能需要同时处理结构化和非结构化数据。为了方便用户对各种数据类型的查询和分析,需要根据不同的数据结构研究合理的数据存储索引机制,以提高计算密集型查询和分析的时间效率。
1.2.1 结构化数据的索引策略
对于海量结构化数据,如果仍要遵循数据一致性规则,将导致数据更新延迟、局部数据失效、系统扩展性受限等问题。因此,应放宽对数据一致性的要求,取消复杂的关联查询,结合具体的应用场景,提高系统的可用性。可以采用倒排索引技术,通过词典和倒排链表实现字符串到文件的映射,以便根据查询词快速定位。对于海量结构化数据,则需要分布式处理索引,通过索引分割建立索引集群。索引分割可以采用混合分割,即根据数据特点分别对索引进行基于文档的纵向分割和基于词的横向分割。此时,整个文档集合可以局部的纵向分割先划分成N份,然后对于每一个子文档集合在M个索引集群节点上,针对查询频率高的词进行基于“词”的横向分割。
1.2.2 非结构化数据的索引策略
对于非结构化数据,首先需要在分析数据的基础上进行预处理,然后根据不同的数据特点通过适当的算法进行数据原始特征采集和转化,生成数据的有效特征,从而得到高维数据,最后实现数据的存储。这里的特征提取算法尤为重要,算法不但要最大程度地降低特征维度,还要保证所提取的数据特征的有效性,力求从中得到更多有价值的数据和信息。
随着大数据时代的到来,数据维度不断增加,树形索引技术已无法满足日益增加的索引复杂度需求,因此,可以采用LSH算法,利用 Hash函数族,在保持原高维数据空间相似性的前提下,将高维索引数据转化为低维数据,使高维数据点尽可能地Hash到相同桶中,同时要均衡各节点的负载,从而有效地解决高维数据的相似性搜索问题。但是LSH算法将会把大量时间用于计算桶合并后查询点与这些高维数据点集合的距离,以便选取最近的一些数据点作为最终的查询结果返回,从而浪费大量时间。为了解决这个问题,可以在Hash函数中融入谱分析技术,即对高维数据进行谱分析,对给定的一个高维样本数据库进行训练,通过特征函数分析高维数据样本的平均分布,以构造谱Hash函数,从而保证将相似的高维数据点Hash到一个相似值上。
对于不同种类的高维数据,则要充分利用概率分布特点,使其映射到不同的节点空间中,将这种分片策略集成到非结构化数据分布式索引系统中,以实现高效查询。LSH高维数据划分与节点映射如图2所示。
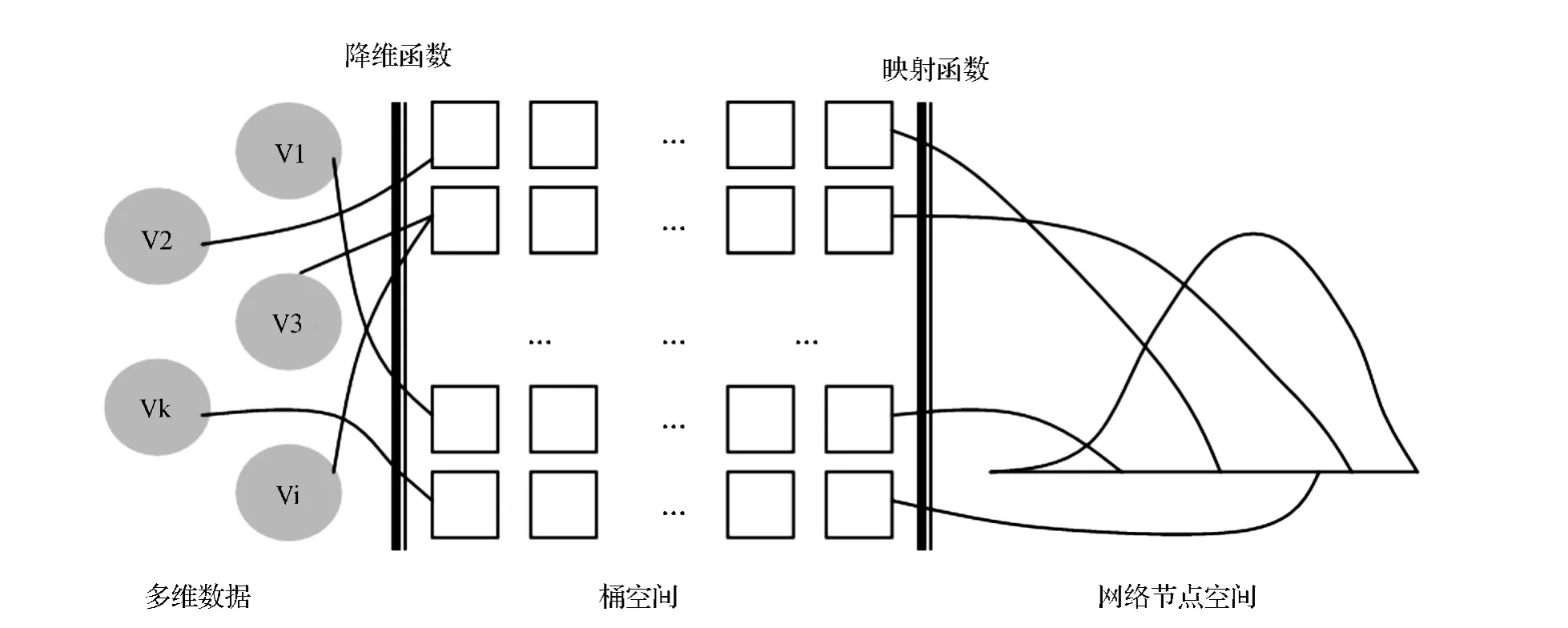
图2 LSH高维数据划分与节点映射
1.3 高效并行聚集查询技术
在对海量数据实现了分布式存储及索引机制的基础上,还要针对具体查询进行处理和优化。由于海量数据库的应用中具有大量聚集查询,因此,要重点针对海量数据的聚集查询操作进行处理和优化。
如果系统经常接收到的查询是聚合查询,则可以采用刷新缓存的方法来进行。首先,系统要为每种聚集查询语句分别建立缓存表,在每一个时间片内执行一次聚集查询操作,然后将带有时间标记的查询结果存入到相应的缓存表中,以后一旦有查询需要处理,则按时间段到相应的缓存表中去匹配即可。其次,如果用户提交的是已优化的聚集查询,就要按时间将其分解为探测查询和剩余查询,最后合并查询结果即可。
上述方案在收集缓存时需要直接访问源数据库,因此只适用于聚集查询种类不多的情况,如果聚集查询种类多,势必会降低系统性能。这时,可以将数据在入库前就进行分流,一段数据流载入小规模数据库,另一段数据流则直接载入源数据库。当需要收集缓存信息时,就可以直接在小规模数据库上进行操作,然后将结果存入缓存。相应的时间片结束时,要在中间结果数据库中执行该时间片内的聚集查询,然后将查询结果存入缓存表,同时将中间结果数据库中该查询对应的缓存表截断,以便收集下个时间片的缓存信息。由于中间结果数据库中的数据容量与主数据库相比要小得多,因此在其上面做聚集查询操作效率非常高,并且不会影响到主数据库系统的性能。
2 并行编程模型
为了使并行编程不依赖于具体的硬件平台,让更多的人能够在比较低的起点上快速有效地开发并行程序,实现串行程序的并行执行,需要设计出合理有效的并行编程模型。并行编程模型可以采用层次化结构设计。
首先,为实现并行编程的平台无关性,需要将与平台相关的底层所有并行函数库进行封装,用户可以通过统一的与平台无关的上层API接口进行并行程序开发,程序可以在不同的计算平台上实现编译,同时将上层API自动映射到和平台相对应的函数库中。
其次,为了大规模计算问题的并行化,解决复杂问题,要通过任务调度策略和数据分配功能,使多任务计算问题在执行时达到较低的平行开销和较好的负载均衡。对一个计算问题,可以根据任务规模分别采用不同的粒度,并将其划分为多个独立的计算单元,然后通过线程的并发同步解决计算问题。每个任务通过一个数据调度器对数据按行或按列划分,将数据平均分配到各个线程上,每个数据块分配给哪个线程可以是顺序分配,也可以是循环分配或是随机分配。
最后,为了增强系统的可扩展性,应提供应用函数库和运行时函数库的扩展手段,使系统可以支持任何最新低层计算平台,并可针对某一具体应用领域开发特有的编程模型。
3 结束语
本文致力于面向计算密集型的海量数据查询处理关键技术的分析与研究,探索了在大数据环境下,根据不同数据的特点搭建分布式存储系统,以提高查询效率为目的而采用降维处理实现索引机制,并针对海量数据的聚集查询操作进行处理和优化,同时分析了为面向更多用户而设计的与平台无关的并行编程模型。通过这种系统架构,更好地规划完成了对计算密集型海量数据的存储,并实现了高效查询及数据处理。需要进一步研究的是,如何在分布式高效存储且低冗余的情况下更好地保证数据的可靠性;如何使并行编程模型的并行执行和任务调度对所有编程人员和用户透明。随着大数据时代的发展,海量数据查询仍是一个值得深入研究的领域。
[1] 周旭.面向Internet的大规模分布式存储技术研究[D].成都:电子科技大学,2004.
[2] 于滨.海量非结构化数据分布式分析与检索[D].杭州:浙江大学,2012.
[3] 李卓浩.面向海量数据管理的分布式倒排索引研究与应用[D].杭州:浙江大学,2012.
[4] 徐小龙,吴家兴,杨庚,等.基于大规模廉价计算平台的海量数据处理系统的研究[J].计算机应用研究,2012(2):582-585.
[5] 马俊涛,黄如生.以混合存储模型实现云计算平台对电信海量数据的处理[J].移动通信,2011(7):76-79.
[6] 李婷.一种平台无关的并行编程模型的设计与实现[D].合肥:中国科学技术大学,2014.
