一种基于排序学习方法的查询扩展技术
2015-04-21林鸿飞
徐 博,林鸿飞,林 原,王 健
(大连理工大学,辽宁 大连 116024)
一种基于排序学习方法的查询扩展技术
徐 博,林鸿飞,林 原,王 健
(大连理工大学,辽宁 大连 116024)
查询扩展作为一门重要的信息检索技术,是以用户查询为基础,通过一定策略在原始查询中加入一些相关的扩展词,从而使得查询能够更加准确地描述用户信息需求。排序学习方法利用机器学习的知识构造排序模型对数据进行排序,是当前机器学习与信息检索交叉领域的研究热点。该文尝试利用伪相关反馈技术,在查询扩展中引入排序学习算法,从文档集合中提取与扩展词相关的特征,训练针对于扩展词的排序模型,并利用排序模型对新查询的扩展词集合进行重新排序,将排序后的扩展词根据排序得分赋予相应的权重,加入到原始查询中进行二次检索,从而提高信息检索的准确率。在TREC数据集合上的实验结果表明,引入排序学习算法有助于提高伪相关反馈的检索性能。
信息检索;查询扩展;伪相关反馈;排序学习
1 引言
查询扩展是一门重要的信息检索技术,它能够利用自然语言处理等多种方法对用户提交的查询进行分析和完善,进而提升信息检索的性能。伪相关反馈技术是当前较为热门的一种查询扩展方法,它假设用户提交查询进行初次检索后得到的前N篇文档与原始查询是相关的,而在这些文档中出现频率较高的词与原始查询也更为相关,因此可以从中提取一些高频词来对原始查询进行补充,从而更加准确地理解用户的信息需求。目前许多基于伪相关反馈的研究都关注于扩展词的选择,基于SVM的分类方法被用来对扩展词的好与坏进行区分[1],进而选择更加有用的扩展词来提升查询扩展的性能;在冗长查询中引入回归方法对查询词进行加权[2],从而提高查询中关键词的权重,更为清晰地描述查询意图;利用改进的马尔科夫随机域模型对查询词赋予权重[3],结合词与词之间的语言和统计特征对查询词进行排序[4]等。这些研究表明,伪相关反馈作为一种局部上下文分析的查询扩展技术相比于传统的全局分析方法具有更好的检索性能,但如何对查询扩展词赋予权重关系到检索性能能否被进一步提升。排序学习[5]是机器学习与信息检索相结合的研究领域。排序作为信息检索中的核心问题一直以来备受研究者的关注,而排序学习是借鉴机器学习的方法,通过训练集训练排序模型,并将训练好的模型应用于测试集的排序任务中,从而提高排序的准确率和召回率[6]。从广义上讲,很多问题实际上都可以归结为排序问题,比如文本检索、问答系统、文档摘要、推荐系统等。近年来许多经典的排序学习算法被相继提出,并被证明能够很大程度上提升检索性能,如RankBoost[7],RankSVM[8-9]等。当前,一些研究致力于在查询扩展中引入排序方法,比如在查询日志中挖掘查询推荐,并对推荐的查询进行排序[10];基于查询会话发现替代查询,并对替代查询进行排序[11]等,但很少有研究关注于利用排序方法对伪相关反馈技术进行改进。
本文提出了一种基于排序学习方法的查询扩展技术,该方法利用排序学习对扩展词进行排序,从而为扩展词赋予更加合适的权重,在选取扩展词的过程中,排序学习方法综合考虑了扩展词的多种统计特征,更好地完成了查询重构。与文献[12]利用外部资源挖掘扩展词不同,本文利用伪相关反馈文档提取扩展词,并关注于伪相关反馈方法性能的提升,而在实际应用中利用伪相关反馈技术虽然能够得到理想的扩展词,但是仅利用伪相关反馈方法的打分为扩展词赋的权重并不能准确地描述扩展词与查询词的相关程度,于是我们在扩展词的选择中引入排序学习方法,相比于只应用单一特征赋予扩展词权重的传统伪相关反馈技术,排序学习方法可以在查询扩展中考虑到更多扩展词的相关性信息,因而能够更加充分的描述扩展词与原始查询的相关性,从而改善原始伪相关反馈扩展词加权不够精准的问题,更好地胜任查询扩展任务,提高信息检索的性能。
2 基于排序学习算法的查询扩展技术
2.1 基于伪相关反馈的查询扩展词选择
在介绍如何将排序学习方法引入查询扩展之前,我们先简要介绍一下利用伪相关反馈方法从反馈文档中提取扩展词的方法。这里的反馈文档是指对查询进行初次检索后得到的前N篇文档。我们采用语言模型进行初次检索,利用查询扩展中的相关模型[13],来提取所需的扩展词。相关模型(Relevance Model)是一种重要的基于语言模型的查询扩展技术。在扩展词权重的赋予中,相关模型分别建立了查询语言模型和文档语言模型,并通过二者的结合来对反馈文档中的词的重要性进行衡量,进而选出相关性得分最高的扩展词,用于查询扩展。
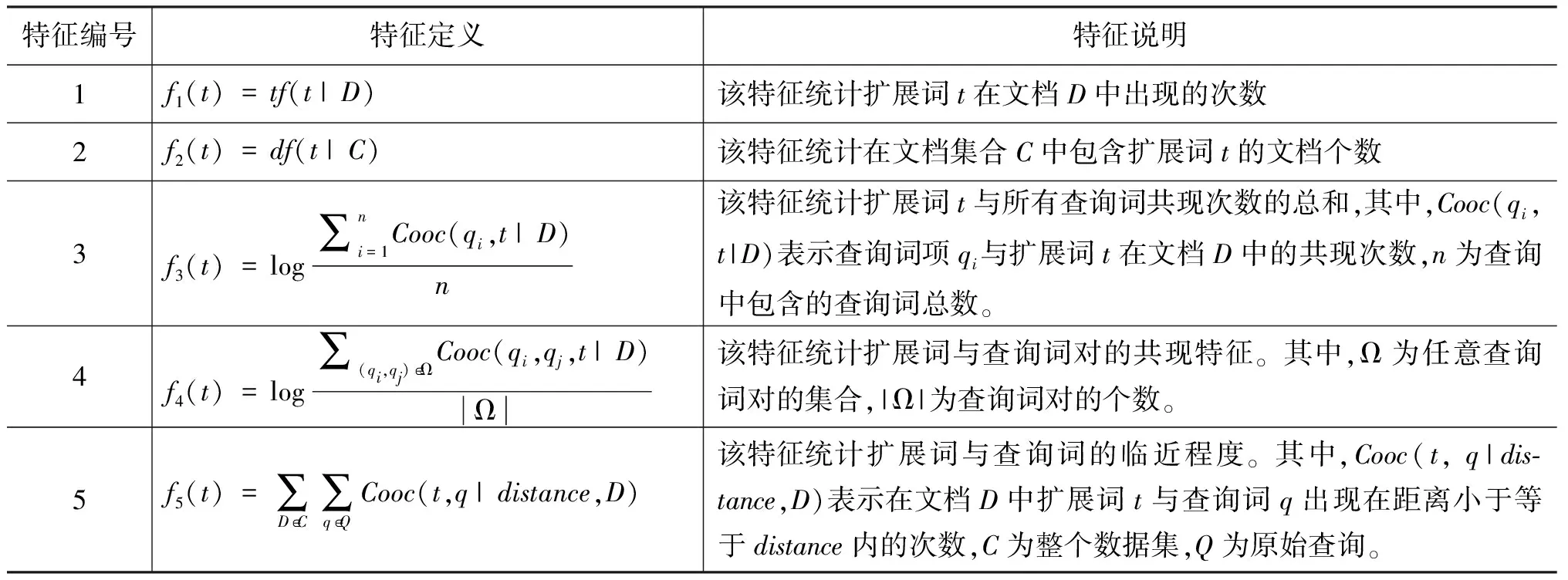
表1 扩展词特征的定义
2.2 扩展词的相关性标注
在利用相关模型得到扩展词集合后,我们需要对扩展词的相关性进行标注。标注的目的是为了利用排序学习方法训练基于扩展词的排序模型,进而对扩展词进行重新排序。扩展词的相关程度可以通过扩展词对检索性能的影响来衡量,本文在词的相关性标注中,首先将扩展词加入到原始查询中进行检索,然后将检索结果与原始查询结果进行比较,来确定扩展词是否有助于提升检索性能,进而标注扩展词的相关性,具体如公式(1)所示。
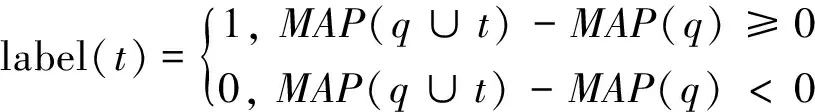
(1)
本文选择平均准确率(MAP)对检索结果进行评价。从公式(1)可以看出,当把扩展词加入到原始查询中进行检索时,若平均准确率相比于原始查询的平均准确率有所提升,则认为该查询词为相关扩展词并标注为1,否则将该扩展词标注为0。
2.3 扩展词特征选取
为了训练针对于扩展词的排序模型,我们还需要进一步将扩展词表示成词特征向量的形式,即通过不同的特征来建模扩展词与原始查询的相关性,进而表征不同的词与原始查询的相关程度,以及不同的扩展词之间的差异程度。本文定义了若干不同的词特征,它们不仅包含了信息检索领域传统的统计信息,比如扩展词在数据集合中出现的词频,文档频率等,而且为了能够更加充分地描述扩展词的相关程度,我们也在特征选取中采用了扩展词的共现信息作为词排序的特征,比如考虑了诸如扩展词与单一查询词的共现次数,扩展词与多个查询词的共现次数等特征。在模型的训练过程中,每一个扩展词都被表示成了特征向量的形式。本文所定义的词特征如表1所示。
在表1中,特征1和特征2分别利用了文档中的词频和文档频率信息;特征3利用了扩展词与单一查询词的共现信息;特征4利用了查询词对和扩展词的共现信息,相比于特征3,这个特征包含了更强的语义信息,研究表明这种特征能够体现扩展词与整个查询在语义层面的关系;特征5从另一个角度利用了共现信息,它的含义是若扩展词与查询词在一篇文档中出现的距离越近,则说明它们的相关程度越大,即把两个词在整个数据集中出现在同一篇文档一定距离内的文档的总数作为特征,在本文实验中,分别取5和12作为distance的大小进行特征的提取。
本文所使用的特征都是从实验数据集合中提取的。实验数据集采用了TREC提供的Robust2004数据集。在计算特征1和特征2时,我们分别对提取的特征值进行了取对数和除以特征最大值两种处理,得到了另外四种新的特征。而在数据集文档中,每一篇文档都包含了Text,Title,Dateline三个不同数据域,每个数据域对于词特性的描述能力是不同的,因此我们不仅基于整篇文档进行了词特征的抽取,而且还基于每个不同的域也分别进行了词特征的提取,并把从这四个部分提取的特征分别作为不同的特征应用于词排序过程中,也就是说针对于每个扩展词我们分别提取了与上述描述对应的总计36个不同特征。
2.4 排序学习方法
本节主要介绍三种本文使用的排序模型。它们分别是Regression, RankSVM和RankBoost。
Regression是一种传统的机器学习方法也是最为直接的一种排序学习方法,它能够直接将排序问题转化为回归问题进行处理。在本文的实验中,回归方法将每一个词对应的特征向量作为输入,输出该词的相关性得分。RankSVM是一种重要的排序学习方法。该算法将支持向量机(SVM)引入到了排序问题中,不仅集成了支持向量机的一些优良特性,而且很好地将其转化到了排序问题中,取得了较好的排序效果。RankBoost是一种重要的排序学习算法,该算法采用机器学习领域的提升方法进行预测模型的训练,与其他基于提升的方法类似,RankBoost是通过若干次的迭代过程完成模型训练的,在每一次迭代中该算法选出一个最优的弱学习器作为本轮迭代的分类器对于所有对象进行分类,并根据排序中待排序对象的权重分布和本轮迭代的结果为该弱学习器计算权重,并更新下一轮迭代中待排序对象的权重分布,最终的预测模型为迭代过程中找到的所有弱学习器的线性加权和,最后将该模型用于新对象的排序。
近年来的研究表明,这三种算法在检索中具有较好的排序性能和较高的效率,所以本文将它们引入伪相关反馈中,对查询扩展过程进行改进,即对扩展词集合中的扩展词进行重新排序和重新加权。
2.5 基于排序学习算法的查询扩展流程
本节主要介绍本文如何将排序学习算法用于查询扩展的扩展词排序。图1给出了基于排序学习方法的查询扩展架构的流程。如图所示,首先我们利用语言模型进行初次检索,选择初次检索的前N篇文档作为扩展词的来源,接下来采用相关模型选择一组高频词作为扩展词,然后对词的相关性进行标注,并把扩展词表示成特征向量的形式,然后利用排序学习方法对提取的扩展词进行重新排序,并根据排序模型赋予的得分对每个扩展词赋予不同的权重,将重新加权后的扩展词加入到原始查询中形成扩展后的新查询,最后对扩展后的新查询进行检索。

图1 查询扩展流程
3 实验
3.1 实验数据集
本文实验采用了TREC的英文语料集合Robust2004以及相对应的查询文档和相关性标准评估文档,它是2003年TREC Robust检索任务所使用的数据集。实验中,我们将全部150个的查询分成三部分,分别为训练集、验证集和测试集,用于对排序模型的训练,对算法参数的选择和对测试数据的预测。检索时,我们只使用了查询的Title部分作为初始查询。在索引的创建过程中,我们使用Porter算法分别对语料和查询进行词干化处理,并且根据停用词列表为数据集和查询去停用词,此外,分别为每一篇文档的Title部分、Text部分、Dateline部分创建了不同域,用于针对于不同的域的统计特征的提取。
3.2 实验设计
本文采用Robust2004作为实验语料。用于比较的基准方法为基于语言模型[14]的初次检索和基于相关模型的伪相关反馈检索。实验针对于三种排序学习方法Regression, RankSVM和 RankBoost进行了词排序模型的训练,并将训练后的词排序模型用于扩展词的加权。
本文实验采用了Indri检索系统作为基础的检索环境,在实验中,对原始语料建立索引,对于查询集合中的每一个查询,首先进行初次检索,在检索得到的前N篇文档中,利用伪相关反馈技术提取出现频率较高的前k个扩展词作为扩展词集合。针对于每一个扩展词用前文中提到的特征提取方法,对扩展词进行相关性标注,然后将所有扩展词表示成特征向量的形式。之后按照8∶1∶1的比例将特征文件划分为训练集、验证集和测试集,采用十折交叉验证实验进行模型的训练,最后将训练完的模型用于对测试集中与同一查询相关的扩展词的排序,并将重新加权后的扩展词列表加入到原始查询中进行二次检索。其中,根据TREC比赛的最佳参数,我们设置相关参数:N=10,k=50。此外在将扩展词加入到原始查询中时,将扩展词集合与原始查询的比重分别设置为0.2和0.8。
3.3 实验结果和分析
本文分别采用了信息检索领域广泛采用的MAP、P@k和NDCG@k 三种评价指标对于实验结果进行评价。在后文的图和表中,QL表示直接用原始查询进行初次检索时的结果,RM表示用基于相关模型的伪相关反馈进行检索时的结果,RankBoost,RankSVM,Regression分别表示利用这三种算法对伪相关反馈得到的扩展词进行重排序后检索的结果。表2列出了上述几种算法进行检索结果评价时,当k=3,5,10时的P@k和NDCG@k评价结果以及MAP的评价结果。为了使结果对比更为清晰,我们用图2和图3分别对上述不同算法的实验结果在P@k和NDCG@k上当k值变化时的评价指标进行了对比。图中纵坐标为评价函数的分值,横坐标为处于不同位置的评价指标函数。
通过对比多种方法的实验结果可以看出,相比于基于语言模型的初次检索,原始伪相关反馈在各种评价指标上都有所提升;而基于排序学习的方法通过对扩展词的权重进行重新计算,使得检索性能进一步提升。从表2可以看出,将回归算法引入到词排序中后的检索性能与原始伪相关反馈的性能相似,只在P@k评价指标上略好于后者,而在其他指标上不如后者,也就是说将回归算法用于扩展词的重新排序并不能对检索性能产生较大提升;而将RankSVM算法引入到词排序中相比于回归方法的检索性能有了较大提升,仅在个别评价指标上略差于伪相关反馈,并且平均准确率也获得了一定的提升;基于RankBoost的查询扩展相比于原始伪相关反馈在多种评价指标上都有了较大幅度的提升。因此我们认为基于排序学习的查询扩展技术对于扩展词的重新排序更为准确,相比于原始伪相关反馈在整体上具有更好的检索性能,而RankBoost算法对检索性能的提升更为显著。
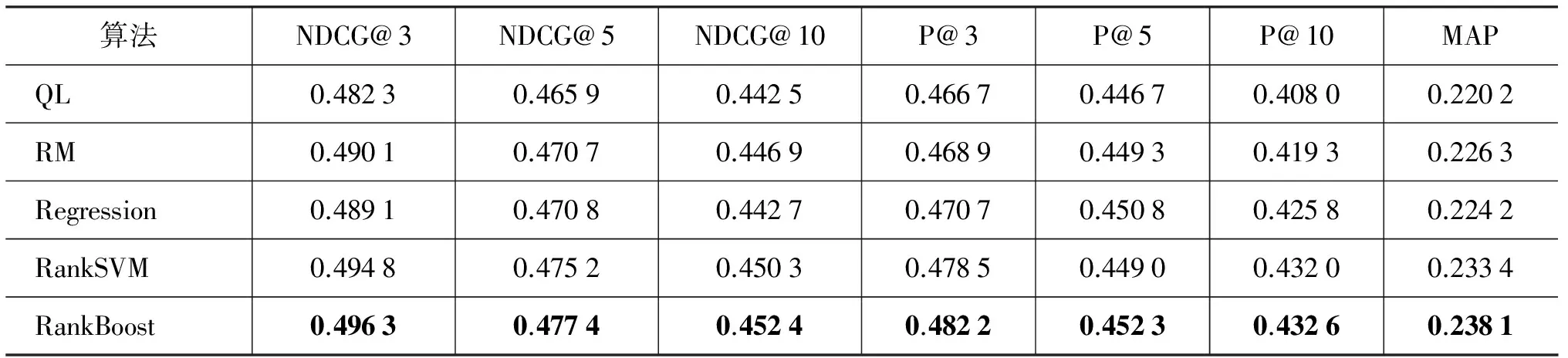
表2 检索结果的评价比较
从图2和图3中我们可以看到类似的趋势。基于原始伪相关反馈和基于回归方法的词排序算法,二者有较为相似的检索性能;而将RankSVM和Regression两种算法引入到词排序过程的查询扩展在P@k和NDCG@k评价时的趋势较为相近,而基于RankBoost的查询扩展在多组评价指标上体现出了更大的优势。这一定程度上是由于Regression在排序过程中只考虑了每个扩展词的绝对分数,而忽略了扩展词之间的相关性,因此对于扩展词重排序的结果不太理想;而RankSVM和RankBoost二者相比,前者是基于分类的SVM算法,后者是基于提升算法,通过实验结果的评价指标可以看出,基于
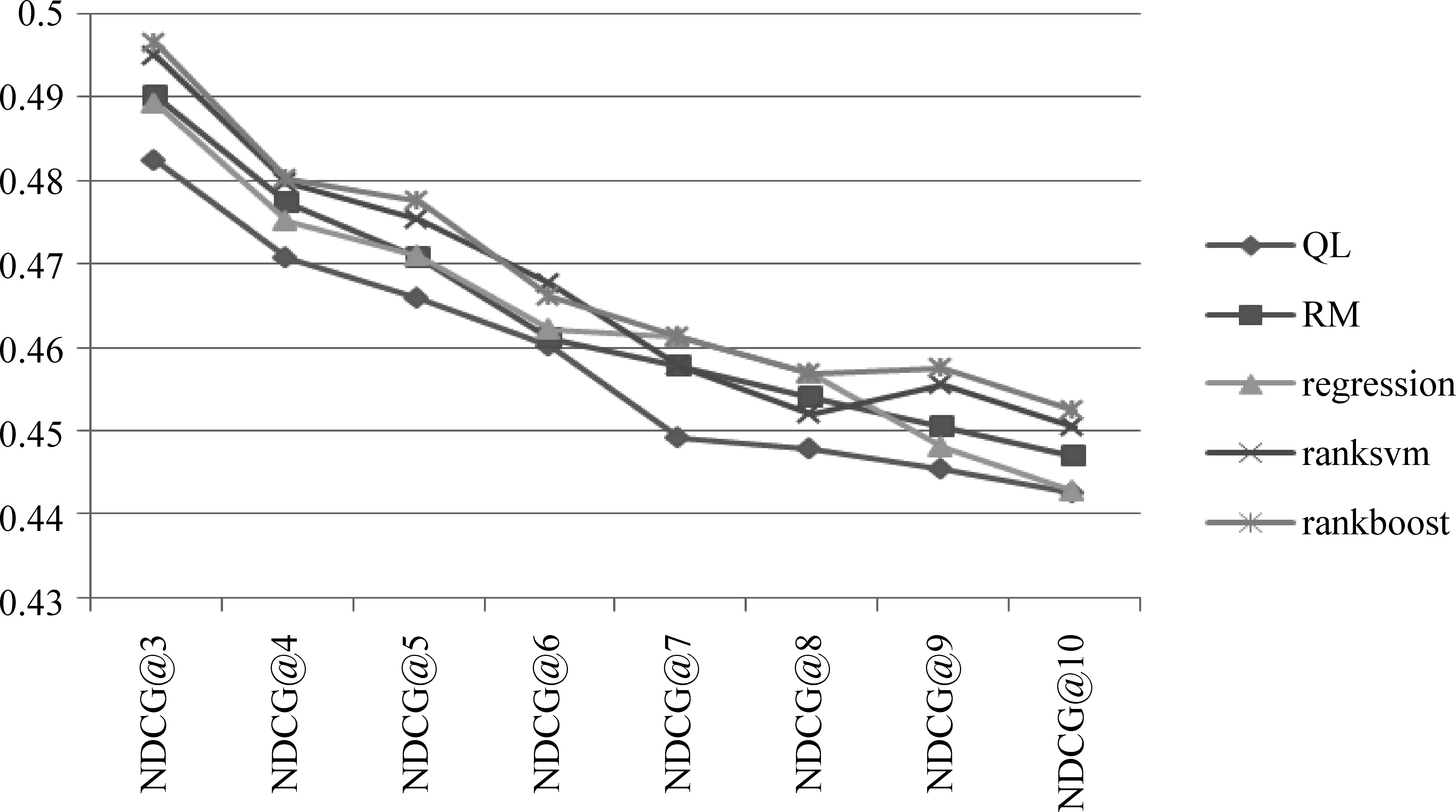
图2 NDCG@k评价结果的比较
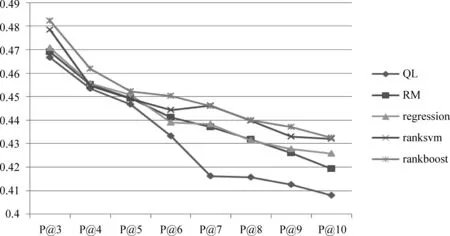
图3 P@k评价结果的比较
提升算法的RankBoost算法在查询扩展的词排序选择阶段具有更大的优势,所以我们认为选用了RankBoost算法对扩展词进行重排序对检索性能产生了更大的帮助。
我们之所以将排序算法引入伪相关反馈进行查询扩展,是由于原始伪相关反馈对于扩展词权重的分配只考虑了伪相关反馈方法赋予扩展词的分数,而伪相关反馈在给扩展词加权的过程中仅仅考虑了扩展词的词频、文档频率等较少的特征,因而扩展词的权重并不是最合适的,而在引入了排序学习算法后,在对于扩展词的权重计算时,考虑到了更多关于扩展词的统计特征,因而更好地完成了查询的重构,取得了更高的检索性能;而RankBoost排序学习算法采用了机器学习中的提升方法,提升方法可以在模型的训练过程中,根据模型对于训练数据的训练结果,不断地构造弱学习器对于训练结果进行提升,最终得到的模型是多轮迭代后的弱学习器的集合,因此能够更好地胜任扩展词排序的任务。
4 结论与展望
本文提出了一种基于排序学习方法的查询扩展技术。相比于传统的伪相关反馈技术,本文提出的方法获得了更好的检索性能,它首先对伪相关文档中提取的扩展词进行了相关性标注,把扩展词表示成了特征向量的形式,然后利用排序学习算法对所有的扩展词进行排序,并在此基础上根据扩展词的排序得分赋予不同扩展词不同的权重,权重表明了扩展词与原始查询的相关程度,在此基础上完成了查询的重构,既提升了伪相关反馈方法对于扩展词加权的精准度,又进一步提升了检索的性能。在TREC数据集上的实验结果表明将排序学习方法引入到查询扩展中确实有助于扩展词相关性的判断,改善伪相关反馈过程中扩展词权重不够准确的问题,而RankBoost算法在词排序中更为有效,对检索性能产生了较大的提升。本文提出的利用排序学习方法对于查询扩展进行改进的思路具有较好的推广性。未来的工作可以从以下几个方面继续进行,一方面可以尝试使用其他的排序学习方法对扩展词排序进行改进,另一方面可以在排序过程中,引入更为适合的统计特征,来表征不同查询词的重要程度,从而进一步提升检索性能。
[1] G Cao, J Y Nie, S Robertson. Selecting good expansion terms for pseudo-relevance feedback[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 2008: 243-250.
[2] L Matthew, A James, C Bruce. Regression Rank: Learning to Meet the Opportunity of Descriptive Queries[C]//Proceedings of the 32th European Conference on IR Research, Toulouse, France, 2009: 90-101.
[3] L Matthew. An Improved Markov Random Field Model for Supporting Verbose Queries[C]//Proceedings of SIGIR2009, American, 2009: 476-483.
[4] C J Lee, R C Chen, S H Kao and P J Cheng. A Term Dependency-Based Approach for Query Terms Ranking[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2009: 1267-1276.
[5] T Y Liu. Learning to Rank for Information Retrieval [J]. Foundations and Trends in Information Retrieval, 2009, 3(3): 225-331.
[6] T Qin, T Y Liu, J Xu, et al. LETOR: Benchmark Collection for Research on Learning to Rank for Information Retrieval[C]//Proceedings of SIGIR 2007 Workshop on Learning to Rank for Information Retrieval (LR4IR 2007), Amsterdam, The Netherlands, 2007: 3-10.
[7] Y Freund, R D Iyer, R E Schapire, et al. An Efficient Boosting Algorithm for Combining Preferences[J]. Journal of Machine Learning Research, 2003, 4:933-969.
[8] Y Cao, J Xu, T Liu, et al. Adapting ranking SVM to document retrieval[C]//Proceedings of SIGIR2006, Seattle, WA, USA, 2006:186-193.
[9] T Joachims. Optimizing search engines using clickthrough data[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, Alberta, Canada, 2002: 133-142.
[10] U Ozertem, O Chapelle, P Donmez, et al. Learning to suggest: a machine learning framework for ranking query suggestions[C]//Proceedings of SIGIR2012, Portland, OR, USA, 2012: 25-34.
[11] R Jones, B Rey, O Madani, et al. Generating query substitutions[C]//Proceedings of WWW2006, Edinburgh, Scotland, UK, 2006: 387-396.
[12] Y Lin, H Lin, S Jin, et al. Social Annotation in Query Expansion: a Machine Learning Approach[C]//Proceedings of SIGIR2011, Beijing, China, 2011: 405-414.
[13] V Lavrenko, W B Croft. Relevance based language models[C]//Proceedings of SIGIR2001. New Orleans, Louisiana, 2001: 186-193
[14] J Ponte, W Croft. A language modeling approach to information retrieval[C]//Proceedings of SIGIR1998, Melbourne, Australia, 1998: 275-281.
A Query Expansion Method Based on Learning to Rank
XU Bo, LIN Hongfei, LIN Yuan, WANG Jian
(Dalian University of Technology, Dalian, Liaoning 116024, China)
Query Expansion is an important technique for improving retrieval performance. It uses some strategies to add some relevant terms to the original query submitted by the user, which could express the user’s information need more exactly and completely. Learning to rank is a hot machine learning issue addressed in in information retrieval, seeking to automatically construct ranking models determining the relevance degrees between objects. This paper attempts to improve pseudo-relevance feedback by introducing learning to rank algorithm to re-rank expansion terms. Some term features are obtained from the original query terms and the expansion terms, learning from which we can get a new ranking list of expansion terms. Adding the expansion terms list to the original query, we can acquire more relevant documents and improve the rate of accuracy. Experimental results on the TREC dataset shows that incorporating ranking algorithms in query expansion can lead to better retrieval performance.
information retrieval; query expansion; pseudo-relevance feedback; learning to rank

徐博(1988—),博士研究生,主要研究领域为搜索引擎、机器学习、排序学习。E⁃mail:xubo2011@mail.dlut.edu.cn林鸿飞(1962—),博士,教授,博士生导师,主要研究领域为搜索引擎、文本挖掘、情感计算和自然语言理解。E⁃mail:hflin@dlut.edu.cn林原(1983—),博士,讲师,主要研究领域为搜索引擎、机器学习,排序学习。E⁃mail:zhlin@dlut.edu.cn
1003-0077(2015)03-0155-07
2013-04-08 定稿日期: 2013-07-31
国家自然科学基金(61277370、61402075);国家863高科技计划(2006AA01Z151);辽宁省自然科学基金(201202031、2014020003)、教育部留学回国人员科研启动基金和高等学校博士学科点专项科研基金(20090041110002);中央高校基本科研业务费专项资金。
TP391
A
