汉语语义场网络中的无标度分布现象
2015-04-21姬东鸿萧国政
杨 华,姬东鸿,萧国政
(1. 贵州师范大学 数学与计算机科学学院,贵州 贵阳 550001;2. 武汉大学 文学院,湖北 武汉 430070;3. 武汉大学 计算机学院,湖北 武汉 430070)
汉语语义场网络中的无标度分布现象
杨 华1,2,姬东鸿3,萧国政2
(1. 贵州师范大学 数学与计算机科学学院,贵州 贵阳 550001;2. 武汉大学 文学院,湖北 武汉 430070;3. 武汉大学 计算机学院,湖北 武汉 430070)
语义场是词语意义联系在一起构成的语义系统。一门语言的所有子语义场合在一起,就是该语言的语义场。探索用复杂网络来表示汉语的语义场,基于联想场的概念,该文提出用复杂网络表示汉语的语义场。该网络的节点度,节点权值与边权值均服从无标度分布。展示结点度、结点权值、边权值在一定范围的内容,观察到一些在网络视角才能发掘出的现象。该文将较特别的现象展示给语言学界的专家们,期望引起共鸣,得到对这些现象的更合理解释。
语义场;复杂网络;无标度分布
1 引言
过去对语言的统计特性研究往往基于一阶统计,比如Zipf定理;近年来,复杂网络作为描述复杂系统的一种新颖范式,开始被用来描述语言这一复杂现象[1-3],学者们将语言表示为网络进行研究,尝试从网络的角度去探索语言的性质、认知过程、模拟人类语言的产生过程。观察到了大量在一阶统计上难以察觉的语言和认知心理的现象,并用于解释语言的根源、认知过程等。
汉语是世界最重要的语言之一,其统计规律和性质在语言学上具有重要的参考意义。目前该领域学者们对汉语网络研究已有一些进展。这些网络有基本词法网络[4-5],汉语词同现网络[6],汉语词汇的语法依存句法网络[7]等。实验表明这些汉语网络的拓扑结构表现出复杂网络的许多普适特性,如小世界特性等,并且与非汉语网络的特性非常相似。这说明尽管各种语言有自己的词法和句法,但具有内在的、相对固定的规律。也说明网络是挖掘这些规律的有力工具。
汉语语义场指的是汉语中的词语意义联系在一起构成的语义系统。基于联想语义场的思想,我们构建汉语的(子)语义场网络,观察到该网络中的无标度分布,并观察了网络中结点和边的内容,展现了从网络角度探测到的语言现象。
本文的组织结构如下: 第2节概览了目前普遍研究的语言网络;第3节介绍了联想语义场的概念,并基于该概念介绍了语义场网络的构建方法;第4节描述了无标度分布及其相关概念;第5节展现了语义场网络的无标度分布现象,其中对于节点权值、边权值的分布的研究是较为独特的,并观察了某些特定范围的词语特征;第6节指出了未来的工作。
2 语言复杂网络概览
复杂网络作为描述复杂系统的一种新范式,近年被用来描述语言这一复杂现象[1-2, 8]。很多文献中将语言的复杂网络称为语义网络(Semantic Network),这个概念不等同于“语义网(Semantic Web)”。
(1) 单词同现(相邻)网和单词搭配网。文献[8]从英国国家语料库的句子集合构造出两种图: 1)单词同现网: 顶点是语料库中所有的单词,一个句子当中的单词之间的距离指的是两个单词之间的单词个数加1,两个单词至少在一个句子里小于等于D(实验中D取2)的距离里出现过,则它们之间有一条边。2)单词搭配网: 类似单词同现网,但只保留了那些同现概率及互信息较高的同现词对之间的边。这两个网络都具有小世界和无标度等网络特性。文献[8-9]构建和分析了各种搭配网。这些网络被划分为核心词汇和比较周边的社会方言(sociolects)或者与具体话题相关的术语[2]。
(2) 依存语法网。依存语法网的构建方法[10]是: 以单词为顶点,如果两个单词至少在一个句子里分别以modifier(源顶点)和head(目标顶点)的依存语法角色同现过,则用modifier指向head的有向边将它们相连。文献[10]从捷克语、德语和罗马尼亚语的树库(tree bank)中的句子获得语法依存网络,这些句子的单词之间已根据它们的依存结构进行标注。该依存语法网有小世界特性;结点入度,出度服从幂律分布。
(3) 词典网络——专家知识网。同义词典可以定义词义之间的关系(如同义,反义,同音异义,同形异义);概念词典(如WordNet)能定义概念之间的联系(如上下位关系)。基于这种含有专家知识的词典网络主要有: 同义词典网和概念网。同义词典网中,顶点表示词典中的词语,边表示词义的关系[11];例如,两个词语是同义词,则用边连接它们。词典的来源主要有Roget’s同义词典和Merrian-Webster同义词典等[1, 12-14]。基于WordNet的网络[12, 15]是一种概念网,顶点是词语(单词或概念)。词语之间通过各种关系相连而形成边,比如同义关系,反义关系、上下位关系。这些网络都表现出复杂网络的普遍特征[16]。
(4) 词汇联想网络。一个用来探索基于词义关系的替代性的来源是基于词汇联想实验,词语被用来作为刺激(stimulus),让参与人员联想到意思或词形相关的单词(response)。词汇联想网(Association Graphs)[12]中,将实验中用到的所有词(stimulus 和response)作为顶点,用边表示了从stimulus到response的联想。
(5) 中文语言网络的相关工作。汉语作为世界最重要的语言之一,其统计规律和性质具有重要的参考意义。文献[6]在大规模语料库(北京大学《人民日报(1998年上半年)》1 300万字左右的人工分词语料库和国家语委5 000万字左右的人工分词语料库)上,基于不同规模和类型的语料子库,构建了汉语词语同现网络,考察汉词语同现网络的特性。实验结果表明汉词语同现网络具有小世界特性和无标度特性[6],该文还基于网络的方法获取了汉语的核心词典。文献[7]基于大规模句法标注树库[17],根据文献[18]提出的汉语依存语法规则,建立了汉词语汇的语法依存句法网络,实验结果表明汉语依存语法网络具有小世界效应和无标度特性,并在层次性、居间中心性和混合模式等方面也体现了复杂网络的普遍性质。这些特性与捷克语、德语、罗马尼亚语等极为相似,说明不同语言的网络具有类似的特性,这种共性对人类语言本质的研究具有一定的启发意义[7]。有一类工作并不止步于网络的统计特性,而是深入到网络中的节点特性与词语的语言特性之间的印证关系,甚至涉及了更名副其实的语义网络研究。如文献[19]给出了“虚词是网络中心节点的”的例证,为汉语虚词的研究提供了新方法。文献[20]考察了汉语语义角色(论元结构)网络,发现该网络虽然也同样具备小世界和无标度特征,但它与句法网络在层级结构和节点度相关性方面存在明显不同。
3 语义场网络
很多研究对以什么单位为网络结点,如何定义结点之间的关系,研究的兴趣何在,都未做出充分回答[2]。然而,尽管各种已研究的网络从构建上有区别,但都有一个共同点: 结点之间的关系都试图表达词语之间的语义关联。
3.1 联想场的概念
语义场是指义位形成的系统[21]。语义场的理论有多种: 词汇场、句法场、联想场等。联想场理论认为: 包围在已给词周围的能够更细地规定这个词的价值的体系。例如,“牛”这个词的联想场就可由下列单位构成的: (1)公牛,母牛;(2)劳动,犁;(3)强壮,耐劳;等等。Ullmann把联想场规定为围绕一个词的联想网络,一切都是被联想的网所包围,依此和其他词产生联系[22-24]。
3.2 如何表达联想
为什么给定激发词“奥运会”,大多数人会联想到“金牌”,“世界冠军”等呢?笔者认为,这种心理过程构建于人共有的背景知识,因而间接地构建于被广泛使用的媒体,包括报纸,电视,互联网等。更具体来说,是因为这些词语是文档的关键词且高频率同现。词语的同现是重要信息,常常同现的词语放在一起时能表现它们自己的含义,例如,“刘翔”、“跑步”、“冠军”三个词语放在一起的时候,尽管没有句法信息,我们仍能判断这里“刘翔”是著名运动员而非一般人,“跑步”是一种高水平的比赛,而不是普通的“奔跑”。表明这些词放在一起的时候,即使没有语法信息和精确的人工义素分析,我们也能比较准确地了解这些词语的指称意义。结合联想场的概念,从概率的角度来看,同一义场中的义位有比较大的概率在同一窗口同现。反之,同现概率大的义位也倾向于处在同一个义场。那么,可以不二元性地判断两个词语是否属于同一义场,而是基于概率论进行判断: 两个词语的同现程度越高,属于同一义场的概率越大。这是一种广义的义场,在自然语言处理中更加实用。如果能获得两个词语同现的频次(亦可转换为概率),就估计了大部分人从一个词联想到另一个词的可能性(容易程度)。
3.3 汉语语义场网络的构建方法与特征
语义场被定义为义位形成的系统[21],但如何来表示这个系统?基于上述广义语义场的概念,我们尝试用三种网络来表示汉语的子场,根据语言复杂网络研究领域中的分类,可称为关键词同现网络(Key Term Concurrence Network,KTCN)。这里仅描述在文献[25]中用于信息检索任务中的查询扩展技术时中表现最好的网络,记为KTCN-R,其生成过程如下: 以大型语料中所有文档的所有关键词为结点,如果两个关键词同时出现在至少一篇文档的同一段落中,则认为它们可能属于同一语义场,则在这对关键词之间加边。边权值表达的是相应的关键词在语料库中所有文档的所有段落中同现的次数。
KTCN-R相对其他研究中的词语同现网络的较为独特之处在于: 第一,一个词语只有是某文档的关键词,才可能导致在网络中产生新边或在相应的边上增加权值;第二,每个关键词必须在指定的窗口中与其他关键词同现,才可能被加入网络。
KTCN-R中的边和边权值共同表达的“联想”,其中权值近似了两个词语之间的联想关系的强度。在KTCN-R中的节点是词语,从计算机领域看来只是“字符串”,似乎并不接近语言学中的义位的定义,但是,由于词语节点与其周边的与它密切的词语节点处在同一系统中,常能反应出其自身的义位,我们强调它被网络中周边的节点保卫,而非孤立的元素。因此我们称这些节点本身为相应词汇的义位,这是一种近似,也是我们称KTCN为语义场网络的理由。
就目的而言,KTCN-R与联想网络相同;从构建上,KTCN-R属于一种词语同现网络;由于边权值在某种程度上表达了词语意义上的关联程度,它又很像专家知识网络,但这种意义上的关联来自于巨型语料。
4 无标度分布及相关概念
我们调查了KTCN-R的诸多统计特性,这里主要描述网络中的无标度分布现象。这里先描述一些图论和统计学中的名词,以期能和语言学界专家共同探讨。以三元组(N,E,W)来描述KTCN-R的规模,其中N,E,W分别被定义为网络结点数,网络的边数,网络中边的权值总和。结点的度定义为该节点的邻边数;对网络的所有节点,可用顶点度的直方图来表现其总体情况,这个直方图就是网络的顶点度分布。如果一个网络的顶点度分布有相当高的异度分布(heterogeneous distributions)特征: 大部分结点的度数很低,而少数结点的度数很高,则称这种分布为无标度分布。“无标度”的本质含义是“无明显特征”,而正态分布则具有绝大部分样本分布在期望附近的明显特征。结点的权值定义为其邻边上的权值之和,注意,KTCN-R中的结点权值并非相应词语在语料中的频次,如前所述,并非语料中出现的词语就一定会成为网络结点。网络的结点平均权值定义为所有结点的权值的平均值。结点平均权值分布的概念则类似于网络的顶点度分布。如果一条边上的权值足够高,说明相应的关键词对同属于同一个语义场的概率越大。反过来,如果一条边上的权值太低,则可以认为边上两个结点的共现是一种偶然现象,而非因为属于同一义场的比较必然的结果。因此,以边权值分布反映这种属于同一义场的概率的分布: 横坐标为网络中边权值,纵坐标为在网络中具备某一权值的边的数目。具有边权值的复杂网络难以获取,这也是文献中很少看到带权网络的原因。
5 实验结果
本文采用NTCIR-7中IR4QA的简体中文语料构建KTCN-R,该语料由新闻文章组成。分别来自新华社和联合早报,总共545 162篇文档。
KTCN-R的规模如表 1所示。这里顺便列出了网 络 边 上 权 值的最大值MaxEdgeWeight。从预料中抽取出的关键词总数为714 738,但是KTCN-R节点数小于714 738,原因是有一些关键词没有与其他关键词同现过。KTCN-R中的结点数量远远超过了《汉语主题词表》收录的词数,这是因为,本文使用的关键词抽词工具抽取出的“词”并不是语言学里严格意义的词,更准确地,可以说是文档的关键字符串,它有可能是语言学上严格意义的词,也可能是词的组合等,例如,“金牌获得者”。KTCN-R的平均度,平均权及它们的标准差,如表 2所示。

表1 语义场网络规模及边的最大权值

表2 结点平均度
5.1 结点度分布
KTCN-R的结点共有3 808种度,结点度最小值是1,最大值是77 214;采取累加分布容易导致迷惑,这里分段描述KTCN-R的结点度分布。第一、二、三段分别是度数在(0,200],(201,500],(500,1 118)的分布,分别如图 1、图2、图 3所示;第四段,即度数大于等于1 118的结点数均小于10。综合以上四段数据,KTCN的度分布是无标度分布。

图2 KTCN-R中201到500度的结点数分布

图3 KTCN-R中500到1 118度的结点数分布
下面观察结点度数在一定范围内的词语特征。本节数据均展示在文献[25]的附录中: 1)文献[25]中附录1列出了KTCN-R中200个度数最低的语词(度数均为1)。这些语词主要包含以下情形: 比较少见的词、不准确的抽词、有意义的并且意义比较具体的语词组合(例如,“生意比去年”是由常见的“生意”、“比”、“去年”组成的);对于语词组合的情形,虽然从语言学的角度基本不像词,在我们基于KTCN-R的查询扩展工作中起到不可忽略的连接作用。2)文献[25]中附录2列出了KTCN-R中度数最高的200个语词和它们的度数,这些语词非常符合语言学角度的“词”,抽“词”结果相当准确,而且这些语词基本不是停用词。此外,这些语词中,除了“新加坡”、“马来西亚”、“委员会”,其余词全部由两个字组成。对于此现象,笔者尚不能解释。3)文献[25]中附录3 列出了KTCN-R中度数为所有度数的中数左右的200个语词,它们的度数均为13,这部分语词虽然不像语言学中严格意义上的词,但是意义却相当完整,仅从这个语言学的“词”之外的角度,抽词错误相当少,而且相对附录2,两个字的情形很少。4)此外,最高度数的一半左右的200个语词的数据与附录2基本相同,因为在KTCN-R中,最大度数为77 214,其一半是38 607,度数大于38 607的语词仅九个。
5.2 结点权值分布
KTCN-R的结点共有7 249种不同的权,最小值是1,最大值是858 411,权值大于等于32 224的权值共629种,对应结点个数均为1。图4、图5、图6分别展示了权值在[1,315],[316,804],[805,1 957]三个区间的结点分布。剩余的数据点共5 305个,权值均小于10,平均值为1.412 63,标准差为0.845 73,中数为1,为1的数据共3 940个。综上,KTCN-R的结点权服从无标度分布。
下面观察结点权值在一定范围内的词语特征: 1) 文献[25]中附录4列出了KTCN-R中权值最低的200个结点的词语,它们的权值均为1,由于权值为1的结点度数必然为1(反之未必成立),而权值为1的结点和度数为1的结点都非常多,因此两种情况应该相似。造成附录1和附录4的差别的原因是实验过程中使用了二叉排序树,两种情况结点被插入二叉树的先后顺序不同。所以它们表现出和度数最低的200个词相同的特征: 很少见的词、不准确的抽词、和少量意义完整的词语组合。2) 文献[25]中附录5列出了KTCN-R中结点权值大于1且最小的200个词语(结点权值均为2)。显然,它们与度或权为1的结点具有相同的特征。3) 文献[25]中附录6列出了KTCN-R中结点权值最高的200个结点的内容及它们的权值。度数最高的200个结点(附录2)和权值最高的200个结点之间的重复率为100%,即这两组数据仅排序不同,因此它们的特征也相同。但KTCN-R中结点度与权的皮尔逊相关系数仅为0.565 346。4)文献[25]中附录7列出了结点权值在所有权值的中数左右的200个词语,它们的权值均为22,这些词语虽然不像词,但是意思却相当完整。5) 此外,最高权值的一半左右的200个词语基本就是权值最大的那些词语。因为KTCN-R中最大权值为858 411,其一半是429 205.5,权值大于的429 205.5词只有五个(结点个数均为1)。

图4 KTCN-R中权值在[1,315]的结点数分布
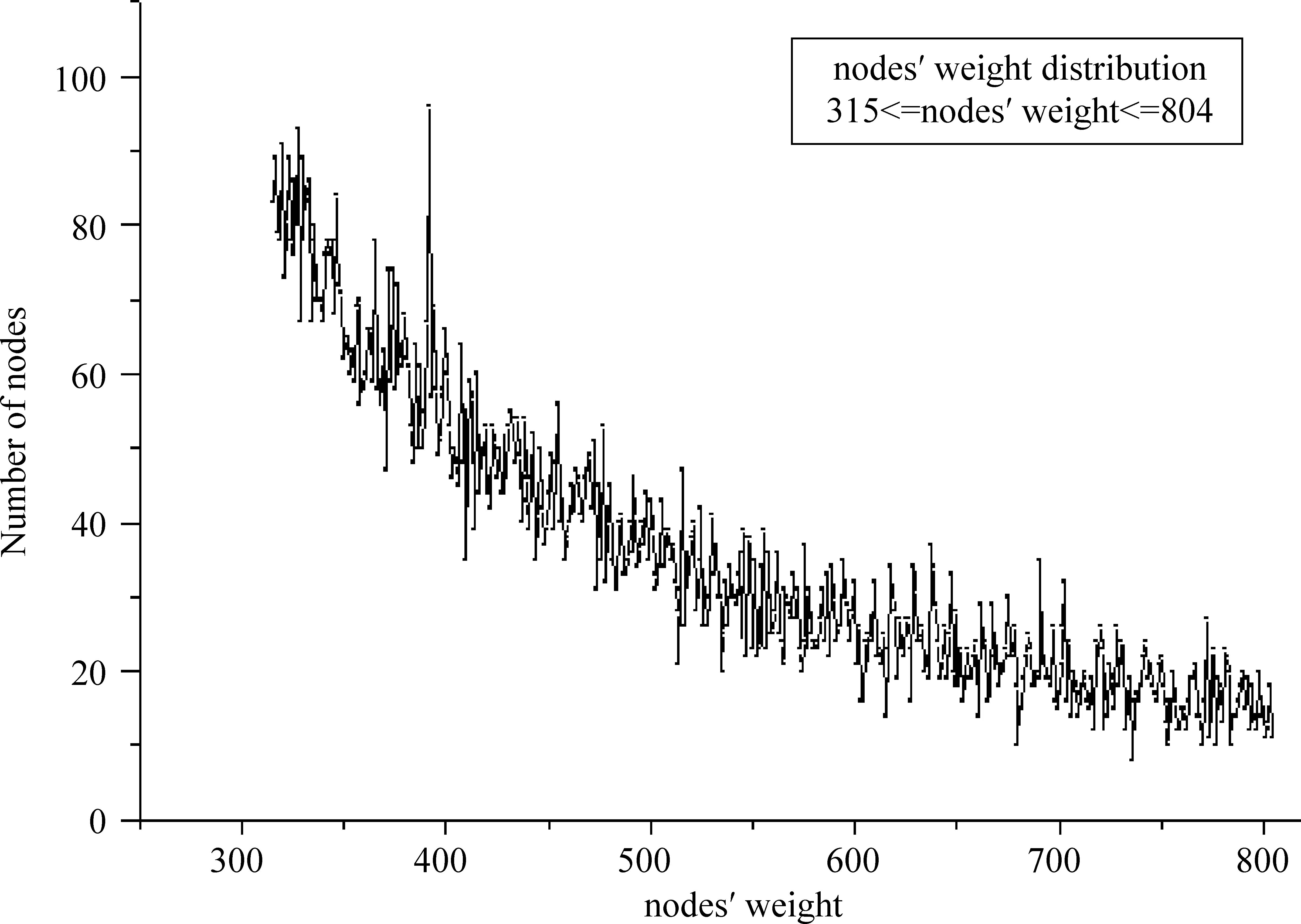
图5 KTCN-R中权值在[315,804]的结点数分布
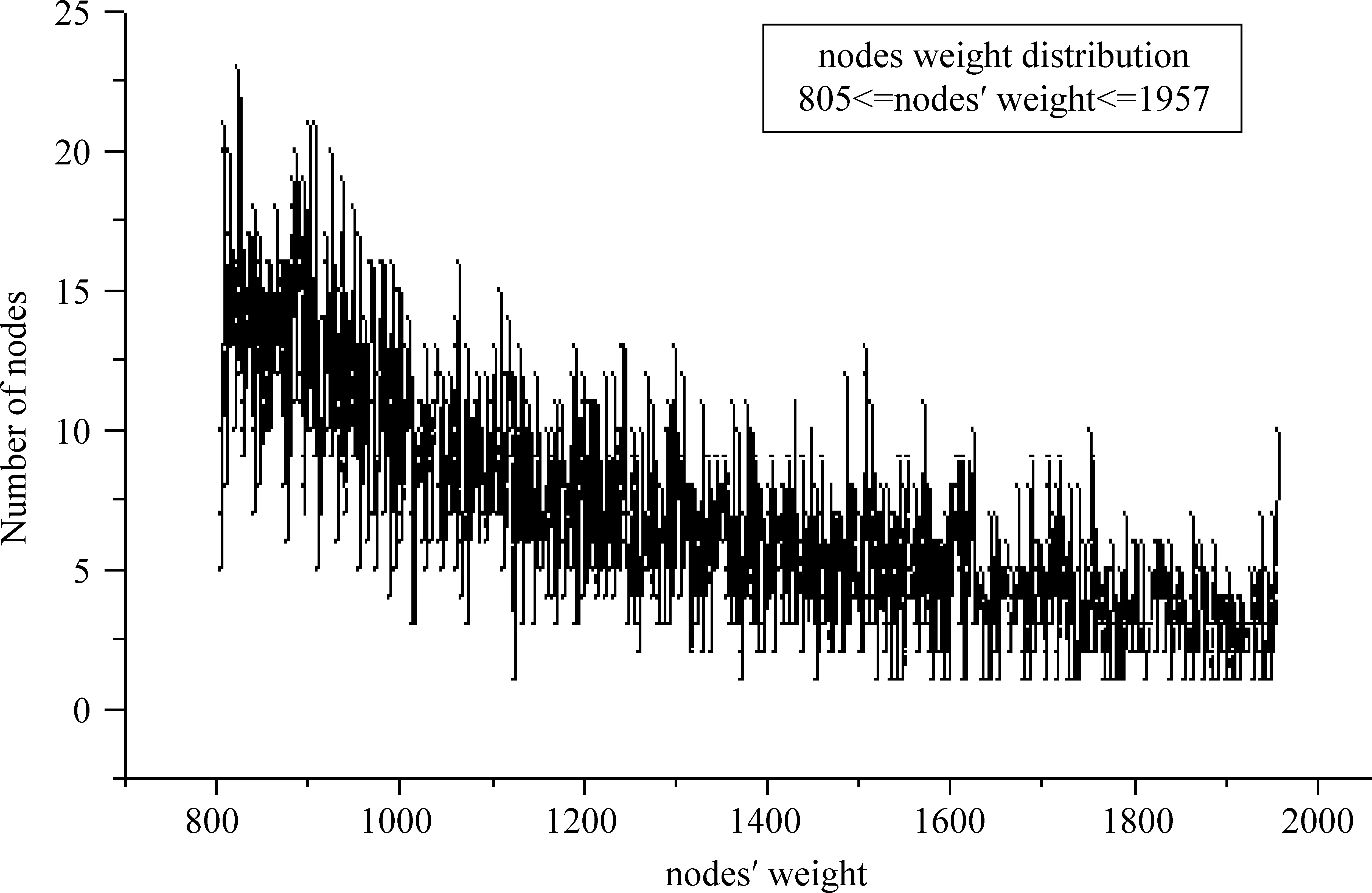
图6 KTCN-R中权值在[805,1 957]的结点分布
5.3 边权值分布
边权为1,2,3,4,5的边数分别是8 275 598,5 106 606,2 454 626,914 240,500 610。图7、图8、图9、图10分别描述了边权值在[6,29],[30,246],[247,573],[574,820]的边数分布。剩余的数据,即权值为821到10 337的边共有1 063种权值,对每个权值,对应的边数均小于10。最小值为1,最大值为8,均值为1.761 99,标准差为1.199 81,中数为1,1 063种权值中有642种权值的边数为1。综上,KTCN-R的边权值服从无标度分布。
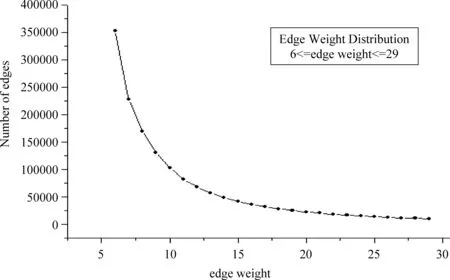
图7 边权值在[6,29]的边数分布

图8 KTCN-R中边权值在[30,246]的边数分布

图9 KTCN-R中边权值在[247,573]的边数分布

图10 KTCN-R中边权值在[574,820]的边数分布
下面考察一些权值在具体范围的边的内容特征: 1)文献[25]中附录8列出了200条权值最小的边的内容,它们的权值均为1。特点是: 结点基本都是意义很完整的词及组合,而不是那些很少见的词语或者错误抽词(这是度和权最小的200个结点的特征)。然而,从常识来看这些边的结点语义关系非常弱,属于同一义场的概率很小;2)文献[25]中附录9列出了KTCN-R中权值最大的200条边的内容。它们的特点是,结点与附录8中列出的低权值边的结点相似,抽词很准确且很常见。但边的特性却与附录8相反: 语义关系非常明显,即属于同一义场的概率较大;3)文献[25]中附录10列出了KTCN-R中边权值在所有边权值的中位数左右200条边的内容,它们的权值都是2,说明中数是2,接近众数1。因此附录10的与附录8的特征接近。4)我们还考察了权值在10(边数20 312)、50(边数3 149)、100(边数729),200(边数205)、500(边数43)的边的内容,对边数少于200的权值,列出全部边的内容,对边数超过200的权值,只列出200个。相应实验结果见文献[25]中附录11到附录15,其中删除了一些言论敏感的结果。从这些数据可以观察出以下结论: 随着权值的增加,边上的两个结点之间的语义相关程度越来越高。并且,在权值为10的情况,这种倾向就已经非常明显了。此外,权值越高,边上的两个结点越显得紧密,但意思也比较宽泛,例如,“企业-500-美国”,但是在比较有意义的范围,形成对比的是: 权值为10的一组,就显得更加领域化,例如,“外商投资企业批准证书-10-申请”,而且相应的结点字符串也比较长。但,无论边权值为10还是500的边的两个结点的语义关系都比较明确。
6 未来的工作
基于本文的工作,有如下工作可以扩展: 1) 更精确地构建网络,如改进关键词的提取算法,使得文章的关键词更加准确,使得节点更加准确,尽可能少地出现不符合人类直觉的“词语”。以互信息为边权值等,增加边及权值的准确性。对这一工作的检验方法是利用该网络作为基础之一实现某些NLP任务,考查性能的提升。例如,可用查询扩展任务的性能提升程度检验互信息和频率哪一个更能表达词语的亲密程度。2) 用于语料建设。跨文本的结构特性可以提供关于“无人工干涉的语料”的知识。类似地,如果语料的网络结构远远偏离了文本网络的原则,则可能有人工干扰。从语料库语言学的角度,对语料的网络分析可以研究语料特性,量化对语料的合理性限制,比如语料应具备自然性限制(naturalness constraints,即无刻意的人工干预),文献[2]及相关研究指出了从复杂网络的角度对语料进行分析的重要性,例如,在语料作为认知学上词汇记忆模型的数据时,小世界特性至少可以作为判断语料需要满足可靠性的必要条件。由于基于网络的语料库语言学研究刚刚起步,目前最主要的任务是探索大型文本网络的结构,寻找出相关的规律,找出合适的结构参数指标,评价语料的质量,有益于语料的建设和处理[2]。 3) 类同文献[6]的工作,寻找中文的核心词汇;可以KTCN-R为基础,帮助中文词汇表(比如汉语主题词表)的建设与更新,在构建词表时,度数或者节点权值越大的节点,越早受到语言学家的审验。4) 寻找语言的深层次特征。5) 语义场网络的权值表达了词语之间容易联想到的强度,因而可用于认知及联想研究,类似文献[12]中构建网络时,减少参与网络的构建的人力工作。6) 用于自然语言处理的任务,通过各种方法修订该网络,并找到应用。如文献[25]中对KTCN-R的权值进行反转,用最短路径表达词语的语义亲密程度,并用于信息检索任务;又如,基于KTCN构建词汇链,可能改善基于词汇链技术的任务的性能。
[1] Ferrer I Cancho R. The structure of syntactic dependency networks: Insights from recent advances in network theory[J]. The Problems of Quantitative Linguistics,2005: 60-75.
[2] Mehler A. Large text networks as an object of corpus linguistic studies[J]. Corpus Linguistics.An International Handbook of the Science of Language and Society,2007: 328-382.
[3] Solé R V, Corominas Murtra B, Valverde S, et al. Language networks: Their structure, function, and evolution[J]. Complexity, 2010, 15(6): 20-26.
[4] 韦洛霞, 李勇, 李伟,等. 汉字网络的3度分隔与小世界效应[J]. 科学通报,2004, 49(024): 2615-2616.
[5] 韦洛霞, 李勇, 康世勇,等.汉语词组网的组织结构与无标度特性[J]. 科学通报,2005, 50(015): 1575-1579.
[6] 刘知远, 孙茂松. 汉语词同现网络的小世界效应和无标度特性[J]. 中文信息学报,2007, 21(006): 52-58.
[7] 刘知远, 郑亚斌, 孙茂松. 汉语依存句法网络的复杂网络性质[J]. 复杂系统与复杂性科学, 2008, 5(2): 37-45.
[8] Ferrer I Cancho R, Sole R V. The small world of human language[J]. Proceedings of the Royal Society B: Biological Sciences. 2001, 268(1482): 2261-2265.
[9] Dorogovtsev S N, Mendes J F. Language as an Evolving Word Web[J]. Proceedings: Biological Sciences. 2001, 268(1485): 2603-2606.
[10] Ferrer I Cancho R, Solé R V, Köhler R. Patterns in syntactic dependency networks[J]. Physical Review E, 2004, 69(5): 051915.
[11] Kinouchi O, Martinez A S, Lima G F, et al. Deterministic walks in random networks: An application to thesaurus graphs[J]. Physica A: Statistical Mechanics and its Applications. 2002, 315(3-4): 665-676.
[12] Steyvers M, Tenenbaum J B. The Large-Scale Structure of Semantic Networks: Statistical Analyses and a Model of Semantic Growth[J]. Cognitive Science. 2001, 29(1): 41-78.
[13] Albert R, Barabasi A L, Jeong H, et al. Statistical Mechanics of Complex Networks[J]. Nature Genetics. 2002, 31: 60-63.
[14] Newman M E. The structure and function of complex networks[J]. SIAM Review, Arxiv preprint cond-mat/0303516. 2003, 45: 167-256.
[15] Sigman M, Cecchi G A. Global organization of the Wordnet lexicon[J]. Proceedings of the National Academy of Sciences. 2002, 99(3): 1742-1747.
[16] Motter A E, de Moura A P S, Lai Y C, et al. Topology of the conceptual network of language[J]. Physical Review E, 2002, 65(6): 065102.
[17] 周强. 汉语句法树库标注体系[J]. 中文信息学报. 2004, 18(004): 1-8.
[18] 周明, 黄昌宁. 面向语料库标注的汉语依存体系的探讨[J]. 中文信息学报. 1994, 8(003): 35-52.
[19] 陈芯莹, 刘海涛. 汉语句法网络的中心节点研究[J]. 科学通报. 2011, 56(10): 735-740.
[20] 刘海涛. 汉语语义网络的统计特性[J]. 科学通报. 2009(014): 2060-2064.
[21] 贾彦德. 汉语语义学[M]. 北京: 北京大学出版社, 1999. 147-208.
[22] 林纪诚. 英语语篇中词汇衔接手段试探[J]. 外国语 (上海外国语学院学报), 1986, 5: 20-26.
[23] 夏日光. 语义联想场与名形词类转变的英译[J]. 西安外国语学院学报. 2004, 12(4): 84-86.
[24] 王悦. 俄语语义场划分的原则与类型[J]. 经济研究导刊. 2012,14: 227-228.
[25] 杨华. 复杂网络在自然语言处理中的应用初探[M]. 南京: 南京大学出版社, 2012: 126-137.
Scale -Free Distribution Phenomenon in Chinese Semantic Field Network
YANG Hua1,2, JI Donghong3, XIAO Guozheng2
(1. School of Mathematics and Computer Scinece, Guizhou Normal University, Guiyang, Guizhou 550001,China; 2. College of Chinese Language and Literature, Wuhan University, Wuhan, Hubei 430070, China; 3. School of Computer, Wuhan University, Wuhan, Hubei 430070, China)
Semantic field is the semantic system composed of glosseme and the linkage among themselves. For a given language, all sub-semantic-field forms the whole semantic filed for that language. According to the conception of association semantic filed, we employ the complex network to represent Chinese semantic field. The scale-free distributions of node degree, node weight, and edge weight, are observed in this network. Some net-work unique language phenomena can be discovered by terms whose node degree, node weight, edge weight are in specific ranges. We demonstrate some specific phenomena detected, expecting further studies would provide reasonable explanations.
semantic field, complex network, scale-free distribution

杨华(1974—),博士后,教授,主要研究领域为自然语言处理。E⁃mail:yanghuastory@foxmail.com姬东鸿(1967—),博士,教授,博士生导师,主要研究领域为自然语言处理。E⁃mail:dhji@whu.edu.cn萧国政(1949—),博士、教授、博士生导师,主要研究领域为汉语言文字学、理论语言学及自然语言处理。E⁃mail:gzxiao@whu.edu.cu
1003-0077(2015)03-0034-10
2013-04-08 定稿日期: 2013-07-31
国家自然科学基金(61070243)、国家社科基金(11&ZD189)、贵州省高层次人才科研项目(TZJF-2010年048号)、贵州省科教青年英才培养工程项目(“黔省专合字(2012)155号”)、贵州师范大学博士科研启动基金项目(11904-05032110011)
TP391
A
