Hadoop 平台下计算能力调度算法的改进与实现
2015-04-16戴小平张宜力
戴小平,张宜力
DAI Xiaoping,ZHANG Yili
安徽工业大学 计算机学院,安徽 马鞍山243002
Computer Science School,Anhui University of Technology,Ma’anshan,Anhui 243002,China E-mail:jszhangyili@163.com
1 引言
云计算是一种新的计算模型,是随着并行计算、分布式计算和网格计算技术的发展而来的,在学术界和工业界产生了巨大的影响,Google、Amazon、Microsoft 等大公司是云计算的先行者[1]在众多的云计算解决方案中,Google提出的基于分布式文件系统GFS 建立的廉价集群实现MapReduce 编程思想[2-3]的方案因其应用简单、高效的特点得到了广泛支持,解决了许多大规模数据的计算问题。而Hadoop 作为Google 相关思想开源实现的一个分布式系统,除了成本少,有较高的效率和伸缩性外,安全性也得到了很好的保障[4-5]。
Hadoop 平台中作业调度器对平台性能至关重要,作业调度技术作为Hadoop 平台的核心技术之一,不仅对Hadoop 平台的整体性能有影响,还对系统资源是否有效利用起到了至关重要的作用。但是目前的几种作业调度算法都存着资源浪费,作业响应时间过长,没有考虑作业配置及不能够满足作业多样性的服务要求等缺点[6]。
本文基于计算能力调度算法实现了一种基于优先级的计算能力加权调度算法,能够有效地解决目前Hadoop的作业调度算法中存在的一些问题,并在Hadoop平台的实验中表现良好。
2 MapReduce编程思想
MapReduce是Google公司的核心计算模型,它将复杂的运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map(映射)和Reduce(归约)。简单的MapReduce 的过程如图1 所示,MapReduce 首先将用 户输入的数据通过Split 方法将其分成若干Block(每个Block的默认大小为64 MB,每一个Block由一个Mapper管理,在整个MapReduce 中Reducer 是通过配置来得到的,而Mapper 的数量则是由Block 的数量来决定)每一个Mapper 将运行在该Block 所在的本机中,所有的临时数据和中间数据也都会存储在本机中,当所有的Mapper运行完成后,Reducer 便会开始运行,将所有Mapper 的输出作为它的输入,最后将结果输出到GFS 中[7]。
图1 给出了MapReduce 执行过程,分为Map 阶段以及Reduce 阶段,这两个阶段都使用了集群中的所有节点。在这两个阶段之间还有一个中间的分类阶段,即将中间结果包含相同Key 交给同一个Reduce 函数去执行。MapReduce操作相关的类型如下:
map(keyin,valuein)→list(keyout,valueintermediate)
reduce(keyout,list(valueintermediate))→list(valueout)

图1 Google MapReduce执行过程
3 Hadoop 的作业调度算法
Hadoop的调度器旨在调度各种提交到Hadoop的作业,使作业有个合理的执行顺序。它不仅要对作业进行调度,提高系统的吞吐量,使系统处理尽可能多的作业,提高执行效率,而且还要考虑系统的利用率,不使系统空闲下来,另外还得兼顾用户的感受提高作业响应时间。
早期Hadoop 的作业调度算法按照作业提交顺序来运行,使用的就是FIFO 调度算法。后来FaceBook 和Yahoo分别提设计了公平调度算法,计算能力调度算法。
公平调度算法目的是能够满足多用户多类型作业的并行运行[8]。该算法的设计思想是让所有的作业随着时间的推移,都能平均获取等同的共享资源。算法以池的形式管理作业,默认情况下每个用户都有一个独立的作业池,用户能获得相等份额的资源而不管用户提交了多少作业。在公平调度算法的具体实现中,为了选择合适的作业执行,公平调度算法还定义了作业赤字作为选择依据,即一个作业在理想情况下应该获得的计算资源量与它实际获得的计算资源了之间的差距。公平调度算法会周期性地观察各个作业中有多少任务已经在上一时间段内执行,并将该结果与它应得的资源份额作对比更新该作业的赤字值。一旦有空闲的TaskTracker 出现,它会被首先分配给当前具有最高赤字的作业使用。
计算能力调度算法[9]中可以定义多个队列,当用户提交了一个作业,该作业会被放到一个队列中。各个队列根据配置文件分配到相应数量的TaskTracker 资源用于处理Map 操作和Reduce 操作。当系统中出现了空闲的TaskTracker,算法会首先选择一个具有最多空闲空间的队列。当一个队列被选中时,调度器就会根据该队列中作业的优先级和提交时间进行选择合适的作业。计算能力调度算法虽然吸取了公平算法的不足,根据作业的性能分配资源,但这种分配策略过于简单,容易陷入局部最优,同时该算法配置起来也是比较繁琐的,而且对服务水平协议也不能很好的支持。
在Hadoop 中作业调度器是一个可以插拔的模块,因此针对Hadoop 现存调度器存在的问题,以及根据自己的实际应用要求修改或者重新设计调度器。国内外有很多专家学者对Hadoop 的作业调度算法进行了深入的研究。Torabzadeh 等提出了在两阶段装配式流水作业调度中基于云理论的模拟退火算法,其中给出相关函数,加入相应指标,并证明了该算法使总运行时间和平均运行时间减少[10]。Hadoop 的公平调度算法中存在着调度公平性与数据本地化的冲突。Zaharia 和Borthakur等人在公平调度算法的基础上提出了Delay Scheduler策略,延迟调度的设计目标是尽可能小地减少公平性,并提高作业的数据本地化,最终提高系统的吞吐量[11-12]。延迟调度的思想主要是针对小作业提出的,能很大程度提高小作业的吞吐量,从而提高整个系统的吞吐量。彭舰等提出了一种能够找到总完成时间和平均完成时间最短的算法[13]。邓自立针对Hadoop 的FIFO 调度算法的不足给出了一个基于优先级的加权轮转调度算法(PBWRR),这种算法避免了作业的长期等待,又考虑到了作业的优先级[14]。
4 基于优先级的计算能力加权调度算法
4.1 算法的思想与设计
在原算法中当某个Tasktracker 上出现空闲slot 时,调度器依次选择一个queue、(选中queue 中的)job、(选中job 中的)task,并将该slot 分配给该task[15]。下面介绍选择queue、job 和task 所采用的策略。
(1)选择queue:将所有queue 按照资源使用率由小到大排序,依次进行处理,直到找到一个合适的job。
(2)选择job:在当前queue 中,所有作业按照作业提交时间和作业优先级进行排序,调度依次考虑每个作业,选择符合两个条件的job:①作业所在的用户未达到资源使用上限;②该TaskTracker 所在的节点剩余的内存足够该job 的task 使用。
(3)选择task,考虑task 的locality 和资源使用情况。
计算能力调度算法应用于较多小作业时性能较差,容易陷入局部最优,本文的算法主要是在计算能力调度的基础上优化步骤(2)中的作业选择策略,优化后的策略更加公平,避免选择策略陷入局部最优,从而提高了整个系统的效率和用户满意度。
在原算法中作业队列是按照作业提交时间和作业优先级进行排序,然后选择队列头部的作业。在本算法中首先根据作业权重对每个队列的作业进行排序,然后将这个空闲的slot 分配给选中队列的第一个作业的task(该作业必须满足步骤(2)中的两个条件)。可以看出,作业的权重是选择的重要参考依据。
考虑到TaskTracker主动请求task的模式以及Hadoop任务调度体系非抢占模式的特点,为了使调度的任务避免长期的等待,同时各个任务调度权重又能根据实际情况进行调整,可以通过下面一系列推导得到权重的公式。
假设用V表示一个轮转周期内处理数据的总量,一般情况下Map任务的数量远远超过Reduce任务的数量。因此,用系统能够同时运行的Map 任务数量的能力来表示系统的所能处理任务数量的能力,记为taskcapacity。而且每个Map 任务所处理的数据量为输入数据的分块,大小即为HDFS中数据块的大小,记为blockSize(一般设为64 MB),所以每一个轮转周期系统所处理的数据量为:

用avgtasksize表示某job划分的任务平均大小,jobsize表示某job的大小,tasknumber表示job的任务数,则有:

如果job[i]的权重为weight[i] 为了保证优先级的作用和有效性,某个job 的优先级与所有job 优先级之和的比值应该基本等于这个job 执行的数据量与队列一个轮转周期的数据量的比值,即有:
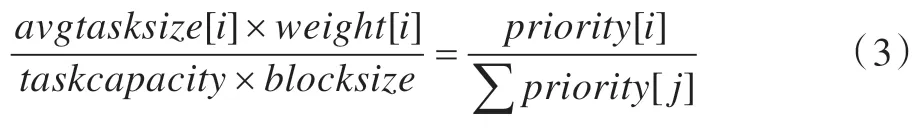
于是就可以得到:

根据实际情况对权重进行动态的调整避免算法陷入局部最优,这里的实际情况就是队列中作业的等待时间以及作业完成度(未完成task/全部的task)。因此计算作业权重要将作业的等待时间以及作业的完成度考虑进去,由此可得:

其中,ctime表示当前时间,stime表示作业提交时间,utask表示未完成任务数,atask代表任务的总数。
权重是同一队列中作业排列的依据,在公式(5)中taskcapacity、blockSize和avgtasksize对同一队列的作业来说都是定值所以可以简化权重公式为:


4.2 算法的实现
(1)数据结构设计
jobQueue 的调度队列中每个元素jobInfo 的数据结构为:
class JobSchedulingInfo {
JobId jobId;
JobPriority priority;
long startTime;
int taskNum=0;
int finshedTaskNum=0;
double weight=0;
}
本文算法在JobSchedulingInfo 中增加了几个参数,解析如下:
taskNum:作业的任务数量;
finshedTaskNum:作业已完成的任务数;
weight:作业的权重。
(2)权重的计算方法
权重的计算要基于作业的优先级、作业的提交时间以及作业的完成量,其中优先级对应的值如表1 所示。

表1 优先级对应的具体值
算法的伪代码如下:

(3)算法的其他内容描述
本算法中要将JobQueue 中作业根据作业的权重进行排序,实现的关键部分就是增加一个新的比较器,通过比较器来对队列排序。比较器伪代码描述如下:

5 实验结果及分析
实验采用三台虚拟机,操作系统为Linux Ubuntu 10.04.2,Java Version为1.6.0_10-rc2,Hadoop版本为0.20.2。将其中一台作为主机Master,其余的两台分别作为Slave。使用最常用的WordCount(从文本数据统计单词次数)作业来测试调度的改进。算法部分参数配置如表2 所示。

表2 算法参数配置
实验1将八个作业传到集群上运行,作业的详细信息如表3。
FIFO 调度器中得到的运行时间如图2 所示。
将Hadoop0.20.2 计算能力调度器插入到集群中。同样将上面的八个作业传到集群上运行得到的运行时间如图3 所示。
将本文的调度算法插入到集群中,得到的运行时间如图4 所示。
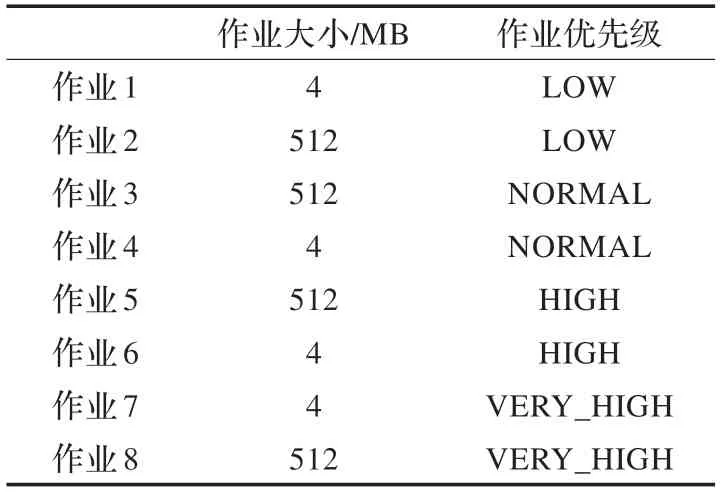
表3 作业详细信息

图2 FIFO 调度器运行结果图

图3 计算能力调度器运行结果图

图4 本文算法运行结果图
对比实验结果可以看出三个调度算法的执行顺序均不相同,时长不一。FIFO 算法是按照作业的优先级和进入队列先后时间顺序执行的,没有考虑作业的长短以及不同作业的需求,执行总时间最长,计算能力调度算法和本文算法执行顺序不同是因为算法的选择作业策略不同。对比图3 和图4,可以看出图4 中的部分小作业执行时间提前,执行顺序并没有严格按照作业的优先级进行执行;还可以看出虽然部分作业的执行时间延长了但是等待作业执行时间提前了。这是因为在作业执行的尾段,作业的完成度较高而等待作业的完成度较低,调度器动态调整了作业的权重,等待作业的权重这时候有可能大于运行的作业,这样就减少了等待作业的响应时间。同时可以看出,优化后的作业选择策略使得总时间比计算能力调度算法减少了两分多钟。
实验2测试更一般的情况,提交八个作业到集群上运行。作业的优先级和大小是不尽同的,集群分别使用FIFO、本文算法和计算能力调度算法,完成时间对比如图5 所示。
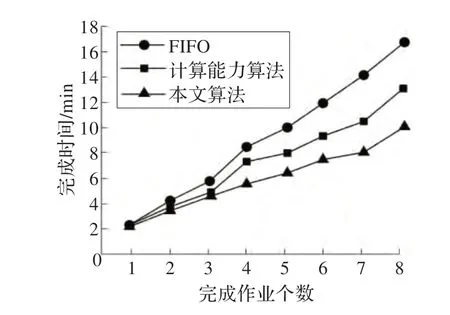
图5 作业在不同调度算法下的完成时间对比
从图5可以看出虽然本文算法在完成前几个作业和原算法的用时上并没有太大的优势,但是随着作业数的增加本文算法逐渐显现出优势。因此可以预测,在大的多用户多任务的集群上本文算法的效率肯定将超过原算法。
实验3将三个不尽相同的作业组上传到集群上,并用本文算法和计算能力调度算法进行测试。每组八个作业,作业的优先级随机分配,J-a 是小作业占多数的作业组,J-b 是大作业和小作业的数量相当的作业组,J-c 是大作业占多数的作业组,得到结果如图6 所示。

图6 三组作业在两种调度算法下的时间比较
从图6可以看出来不同类型的作业组在本文算法下运行的时间均比计算能力调度算法要少。在作业组中有较多小作业的时候本文算法可以减少总运行时间,当作业组中大作业占据绝大多数时,本文算法就退化为与计算能力调度算法类似。结合实验对比图可以得出本文算法减少了部分作业等待时间,优化了作业选择策略,使得作业组的总运行时间减少,提高了用户的满意度。
6 结束语
作业调度器关系到Hadoop 平台整体的性能和系统的资源使用效率,以及云计算服务的能力。本文提出了一种基于优先级的计算能力加权调度算法,当系统出现空闲的slot 时,作业的选择策略不仅仅考虑作业的优先级而是同时将作业的等待时间和作业完成度动态的考虑进去。这种策略避免了作业调度器陷入局部最优,同时能够减少某些相对较高优先级小作业的等待时间,在一定程度上优化了作业选择策略,减少了总运行时间,提高了系统的使用效率。
[1] 刘鹏.云计算[M].2 版.北京:电子工业出版社,2011.
[2] Dean J,Ghemawat S.MapReduce:Simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[3] Ralf L.Google’s MapReduce programming model-revisited[J].Science of Computer Programming,2008,70(1):1-30.
[4] Wbite T.Hadoop 权威指南[M].曾大聃,周傲英,译.北京:清华大学出版社,2010.
[5] Apache Hadoop[EB/OL].[2013-09-01].http://hadoop.apache.org/.
[6] 赵春燕.云环境下作业调度算法研究与实现[D].北京:北京交通大学,2009:20-58.
[7] 罗军舟,金嘉晖,送爱波,等.云计算体系架构与关键技术[J].通信学报,2011,32(7):3-21.
[8] Fair Scheduler[EB/OL].[2013-09-01].http://hadoop.apache.org/common/docs/r0.20.2/fair_scheduler.html.
[9] CapacityScheduler[EB/OL].[2013-09-01].http://hadoop.Apache.org/common/docs/r0.20.2/capacity_scheduler.html.
[10] Torabzadeh E,Zandieh M.Cloud theory-based simulated annealing approach for scheduling in the two-stage assembly flowshop[J].Advances in Engineering Software,2010,41(10):1243-1298.
[11] Zaharia M,Borthakur D,Sen Sarma J,et al.Delay scheduling:A simple technique for achieving locality and fairness in cluster scheduling[C]//Proceedings of EuroSys’10.New York,NY,USA:ACM,2010:265-278.
[12] Matei Z,Dhruba B,Joydeep S,et al.Delay scheduling:A simple technique for achieving locality and fairness in cluster scheduling[C]//Proc of the 5th European Conference on Computer Systems,2010:265-278.
[13] 李建锋,彭舰.云计算环境下基于改进遗传算法的任务调度算法[J].计算机应用,2011,31(1):184-186.
[14] 邓自立.云计算中的网络拓扑设计和Hadoop平台研究[D].合肥:中国科学技术大学,2009.
[15] 陈艳金.MapReduce 模型在Hadoop 平台下实现作业调度算法的研究和改进[D].广州:华南理工大学,2011.
