小兴安岭伊春地区林火发生自然影响因子及其影响力1)
2015-04-03梁慧玲郭福涛王文辉苏漳文赵嘉阳林玉蕊
梁慧玲 郭福涛 王文辉 苏漳文 赵嘉阳 林玉蕊
(福建农林大学,福州,350002)
森林火灾是森林更新和演替的主要影响因子之一[1],不仅会对森林生态系统造成重要的干扰和影响,也会对人类的生命财产安全造成威胁[2-3]。我国森林资源丰富,但也是林火高发区,每年林火发生超过10 000 次,过火面积达820 000 hm2[4],防控森林火灾是科研人员和林业管理部门的一项重要工作。森林火灾受火源、气候、地形、植被特征等多种因素共同影响[5],了解和掌握林火发生的主要影响因素,是判断林火分布格局,预测林火发生趋势以及科学管理林火的前提。位于小兴安岭地区的伊春市是我国北方森林旅游名城,该地区森林资源丰富,区内有多个国家级森林旅游景点,近年来随着森林旅游业的迅速发展该地区面临着严重的森林火灾防控问题。目前,国内关于该地区林火发生影响因素的研究已经开展,并取得了一定进展,研究多集中在气象因子与林火的关系分析。高永刚运用气候统计分析方法,分析了气候变化对伊春林区森林火灾的影响[6];郑琼对伊春地区1980—2010 年森林火灾的影响因子进行了分析,结果表明空气湿度、温度和风速是影响林火发生的主要影响因子[7];王继常指出平均相对湿度和年降水量对伊春地区林火发生的影响较大[8]。目前的研究方法主要为单因素方差分析法[7-9]、时间变化趋势图分析法[6]和一般线性回归模型[8],这些方法具有一定的合理性,但在深入分析单个因子对林火发生的影响力上存在不足。
随机森林(RF)是由Breiman 和Cutler 于2001年提出的一种组合分类器,具有不需要预先设定函数表达式、能够克服自变量之间的交互作用、分类精度高等优点。同时该方法还可以计算自变量的相对重要性和对单个因子的影响力进行分析[10-13]。由于该方法具有在分类判别及变量重要性分析上的优越性,近几年国外已有少数学者将其应用于森林火灾与影响因子关系的研究[14-16]。目前,国内对伊春地区林火影响因子的研究虽已开展,但关于影响因子的影响力分析还鲜有报道。因此,本研究应用此方法,对小兴安岭伊春地区的林火发生影响因子进行分析,试图找到对伊春地区林火发生有显著影响的因子,并进一步分析这些因子对林火发生的实际影响力,最后基于显著因子的分析结果对伊春地区进行火险区划分。本研究结论将为伊春地区的林火管理提供依据,并为该地区的森林旅游景区的发展与规划提供参考。
1 研究区域概况
伊春位于黑龙江省东北部地区(127°37′-130°46′E,46°28′-49°26′N),面积39 017 km2(图1),属低山丘陵地形,平均海拔高度600 m,其地面海拔高程在125~330 m,地势开阔,坡度平缓。该区属于北温带大陆性季风气候,年平均气温1 ℃,气温偏低;年降水量750 ~820 mm,降水量较充沛。区内森林茂密,树种较多,森林覆盖率为83.8%。森林类型是以红松(Pinus koraiensis)为主的针阔混交林,主要树种为红松、兴安落叶松(Larix gmelinii)、樟子松(Pinus sylvestris var. mongolica)、山杨(Populus davidiana)、蒙古栎(Quercus mongolica)等[17]。伊春地处小兴安岭地区,是我国北方森林旅游胜地。截至2012 年底,国家级自然保护区共5 个,2013 年末,国家AA 级以上景区共有27 处,全年共接待游客583.8万人次,比2012 年增长7.5%。
2 材料和方法
2.1 数据来源与处理
本研究所涉及的数据包括林火发生数据、高程、植被类型、基础设施和气象因子等5 部分,共14 个变量。
1980—2009 年伊春地区林火发生数据来源于伊春森林防火办公室,数据包括起火地理坐标,火灾大小、起火原因和火灾发生时间等信息,共有379 个火点。在建立森林火灾的判别模型时,需要构建一定比例的随机点(非火点),因此,本研究应用Arc-GIS 软件按约1 ∶2 的比例随机创建758 个非火点[18],创建过程遵循时间和空间上的完全随机;且用0 表示没有林火发生,用1 表示林火发生。
高程数据来源于国家测绘地理信息局(http:218.244.250.78/NgccDigitalHall/)提供的1 ∶250 000数字地形图。
植被类型数据来源于中国科学院寒区旱区环境与工程研究所(http:www.careeri.cas.cn/)提供的分辨率为1 km 的中国数字植被图。植被类型用各植被类型的面积占研究区域面积的比重来表示。
基础地理信息数据来源于国家测绘地理信息局(http:218.244.250.78/NgccDigitalHall/)提供的精度为1 ∶25 万的矢量地图。基础设施变量包括:火点或非火点到铁路、公路和居民点的最短距离共3个变量。图1 显示了伊春地区火点,高程及人为基础设施的空间分布。
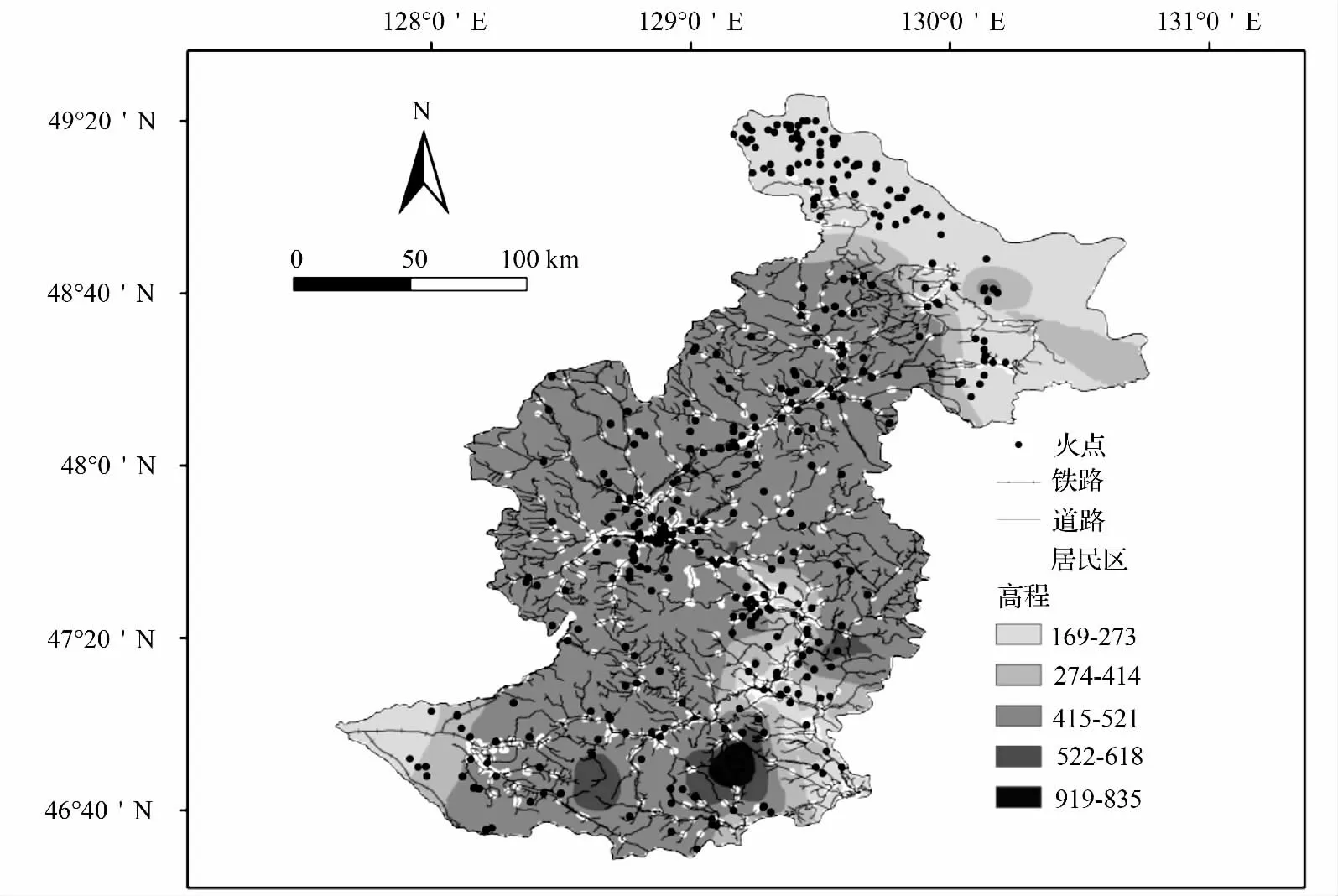
图1 伊春地区火点、铁路、道路、居民区和高程分布
气象数据来源于中国气象数据共享网络(ht- tp:cdc.cma.gov.cn/),包括日平均地表温度、日最高地表温度、日最大风速、20:00—20:00 时降水量、日照时间、日平均气温、日最高气温、日平均相对湿度共8 个气象因子。
运用ArcGIS10.0 软件分别从数字地形图、数字植被图中提取火点/非火点所对应的海拔、坡度、坡向和植被类型数据,用ArcGIS 的图层链接功能计算火点/非火点到铁路、公路和居民点的最短距离,结合EXCEL 的编程模块提取火点/非火点所对应的每日气象数据,并应用SPSS19.0 对1980—2009 年伊春地区的林火发生数据及各驱动因子数据进行基本统计描述(表1)。本研究从总样本数据中随机选取60%的训练样本用于建模,另外40%的测试样本用来检验模型[15]。为了保证变量选择的稳定性,在随机划分数据的过程中,进行了3 次重复并分别进行模型拟合,最后选择在3 次拟合结果中出现2 次或以上的重要变量进入全样本数据模型的拟合计算。
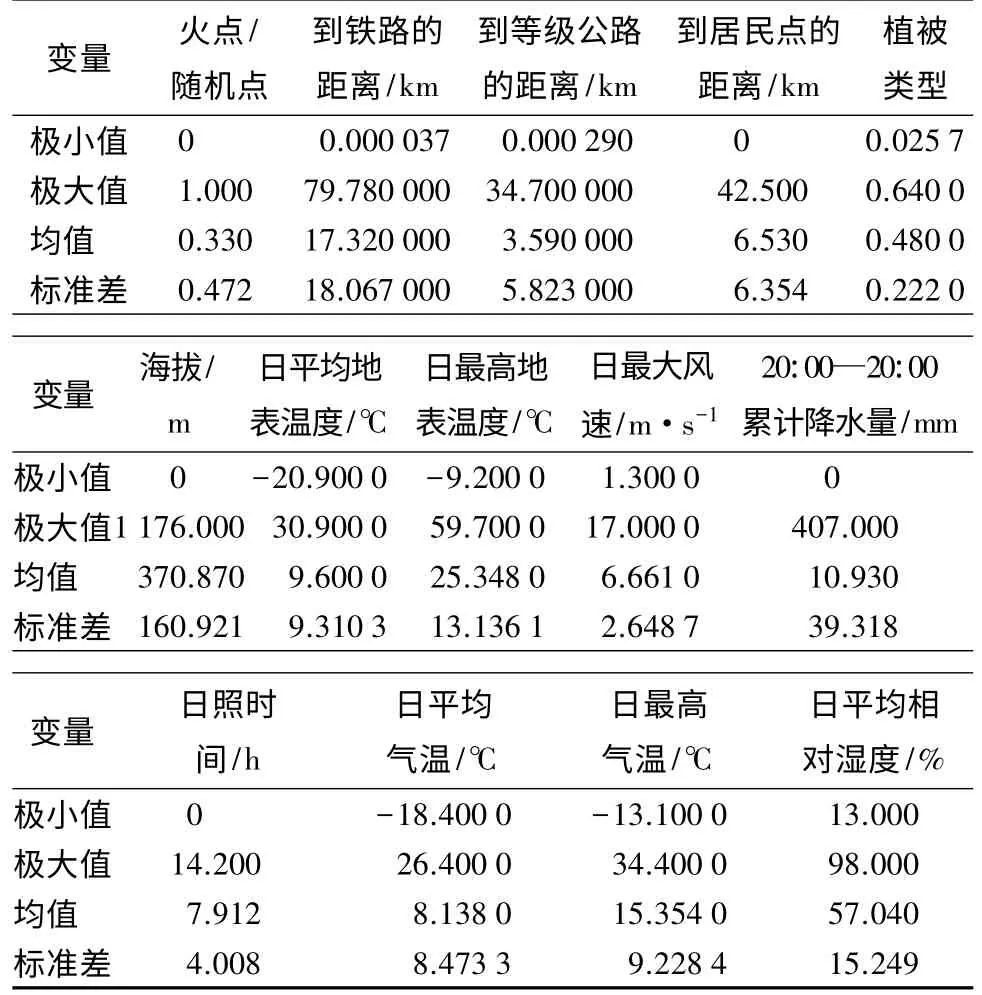
表1 林火发生数据与驱动因子的基本统计描述
2.2 随机森林算法
2.2.1 随机森林基本原理
随机森林是一种基于分类回归树的组合分类器{h(x,θk),k=1,2,3,…},其中x 是输入向量,θk是独立同分布的随机向量。采用bootstrap 重抽样技术从原始数据集中抽取n 个与原始数据集大小相同的bootstrap 样本,对这n 个bootstrap 样本分别建立n棵没有剪枝的决策树,在每棵树的节点处随机抽取m 个变量(m 小于总变量数量),且在m 个变量中选择一个最具有分类能力的变量进行分裂,从而得到n 个结果;最后将这n 个结果综合起来作为随机森林的最终结果[10-11,14]。
2.2.2 重要影响因子选择与排序
随机森林能够计算变量的重要性得分,根据其得分可以用来评价变量的贡献力大小,变量的重要性得分越高,说明该变量的贡献力越大。衡量变量重要性的指标有两个,一个是人为地加入噪声后,随机森林预测准确性的下降程度,该值越大说明该变量的重要性越大;另一个是平均基尼指数减少量,通过基尼指数计算节点纯度,从而比较变量的重要性,该值越大说明该变量的重要性越大[13];进而根据各个变量的重要性得分,以降序的方式对其进行排列,剔除不重要的变量重新构建随机森林;最后以使袋外误差最小为原则,选择袋外误差最小的指标集作为模型的最终指标体系。本研究应用随机森林预测准确性的下降程度来评价变量的重要性,并在R 统计软件中调用randomForest 程序包、varSelRF 程序包和varImpPlot 函数来实现随机森林的构建和特征变量的选择与排序。
2.2.3 重要因子的影响力分析
因子的影响力分析是基于局部依赖图进行的。局部依赖图是将“黑匣子”分类和回归工具中自变量对因变量的影响可视化的工具[11,19]。设分类函数为f,预测变量X=(X1、X2、…、Xs),则f(X)= f(X1、X2、…、Xs)。函数f 对变量Xj依赖值等于函数f 关于除Xj变量之外的所有变量的期望值。对于林火发生与否的二分类问题,则f(X)= 0.5ln(p(X)/(1-p(X))= 0.5logit(p(X)),其中p 为林火发生的概率[11,19-20]。
2.3 模型拟合优度和预测准确率检验
结合受试者工作特征曲线分析法对随机森林算法进行拟合优度检验[15],并结合林火发生的临界值,计算随机森林算法对林火发生与否的正确判别率,对随机森林算法的拟合结果进行评价。受试者工作特征曲线(ROC 曲线)是一条以假阳性率为横坐标,真阳性率为纵坐标绘制而成的曲线,是一种不依赖阈值的检验方法,以ROC 曲线下的面积(AUC)作为模型预测准确性的衡量标准。AUC 值在[0.5,1]区间上变化,AUC 值越大,说明模型的拟合效果越好。一般认为,AUC 值等于0.5 时相当于是一个完全的随机预测;在(0.5,0.7]之间说明模型的拟合效果较差;在(0.7,0.9]之间说明模型的拟合效果中等;在(0.9,1]之间说明模型的拟合效果非常好[21]。根据ROC 曲线分析法计算出来的敏感性值和(1-特异性值),求出约登指数,进而确定林火发生的临界值,如果林火发生的预测概率大于该临界值则认为有林火发生,否则认为无林火发生[22-24]。
2.4 林火发生概率分布格局
基于随机森林算法所计算的全样本数据预测概率,运用ArcGIS10.0 对其进行克里金插值,分析伊春地区林火发生概率的空间分布特征。并且根据林火发生的临界值,将小兴安岭地区划分成3 个森林火灾等级:低火险区(<临界值)、中等火险区(临界值~0.5)和高火险区(>0.5)[23],对小兴安岭地区的火险等级进行区划。
3 结果与分析
3.1 驱动因子分析
由变量的重要性排序图(图2)可知,日平均相对湿度、日最高地表温度、海拔、日最高气温和到居民点的距离等5 个变量进入了全样本数据模型的拟合计算,表明这5 个变量是影响林火发生的主要驱动因子;且日平均相对湿度对林火发生的影响最大,日最高地表温度次之,而到居民点的距离对林火发生的影响相对其他4 个变量较小。
为了更好地分析各主要影响因子对林火发生的影响规律,运用partialPlot 函数做出随机森林算法中林火发生与各影响因子之间局部依赖图(图3),横坐标为驱动因子的取值,纵坐标为[logit(林火发生概率)]/2,纵坐标值越大越容易发生火灾。
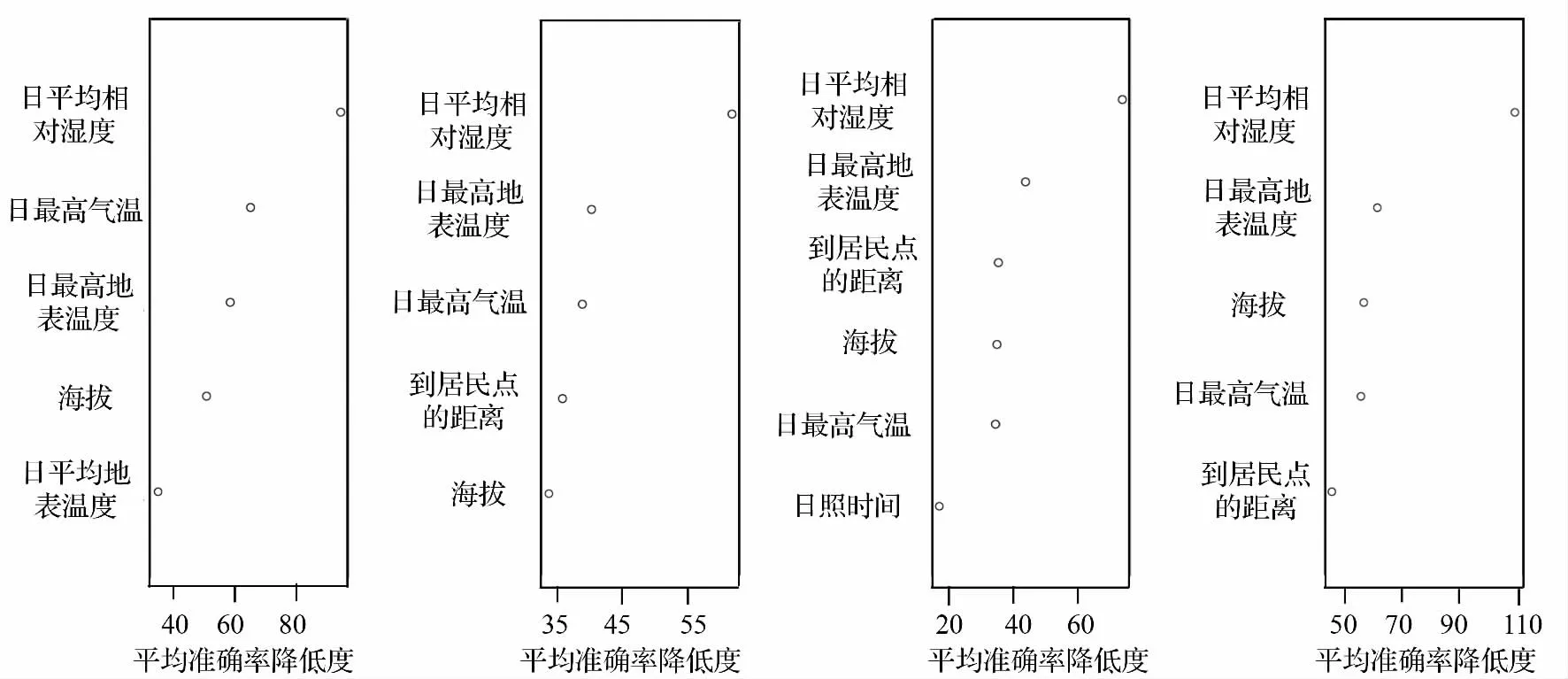
图2 主要驱动因子的重要性排序图
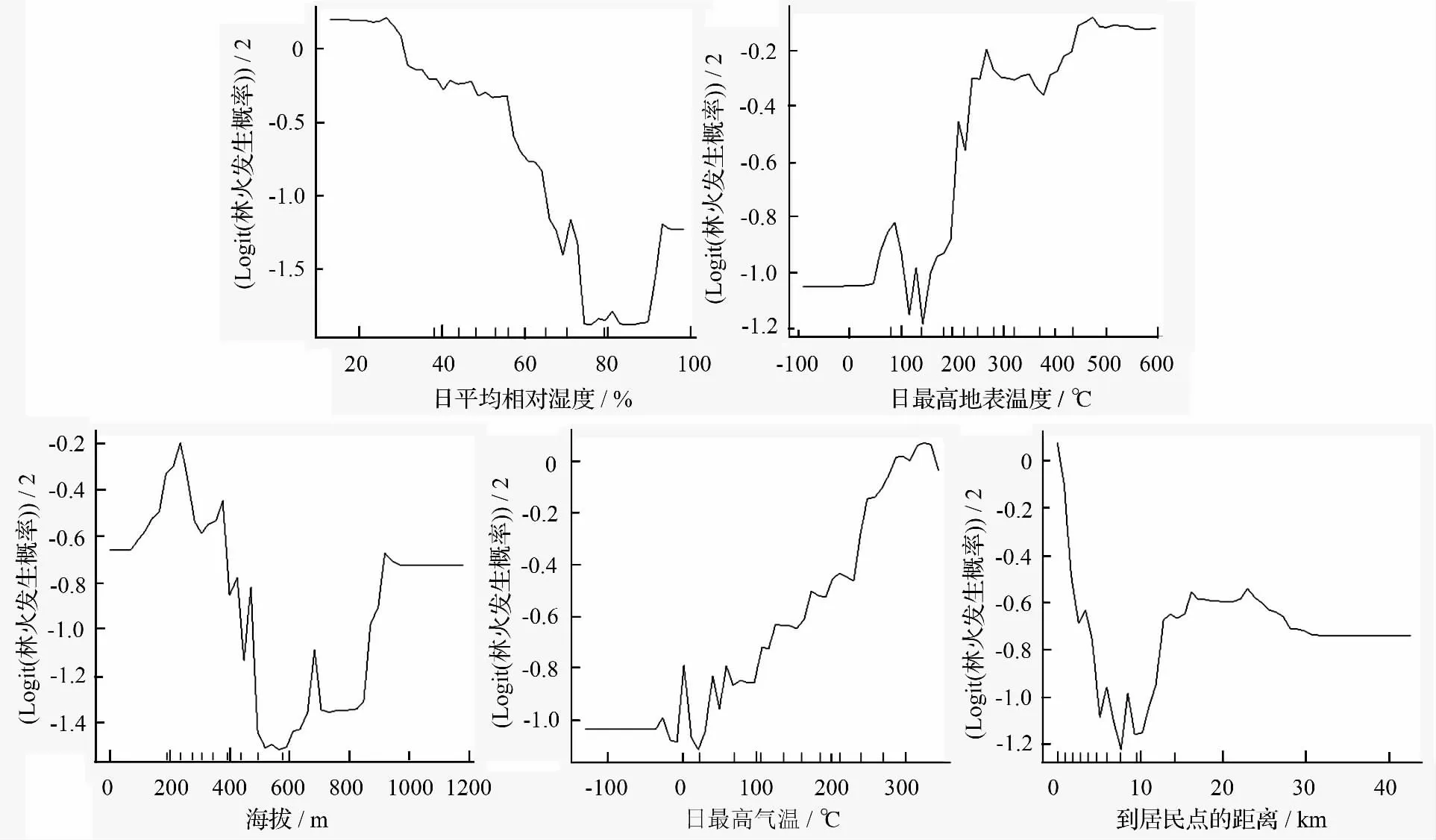
图3 主要驱动因子对林火发生的影响
图3 显示了5 个重要影响因子各自对林火发生的影响区间。日平均相对湿度对林火发生的影响呈下降趋势,当天平均相对湿度小于30%时,火灾发生的概率最大;在80%到90%的范围内对林火发生的影响最小。日最高地表温度大约在15 ℃的范围内对林火发生的影响最小,大于15 ℃之后对林火发生的影响逐渐增大。海拔在400 m 以下时对林火发生的影响较大,在400 ~900 m 的范围内,对林火发生的影响较小。日最高气温对林火发生的影响呈上升趋势,当天最高气温小于0 ℃时,火灾发生概率相对较小;大于0 ℃后,日最高气温与林火发生呈正相关关系。离居民点的距离(h)<8 km 的范围内呈下降趋势,在8 km<h≤18 km 的范围内呈上升趋势,在18 km<h≤30 km 的范围内略有下降,>30 km 之后呈平稳状态。
3.2 模型校验及拟合结果分析
图4 为3 个训练样本(60%)的ROC 曲线图,其AUC 值分别为0.859、0.819、0.835,且P 均小于0.001,说明基于特征变量选择结果所建立的随机森林算法对林火发生的拟合效果较好,且具有统计意义,可用于林火发生的拟合计算。基于ROC曲线分析法所计算出的林火发生临界值分别为0.456、0.420、0.320。
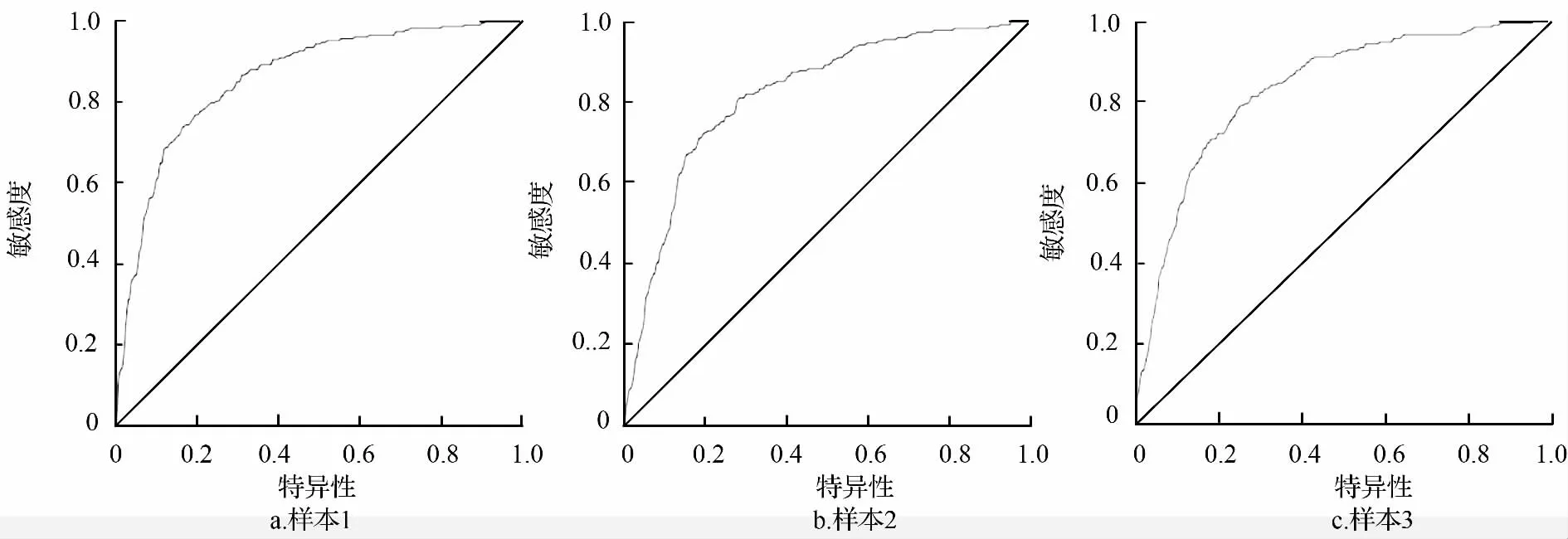
图4 随机森林ROC 曲线图
随机森林算法对训练样本的正确预测概率在76.4%~80.4%,对测试样本的正确预测率在75.8%~81.5%,且对未发生林火的正确预测率整体上高于对林火发生的正确预测率(表2)。最后,基于特征变量的选择结果,对全样本数据进行拟合计算。经计算全样本数据模型的AUC 值为0.848,P<0.001,林火发生的临界值为0.413,随机森林算法对林火发生的正确判别率为79.3%。
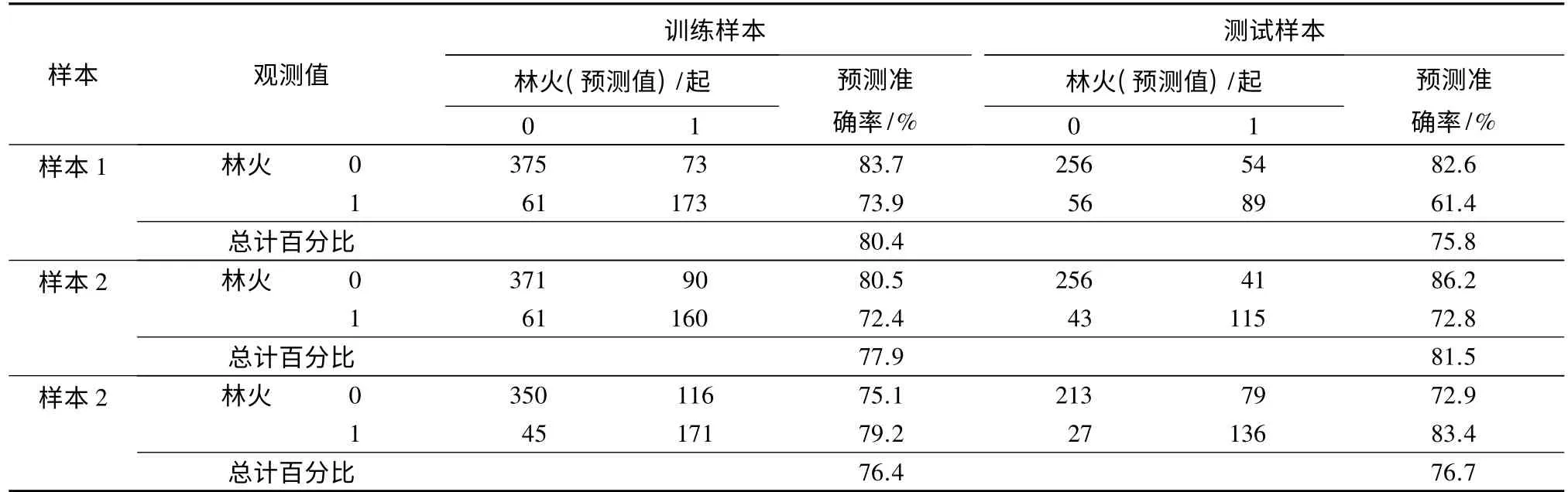
表2 随机森林算法对林火发生的正确判别率
3.3 林火发生概率分布格局分析
基于随机森林算法所计算的全样本数据的预测概率,运用ArcGIS10.0 对其进行克里金插值,并对其进行火险等级划分。从林火发生概率分布图(图5)和火险区划图(图6)可知,伊春地区的林火发生主要集中在中部地区、东南地区和最北部地区,西南、东北地区也存在林火易发区。低火险等级区域占总面积的77.0%,中火险等级区域占总面积的13.9%,高火险等级区域占总面积的9.1%。
4 结论与讨论
综合分析了高程、植被类型、基础设施和气象因子等13 个因子与林火发生之间的关系。研究结果表明相对湿度、最高地表温度、海拔、最高气温和离居民点的距离是影响伊春地区林火发生的主要影响因子。相对湿度是反应林内可燃物含水量的一个重要指标,对林火发生有重要影响[25]。研究表明,日平均相对湿度对林火发生的影响力最大,说明了林火发生对相对湿度的变化非常敏感,这与其他学者的研究相一致[23]。此外,研究发现日平均相对湿度小于30%时,火灾发生的概率最大,这与郑琼等[7]对伊春地区的研究结果一致。气温与林火的发生关系密切,可以直接影响相对湿度的变化,减少可燃物含水率,从而降低可燃物着火点。研究结果显示日最高地表温度和日最高气温对林火发生有重要影响,且二者的影响趋势相近。日最高地表温度小于20 ℃,日最高气温小于5 ℃时对林火发生的影响较小。日最高气温大于5 ℃时,其与林火发生大致呈正相关关系,即温度越高,越容易发生火灾,大于30℃时,火灾概率开始下降,与王淑华等[9]对伊春地区的研究结果一致。此外,研究还发现林火易发生在0~400 m 的低海拔区域,主要原因在于伊春地区地面海拔高度在125~330 m,且地势平缓,是主要的城市人口和工业的聚集地,人为活动频繁,容易发生人为火灾。而森林区域主要分布在海拔400 m 以上的区域,是森林旅游的主要分布区,也是当地林火管理的重点区域,由于监控严格,管理到位,发生森林火灾的次数相对较少。本研究还显示离居民点的距离也会对当地林火发生产生显著影响,林火易发生在距居民区10 ~15 km 的范围内,当地实际情况是很多森林旅游景点及森林栈道大多修建于离市区10 km 左右范围,导致当地与森林有关的人为活动主要发生在该距离尺度内。
另一方面,本研究没有发现植被类型对林火发生有显著影响,这与Maingi 和Henry[26]和Avila-Flores 等[27]的研究结果相反,可能由于该地区林型相对单一,空间异质性不明显,因此植被类型没有表现出很强的影响力。王淑华等[9]和郑琼等[7]对伊春地区的研究结果表明当天日照时间与森林火灾呈显著的正相关关系,王淑华等[9]与王继常和李利[8]对伊春地区的研究结果表明风速与森林火灾也呈显著的正相关关系,而本研究结果没有发现日照时间和风速对森林火灾有显著影响,原因在于随机森林算法并不是单一的检验某一气象因子与林火发生之间是否有显著的线性关系,而是分析气象因子之间对林火发生的相对重要性。这种方法的优势就在于在复杂多变的自然环境下,能够较准确地分析出影响林火发生的重要因子及他们之间的影响权重。而且随机森林抽样检验的过程也能够保证因子重要性检验的准确性和稳定性。更为重要的是随机森林是线性相关性的检验,这也是该方法优于传统方法的一个重要方面。
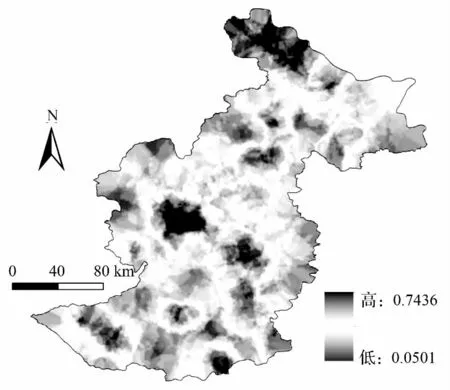
图5 林火发生概率分布图
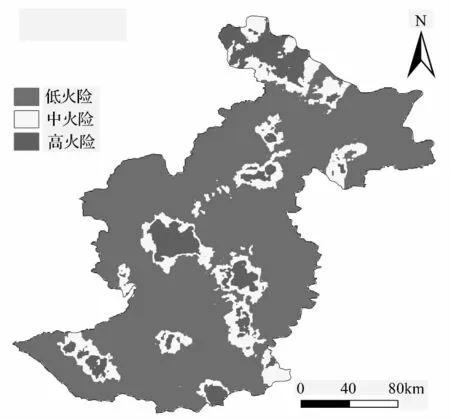
图6 火险区划图
模型的拟合结果显示,随机森林算法对我国伊春地区林火发生的预测具有较高的预测精度,且模型的拟合效果较好,其对全样本数据的拟合精度为79.3%,表明随机森林算法可用于伊春地区林火发生的预测预报。伊春地区林火发生概率插值图和火险区划图显示,该地区林火发生主要集中在中部地区、东南地区和最北部地区,西南、东北地区也存在林火易发区。可在这些地区配备更多的消防资源,做好林火预防工作,使林火发生所造成的损失达到最小。
[1] Chang Y,He H S,Bishop I,et al. Long-term forest landscape responses to fire exclusion in the Great Xing’an Mountains,China[J]. International Journal of Wildland Fire,2007,16(1):34-44.
[2] Liu H P,Randerson J T,Lindfors J,et al. Changes in the surface energy budget after fire in boreal ecosystems of interior Alaska:an annual perspective[J]. Journal of Geophysical Research Atmospheres,2005,110(D13):2515-2530.
[3] 彭欢,史明昌,孙瑜.基于Logistic 的大兴安岭雷击火预测模型[J].东北林业大学学报,2014,42(7):166-169.
[4] Zhong M H,Fan W C,Liu T M,et al. Statistical analysis on current status of China forest fire safety[J]. Fire Safety Journal,2003,38(3):257-269.
[5] 刘志华,杨健,贺红士,等.黑龙江大兴安岭呼中林区火烧点格局分析及影响因素[J].生态学报,2011,31(6):1669-1677.
[6] 高永刚,张广英,顾红,等.气候变化对伊春林区森林火灾的影响[J].安徽农业科学,2008,36(28):12269-12271,12274.
[7] 郑琼,邸雪颖,金森.伊春地区1980—2010 年森林火灾时空格局及影响因子[J].林业科学,2013,49(4):157-163.
[8] 王继常,李利.伊春林区森林火灾与气象因子相关分析[J].防护林科技,2014(6):48-50,62.
[9] 王淑华,孙鹏飞,程春香.伊春市气象因子与森林火灾相关性研究[J].林业科技,2008,33(2):24-26.
[10] Breiman L. Random forests[J]. Machine Learning,2001,45(1):5-32.
[11] Cutler D R,Edwards T J,Beard K H,et al. Random forests for classification in ecology[J]. Ecology,2007,88(11):2783-2792.
[12] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1190-1197.
[13] 刘盈君,张涛,王璐,等.基于随机森林的精神分裂症血清代谢组学研究[J].山东大学学报:医学版,2015,53(2):1-5.
[14] Oliveira S,Oehler F,San-Miguel-Ayanz J,et al. Modeling spatial patterns of fire occurrence in Mediterranean Europe using Multiple Regression and Random Forest[J]. Forest Ecology and Management,2012,275(4):117-129.
[15] Rodrigues M,de la Riva J. An insight into machine-learning algorithms to model human-caused wildfire occurrence[J]. Environmental Modelling & Software,2014,57:192-201.
[16] Kane V R,Lutz J A,Alina Cansler C,et al. Water balance and topography predict fire and forest structure patterns[J]. Forest Ecology and Management,2015,338:1-13.
[17] 于颖,范文义,杨曦光.1901—2008 年小兴安岭森林NPP 估算[J].林业科学,2014,50(10):16-23.
[18] Catry F X,Rego F C,Bação F L,et al. Modeling and mapping wildfire ignition risk in Portugal[J]. International Journal of Wildland Fire,2009,18(8):921-931.
[19] Hastie T,Friedman J,Tibshirani R. The Elements of statistical learning-data mining,Inference,and prediction[M]. New York:Springer-Verlag,2001.
[20] Liaw A,Wiener M. Classification and regression by random forest[J]. R News,2002,2(3):18-22.
[21] del Hoyo L V,Martín Isabel M,Javier Martínez Vega F. Logistic regression models for human-caused wildfire risk estimation:analysing the effect of the spatial accuracy in fire occurrence data[J]. European Journal of Forest Research,2011,130(6):983-996.
[22] 邓欧,李亦秋,冯仲科,等.基于空间Logistic 的黑龙江省林火风险模型与火险区划[J].农业工程学报,2012,28(8):200-205.
[23] Chang Y,Zhu Z L,Bu R,et al. Predicting fire occurrence patterns with logistic regression in Heilongjiang Province,China[J]. Landscape Ecology,2013,28(10):1989-2004.
[24] 柳生吉,杨健.基于广义线性模型和最大熵模型的黑龙江省林火空间分布模拟[J].生态学杂志,2013,32(6):1620-1628.
[25] 毛光伶.林火与气象条件相互关系及其预报[J].气象,1988,14(9):52-54.
[26] Maingi J K,Henry M C. Factors influencing wildfire occurrence and distribution in eastern Kentucky,USA[J]. International Journal of Wildland Fire,2007,16(1):23-33.
[27] Avila-Flores D,Pompa-Garcia M,Antonio-Nemiga X,et al.Driving factors for forest fire occurrence in Durango State of Mexico:a geospatial perspective[J]. Chinese Geographical Science,2010,20(6):491-497.
