一种星载IP交换机队列管理器的设计*
2015-03-25乔庐峰陈庆华李欢欢
王 晶,乔庐峰,陈庆华,郑 振,李欢欢
(解放军理工大学 通信工程学院,江苏 南京 210007)
一种星载IP交换机队列管理器的设计*
王 晶,乔庐峰,陈庆华,郑 振,李欢欢
(解放军理工大学 通信工程学院,江苏 南京 210007)
针对星载IP交换机中硬件存储资源使用受限的情况,提出了一种适用于共享存储交换结构、存储资源占用少的队列管理器。通过添加索引的方法,使得所有的单播队列能够共享一个指针存储区。根据位图映射,将组播指针转化为多个单播指针,即可把组播操作的数据流按照单播操作方式写到相应的逻辑队列路径,达到节约存储器资源的目的。该队列管理器通过链表数据结构的头部和尾部来控制指针索引的写入和输出。最后,在Xilinx的xc6vlx130t FPGA进行了综合实现,结果显示,该方案相比基于指针复制的队列管理器,在8端口的交换机中存储器资源的使用量要节约22%以上。
星载IP交换机;队列管理器;组播;FPGA
0 引 言
由于受到外太空恶劣环境和航天级器件使用受限的影响,星上交换设备作为卫星有效载荷的一部分,其功率消耗、缓存容量和可采用的技术都受到了很大的限制[1]。太空中的空间粒子流对器件的正常工作产生严重影响,其中最主要的影响之一是单粒子翻转问题,即空间粒子流造成的电路逻辑错误。采用FPGA进行系统实现时,三模冗余技术是解决单粒子翻转最主要的方法之一[2]。三模冗余方法在提高电路抗单粒子效应能力的同时,要求一片FPGA的主要资源使用量原则上不能超过总资源量的1/3。这对交换机的硬件资源消耗提出了苛刻的要求。另外,星载IP交换机中可用存储器也受到了严格限制,航天级SRAM、SDRAM和DDR的容量和工作时钟频率通常远低于普通商用级器件。
因此,必须针对其硬件资源使用受限和性能方面的要求,设计出结构简单、性能良好和可靠性高的星上交换结构。而设计交换结构的一个难点就在于队列管理器[3](Queue Manager, QM)的设计实现。共享存储(Shared Memory, SM)交换结构由于具有结构简单、存储资源利用率高、低时延的特性[4],是设计星上交换设备很好的一个选择。共享存储交换结构中主流的地址复制队列(Address Copy Queue,ACQ)需要额外的空间存放复制的地址,会使得QM电路占用过多的存储资源[5]。
本文提出一种ATQ(Address Transfer Queue)队列管理器结构,通过添加一个索引存储区,配合原有的自由指针队列(Free Queue, FQ),使得所有的单播队列共享一个指针存储区,并把组播指针按照位图映射转化为多个单播指针以将组播操作转化成单播操作,这样就只需一个单独的组播队列就可以完成组播操作。通过与当前主流的基于ACQ的QM比较,本文提出的方案存储资源占用更少,能够满足星载IP交换机苛刻的存储资源要求。
1 基于ACQ的QM结构分析
本文讨论基于ACQ的结构并取之作对比。基于ACQ的QM结构框图如图1所示。数据流进入后根据单播/组播两种不同类别的操作,进入到相应的路径,然后从自由指针存储区(FQ_ram)中获取一个自由指针,该指针就是指向外部共享SRAM的地址[6]。如果是单播请求,则把信元数据存储在外部共享SRAM中缓存起来,指针则根据队列号存入相应的队列控制器(Queue Controller, QC),QCs的输出根据加权轮询(Weighted Round Robin, WRR)算法[7]实现不同优先级的有效调度。如果是组播请求,信元数据与单播的数据一样存储在外部共享SRAM中缓存起来,而组播指针则如图1所示,通过地址复制电路(Address Copy Circuit, ACC)把指针复制到各个相应的QCs中[8],然后与单播操作类似,在输出端取出需要的指针。
在输出端,对于单播操作,QC中的指针取出后,便根据该指针向外部共享SRAM取信元数据发送到输出端口,信元输出后便把该指针归还到自由指针队列中。组播操作时,取出每个组播组的QC中该组播指针时,都从SRAM中取一遍相应的信元数据并发送到对应的输出端口。当所有组播成员都按照组播指针发送完其指向的信元数据后,才把它归还到自由指针队列。
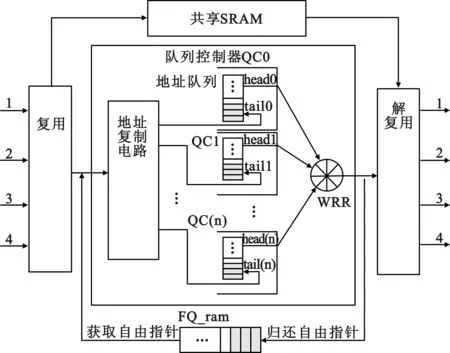
图1 基于ACQ的QM结构
基于ACQ的QM需要为每个输出端口建立QC,以用来存储单播/组播请求的指针,当物理端口数量很大时,QM也要建立相应数量的QC来存储指针。这样的方式带来的后果就是会占用过多的存储资源[9]。文献[9]在Xilinx的V4sx55 FPGA实现的基于ACQ交换结构在8个端口的情况下的Block RAM/FIFO资源消耗量达到25%,当端口数量增加到32个端口时,在原有FPGA器件上将无法满足设计要求。当然,如果换一个存储量更大的FPGA器件可以解决问题,但随之而来的问题是,会增加硬件成本,而且当端口数量再增加时,可能会再次遇到同样资源不够用的问题。另一个解决办法是降低设计电路的资源消耗量,本文提出的方案就是基于该思路,下面将介绍本文提出的队列管理器。
2 基于ATQ的QM设计
为了克服基于ACQ的QM在特定应用中存储资源占用过多的问题,本文设计了一种基于ATQ的QM,其整体结构如图2所示。与基于ACQ的QM不同的是:自由指针不直接建立队列,索引存储区(index_ram)中的索引用于建立队列,索引指针存储区(index_ptr_ram)是以索引为地址,存放的是自由指针;所有的单播队列共享一个指针存储区,所以无需建立多个QCs;组播操作通过位图映射转换为单播操作,不再需要ACC模块,避免了组播操作占用存储资源过多的问题。

图2 基于ATQ的QM结构
2.1 ATQ内部队列操作分析
首先分析单播请求的情况,数据流从输入端进来,信元数据存储在外部共享SRAM中,然后从index_ram中获取一个索引,同时从FQ_ram获取一个自由指针,该指针是信元数据对应在SRAM中的地址。以获取的索引为地址,将获取的自由指针写入索引指针存储区。此时自由指针与索引同步,即与每一个自由指针存储地址对应着的index_ram中存储着一个索引。输出时,根据索引找到对应的单播队列,并以索引为地址读出索引指针存储区的自由指针,然后以自由指针为地址取出存储在SRAM中的信元数据,发送到对应的输出端口。
组播操作的情况是节约存储资源的关键所在。图2中可以看到,本文设计的QM的结构相比图1中基于ACQ的结构,组播操作做了很大的改变。组播请求时,信元数据存储在外部共享SRAM中,从index_ram中获取一个索引,同时从FQ_ram获取一个自由指针,以获取的索引为地址,将获取的自由指针添加到index_ptr_ram的链表中。此时还需为每次组播操作存储一个组播计数器(Multicast Count, MC)[10],MC值表示当前组播操作要发送到指定端口的数量,该值在归还请求时要用来指定归还索引的个数,以确保组播操作的正确性。组播的输出采用的方式是根据位图映射将组播操作按比特位从低位到高位依次转化为单播操作,位图映射值中每个为1的比特都需要转化为1次单播操作,转化完成后即将该比特置0,直到最后一个为1的比特被置为0。位图映射值与相应写入单播队列号的对应关系如表1所示,其中x表示该比特位不影响映射结果。
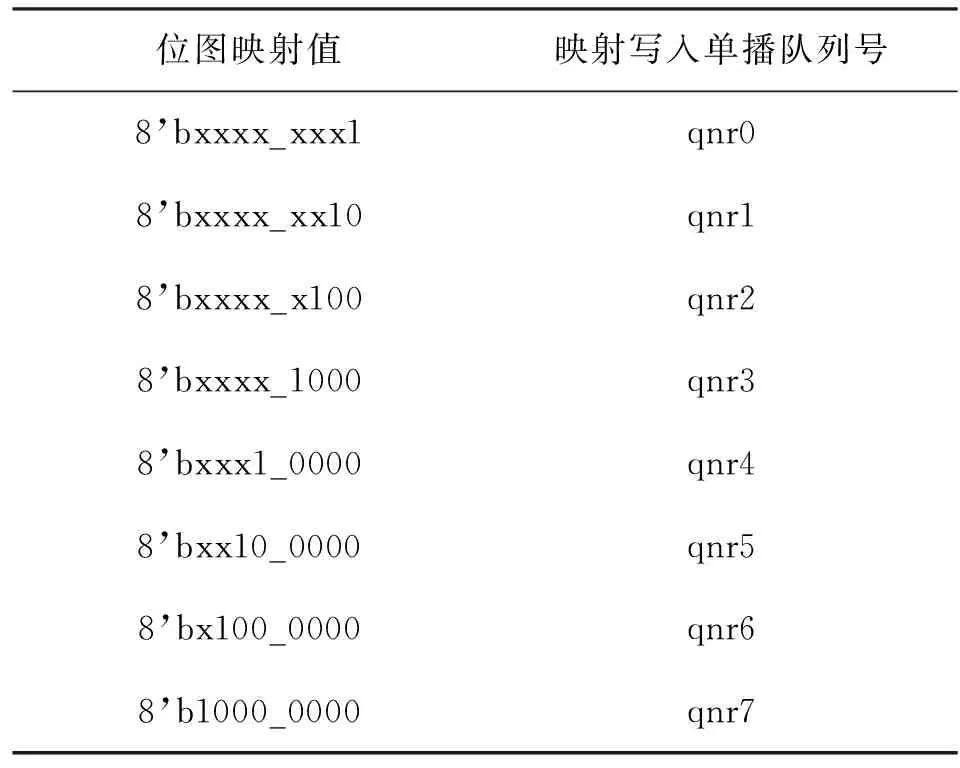
表1 位图映射值与对应写入单播队列号
组播操作流程举例如下,假设位图映射值为8’b0101_1001,由于位图映射值的第0比特为1,向index_ram中再获取一个索引,以它为地址将当前的自由指针写入索引指针存储区,对照表1可知,应该将获取的索引写入qnr0队列链表中,此时并把当前位图映射值置为8’b0101_1000,即把操作完成的那个比特由1置为0。本次操作完成后,跳转到组播操作开始的状态,从低位到高位重复上一步操作,每次要获取一个新的索引,而自由指针保持不变,最后一次添加索引到qnr6队列链表中,置位图映射值为8’b0000_0000,位图映射操作完成。该操作完成后,每个组播队列成员都获取了索引,以该索引为地址,组播成员可在指针索引存储区中得到相同的自由指针,然后各自以该自由指针为地址从外部SRAM中获取组播数据,发送到各个组播端口。
归还请求时,针对单播,索引与自由指针是一起归还。组播则是先读取输入时存储的MC值,判断是否为0,若不为0,自由指针暂不归还,只归还一个索引,且将MC值减1。然后重新跳转到归还请求的状态,重复操作,直到判断出MC值减为0,才能归还自由指针,归还自由指针后,此次归还操作结束。
2.2 数据结构操作分析
索引的添加使得所有的队列能够共享一个指针存储区,本文是通过链表来链接索引操作的。图3给出了两条链表逻辑队列操作过程。存储区(ptr_ram)左侧存放的是相应的portmap值,位图映射需要用到该参数。自由指针不直接建立队列,而是通过索引来建立,索引链表中存储的是队列获取的索引。通过链表数据结构的头部(head)和尾部(tail)可以控制索引的写入和输出。写入时,将获取的索引写到对应队列链表的tail中,读出时,从相应队列链表的head处取出要归还的索引。

图3 两条链表逻辑队列
3 仿真结果与分析
本文选用Xilinx的xc6vlx130t FPGA来实现基于ATQ的QM,开发环境是Xilinx集成开发环境ISE 14.3,核心电路模块是用Verilog HDL编程实现。仿真工具用的是ModelSim SE 10.0a,下面给出关键电路的仿真结果。
3.1 输入请求仿真与分析
输入请求时,数据统一存入外部共享SRAM,从FQ_ram中获取自由指针,index_ram中获取索引。根据队列号寻址相应的队列,将索引加到该队列链表的tail,并将tail指向下一个索引,head值保持不变。图4是输入请求时的仿真波形图,本文仿真了qnr为3、4这两种单播输入及qnr为8的组播输入的情况。可以看到,输入请求时,自由指针与索引是同步的,并且每次请求都会在相应的地址写入MC值,qnr为3、4时,由于是单播,MC写入值保持为0。qnr为8时,组播操作,MC值一次写入值为3,另一次写入值为2,存储的MC值在归还请求操作流程中要用到。

图4 输入请求仿真波形
3.2 输出与归还请求仿真与分析
输出请求时,根据队列号寻址相应的队列链表,然后取出需要的索引、自由指针。当前自由指针操作结束,后级电路释放该指针后会给ATQ归还请求,即将操作完成的自由指针写入FQ_ram,给后续操作再用,充分利用存储资源。图5是输出请求的仿真波形,图6给出了归还请求的仿真波形。

图5 输出请求仿真波形

图6 归还请求仿真波形
输出操作是从相应队列链表的head处开始,qnr为3时,head从index_ram的0开始,每次给完请求应答后,head值加1,qnr3操作结束后,head值增加到9,则下一个队列qnr4的head从9开始,同理qnr为8的时候,head值从17开始,对应的在每次请求应答后加1。head值的递增是在缩短当前队列链表的长度,后级电路给归还请求后,这些被释放的索引、自由指针将会在后续的输入请求时再次使用。有一点需要注意的是,组播操作的归还请求时,先归还索引,然后判断MC值是否为0,为0才能归还自由指针,否则只能归还索引并将MC值减1。图6中可以看到,MC值减为2,1,0时,index_ram写操作执行了3次,FQ_ram的写操作只在MC值为0时执行了1次。
3.3 综合结果对比分析
本文对基于ACQ和基于ATQ两种模型在Xilinx的xc6vlx130t FPGA进行了实现,使用ISE14.3自带的综合工具XST分别进行了综合,得出了综合结果。表2是两种模型综合结果报告对比,表2中,基于ACQ的QM共占用了2 920个Slice Registers、2 983个Slice LUTs和70个Block RAM/FIFO,而对应本文设计的基于ATQ的QM模型共占用量分别是1 199个、1 625个、13个。显然,基于ATQ的QM的关键源消耗量都低于基于ACQ的QM,特别是Block RAM/FIFO,使用量要少22%。因此,对于海量端口的网络应用,本文设计的基于ATQ的QM有很大的优势。
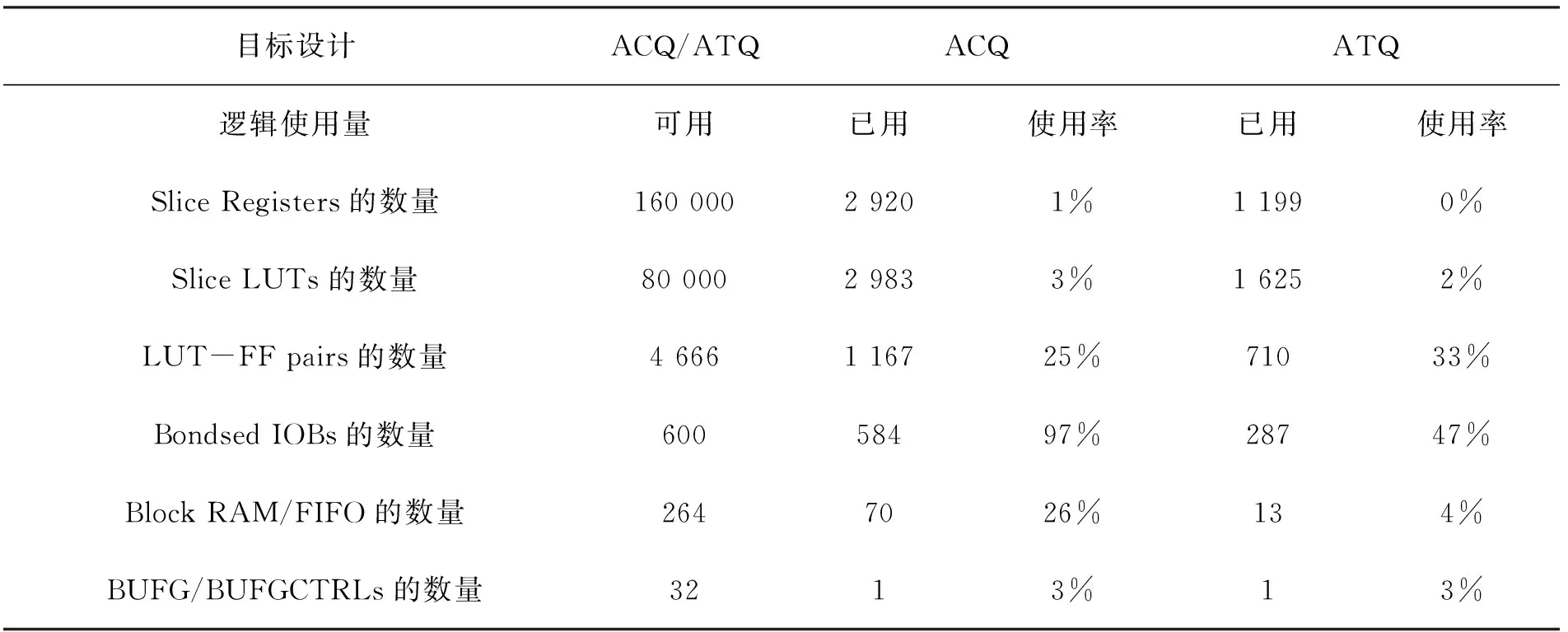
表2 两种模型综合结果报告对比
两种结构模型都是实现了8个端口的情况,基于ACQ的结构Block RAM/FIFO资源消耗量达到26%,当端口数量增加4倍即32个端口时,基于ACQ的QM将无法满足设计要求,而本文设计的方案,不但能满足设计要求,而且还有一定的裕量,为今后电路的扩展提供了条件。
4 结 语
本文针对星载IP交换机资源受限的情况,设计实现了一种基于ATQ的QM,分析了它的结构原理及实现方法。整个电路在Xilinx的xc6vlx130t FPGA进行了实现。通过与基于传统ACQ的QM作对比,充分体现该方案在节约资源消耗方面的优势,关键资源消耗要少22%以上。在星上交换设备中,本文设计实现的基于ATQ的QM是一个非常好的选择。我们将在未来的工作中搭建实验平台,运用该平台,分析并改善本文提出方案的性能。
[1] Ors T,Sun Z, Evans B G. A Meshed VSAT Satellite Network Architecture Using an On-Board ATM Swith[C]// IEEE International Conference on Performance, Computing, and Communications [Piscataway:IEEE,1997.208-214.
[2] THO Le-Ngoe.Switching for IP-based Multimedia Satellite Communications[J]. IEEE Journal on Selected Areas in Communications,22(3),2004(4):318-322.
[3] 高仲合, 田硕. 一种基于负载的公平性主动队列管理算法[J]. 通信技术, 2011, 44(11): 94-96. GAO Zhong-he, TIAN Shuo.Load-based Fair Active Queue Management Algorithm[J]. Communications Technology,2011,44(11):94-96.
[4] ZHANG Qi, Woods Roger, Marshall Alan. Design and Implementation of a Flexible Queue Manager for Next Generation Networks[C]// 2011 Conference Record of the Forty Fifth Asilomar Conference on IEEE. Signals, Systems and Computers (ASILOMAR),2011:498-502.
[5] Dong Z, Rojas-Cessa R. Throughput Analysis of Shared-Memory Crosspoint Buffered Packet Switches[J]. Communications Iet, 2012, 6(9):1045-1053.
[6] ZHENG Ya-song, XU Yuan-chao, MENG Hai-bo, et al. Optimizing Mapreduce with Low Memory Requirements for Shared-Memory Systems[C]// 2014 15th IEEE/ ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD)IEEE Computer Society,2014:1-6.
[7] Heisswolf J, Konig R, Becker J. A Scalable NoC Router Design Providing QoS Support Using Weighted Round Robin Scheduling[C]// Proceedings of the 2012 IEEE 10th International Symposium on Parallel and Distributed Processing with Applications IEEE Computer Society,2012:625-632.
[8] Ejlali Mina, Saidi Hossein, Montazeri Mohammad Ali, et al. Design and Implementation of a Shared Memory Switch Fabric[C]// 2012 Sixth International Symposium on IEEE, Telecommunications (IST), 2012:721-727.
[9] 沈泽民,乔庐峰,陈庆华等. 一种多优先级变长调度星载IP交换机交换结构的设计[J]. 电子学报,2014,42(10): 2045-2049. SHEN Ze-min, QIAO Lu-feng, CHEN Qing-hua,et al.Design of Switch Fabric in Satellite Onboard IP Switch based on a Multi-Priority Variable-Length Packets Scheduling[J].Acta Electronica Sinica,2014,42(10):2045-2049.
[10] LU Qing-mei, HE Li-lin. Research on the Routing Algorithm based Greedy Multicast Algorithm[C]// 2010 International Conference on Computer Application and System Modeling. 2010: 437-439.
Design of Queue Manager in Satellite-Borne IP Switch
WANG Jing,QIAO Lu-feng,CHEN Qing-hua,ZHENG Zhen,LI Huan-huan
(College of Communications Engineering, PLA University of Science and Technology, Nanjing Jiangsu 210007, China)
Aiming at the limited hardware storage resources in the satellite-borne IP switch, a queue manager suitable for shared memory switch structure and with less occupation of storage resources is proposed.Through adding index, all the unicastqueues could share one pointer memory block. Based on bitmap, multicast pointer is translated into several unicasts, that is,the data stream of multicast is written into corresponding logic queue in accordance with the unicast operating mode, so as to save the storage resource. The queue manager controls the write-in and output of index pointer via the head and tail of linked-list data structure.Finally the synthesis and implementation are realized on Xilinx′s xc6vlx130t FPGA, and experiment indicates that, compared with queue manager based on pointer duplication,the proposed scheme could reduce more than 22% of the storage resource in interchanger.
satellite onborad IP switch; queen manager; multicast; FPGA
10.3969/j.issn.1002-0802.2015.10.020
2015-05-17;
2015-09-02 Received date:2015-05-17;Revised date:2015-09-02
TP393.03
A
1002-0802(2015)10-1196-06

王 晶(1989—),男,硕士研究生,主要研究方向为高性能交换机和路由器相关研究工作;
乔庐峰(1971—),男,博士,教授,主要研究方向为通信和计算机网络中关键芯片和电路技术研究;
陈庆华(1976—),男,讲师,主要研究方向为交换技术和计算机网络;
郑 振(1992—),男,硕士研究生,主要研究方向为高性能交换机和路由器相关研究工作;
李欢欢(1990—),女,硕士研究生,主要研究方向为文本相关的说话人识别。
