用文本挖掘方法发现药物的副作用
2015-03-22,
,
近年,药物安全问题日益凸显。一方面,临床上由于对药物副作用的认识不足而导致的药物治疗错误、急慢性中毒、与药物相关的发病率和病死率升高、药物的滥用与错用等问题频繁出现;另一方面,由于临床试验的长期性、复杂性,批准上市药物的副作用反馈有延迟,导致早期难以预测药物副作用,如罗非昔布1999年5月由FDA批准上市,直至2004年方因其心血管危害性召回。因此,及时发现药物副作用成为备受关注的话题。
1 用文本挖掘方法探测药物副作用的必要性、可行性
目前具有药物副作用关联知识的数据库均存在问题。如SRS(Spontaneous Reporting System)、FAERS(FDA Adverse Event Reporting System)等自发报告型数据库的数据来源不够权威,存在过度报告、数据不全、重复申报等局限性;SIDER (Side Effect Resource)数据仅涉及FDA批准的药物,数据是通过简单的模式匹配从文本中提取的,可靠性较差,而且临床试验中因素错综复杂,不能完全确定不良反应是由该药物引起的;European Medicines Agency等大型数据库涉及内容过多,无专门的药物副作用检索,使用效果不佳;还有个别数据库存在不向公众公开,不及时更新等问题。因此,用文本挖掘方法从自由文本中准确、全面探测药物副作用,以充实药物副作用数据库十分必要。
最近大量基于文本挖掘的生物医学知识发现研究成果表明[1],文本挖掘可成功地应用于基因位点、蛋白通路、疾病等生物医学实体之间的关系探测,说明用文本挖掘方法预测和补充扩展现有数据库的药物副作用数据也是可行的,而且使用文本挖掘研究药物副作用,更快捷,耗时耗资更少。但是,用文本挖掘技术从自由文本中提取药物副作用的实现并不仅仅依赖于文本挖掘传统的共现聚类分析等,还要结合复杂的自然语言处理工具。本文就当前最新生物医学文本挖掘技术在药物研究领域中的相关研究成果和主要方法进行了调查和分析,并对未来发展做出展望。
2 文本挖掘技术提取药物副作用研究的现状
笔者就PubMed/MEDLINE中用文本挖掘技术从自由文本中提取药物副作用的方法进行了调研。检索策略为(“Data Mining”[Majr] OR “Natural Language Processing”[Majr]) AND (“adverse effects”[Subheading] OR “chemically induced”[Subheading]) AND (“0001/01/01”[PDAT]:“2014/12/31”[PDAT]),检索时间为2015年6月11日,共检索到71篇相关文献。第一篇文献出现于2003年,Trick WE等报告了首次将自然语言处理技术用于从中央静脉导管插入术后病历报告中识别副作用[2]。至今,从自由文本中自动提取药物副作用信息的相关研究尚处于发展阶段。从图1的拟合曲线看,文献数量随时间推移几乎呈指数趋势上升,但尚未达到峰值,可见该领域仍具有广大的研究空间。
以下从挖掘流程、挖掘/提取方法、结果评价和现有工具软件4方面归纳总结用文本挖掘技术提取药物副作用的研究现状。
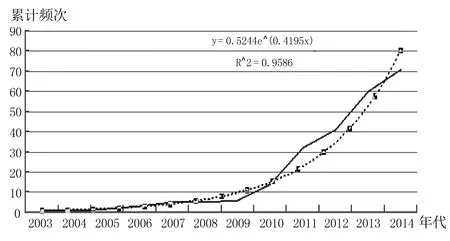
图1 文本挖掘技术探测药物副作用的文献年代分布
2.1 文本挖掘流程
用文本挖掘技术从自由文本中提取药物副作用一般包括识别命名实体(Named Entity Recognization,NER)和探测药物—疾病关系(Chemical Disease Relation,CDR)2项子任务。识别命名实体是在生物医学数据中识别具有特定意义的实体,并将其归类到预定义的类别,其难度在于现阶段药物命名实体数量的爆炸性增长、药物命名实体构词形式的多样性和低规律性及药物命名规则不统一[3];探测药物—疾病关系面临的难题是选择与整合合适的方法,从而准确而全面地识别出更多的药物—疾病关系。
根据已有文献可知,用文本挖掘技术从自由文本中提取药物副作用分为数据获取、构建词典、数据清洗和处理(段落和句子或词语水平的切分)、药物副作用提取、结果评价和反馈5个环节(图2)。
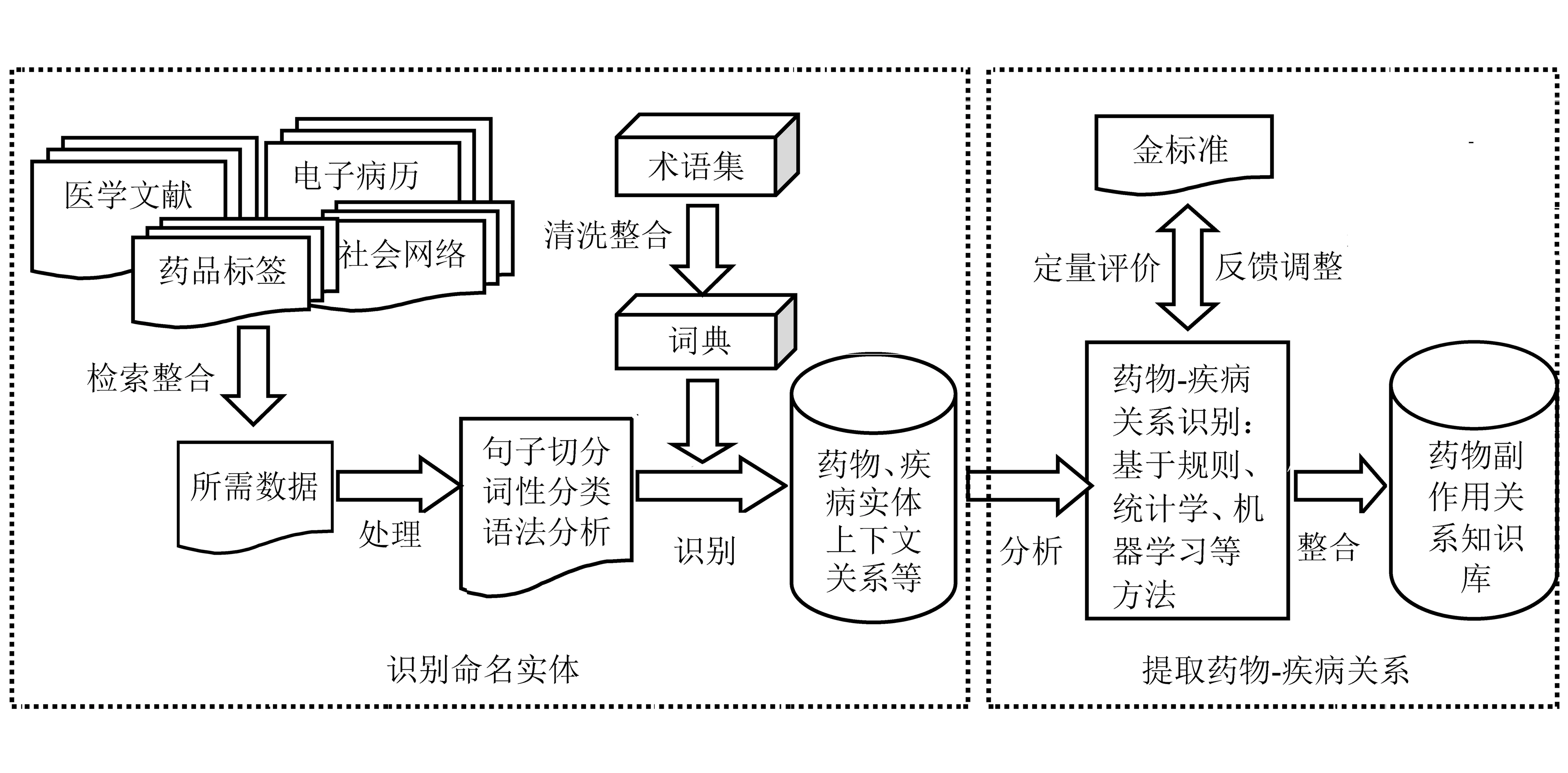
图2用文本挖掘技术从自由文本中提取药物副作用的主要流程
2.2 挖掘/提取方法
2.2.1 数据获取
可用于文本挖掘的数据资源包括病人的健康档案、电子病历(Electronic Health Record,EHR)、医疗病例报告、研究论文、专利、博客、论坛以及新闻报道等多种形式[4],具体可分为以下四大类。一是电子病历,通常包括人口统计学、病史、药物过敏、免疫状态、实验室测试结果、放射学图像、生命体征等多种信息,对分析患者的治疗效果最有价值。有研究证实可利用EHR早期预警药物副作用[5]。但获得完整的电子病历困难,而且其高度异质性和非结构化限制了它的使用。EHR的可获得性及资料完整性并不易实现。二是研究论文,主要是MEDLINE收录的生物医学文献,数据回溯到1946年并可免费检索,同时全文获得和自然语言处理是难题。三是社会媒体,其来源广泛,可获得性强,但是存在病人表述不准、用语不规范、报告角度与专业人员不对口、虚假报告等问题,对数据清洗和处理提出挑战。四是Web 数据,如搜索记录等,存在与社交网络类似的问题。还有药物产品标签(Daily-Med Website可下载电子版药物标签)、临床试验、自发报告等可作为药物副作用提取的数据源。
2.2.2 构建词典
词典质量影响药物副作用提取结果,其价值在于通过基于字符串匹配或字符串相似等算法识别自由文本中出现的药物和疾病实体。词典通常来自多个标准术语资源,目前常用于构建词典的术语集[4-5]如表1所示。除此之外,NCBO(The National Center for Biomedical Ontology)的 BioPortal (http://bioportal.bioontology.org/)是最全面的生物医学开放存储库,整合汇集了441种生物医学本体资源(包括以下大部分术语集),可提供Web浏览和检索。
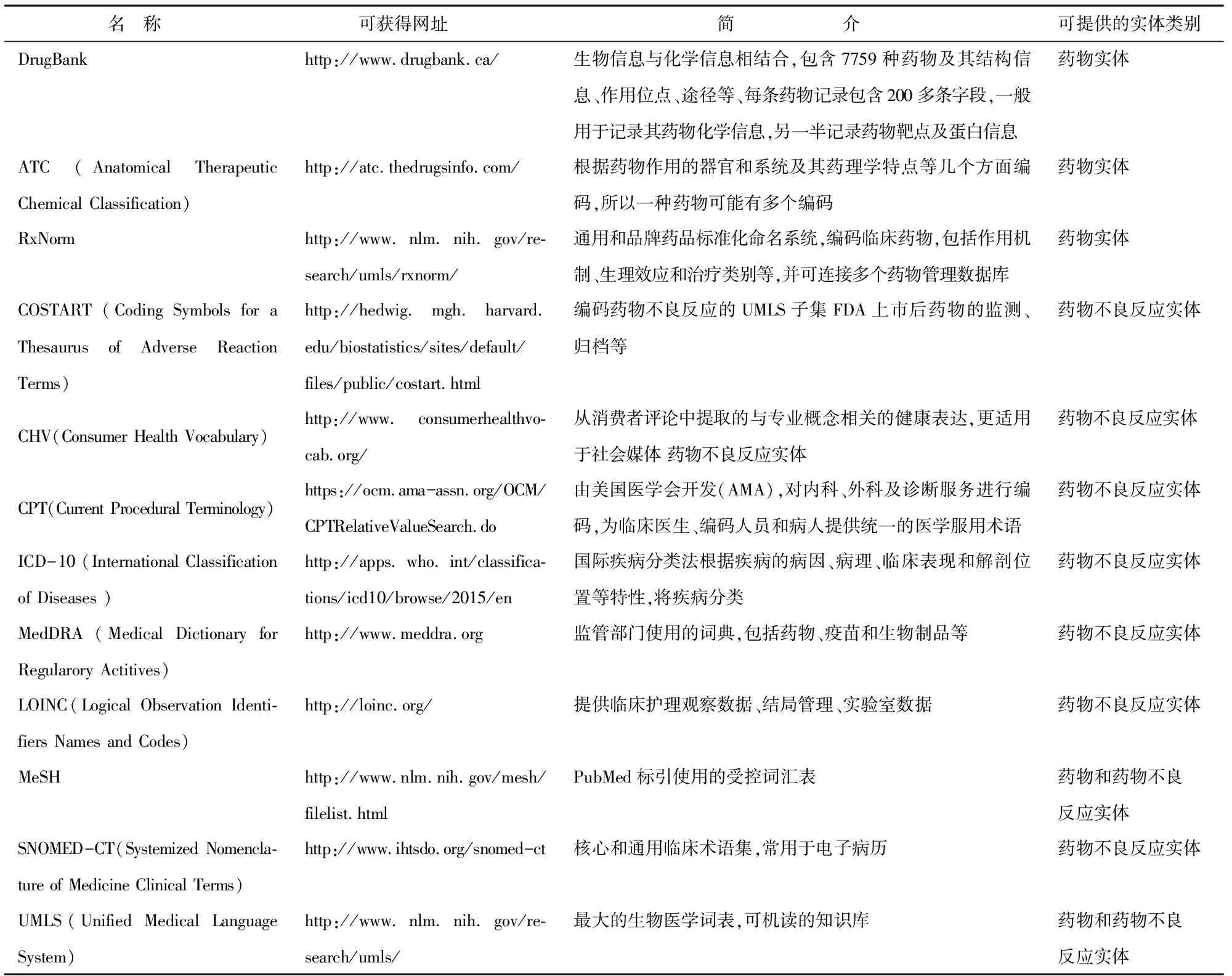
表1 常用术语集简介
2.2.3 数据清洗及标准化处理
数据清洗和标准化处理通常是借助一定的软件工具和计算机语言实现,涉及到句子切分、标准化、词性分类、词形还原及词干化、上下文消歧等工作,目的是使词典能够更为准确地匹配出相应的药物和疾病实体。常用软件工具有Stanford Parser和Link Grammar Parser。词形还原和词性标准及词干化的工具有Stanford CoreNLP,NLTK(python包),Specialist NLP Tools,Tree Tagger,European Languages Lemmatiser,CST's Lemmatiser,WMTrans Lemmatiser等。
Stanford Parser是斯坦福大学开发的自然语言处理软件,主要基于优化的概率,运用上下文无关文法和词汇化依存句法分析方法,生成句法结构树以及句子中各成分之间的依存关系[6]。Link Grammar Parser依据语法和形态规则对句子进行分析,并输出其句法结构,它包含一组链接字对的标签集合以及结构树,也可以生成Stanford风格的句子的依存结构。近期研究表明,Specialist NLP Tools对于词形还原和词干化的效果较好,准确率较高[7]。
2.2.4 实体识别方法和关系抽取算法
2.2.4.1 实体识别方法
从清洗后的数据中识别命名实体的常用方法包括基于规则、基于词典和基于机器学习的方法,在实际使用中通常会将几种方法结合,以获得更好的识别效果。
基于规则的方法,即依据特定规则识别命名实体,这些规则描述了自由文本中使用的语法、句法、词汇、形态以及书写的特点长期形成的模式。基于规则的命名实体识别系统通常依赖于正则表达式组合和由领域专家设计的规则。因为对专家知识的依赖,这种命名实体识别系统缺乏可扩展性和适应性。徐博等采用基于上下文模板的方法,从PubMed中构建的丰富的药物词典,不仅可识别出Drugbank中已有药名,甚至还能识别该库中没有的药物[8]。Tikk D等使用基于规则的方法和条件随机场方法进行了药物提取[9]。
基于词典的方法,依赖于现有的字典识别自由文本中的命名实体,通常是基于字符串匹配或字符串相似的算法。其性能取决于底层术语资源的全面性及算法性能。何林娜等人综合运用基于词典的方法和条件随机场方法,利用PubMed信息构建了药物词典,并利用特征耦合泛化等方法对词典进行去噪,获得了较好的F值[10]。
基于机器学习的方法,适用于不同的学习算法训练模式,但它需要人工注释语料库。机器学习模型的性能取决于文本特征的辨别力以及算法[11]。条件随机场(CRF)是最常用的技术,其识别生物医学实体效果较好[12]。
2.2.4.2 药物及其副作用关系抽取方法
从自由文本中识别出药物实体和疾病实体之后,提取药物及其副作用的基本方法可以分为基于规则、基于统计学和基于机器学习的方法。
基于规则/模式的方法通常是利用生物学实体的一般知识并结合语言结构寻找文本中明确陈述的关系,如“A effect B”等。更为复杂的方法是结合语义知识和词性分类来解释,还涉及到停止词去除、否定词探测、词义消歧、时间推理等利用人工辅助规则。Rong Xu等利用Stanford Parser生成语法树,从中提取出语法模式,并利用该模式识别出更多包含药物副作用的句子[13]。
基于机器学习的方法,借鉴了词性分类、语法切分、术语频次等方法及语法的上下文知识,通常效果较好,其局限性依然是需要大量的人工注释。机器学习常用算法有支持向量机(SVM)、贝叶斯模型、隐马尔科夫模型(HMM)、条件随机场(CRFs)和最大熵[12],实际应用中也常与标准化最小二乘法分类、特征向量提取、logistic回归、十迭交叉验证等算法结合以获得更好的效果。Yang等[14]比较了不同的机器学习算法,综合运用朴素贝叶斯、决策树和支持向量机方法,从致编者的信中提取不良药物反应。Christian M Rochefort等[15]运用logistic回归和AUC曲线等方法实现了医院流行的3种不良事件的自动检测。
基于统计学的方法,可以是基于共同出现的频次,即通过共现频次排序消除薄弱关联;也可结合列联表和相似性系数,通过ROC曲线确定阈值进行评价;还可以进行聚类分析和网络分析。在自发报告系统中探测药物不良反应,主要是利用失衡分析方法(Disproportionality Analysis,DPA)。通过某药物与其可疑的不良反应之间的共现次数来预测二者的关联[16]。
2.2.5 结果评价和反馈
为了更好地评价药物副作用提取系统或者提取结果的优劣,需要确定指标对结果进行评价。首先,需找到可作为评价金标准的数据集,即经评判、公认的正确提取的药物—副作用关系对的集合。目前研究者通常从国际性相关比赛公布的训练集或语料库中寻找。如EU-ADR (Exploring and Understanding Adverse Drug Reactions)、 Biocreative Challenge,i2b2 NLP Challenge,ADE-EXT Corpus等比赛发布了一些利用计算机技术结合文本挖掘技术从各种数据源(病历、文献等)中自动提取药物副作用的任务,并提供了手工标注的金标准和相对公平的评价标准,供科研人员使用。
常用的评价指标主要有F值,受试者特征曲线ROC(Receiver Operating Characteristic,ROC)和曲线下面积(Area Under Curve,AUC)。
F值是通过准确率(Precision)和召回率(Recall)来综合评价提取结果,其计算公式为:F=2×Precision×Recall/(Precision+Recall)。其中,准确率是指提取出来的正确的(真实的)药物-副作用对占提取出来的所有的药物—副作用对的百分比,召回率(又称查全率)是指提取出来的正确的(真实的)药物—副作用对占所有的应提取出来的药物—副作用对的百分比。F值越高(越接近于1)表示效果越好,目前运用较广。
ROC和AUC是考量评价分类器的指标。在ROC 空间中,横坐标对应于FPR(假阳性率,即负类被错误判断为正类的百分比),纵坐标是TPR(真阳性率,即正类被正确地判断为正类的百分比)。对于二分类问题,通过设定一个阈值,将实例分类到正类或者负类(如大于阈值划分为正类)。那么变化阈值并根据不同的阈值进行分类,根据分类结果可计算得到ROC空间中相应的点,连接这些点就形成ROC曲线。ROC 曲线经过(0,0)和(1,1),(0,0)和(1,1)连线形成的ROC 可看作一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。ROC 可直观表示分类器的表现,而AUC可量化标志分类器的好坏。通常,AUC的值介于0.5-1.0之间,AUC值越大越好。
经评价后的结果可用于反馈、调整药物副作用提取方法,直到达到较满意的效果为止。
2.3 现有挖掘工具分析
目前,网络上有很多可用的命名实体识别工具[6],为研究者提供了便利,但功能均不完善,或者只针对某种数据类型,使用时需结合计算机及数据库知识进行拓展(表2)。

表2 现有命名实体识别相关工具
除了表2中的命名实体识别相关工具,还有整合工具Pubtator,它是一个基于Web的生物医学实体关系的提取系统,不仅可从生物医学文献数据库(MEDLINE)中提取生物实体(主要是基因、疾病、化学物质),还能将他们之间的关系提取出来。该系统与PubMed连接,可以直接在该网站检索,每天实时更新标注记录。当然,该系统目前的控测仅限于PubMed摘要部分,未来期待通过更精准的文本挖掘算法,实现对全文内实体的定位与关系的探测[17]。
3 结论
综上所述,利用文本挖掘技术发现药物及其副作用研究还有一些问题亟待解决,未来仍有较大发展空间。首先,该领域需要大量研究数据,包括研究数据的选择、词典的选择和训练集测试集的选择等。选择数据源时考虑到数据结构的异质性和数据的质量、可靠度、完整性和可获得性,研究人员应结合课题和实际情况收集尽量完善、真实、结构化的数据,为数据的清洗和处理做准备。其次,文本挖掘算法、偏倚和混杂因素都有可能影响算法的性能和提取效果,而计算机相关研究人员可能更注重于算法的改良,文本挖掘研究人员似乎更青睐于研究方法的创新,二者融合是该研究发展的必然趋势。只有融会贯通才能提供更准确、更有借鉴意义的药物预警信息。再次,现阶段研究人员定制的方法和算法多半是针对某一特定数据源、数据库和语料库的,研究算法和方法的通用性和可移植性不高,这是未来发展应当关注并解决的问题。最后,通过文本挖掘方法检测到的药物不良反应信号可作为警告信息,其确认仍然应该通过适当的临床试验评估获得支持。
