一种基于词序的社会情感演变分析模型*
2015-03-19刘义红祝恒书
刘义红,朱 琛,祝恒书
(1.淮南师范学院计算机学院,安徽 淮南232001;2.中国科学技术大学计算机科学与技术学院,安徽 合肥230027;3.百度研究院大数据实验室,北京100085)
1 引言
在信息高速发展的今天,网络已成为人们获取信息的重要途径并正在改变着人们的生活行为方式。特别是基于Web 2.0的互联网技术更是提高了网络终端用户的个性化程度,允许人们在网络上进行各种各样的社会互动,表达自己的情感。例如,新浪、人民网、雅虎等一些在线社会新闻网站,允许人们在阅读一篇新闻后,通过标注情感标签来表达个人的社会情感(如有趣、感动、愤怒等),这种人工标注的情感标签显然可以精确地反映读者对新闻的态度。另一方面,对含有社会情感的文本词序进行分析和研究,能够进一步提高情感分析的准确率,更好地挖掘出人们的社会情感演变趋势,进而可以辅助情感预测、异常诊断以及文本分类等等,为决策者提供服务。近年来基于社会情感的数据挖掘,以及如何提高其准确率成为文本挖掘应用研究的热点[2~13]。
本文提出一种基于词序的社会情感演变分析模型BTMESE(Bigram Topic Model for analyzing the Evolution of Social Emotion)。模型试图通过引入新闻文档中词与词之间的前后关联性,将时间、文本、情感三种信息结合起来进行综合分析,探讨它们之间的内在联系,追踪社会情感演变趋势,以期进一步提高情感分析的准确率。最后,我们在真实世界的数据集上对模型进行了检验,结果表明该模型简单有效,能够较好地进行社会情感分析。
本文第2节概要介绍与本研究内容相关的工作;第3节详细介绍一种基于词序的社会情感演变分析模型;第4节给出该方法的实验结果及分析;最后进行总结并对下一步工作进行展望。
2 相关工作
社会情感挖掘,简单而言,就是对带有情感色彩的主观性文本进行分析、处理、归纳和推理,又称情感分析。目前,研究者主要聚焦在情感信息特征抽取、情感分类和情感信息检索与归纳上[1]。情感信息特征抽取,一般在词、句子、段落或篇章级层面进行,旨在抽取情感文本中有价值的情感信息,它是情感分析的基础任务[2]。情感分类,则是利用情感信息特征抽取的结果,将情感文本单元分为若干类别(如喜、怒、哀、乐等),供用户查看。情感信息检索与归纳,则是情感信息特征抽取和分类后呈现的结果应用,它是情感分析技术与用户交互的集中体现。其中,情感信息检索是为用户检索出包含情感信息且主题又相关的文档;而情感信息归纳是针对大量主题相关的情感文档,自动分析和归纳整理出情感分析结果,供用户参考。本文主要探讨情感分析中的分类方法。
早期的情感分类研究,主要是将情感形式化为分类任务,把整个文档看成正面或负面,或评级得分,然后采用机器学习的方法进行分类[3]。例如,文献[4]利用分类算法从股票市场意见留言板上提取情感,用于决定是否购买或出售股票。文献[5]利用朴素贝叶斯、最大熵、支持向量机(SVM)等方法对电影评论进行分类。然而,随着研究的深入,研究者又提出了一些全新的跨领域的情感分类算法。文献[6]设计了一种基于Web信息的标题情感分类算法。文献[7]设计了一个MoodLens系统,将新浪微博上的95个表情符号映射分类到四类情感中。文献[8]设计了一个ESLAM 模型,对Tiwtter信息进行情感分析,它的基本思想是用手动标记的数据训练一个语言模型,然后利用平滑技术去处理噪声情感数据。文献[9]提出了一个多标签情感分类系统。该系统由文本分割、特征提取和多标签分类三个部分组成,用于微博情感分类。这些工作大多数是直接从文档(或词语)中研究感情。
另一方面,主题模型作为一种有效的文本分析工具,在文本和离散型数据分析中被广泛运用。一些研究者认为文档是由一些隐含的主题构成的,这些主题决定着构成文档的单词。因此,他们开始采用主题模型来分析社会情感,取得了很好的效果。文献[10]提出一个主题-情感混合模型,在博客上进行情感分析。文献[11]提出一个基于LDA(Latent Dirichlet Allocation)扩展的情感主题模型,从文档中获取主题和情感关联。然而,这些方法均需要满足一个基本假设,就是文本中的词是相互独立的,忽略了词序相关信息,并且很少考虑时间对主题的影响。因此,人们提出了一些改进方法,融入词序和时间等信息。例如,文献[12]提出了一种基于LDA 的N-gram 语言模型,用来捕捉词与词之间的依赖关系。文献[13]利用Topical N-gram 模型,依据新闻主题背景下词与词之间的关联性,提出了一种新闻线索提取方法。文献[14]提出了一种基于主题相关类的N-gram 语言模型,揭示潜在的主题信息,从中提取词与词之间的关系。文献[15]提出一个主题时间ToT(Topics over Time)模型,每个主题在时间上是一个连续概率分布。文献[16]提出一个微博-主题时间MB-ToT(MicroBlog-Topics over Time)模型,在微博上进行综合主题分析。文献[17]提出一个情感时间主题模型eToT(emotion ToT),分析时间情感主题之间的关联性。
综上所述,目前基于社会情感挖掘的理论方法及工程应用很多,但很少有人将词序信息引入到文本情感分析和情感演变趋势的挖掘之中,忽略了文本中词序、时间所隐含的重要信息。
3 BTMESE建模
3.1 定义
现在许多在线新闻允许不同用户阅读后,通过增加评论或注释来表达自己的情感,可以进一步理解为,每一篇新闻(文档)是由一个时间戳、一组词和一组情感组成。因此,我们采用概率图模型来分析在线新闻的社会情感。为了方便描述图模型,我们在这里定义下列术语和符号:
定义1 语料库W,形式化定义为:
W={(t1,W1,E1),…,
(td,Wd,Ed),…,(tD,WD,ED)}
其中,三元组(td,Wd,Ed)表示第d个文档是由时间戳td、词向量Wd和情感集合Ed三部分构成,D表示文档总数。
定义2 文档d中词向量Wd,形式化定义为:
Wd=(wd,1,wd,2,…,wd,i,…,wd,Nd)
其中,wd,i表示文档d中第i个词项,Nd表示文档d中词项总数。
定义3 文档d中社会情感Ed,形式化定义为:
Ed={ed,1,ed,2,…,ed,i,…,ed,E}
其中,ed,i表示文档d中第i个情感,E表示文档d中情感类别数。
定义4 时间戳td是将文档d的原始时间数据按照给定的时间粒度(如,月份、年等)进行离散化得到的一个时间片。
本文中使用的符号如表1所述。

Table 1 Notations used in this paper表1 文中使用的符号说明
3.2 BTMESE模型
我们提出的基于词序的社会情感演变分析模型(BTMESE)如图1 所示,通过文档中隐含的主题可以有效地分析出时间、文档和情感三者之间的潜在联系。图1中,阴影节点表示观察数据,空白节点表示隐含变量,箭头表示依赖关系。BTMESE中的每个主题在词、情感和时间上分别对应着一个隐含的概率分布,而如何选择这些分布则依据实际问题而定。这里,一篇文档中所有的词共享相同的情感分布和同一时间戳,为简化参数估计过程,假设主题在情感上服从Dirichlet分布,在时间上服从Beta分布(注意,我们需要将时间戳归一化到0~1)。BTMESE的参数化设定如下:


Figure 1 Model of BTMESE图1 BTMESE图模型
BTMESE 模型生成一篇文档的过程描述如下:
(1)根据先验Dirichlet(α) 分布得到文档的一个主题多项式分布θd。
(2)对于文档d中第个i(i∈Nd)单词:
①从Mult(θd)中随机选择一个主题zd,i;
②若i≠1,从中产生一个单词wd,i;否则,从中产生一个单词wd,i。
根据上述生成过程,整个语料库的完全数据,即随机变量主题z、单词w、情感e和时间戳t的联合概率分布表示为:
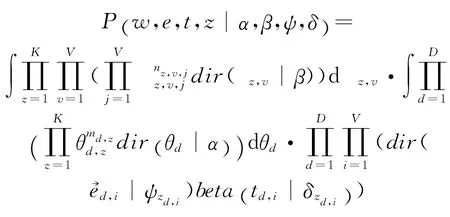
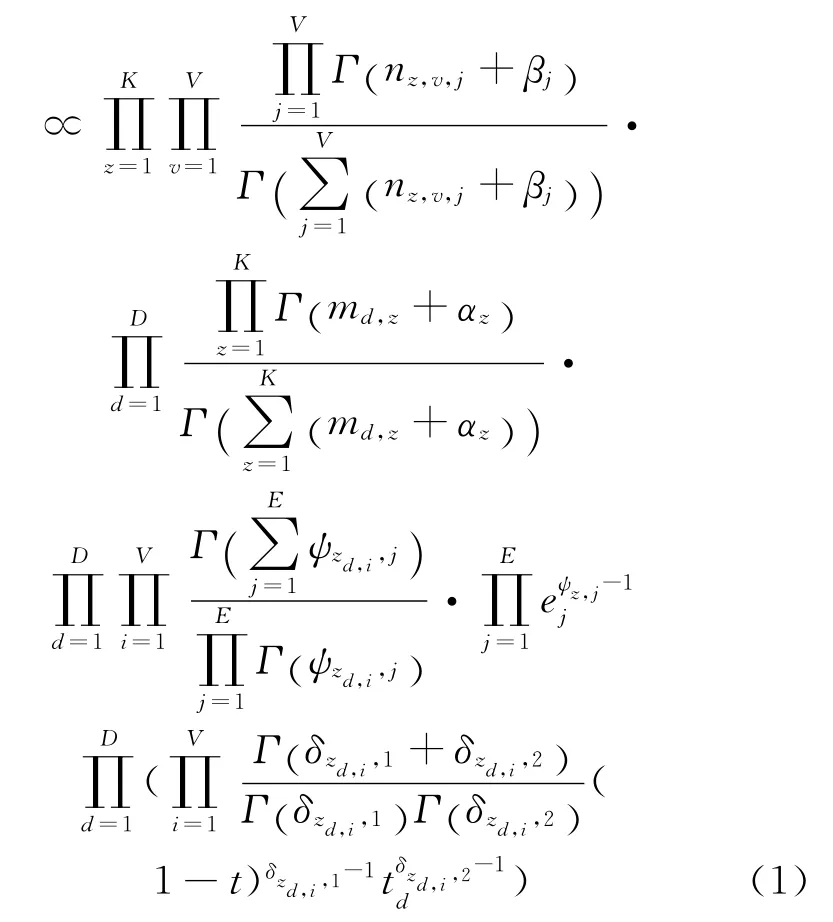
其中,nz,v,j表示主题z上单词v后面出现单词j的频次,md,z表示文档d上出现主题z的频次,α、β为超参数。Γ()为Gamma函数。
3.3 参数估计
BTMESE参数估计,我们采用基于Gibbs采样的近似推理方法[18,19]。在Gibbs采样过程中,需要计算每个词wd,i的条件后验概率分布,即Gibbs采样公式。其推理过程:

其 中*﹁d,i表 示 除 单 词wd,i外 其 它 单 词 对 应 的 随机变量。其它符号含义同式(1)或表1。
在每次Gibbs迭代采样后,我们更新参数θ、ψ、δ:


3.4 BTMESE应用
BTMESE有许多潜在的应用,如情感预测、时间预测等,还可以分析主题在时间、情感上的演变趋势。下面以情感、时间预测为例,介绍BTMESE的应用。
情感预测是情感分析中的分类问题,具体地说,就是给出文档(如,一篇新闻),预测出具有最高生成概率的情感e*,即:

而

其中,P(w|z) 、P(e|z) 、P(z)均可通过 模型学习得到。
更进一步,在给出文档d和时间戳t下,可预测出具有最高生成概率的情感e*,即:
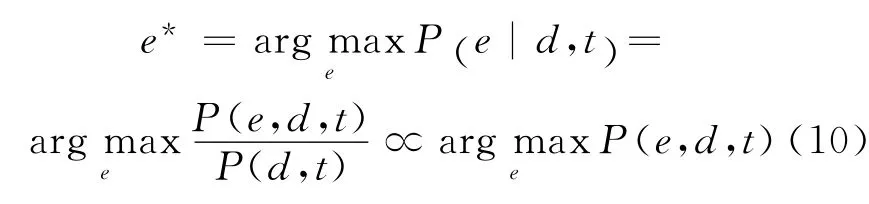
其中,P(e,d,t)可由式(1)计算得到。
类似地,时间预测问题可以描述为,给出文档d(如,一篇新闻),预测出具有最高生成概率的时间戳t,即:
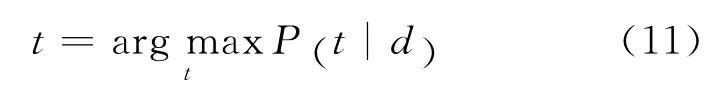
而
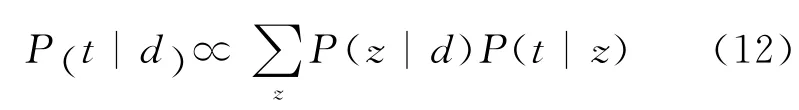
其中,P(t|z)、P(z|d)很容易通过模型学习得到。
此外,本模型所揭示的情感演变信息可以对诸如新闻推荐、文本信息异常诊断提供一定的帮助。
4 实验结果及分析
4.1 实验数据
实验数据来源中国科学技术大学语义计算与数据挖掘实验室,数据采集于新浪门户网站社会新闻栏目上的社会新闻和用户阅读该新闻标注的社会情感,时间从2012年8月21日至2013年11月11日。经过预处理后,数据集由7 504 篇新闻和4 844 594个情感注释组成,情感注释有高兴、感动、愤怒、难过、新奇、震惊等6个类别,采用XML数据格式存储[20]。为了保证模型的性能,实验时我们去除了数据中所有无意义的停止词和频次低于5的词。
图2给出了数据集的一些简单统计特性,图2a展示了不同类别上的情感数量分布,从图中我们可以发现“愤怒”的情感最多,说明多数人喜欢用愤怒来反映自己的情感。图2b展示了不同时间片的新闻上社会情感的分布,可以观察到社会情感随时间的演变过程,反映社会情感容易受到不同时间段的新闻事件影响。具体来说,就是数据集中的时间、文本、情感之间存在潜在关联。
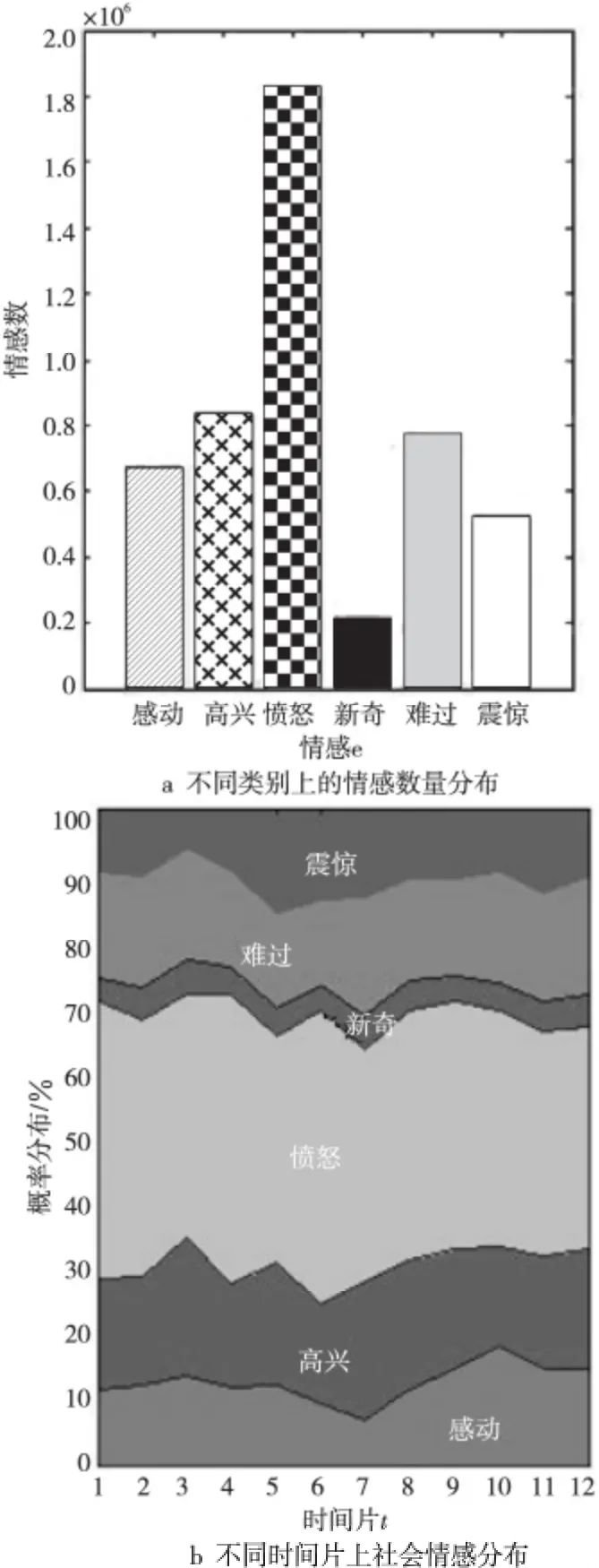
Figure 2 Simple statistical properties of the dataset图2 数据集的一些简单统计特性
4.2 BTMESE模型的训练效果
实验中,BTMESE 模型需要预先给定一个数值K来表示新闻主题的个数,这里,我们利用经典方法Perplexity[21,22]来估计K值,将主题数K设置为50。依据文献[23],将模型超参数α、β分别设置为50/K、0.01。经过500次迭代,Gibbs采样收敛,得到实验结果。
实验结果展示了基于词序的时间、情感、文本和新闻主题之间的隐含关系。为简单说明问题,我们只随机选择四个隐含主题来分析实验效果。图3展示了四个不同新闻主题在时间上的概率分布,图4展示了四个不同新闻主题上具有最高生成概率的情感分布。从结果中我们发现,topic#2、#3有相似的概率分布,这里情感标签“愤怒”的概率最大,但是,它们又出现在不同的时间片上。这表明,时间对情感能产生重要影响,进而可分析出社会情感的演变过程。
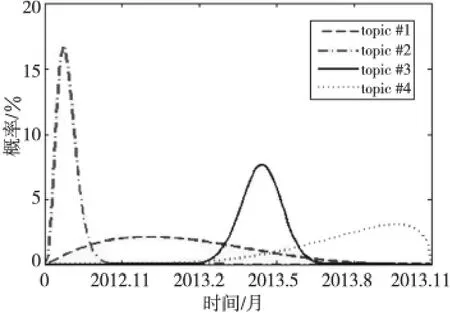
Figure 3 Distributions of four different news topics with respect to different time spans图3 四个不同主题在时间上的概率分布
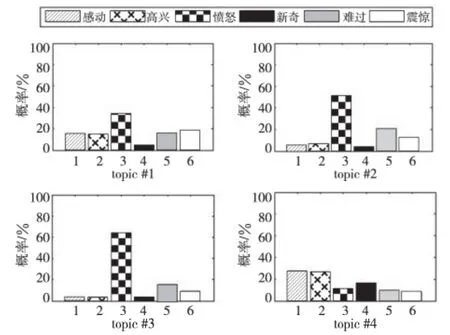
Figure 4 Distributions of emotions in four different news topics图4 四个不同主题上的情感概率分布
表2给出了四个不同新闻主题上的排序较高的前10个关联词。我们通过这些关联词可以发现社会事件。例如,Topic#1 表明人们比较关注教育事件,Topic#2、#3 表明发生了重大交通事故和征地拆迁引发社会关注的突发事件,Topic#4表明人们比较关注家庭情感事件。同时,我们还能通过观察这些主题上表现出来的情感分布和发生的时间分布,进一步分析出新闻事件下的社会情感变化。

Table 2 Top 10words in four different topics表2 四个不同主题上前10个排序词
4.3 BTMESE模型的有效性分析
在这部分,我们通过情感预测性能分析来评价BTMESE模型的有效性。检验方法是,首先选择两 个 较 先 进 的eToT[17]、ETM(Emotion-Topic Model)[15]方法和一个最大熵模型MEM(Maximum Entropy Model)方法作为实验的基准,然后通过评价准则验证BTMESE 模型的有效性。情感预测可以看作一个多分类问题,利用上述模型计算给定新闻文档的每个情感的后验概率P(e|d) ,而每个模型在计算P(e|d) 后得到一组情感排序序列。因此,我们使用流行的评价准则NDCG(Normalized Discounted Cumulative Gain)来评价每个方法的性能。NDCG指标表示一个方法返回的排序序列是否接近真实值,其值越大表示排序性能越好。这里,

而

式(13)中IDCG@N表示最佳排序结果的DCG@N取值。式(14)表示N个情感排序结果的得分,reli表示第i个情感得分,我们设reli取值为:第i个情感总数Ei/所有情感总数E。
实验中,我们采用五折交叉验证的方法,将数据随机分成五份,其中一份作为测试数据,其余四份作为训练数据,最后将五次实验平均得到最终结果。表3展示了不同模型的NDCG@N性能,结果表明,我们提出了方法在NDCG评价指标上相对于其他基准方法的性能提升显著。

Table 3 NDCG@Nperformance of different models表3 不同模型的NDCG@N 性能
5 结束语
本文研究的目的是通过分析新闻文档中的词序关系,追踪社会情感演变趋势,以期有效地解决网络在线新闻的社会情感分析问题,进一步提高情感分析的准确率,为在线服务提供帮助。研究提出了一种基于词序的社会情感演变分析模型BTMESE,内容包括生成模型的构建、参数估计、应用领域和实验性能评价等四个方面。最后,通过在真实世界的数据集上实验,结果证明该模型简单有效,能够较好地进行社会情感分析,准确率较高。但是,文中还有一些地方需要进一步完善,如主题的动态变化、主题的相关性等问题,这将是未来工作的研究方向。
[1] Zhao Yan-yan,Qin Bing,Liu Ting.Sentiment analysis[J].Journal of Software,2010,21(8):1834-1848.(in Chinese)
[2] Xu Lin-hong,Lin Hong-fei,Zhao Jing.Construction and analysis of emotional corpus[J].Journal of Chinese Information Processing,2008,22(1):116-122.(in Chinese)
[3] Cambria E,Schuller B,Liu Bing,et al.Knowledge-based approaches to concept-level sentiment analysis[J].IEEE Intelligent Systems,2013a,28(2):12-14.
[4] Das S,Chen Mike.Yahoo!for amazon:extracting market sentiment from stock message boards[C]∥Proc of the 8th Asia Pacific Finance Association Annual Conference,2001:1.
[5] Pang Bo,Lee Lilian,Vaithyanathan S,et al.Sentiment classification using machine learning techniques[C]∥Proc of the ACL-02Conference on Empirical Methods in Natural Language Processing,2002:79-86.
[6] Kozareva Z,Navarro B,Vazquez S,et al.Ua-zbsa:A headline emotion classification through web information[C]∥Proc of the 4th International Workshop on Semantic Evaluations,2007:334-337.
[7] Zhao Ji-chang,Dong Li,Wu Jun-jie,et al.Moodlens:An emoticon-based sentiment analysis system for chinese tweets[C]∥Proc of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2012:1528-1531.
[8] Liu Kun-lin,Li Wu-jun,Guo Min-yi.Emoticon smoothed language models for twitter sentiment analysis[C]∥Proc of 26th AAAI Conference on Artificial Intelligence and the 24th Innovative Applications of Artificial Intelligence Conference,2012:1678-1684.
[9] Liu Su-hua,Chen Jiun-hung.A multi-label classification based approach for sentiment classification[J].Expert Systems with Applications,2015,42(3):1083-1093.
[10] Mei Qiao-zhu,Ling Xu,Wondra M,et al.Topic sentiment mixture:Modeling facets and opinions in weblogs[C]∥Proc of the 16th International Conference on World Wide Web,2007:171-180.
[11] Lin Cheng-hua,He Yu-lan.Joint sentiment/topic model for sentiment analysis[C]∥Proc of the 18th ACM Conference on Information and Knowledge Management,2009:375-384.
[12] Wang Xue-rui,McCallum A.Topics over time:A non-markov continuous-time model of topical trends[C]∥Proc of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2006:424-433.
[13] Liu Shao-peng,Yin Jian,Ouyang Jia,et al.MB-ToT:An effective model for topic mining in microblogs[J].Applied Mathematics &Information Sciences,2014,8(1):299-308.
[14] Naptali W,Tsuchiya M,Nakagawa S.Topic-dependentclass-based n-gram language model[J].IEEE Transactions on Audio Speech and Language Processing,2012,20(5):1513-1525.
[15] Bao Sheng-hua,Xu Sheng-liang,Zhang Li,et al.Mining social emotions from affective text[J].IEEE Transactions on Knowledge and Data Engineering,2012,24(9):1658-1670.
[16] Lau Raymond Y K,Xia Yun-qing,Ye Yun-ming.A probabilistic generative model for mining cybercriminal networks from online social media[J].IEEE Computational Intelligence Magazine,2014,9(1):31-43.
[17] Zhu Chen,Zhu Heng-shu,Ge Yong.Tracking the evolution of social emotions:A time-aware topic modeling perspective[C]∥Proc of IEEE International Conference on Data Mining(ICDM),2014:697-706.
[18] Lin Xiao-jun,Li Dan,Wu Xi-hong.A joint topical N-gram language model based on LDA[C]∥Proc of 2010the 2nd International Workshop on Intelligent Systems and Applications(ISA),2010:381-384.
[19] Yan Ze-hua,Li Fang.News thread extraction based on topical N-gram model with a background distribution[C]∥Proc of the 18th International Conference on Neural Information,2011:416-24.
[20] http://emotiondata.sinaapp.com/.
[21] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3(5):993-1022.
[22] Azzopardi L,Girolami M,VanRisjbergen K.Investigating the relationship between language model perplexity and IR precision-recall measures[C]∥Proc of the 26th Annual International ACM SIGIR Conferenceon Researchand Development in Informaion Retrieval,2003:369-370.
[23] Heinrich G.Paramter estimaion for text analysis[R].Saxony:University of Leipzig,2009.
附中文参考文献:
[1] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[2] 徐琳宏,林鸿飞,赵晶.情感语料库的构建和分析[J].中文信息学报,2008,22(1):116-122.
