一种基于动态网页解析的微博数据抓取方法*
2015-03-14钟明翔唐晋韬谢松县
钟明翔 唐晋韬 谢松县 王 挺
(国防科学技术大学计算机学院 长沙 410073)
一种基于动态网页解析的微博数据抓取方法*
钟明翔 唐晋韬 谢松县 王 挺
(国防科学技术大学计算机学院 长沙 410073)
微博是一种新型信息传播媒介,产生的海量数据吸引研究人员关注并开展相关研究。微博数据获取是后续分析研究的基础和起点。以新浪微博平台为研究对象,提出了基于动态网页解析技术的微博数据多线程抓取方法。方法利用浏览器内核解析微博页面动态数据,通过模拟登陆,依据社交网站网页链接特点确定页面爬取策略,使用页面解析技术定制页面数据抽取模板,实现以用户为中心的微博数据获取。抓取结果表明,方法能对微博用户数据进行全面高效抓取,为后续数据分析和处理提供数据支持。
新浪微博; 数据挖掘; 动态网页; 爬虫
Class Number
1 引言
近年来,社交媒体在互联网上迅速发展和普及。在线社交网站、博客、维基、微博等社交网络应用在普通大众中不断普及和深入。微博以其平台的开放性、内容发布的低门槛特性发展为重要的社会化媒体。Twitter自2006年创建以来,用户数量一直保持高速增长势头。2009年用户增长率高达2565%,是社交网站Facebook和LinkedIn用户增长率总和的10倍[1]。新浪自2009年8月推出微博产品以来,迅速成长为中国微博平台代表。截止2014年底,微博用户数量超5.3亿,月活跃用户数量达到1.76亿,目前是中国最具影响力和关注度的微博平台。
网民通过微博平台发布和获取信息、表达自我,形成社会舆论。以信息传播为载体维系网络社会关系。微博已经逐渐对社会发展和国家安全产生深远影响。以Facebook、Twitter为代表的社交网站,已经多次证明它们在一些社会事件中扮演着举足轻重的角色。利用微博数据进行舆情分析和潜在客户发掘,使微博数据挖掘具有重大的社会意义和巨大商业价值。
在国内,大量研究人员针对微博数据开展相关研究。HAN Ruixia[2]介绍了微博平台的基本概念和特点。新浪微博官方提供技术支持的SDK,出于商业利益和网络资源保护考虑,对普通开发者调用API获取数据进行了限制。也未对网络爬虫和搜索引擎提供静态文件。因此微博数据的全面高效获取成为制约微博研究的一个瓶颈。目前微博数据获取方法可分为四种[3]: 1) 基于微博开放平台的数据获取技术,即利用微博平台提供的API。 2) 基于网络爬虫的数据获取技术。 3) 基于数据源镜像的数据获取技术。 4) 基于网络数据流的数据获取技术。基于镜像资源的数据获取往往不是免费的,且获取需要一定的权限。基于网络数据流的获取需要硬件支持来实现网络环境下用户数据的捕获。通过网络数据流的解析和重构来获取微博数据,需要比较复杂的技术。因此对于普通的开发和研究人员而言,针对新浪微博数据的获取方式,主要有以下两种主要思路及做法: 1) 利用微博平台提供的SDK调用API获取数据; 2) 利用网络爬虫抓取网页内容,根据规则提取信息,或者二者组合应用。陈舜华等[4]提出了合理控制新浪微博API调用频次的分布式抓取技术。周立柱等[5]提出了利用聚焦爬虫抓取网页内容,并按规则提取有效信息的思路,但未涉及登陆模式,难以支持微博数据的完整获取。廉捷等[6]提出了结合新浪微博API和网络爬虫与网页解析,实现微博数据的高效获取方案。孙青云等[7]提出了基于模拟登陆,使用传统网络爬虫,从下载的网页中抽取微博和用户信息数据的方案。但没有涉及网页动态数据的获取和解析,不能完整获取用户评论和转发等重要信息。
通过对不同微博数据抓取方式进行分析,本文选择基于网页动态数据解析的爬虫方案,并实现了一个以登录用户相关的微博数据抓取系统。
2 现有微博获取方式分析
综合分析目前两种获取微博数据的方案: 1) 通过API调用能简洁高效获取便于分析的结构化数据,但在调用频次和返回结果最大数量有诸多限制。 2) 使用网络爬虫方案比较灵活,可基于模拟登陆和网页数据解析获取相关数据,但实现难度较大,且无法获取结构化的微博数据。
2.1 新浪微博API
微博开放平台(Weibo Open Platform)是利用微博平台的信息传播能力接入第三方应用,向用户提供应用和服务的开放平台。目前新浪微博开放平台提供了微博接口、关系接口、用户接口、评论接口、粉丝服务接口等26类API接口[8]。几乎包括了微博的所有功能。但对于需定制的数据请求服务,则必须在API基础上进行扩展开发。开发者要调用API首先需通过OAUTH2.0认证授权。现在新浪微博全面采用OAUTH2.0认证授权。在OAUTH2.0授权下通过调用API接口请求获取JSON格式数据文件。通过OAUTH2.0调用API接口有两种方式: 1) 直接使用参数传递。如参数名为access_token,调用方式为https://api.weibo.com/2/statuses/public_timeline.json? access_token=abcd。其中json?表示返回数据格式为JSON。JSON是一种轻量级数据交换格式。JSON文件结构简单,不使用标记内容属性的说明性标签。如:{“ID”:“1472368912”:“name”:“Jake”}。因此JSON文件不仅返回文件更小,而且计算机易于分析处理。 2) 在header里传递。如Access Token的值为abcd,调用形式为在header里添加Authorization:OAuth2 abcd。其他的接口参数正常传递即可。
出于商业利益和服务器安全考虑,新浪微博API从用户维度和IP维度,对不同授权级别开发者进行了访问频次限制。为防止用户调用API进行非法操作,新浪微博开放平台针对API的返回数据量和调用次数也进行了严格限制。且微博API技术原理是HTTP轮询(POLLING),非即时推送(realtime push)协议。调用API不能达到及时获取最新消息的效果。
2.2 网络爬虫
网络爬虫(又称网页蜘蛛,网络机器人等),是一种按照设定规则自动抓取万维网信息的程序或脚本。初期的通用爬虫是对万维网的所有网页进行无差别抓取。其目标是尽可能大的网络覆盖率。随着万维网数据形式不断丰富和网络技术的发展,为根据既定抓取目标有选择的获取信息,面向垂直搜索的聚焦爬虫应运而生[9]。垂直搜索的聚焦爬虫目的是精确地抽取网页内容,并保存为结构化数据。其重点和难点在于定制高效的网页内容分析和抽取。聚焦爬虫从当前抓取页面数据中进行分析和过滤,根据一定策略选择URL放入后续抓取队列,直到满足停止条件则终止。因此可以通过合理设置URL选择策略和页面数据抽取策略,使用网络爬虫来获取相关数据。
Ajax是一种创建快速动态网页技术。可在不重新加载整个网页情况下,通过后台与服务器进行少量数据交换,实现网页某个部分的异步更新。为减少网络传输流量,提高用户体验度,微博网站对Ajax技术应用越来越多。目前新浪微博的评论和转发信息都是由JavaScript动态生成。由于Ajax页面是由客户端浏览器执行脚本代码动态生成。因此网络爬虫仅能抓取web服务器返回的html文件,不能抓取JavaScript动态生成的信息。同时由于新浪微博的用户隐私保护策略,只有登录的用户才能对评论、转发等页面信息进行浏览。因此,使用网络爬虫必须解决网页客户端动态数据获取和模拟登陆两个问题。
3 基于网页动态数据获取的爬虫方案实现
3.1 爬虫框架下动态网页数据获取技术
在网络爬虫框架中,页面下载模块负责网页数据的下载获取。本文针对传统网络爬虫无法爬取Ajax页面内容数据的问题,对网络爬虫页面下载模块进行改造。传统网络爬虫页面下载模块直接使用http协议,接受并分析服务器响应来实现页面下载。然而针对社交网站页面javascript动态加载的网页数据,使用http协议不能取到完整页面内容。目前的主要有两种思路: 1) 分析javascript逻辑,通过爬虫在网页中提取关键数据去构造Ajax请求,最后从服务器响应中获取完整数据。但是由于javascript代码使用和编写不规范导致效果不很理想。 2) 在爬虫页面下载模块,利用Web自动测试工具模拟浏览器提取Ajax页面内容。直接获取加载完整的页面数据。目前针对这种方法已经有比较成熟的方案,能在保证速度的情况下有较好的稳定性。Selenium是一个开源Web功能测试工具[10]。通过javascript管理测试过程。其针对Java提供API可以和浏览器内核进行交互,其核心是webdriver,可以模拟用户真实操作,包括浏览网页页面,触发鼠标事件、点击链接、提交表单、输入文字等用户行为。通过对网络爬虫抓取框架的页面下载模块进行改写,控制浏览器内核与微博Web服务器交互,持续获取完整页面动态数据。即可实现模拟登陆以及获取完整的Ajax页面数据。爬虫系统框架如图1所示。其中爬虫框架模块划分不是本文重点,在此不展开阐述,详细细节请参考相关引用文献。
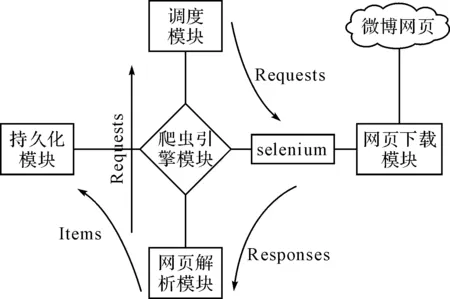
图1 网络爬虫框架
3.2 模拟登陆
使用爬虫对微博网页进行爬取之前,首先需要进行模拟登录。模拟登陆通过Java程序模拟浏览器行为实现登陆过程。模拟登陆程序通过webdriver打开登陆页面。使用findElement方法进行页面元素查找和定位。在页面元素内通过读取配置文件模拟输入用户名、密码,提交按钮完成模拟登陆流程。模拟登陆基本实现过程如下:
1) 利用webdriver打开登陆页面。
2) 使用findElement方法在登陆页面内查找账号和密码输入框元素,通过sendkey方法对该元素进行传值。如密码输入框元素查找方式为:findElement(By.xpath(("//input[@node-type='password'],之后通过sendKeys(pswd)即可完成密码输入。
3) 通过查找和点击提交按钮完成登陆流程。
程序模拟登陆成功后,通过调用浏览器内核向服务器发送数据请求来实现微博网页的获取。通过客户端保持与服务器的session会话即可继续访问微博的其它数据资源。
3.3 针对社交网站网页特征的抓取
从网络数据的拓扑特征上讲,社交网站数据属性区别于一般的普通网站。社交网站网络数据分为两大类[11]:用户信息数据和微博信息数据。用户信息数据主要字段包括:用户UID、昵称、所在城市、微博数、粉丝数、关注数、注册时间、用户认证类型等。微博信息数据主要字段包括:作者信息、微博ID、发布时间、内容、评论数、转发数等。社交网站数据存在两个维度的网络:第一个是用户关系网络。其节点是用户,边是用户之间的关注关系。第二个是信息传播网络。其节点是用户,边是针对同一主题用户之间的转发评论关系。
面对海量庞杂的微博网站数据,必须确定合适的页面抓取策略,才能实现对特定微博所有数据进行完整获取。本文针对社交网站数据的属性特征使用如下页面抓取策略:
1) 以微博用户首页设为初始页面,作为爬虫的入口。通过爬虫页面下载模块进行动态页面数据获取,从中抽取出微博用户发布的所有微博链接。
2) 将抽取出的用户微博链接放入待抽取队列。
3) 从每条微博独立页面中抓取微博数据信息(作者信息、微博ID、源微博ID、发布时间、内容、评论数、转发数、点赞数)。
4) 从微博评论页面中通过模拟浏览器行为进行点击和翻页,抓取评论信息(评论内容、评论时间、评论作者ID、评论作者名称、评论作者微博主页)。
5) 从微博转发页面中通过模拟浏览器行为进行点击和翻页,抓取转发数据(转发ID、转发源ID、转发时间)。
6) 将每一条转发信息作为一条微博,从中抽取出链接放入待抽取队列。
然后重复步骤3)至6),由此即可以获取特定微博用户发布微博的完整相关信息数据。程序通过设置最大转发层次数,来控制爬虫的抓取深度。程序抓取过程如图2所示。
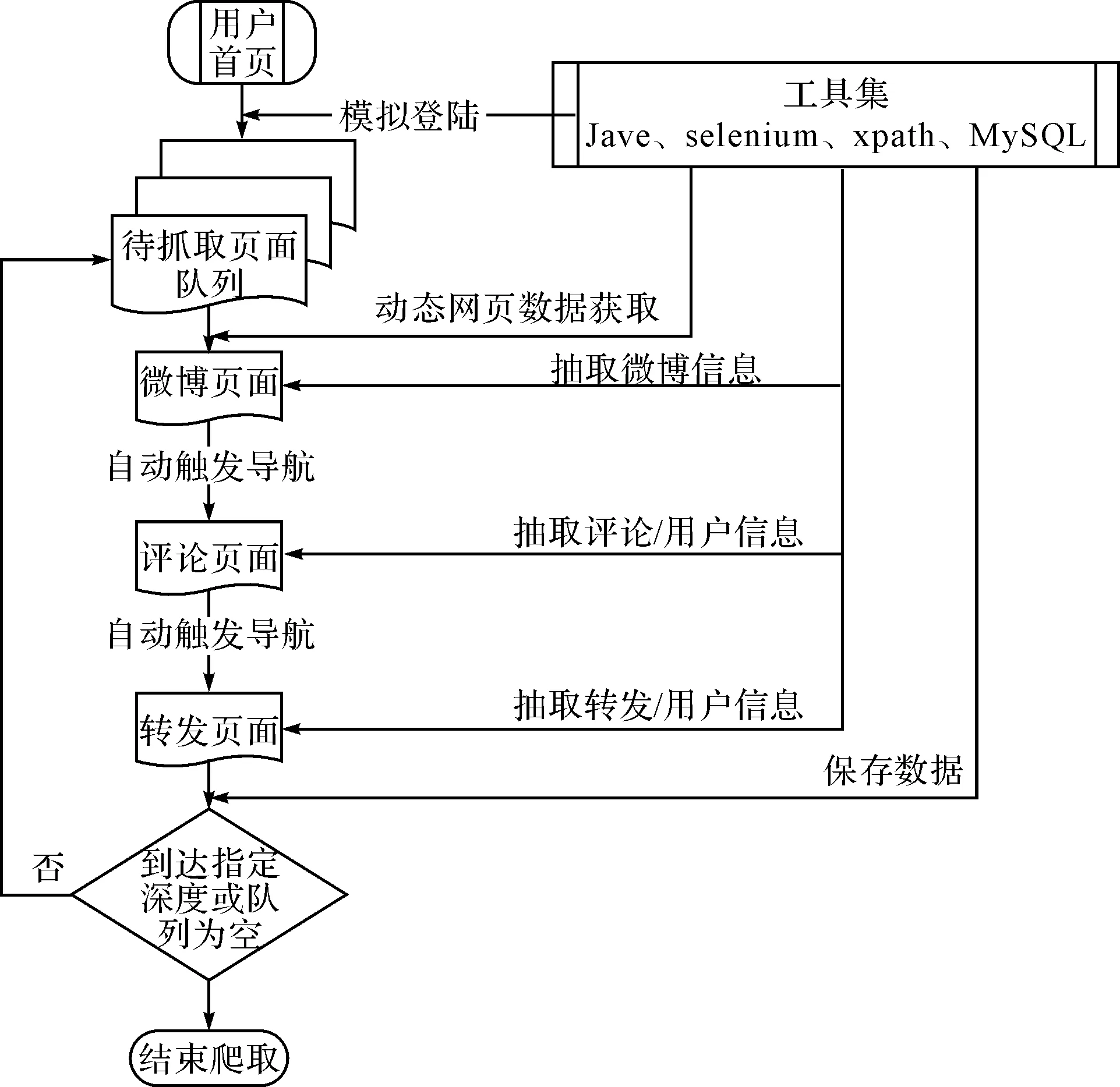
图2 网页数据爬取策略
3.4 页面解析技术
爬虫页面下载模块通过调用浏览器内核,获取微博页面完整的HTML格式文件。经过分析新浪微博页面编码,发现该平台内相同页面类型的编码规则一样。因此可以针对新浪微博页面编码规则,深度定制微博页面信息解析抽取模板,即可实现同类型微博页面数据的解析抽取。通过将不标准的HTML语言转换为DOM数结构,利用xpath和正则表达式等页面解析技术,可实现微博页面数据的高效精确获取。xpath使用路径表达式对HTML页面文件节点元素进行定位选取。正则表达式通过字符串描述、匹配符合规则的字符串。使用正则表达式可摘取字符串中需要的指定内容。把二者结合起来,通过链式抽取可以准确高效地解析出所需的微博数据。
通过分析微博数据编码规范,可针对每一种微博数据进行抽取模板定制,从而实现相关数据的高效全面抽取。如:在新浪微博用户首页中,所有微博链接信息均保存在DOM数结构属性为WB_feed WB_feed_profile的一对〈div〉节点内。通过绝对路径://[@node-type='feed_list_item_date']/@href可获取当前用户发表的所有微博链接。在独立微博页面中通过绝对路径://div[@class='WB_cardwrap WB_feed_type S_bg2']/@mid即可获取当前微博mid值。在微博评论页面中通过绝对路径://div[@node-type='replywrap']/div[@class='WB_text']/allText()可获取评论用户名及其评论内容。
4 实验分析
本文提出了基于网页动态数据获取的微博数据爬虫抓取方案。测试中选择抓取新浪微博平台军报记者微博账号内微博数据,包括微博信息数据、评论信息数据、转发信息数据和相关用户信息数据。对数据抓取效果进行统计分析,对方案爬虫性能进行验证分析并针对影响其性能的原因进行分析。
4.1 数据抓取统计分析
在本实验中对军报记者微博账号内2015年2月4日14:40至2月9日16:00的100条微博数据进行统计分析。爬虫爬取时间为2月4日15:24:54,即以该时刻的100条微博数据进行截面研究。爬虫程序共爬取了该100条微博的共计2187条评论信息、4295条转发信息和2489个用户信息。其中评论信息包括评论ID、微博ID、评论用户ID、评论用户昵称、评论内容、评论时间,共六个字段值属性。转发信息包括转发ID、源转发ID、转发时间,共三个字段值属性。转发层次深度未做设定,即抓取微博的所有转发数据。用户信息包括用户ID、用户主页、用户昵称,共三个字段值属性。用户包含评论用户和转发用户。综合统计所有字段属性总数据条目数量和有效数据条目数量,情况如表1所示。其中有效数据定义为程序准确抽取,并正确保存在Mysql数据库表中的字段属性值。
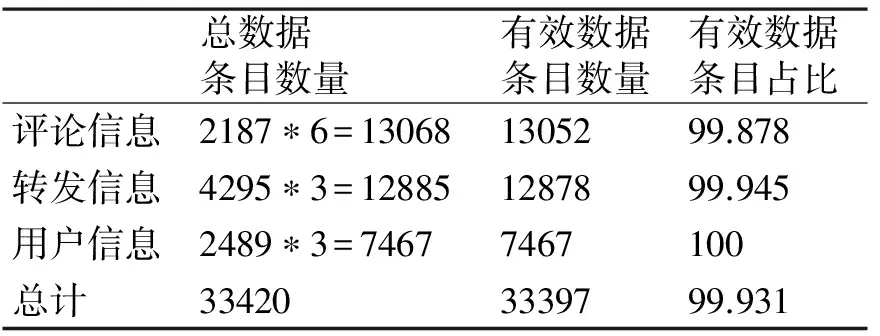
表1 数据准确度统计
从表1可以看出该方案对微博数据的抓取准确度达到了较好的效果。可以对微博传播路径分析、情感倾向分析等提供完整准确的数据支持。
4.2 爬虫抓取性能分析
社交网站数据挖掘属于大数据范畴。微博信息数据量庞大,舆情分析需要海量数据作为基础。单进程爬虫往往很难满足快速抓取大量数据进行舆情分析的需求。本文采用支持并行架构扩展的网络爬虫框架,可以实现多线程并行爬取。本实验仍针对以上100条微博数据,通过开启不同线程数,运行爬虫程序查看其运行速度及加速比。由于实验数据对象实时更新变化,各次抓取数据量会存在极微小差异,但不影响实验结论。爬虫程序在开启1个线程的情况下,完成以上100条微博数据的全面抓取并持久化到数据库,运行时间为4554s。表2为不同线程下爬虫并行抓取时间及加速比。
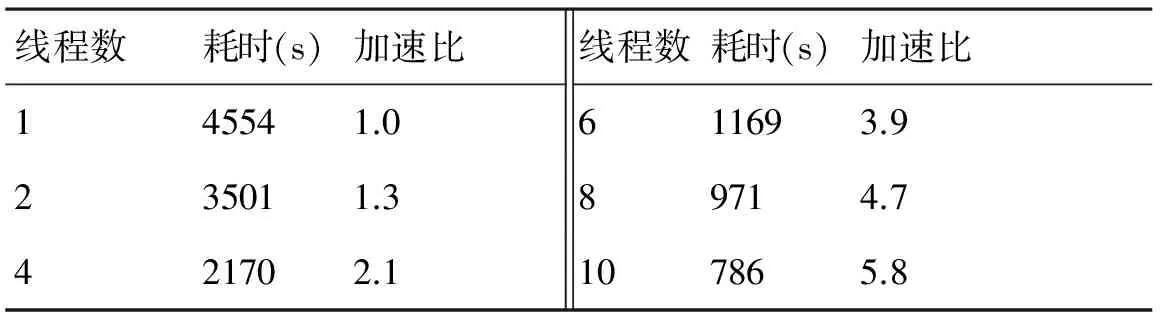
表2 并行抓取耗时及加速比
由于方案基于动态网页数据获取和页面解析,爬虫程序在运行过程中需开启、关闭浏览器,执行Ajax动态数据渲染,提取页面导航元素,触发导航事件并执行页面指令。因此对比微博API调用方式获取数据更耗时。但方案以性能为代价获取完整全面的微博数据,是传统微博数据爬虫和API调用方式不能比拟的。从实验结果可以看出,并行爬虫在多线程并发运行方面具有较好的线性加速比。这说明该方案对海量微博数据的抓取有着非常好的加速效果和潜力。通过合理设置爬虫并行线程数,在保证网络资源带宽的条件下,可以快速高效的获取微博数据。
5 结语
本文介绍了新浪微博数据获取方式,对两种获取方式用法与限制进行阐述和分析。解决了新浪微博数据因API限制和网络爬虫限制而无法完整获取的问题。基于网页动态数据获取技术,通过模拟登陆,确定页面爬取策略,设计微博信息抽取模板和存储方式,完成新浪微博数据挖掘的完整流程。实现了新浪微博数据定制化挖掘方案的实验与应用。实验表明,基于网页动态数据获取,结合网络爬虫技术和页面解析技术,对网络爬虫进行定制改造,能实现指定微博数据的高效和完整获取,可以为社交网络数据挖掘提供准确全面的数据支持。
[1] ABRAHAM R, MART NEZ T. Twittter: Network properties analysis[C]//Proceedings of the CONIELECOMP 2010-20th International Conference on Electronics Communications and Computers. Cholula Puebla, Mexico: IEEE Computer Society,2010:180- 183.
[2] HAN Ruixia. The influence of microblogging on personal public partion[C]//Proceeding of the 2010 IEEE 2nd Symposium on Web Society, SWS 2010. Beijing, China: Association for Computing Machinery,2010:615-618.
[3] 游翔,葛卫丽.微博数据获取技术及展望[J].电子科技,2014,27(10):123-126.
[4] 陈舜华,王晓彤,等.基于微博API的分布式抓取技术[J].电信科学,2013,8(25):147-149.
[5] 周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005,25(9):1965-1969.
[6] 廉捷,周欣,曹伟.新浪微博数据挖掘方案[J].清华大学学报(自然科学版),2011,51(10):1300-1305.
[7] 孙青云,等.一种基于模拟登录的微博数据采集方案[J].计算机技术与发展,2014,24(3):7-8.
[8] 新浪.微博API开发文档[EB/OL]. http://open.weibo.com/wiki/微博API,2014-11-12/2014-12-29.
[9] 刘丽杰.垂直搜索引擎中聚焦爬虫技术的研究[D].哈尔滨:哈尔滨工业大学,2012:3-9.
[10] 吴伶琳.基于Selenium的软件自动化测试的研究与应用[J].计算机与现代化,2013,2(16):65-68.
[11] 郭正彪.大尺度在线社会网络结构研究[D].武汉:华中科技大学,2012:15-26.
Date Crawler for Sina Microblog Based on Dynamic Webpage Date Interpreting
ZHONG Mingxiang TANG Jintao XIE Songxian WANG Ting
(College of Computer, National University of Defense Technology, Changsha 410073)
Microblogging is a new kind of information media. The mass data are generated to attracts the attention of the researchers to carry out related research. Micro-blog data acquisition is the basis and starting point for further research. This paper presents a multi-threaded crawler for Sina microblog platform based on dynamic webpage interpreting. The browser kernel is used to interpret the dynamic data of microblog webpage. Through simulated login, the page crawling strategy based on the characteristics of social networking site is determined, and the webpage parsing technology is used to custom templates of webpage to achieve user-centric microblog data acquisition. The test results show that the method can capture microblog data of user comprehensive and efficiently, provide data support for subsequent dta analysis and processing.
sina microblog, data mining, dynamic webpage, Web crawler
2015年4月2日,
2015年5月27日
国家自然科学基金(编号:61200337;61472436)资助。
钟明翔,男,硕士研究生,研究方向:自然语言处理。唐晋韬,男,博士,讲师,研究方向:社会网络分析、自然语言处理。谢松县,男,博士,讲师,研究方向:自然语言处理。王挺,男,博士,教授,博士生导师,研究方向:自然语言处理。
DOI:10.3969/j.issn.1672-9730.2015.10.026
