基于WEKA的骨科病案数据的关联规则挖掘
2015-03-14石惠
石 惠
(安徽水利水电职业技术学院,安徽 合肥 231603)
医生在对患者病情进行判断时,不仅要依靠先进的医疗技术,还需要依赖丰富的经验。这些经验是从平时大量的诊断中积累的。一方面,所有医生经验的积累并不平均,而且有些疾病发病的几率高,有些则相对较低,在一些发病几率比较小的疾病判断上,就比较容易出现偏差,或者无从判断。另一方面,拥有再丰富的经验的医生也只是依靠主观上的判断。因此,在医院对就诊病人的病情判断中,带着主观意识,没有科学的去衡量各种因素对疾病的影响,是一种被动的诊断。利用数据挖掘技术,把医院病案的历史数据重新利用起来并加以分析,获得潜在的规律和有价值的知识,并提供给医疗工作者。相应科室的医生在判断病情时会更加科学合理,也使得医生的判断更准确,还可以更进一步建立医患间的互信,改善当前相当紧张的医患关系。
1 数据挖掘
数据挖掘又可称为数据库中的知识发现(KDD),就是从大量的无序数据中进行有目的的分析,获取有价值的模式或规律,“挖掘”一词便由此而来。由于数据挖掘是KDD过程中最为关键的步骤,在实践应用中“数据挖掘”已被广泛接受,因此,数据挖掘和KDD这两个术语在实际应用中往往不加以区分。
2 WEKA
WEKA的全名是怀卡托智能分析环境,是一款免费的,非商业化的,基于Java环境下开源的机器学习(Machine Learning)以及数据挖掘(Data Mining)软件。它集成了多种机器学习算法,主要包括数据预处理、分类、聚类、回归、关联规则和在新的交互式界面上的可视化等。
3 关联规则
数据关联是数据库中存在的一类重要的可被发现并且有用的知识,反映单个事件和其他事件之间的依赖和关联。假如2项或多项属性之间存在着关联,那么其中1项的属性值就可以根据其他属性值来进行预测。例如在候车大厅里买方便面的顾客中90%还会买火腿肠,这就是一条关联规则。那么在候车大厅超市中就可以将这2种物品靠近摆放,能促进销售。
关联规则挖掘是数据挖掘领域中的重要课题之一。关联规则挖掘普遍使用支持度和置信度衡量机制。一般地,关联规则挖掘问题可分成2步:发现频繁项目集和生成关联规则。1994年Agrawal等提出了一个算法称为Apriori算法,作为经典的关联规则挖掘算法被引用。
4 骨科病案数据上的关联规则挖掘
基于骨科病案数据,运用weka进行数据挖掘。在收集了某医院骨科住院病案的数据后,再进行进一步地统计、汇总和分析,然后用weka工具进行预处理以便使数据能进行关联规则挖掘,最后再进行关联规则的挖掘。
4.1 数据收集
数据收集是数据挖掘的首要环节,也是数据挖掘的必要步骤。于是首先得收集原始数据,本次收集的数据是某医院骨科6年来住院病案的相关数据,共有956条,如表1所列。

表1 骨科住院病案信息登记表
4.2 数据分析
数据表中有病案号、姓名、性别、年龄、入院日期、出院日期、(住院)天数、出院主诊断(即疾病名称)、ICD(国际疾病编码)、转归(治疗结果)、(是否)手术、住院费用共12个属性。
4.3 数据的预处理
随着数据量的逐渐增多和迅速膨胀,原始数据中存在噪声、不完整和不一致的数据也越来越多。在数据挖掘前需对原始数据进行预处理,主要步骤为数据清理、数据集成、数据转换和数据选择。
(1)数据清理。从现有的数据表中看,数据表中已有的各项数据值比较完整,有些数据项的值不全,但不影响数据挖掘结果,所以不需要填补空缺值。数据的来源单一,所以没有不一致的数据。数据表中对挖掘结果产生影响符合以下3种情形的病案数据均要删除:死亡类数据;未痊愈或好转住院期间中途进行转院或者转科类数据;未痊愈或好转住院期间中途因其他原因强行出院类数据。
另外,对于有些属性值空缺会影响到挖掘结果的数据项,如疾病名称,也要删除。经过数据清理后,最终获得的数据集共有748条数据。
(2)数据集成。原数据的数据表是一个独立的数据源,在此无须进行数据集成。
(3)数据转换。对海量数据进行复杂的数据分析和挖掘将需要很长时间,使得这种分析不现实或不可行。数据转换是将数据转换或归并成一个适合数据挖掘的数据形式。本数据表经数据清理后,有2个属性需要进行转换。描述如下:对数值型数据进行离散化。对所使用的数据的分析以及与骨科医生的不断沟通,首先按照骨科住院病案的特点把住院天数属性值划分为2个区间,一般短期住院在28天以内(包括28天),超过28天的为长期住院,其所对应的具体属性值为(0-28]和(28-inf)。
通过与经验丰富的骨科医生沟通,并依据取值结果来看比较接近自然值,将年龄属性值划分为3个区间,即划分成3个区间,即小于等于35岁的,介于35到68岁之间,大于68岁的。对数据进行泛化处理。分析表1的数据,其中ICD这个属性共有206个属性值,如果直接以此来划分疾病类别,则会导致每种疾病的支持度过低,不利于数据挖掘结果。数据表中的出院主诊断属性值为疾病的中文名称,通过查阅资料并与骨科医生讨论分析,再结合表1数据表中的此属性具体取值,用以下步骤对其进行数据处理:出院主诊断属性的取值按医院诊断骨科疾病时的分类来分,分成创伤、脊柱外科、关节外科、手外科、显微外科、骨肿瘤、小儿骨科和常见骨疾病。再根据每个类的支持度,将那些支持度过小影响挖掘结果的类向上合并,将那些支持度过大的类再进行划分。最终将数据表中所有疾病名称划分成12类,即12个属性值,并且为方便计,先将这个类别名称改名为易于理解的疾病名称(DN),将长疾病名称简化成英文缩写,其他数据项及属性值为了保持一致也全部转化为英文来表示。经过数据转换后的属性取值如表2所列。
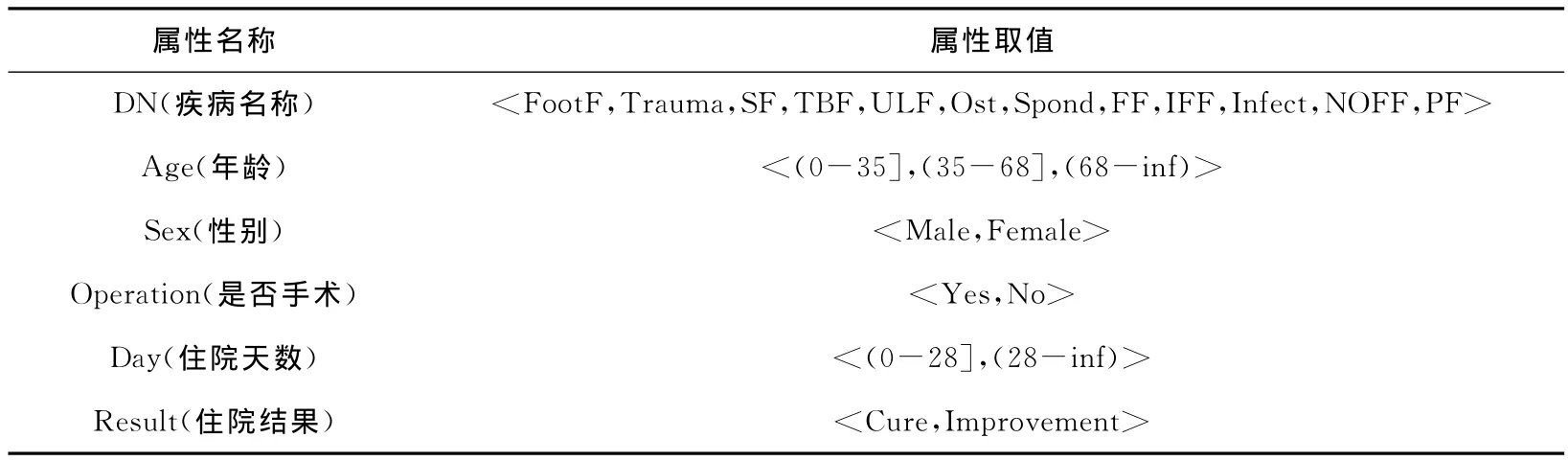
表2 部分属性取值
(4)数据选择。查看数据表,对于数据挖掘无用的数据项如病案号和姓名这2个数据项进行删除;因为有了(住院)天数这个数据项,入院日期和出院日期这2个数据项就可以删除了;出院主诊断和ICD相互重复,所以将ICD数据项删除;因为影响住院费用的因素和所使用的药品及使用的药用器材等密切有关,在数据表中没有这些相关的数据信息,这会影响到数据挖掘的结果,所以对住院费用数据项也进行删除。经过数据清洗、数据转换和数据消减后的数据表如表3所列。

表3 整理后的数据表
4.4 关联规则的挖掘
选择weka中的Associate,采用Apriori算法,设置置信度参数最小值为0.9。得到的规则如下:
从以上关联规则可以看出,普通的骨病、创伤类和上肢骨折类等疾病的病人住院时间为28天以内。关联规则是针对多属性的,当我们收集到更多的可能具有某种关联的数据时,获得的关联规则会更具价值。
5 结束语
本文通过对某医院骨科病案数据的整理分析,并利用weka软件进行数据挖掘,获得了数据间的关联,找出了某些因素间的隐含关系,可为骨科医生对住院病人的病情判断提供理论上的支持。
[1]Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].范明,孟小峰译.北京:机械工业出版社,2007.
[2]Fan Jianhua and Li Deyi.An overview of Data Mining and Knowledge Discovery[J].Comput.Sci&Technol,1998(4):348-369.
[3]David Hand.数据挖掘原理[M].张银奎译.北京:机械工业出版社,2003.
[4]文 拯,梁建武,陈 英.关联规则算法的研究[J].计算机技术与发展,2009(5):56-59.
