Office文件编辑过程痕迹提取研究
2015-03-07徐国天中国刑事警察学院
徐国天 中国刑事警察学院
一、前言
Office软件的主要版本包括:2000、2003、2007和2010,当前大部分基于windows操作系统的计算机安装了Office软件。政府机关、企事业单位、金融机构及个人用户普遍使用Office软件编辑word文档、制作excel数据表、编制ppt汇报,尤其是很多财务报表使用excel制作。在这些Office文档内保存了大量对案件办理有价值的数据信息。为了逃避法律的制裁,迷惑办案人员,犯罪分子可能不是删除整个Office文件,而只是删除或修改了Office文档中的部分内容,如几段文字、几张图片或几个数据表,恢复这些被删除和修改的数据内容,提取出修改的时间和修改人使用的用户名,对公安机关的调查、取证工作有重要的意义,但是目前这部分被删除或修改的数据信息无法有效提取。
当前公安机关遇到此类检验需求时,主要是使用通用数据恢复软件来完成(如Final Data、Easy Recovery)。但是现有数据恢复软件只能恢复出被删除的Office文档,而不能很好地完成文件中间编辑过程的痕迹提取,进而不能满足公安机关逐渐增多的Office文件编辑过程痕迹提取和破损Office文件修复类的检验需求。
针对这种要求,本文开发了一款Office文件编辑过程痕迹自动提取软件系统,该系统可以准确地对NTFS格式磁盘内残留的Office痕迹碎片进行提取,具有很好的实战价值。
二、文件编辑过程痕迹提取
以图1为例解释Office文件编辑过程痕迹提取效果。在硬盘存储空间中,阴影区域代表已被其它文件使用的存储空间,即已占用空间。白色区域代表空闲的、可以使用的存储区域。用户对某个Excel文件执行了第一次编辑操作,在其中添加了一条记录:“张明 ¥5000”,单击保存时,这个文档被保存到第一块空闲空间中。随后另一个用户执行了第二次编辑操作,修改了第一条记录的金额,同时增加了两条新的记录,之后单击了保存按钮。Office软件有这样一个特点,它不会将数据保存在原始的存储位置(即使原始空间足够),而是在硬盘空闲区域重新寻找一块空间存储数据。在本例中,第二组痕迹被保存在第二块空闲存储空间内,之前第一块存储空间内的数据并没有真正消失,只是存储状态由已占用状态重新调整为空闲状态,只要这块存储空间不被其它文件重新使用,第一组痕迹数据就可以成功恢复。最后第三个用户对这个Excel文件执行了第三次编辑操作,删除了最后一条记录,修改了前两条记录的金额字段。完成编辑之后,这组痕迹数据被保存至第三块存储区域。
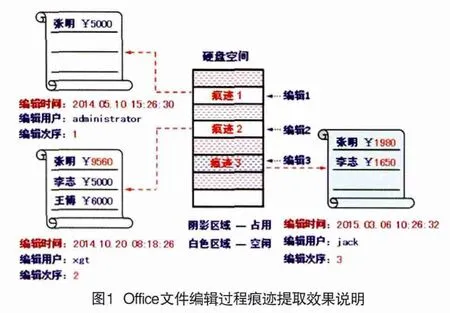
编辑过程痕迹提取要完成的第一个任务就是从硬盘中提取出三组编辑痕迹,形成三个可以直接查看的excel文件。第二要提取出三次编辑操作执行的日期和时间,精确到秒。第三要提取出执行这三个编辑操作的用户名。第四要提取出每组编辑痕迹对应的编辑次序。这样一来,从得到的编辑次序序列中就可以直观地看到缺少了哪几次编辑,这些丢失的编辑操作可能不是发生在这块磁盘,或者对应的编辑痕迹数据已经被覆盖。
三、当前痕迹提取存在的主要问题
目前没有一款专门的软件系统进行Office文件编辑过程痕迹提取,有此类检验需求时,普遍使用通用数据恢复软件(如Final data、Easy recovery)来完成。但是现有通用数据恢复软件在进行Office文件编辑过程痕迹提取时存在以下问题,见图2说明。

如果痕迹数据保存在一块存储区域中(如编辑1产生的痕迹一),那么现有软件可以恢复这组痕迹数据,形成可以查看的Office文件,但是不能确定痕迹的产生时间和执行这次编辑操作的用户名称,也不能确定每个痕迹隶属于哪个文件(即得到一些孤立的、无关联信息的Office文件)。如果痕迹数据保存在多个存储区域(如编辑2产生的痕迹二就分别存储在两个存储区域),那么现有软件无法进行提取。
四、本文系统的主要特色
本文开发的软件系统可以提取出Office文件编辑痕迹的形成时间和执行这次编辑操作的用户名称,找出Office 文件残留在存储设备中的所有痕迹,并按照产生时间顺序进行排列,形成完整的时间链条。
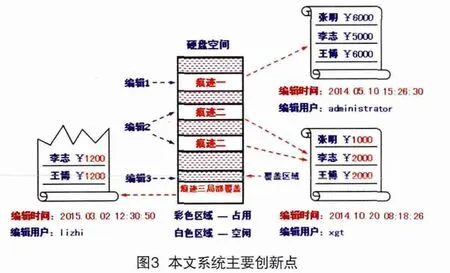
如果某次编辑产生的痕迹数据保存在若干个分隔开来的存储区域中,使用现有数据恢复软件无法提取这种离散存储的数据。课题开发软件系统可以找出所有的存储分片,排列次序组合成完整的Office文件。图3中的编辑2产生的痕迹存储在两个存储区域,应用课题开发软件系统可以识别出这两个分片,确定先后次序,重组成一个完整的Office文件。
残留的痕迹数据极可能被部分覆盖,此时恢复出的Office文件不能正常查看,应用课题开发的软件系统可以修复损坏的Office痕迹文件,正常显示残留的数据信息。图3中编辑3产生的痕迹三局部遭到覆盖,造成文件内容缺失,无法正常打开。课题软件可以从破损文件中提取出残留的数据,并显示出来。
五、Office文档编辑痕迹提取技术关键
(一)Ooxml格式标准
Ooxml是Office Open Xml的简称,是微软新一代办公软件文档格式标准,是由微软开发的一种以XML为基础并以ZIP格式压缩的电子文件规范,支持DOCX文件、XLSX电子表格、PPTX幻灯片等。
DOCX文件由若干个XML文件、文本文件、图片、视频文件组成,这些文件采用ZIP格式压缩存储。所有的文字、表格、图片和视频的ID号均保存在document.xml文件内。所有的多媒体文件均保存在media文件夹下。document.xml.rels文件保存了所有多媒体文件的ID和存储位置影射关系。
(二)文字和图像数据的提取
在2007和2010版本的Office文档中、所有的文字数据均保存在document.xml文件中,如图4-a所示,文字信息夹杂在标记符号

在document.xml文件中只保存了图片数据的ID编号,如图4-b所示。关键词imagedata是图片的标志,这个位置图片的编号为rId26。在document.xml.rels文件中记录了Office文件中所有对象的ID号与存储位置的对应关系。编号rId26的图片保存在media/image20.jpeg。
(三)文字和图像数据的存储
Office文件中的文本对象(如XML文件)是以ZIP格式压缩存储的。图5显示的是document.xml部分数据。起始位置是四个字节的文件头标志,0X 50 4B 电子="。0X 1400代表解压文件所须最低版本为20。0X 0600 是通用标记位。0X 0800代表采用的压缩方法,注意这个字段可以用来区分文档是否采用了ZIP压缩。

0X 00002100代表修改时间,即1980-01-01,所有Office文件的修改时间均为这个数值。0X A2 6F 9E 96是文件的CRC32校验和,注意这里的校验和不是根据随后的压缩数据计算的,而是根据解压之后的数据计算的。只要压缩数据中某个比特位发生变化,得到的校验和就会不同。0X 80 0E 时间即1代表压缩后的文件大小为1379968字节。0X C3 9B 1C 00代表压缩之前的文件大小为1874883字节。0X 0代压缩代表文件名长度为17。文件名为“word/document.xml”共17个字节。
Office文档中的图片数据没有进行压缩处理。这可能是考虑到图像本身已经采用了某种压缩算法进行处理,使用ZIP算法进行二次压缩,文件大小不会有明显的缩小,而解压缩文件还要消耗大量的时间,因此图像数据不进行压缩处理。
(四)离散存储Office碎片的定位
Office文件在编辑过程中,某些中间步骤的痕迹数据不会保存在一块连续的存储空间内,而是离散存储在多个位置。这就需要准确定位这些离散存储的碎片,同时对这些碎片进行排序,重新组合成一个完整的Office文件。
可以通过文件头标志准确识别出硬盘空闲空间内的Office碎片,包括三个特征值:0X 50 4B tre=、0X 50 4B 504B和0X 50 4B 504B。由于Office文档的头部特征值与ZIP数据块的头部特征值相同,这就极易出现误判的情况。因此定位到一个数据碎片之后,判断其修改时间字段,如修改时间为1980-01-01,则认定为Office文件,否则认定为ZIP数据块。
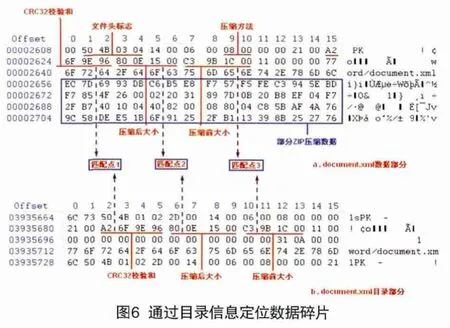
另一个关键问题是如何确定哪些数据碎片属于同一文件。这可以通过Office文档尾部保存的ZIP核心目录数据来确定。Office文件中的每一个对象在ZIP核心目录区域均有一条记录。根据每个目录项保存的对象名、压缩前后大小和CRC32校验和就可以定位到离散存储的数据碎片。同时目录项也记录了所有对象的排列次序,通过它也可以确定所有碎片的排序。
图6说明的是通过目录信息定位数据碎片的举例。图6-b目录信息中的CRC32校验和、压缩前后文件大小和文件名与图6-a数据碎片部分的对应数据完全相同,可以认定这组数据碎片隶属于当前Office文件。
六、软件系统的设计
软件系统采用VC++6.0开发,设计流程如图7所示。首先读取NTFS文件系统的BPB参数表,获得空闲空间的分布情况。之后根据Office文件头部特征值在空闲空间内搜索所有Office碎片。之后依次判断每个目录数据碎片是否为一个完整的Office文件(即整个文件保存在一块连续的存储空间内)。如果不是一个完整的Office文件,则根据目录项逐个寻找散落的数据碎片,并将它们提取、组合成一个文件。
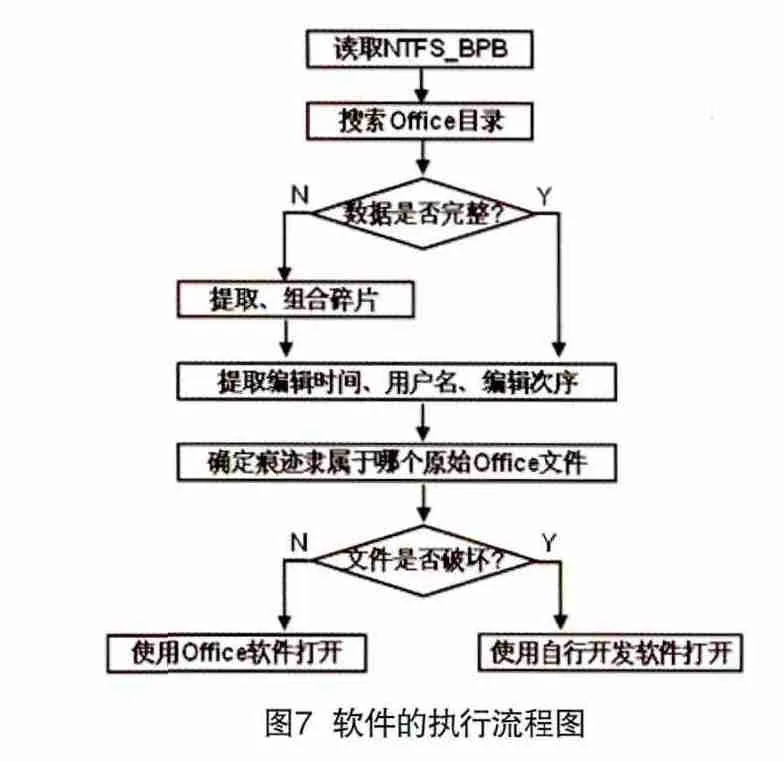
随后软件自动对提取的Office文件进行解压缩,从中提取出文件创建时间、编辑时间、编辑者使用的用户名、编辑次序信息。将具有相同文件创建时间的Office文件划归为一组(即认为这些文件属于同一个原始Office文件的编辑痕迹,依据是在一秒内不可能创建多个Office文件)。最后判断每个Office文件是否遭到破坏(可以通过CRC32检验和进行识别),如未损坏,则可以使用Office软件正常打开。如果已经遭到破坏,则使用自行开发的软件系统进行打开。课题开发的软件系统可以将未损坏部分正常解压缩,使的残留的数据信息(如部分文字、部分图像)仍然可以正常显示。
七、软件系统的测试
本文系统可以提取出Word、Excel、ppt文件的编辑痕迹,形成可直接查看的Office文件,同时获取到文件的编辑次序、编辑时间、执行编辑操作的用户名,软件的运行情况举例说明见图8~图10。
软件体积小,只有500kB,可以在Winxp、Win7、Win8环境下运行,工作时指定准备提取Office文件编辑过程痕迹的目标磁盘分区和用于保存提出痕迹的结果分区。例如本次测试对外置U盘“I”进行痕迹提取,结果保存在外置U盘“H”中。
软件会自动在结果分区中创建一个restore文件夹,并在其中建立三个子文件夹,分别存储提取出的DOCX、PPTX和XLSX文件编辑痕迹。提出的编辑痕迹保存在以文件创建时间命名的文件夹内,图8显示的是提取出两个DOCX文件的编辑痕迹,这两个文件的创建时间分别是2014-06-3004:26:00和2015-02-0111:17:06。

图9显示的是提取出的某个DOCX文件的编辑痕迹,共提取出四条痕迹,以第一条记录为例加以解释。

revision = 09 表示这是第9次对该DOCX文件编辑产生的痕迹。可以看到这四个痕迹的编辑次序并不连续,缺失的痕迹有两种情况。一是这些缺失的编辑操作不在这块U盘上完成,例如将文件复制到其它存储设备上,编辑完成后再复制回原U盘,同名覆盖原始文件。二是部分缺失痕迹已被覆盖,无法提取。modified_time = 2015-02-2608:19:00表示修改时间。lastModifiedBy = xiaoping表示这次编辑操作是由xiaoping用户完成。creator = xiaoping表示这个文件由xiaoping用户创建。
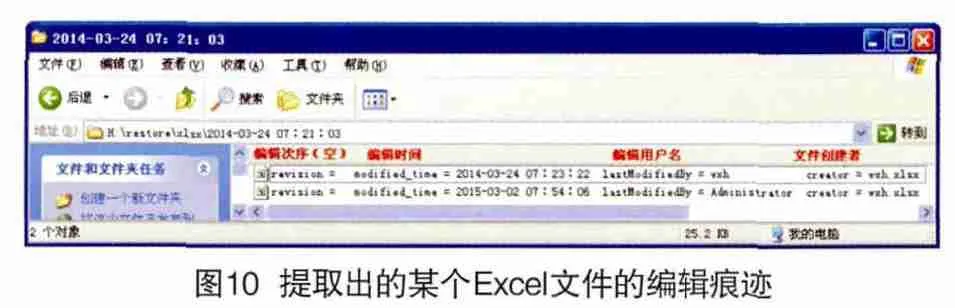
图10显示的是提取出的某个Excel文件的编辑痕迹,与DOCX和PPTX文件不同的是,Excel文件不能提取出编辑次序,但是Excel文件的编辑时间可以精确到秒,因此可以通过编辑时间区分出先后编辑次序。
课题组对软件的实践效果进行了大量测试分析,测试结果显示,未被完全覆盖的编辑痕迹均可正常提取,可得到编辑次序链条,如图8~图10所示。
八、总结
本文针对2007和2010版本的Office软件开发出一款文件编辑过程痕迹提取软件系统,该系统可以提取Office文件遗留在磁盘内的痕迹数据,形成一系列可以直接查看的Office文件,同时获取到痕迹的编辑时间、编辑者的用户名和编辑次序。
由于2003版本的Office文档与2007和2010版本的文档采用了完全不同的存储方式,因此笔者计划进一步研究根据NTFS文件系统日志数据,提取出2003版本Office文档的编辑过程痕迹。
[1] 戴士剑,涂彦晖.数据恢复技术(第二版)[M].北京:电子工业出版社, 2005.
[2] 徐国天. NTFS系统下“小文件”取证软件的设计与实现[J].信息网络安全,2011.
[3] 董立波,罗洁,邵永军. SIM卡中信息提取方法的研究[J]. 刑事技术, 2007.
[4] 徐国天. 基于“连带效应”和“过期日志”的EXT3文件系统数据恢复方法研究[J]. 中国司法鉴定, 2015.
